7、Flink 流计算处理和批处理平台_批处理和流计算-程序员宅基地
技术标签: Flink 流计算处理和批处理平台
一、Flink 基本概念
Flink 是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。Flink 与 Storm 类似,属于事件驱动型实时流系统。
所谓说事件驱动型指的就是一个应用提交之后,除非明确的指定停止,否则,该业务会一直持续的运行,它的执行条件就是触发了某一个事件,比如在淘宝中,我们付款需要在支付宝付款,但是付款成功与否的条件是从淘宝获取的,支付宝通过接口向淘宝反馈扣款结果,这个计算的应用是一直存在的,它需要获取支付宝扣款的结果,将结果进行计算加入到后台数据库,记录日志并且向淘宝反馈扣款成功的信息。这个时候,这一系列的操作都是由于用户触发了付款这个事件而导致的,之后系统就会进行这个计算,应用是持续存在的,没有事件驱动的情况下,这个应用是处于静止状态的,事件驱动之后,应用进行计算和反馈。
1.批处理和流处理
批处理在大数据世界有着悠久的历史。批处理主要操作大容量静态数据集,并在计算过程完成后返回结果。
批处理模式中使用的数据集通常符合下列特征:
(1) 有界:批处理数据集代表数据的有限集合
(2) 持久:数据通常始终存储在某种类型的持久存储位置中
(3) 大量:批处理操作通常是处理极为海量数据集的唯一方法
批处理非常适合需要访问全套记录才能完成的计算工作。例如在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。这些操作要求在计算进行过程中数据维持自己的状态。
需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较高的场合。流处理系统会对随时进入系统的数据进行计算。相比批处理模式,这是一种截然不同的处理方式。流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。
流处理中的数据集是“无边界”的,这就产生了几个重要的影响:
(1) 完整数据集只能代表截至目前已经进入到系统中的数据总量。
(2) 工作数据集也许更相关,在特定时间只能代表某个单一数据项。
(3) 处理工作是基于事件的,除非明确停止否则没有“尽头”。处理结果立刻可用,并会随着新数据的抵达继续更新。
流处理系统可以处理几乎无限量的数据,但同一时间只能处理一条(真正的流处理)或很少量(微批处理,Micro-batch Processing)数据,不同记录间只维持最少量的状态。虽然大部分系统提供了用于维持某些状态的方法,但流处理主要针对副作用更少,更加功能性的处理(Functional processing)进行优化。
功能性操作主要侧重于状态或副作用有限的离散步骤。针对同一个数据执行同一个操作会或略其他因素产生相同的结果,此类处理非常适合流处理,因为不同项的状态通常是某些困难、限制,以及某些情况下不需要的结果的结合体。因此虽然某些类型的状态管理通常是可行的,但这些框架通常在不具备状态管理机制时更简单也更高效。
此类处理非常适合某些类型的工作负载。有近实时处理需求的任务很适合使用流处理模式。分析、服务器或应用程序错误日志,以及其他基于时间的衡量指标是最适合的类型,因为对这些领域的数据变化做出响应对于业务职能来说是极为关键的。流处理很适合用来处理必须对变动或峰值做出响应,并且关注一段时间内变化趋势的数据。
2.Flink 特点和应用场景
Flink 最适合的应用场景是低时延的数据处理场景:高并发处理数据,时延毫秒级,且兼具可靠性。
典型应用场景有:
(1) 互联网金融业务。
(2) 点击流日志处理。
(3) 舆情(舆论情绪)监控。 Flink 的特点有以下几种:
(1) 低时延:提供 ms 级时延的处理能力。
(2) Exactly Once:提供异步快照机制,保证所有数据真正只处理一次
(3) HA:JobManager 支持主备模式,保证无单点故障。
(4) 水平扩展能力:TaskManager 支持手动水平扩展。
Flink 能够支持 Yarn,能够从 HDFS 和 HBase 中获取数据;能够使用所有的Hadoop 的格式化输入和输出;能够使用 Hadoop 原有的 Mappers 和 Reducers,并且能与 Flink 的操作混合使用;能够更快的运行 Hadoop 的作业。
二、Flink 架构
1.Flink 组件架构
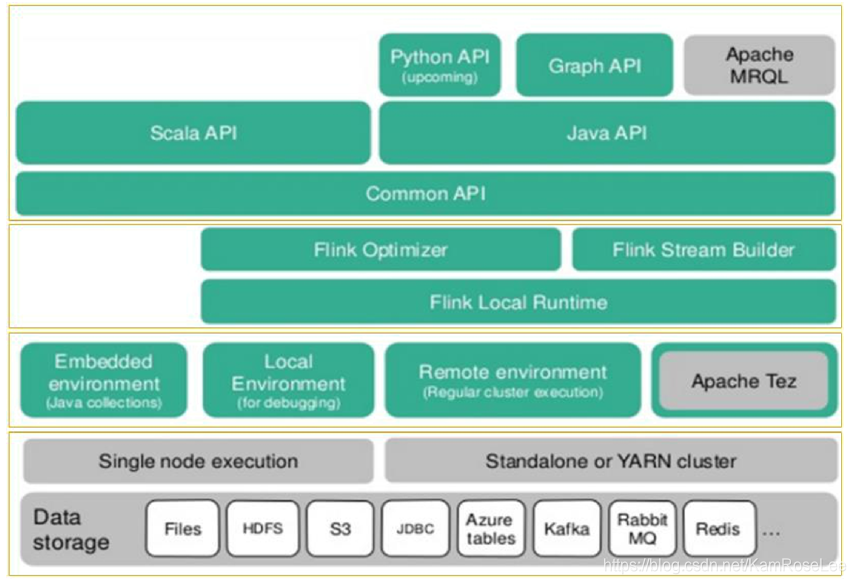
(1) Data storage 底层是数据存储
(2) Single node execution 表示的是部署方式
(3) Local Environment 等表示的是不同的运行环境
(4) Flink Local Runtime 表示是运行线程
(5) Flink Optimizer,Flink Stream Builder 等表示的是优化器
(6) Common API 表示的是 Flink 平台的 API
(7) Scala API 和 Java API 表示的是对外提供的 API
该逻辑图按照从上向下的结构,我们可以看出,最高层的组件都是 API 接口,用于提供用户的接入。第二层主要是创建编译工作流,并且对工作流做优化操作。然后将输入的数据按照创建好的工作流去执行,通过 Flink Local Runtime 组件来执行计算。第三层是环境层,不同的数据和应用的执行环境不同,就比如有一些游戏需要运行在 Java 环境中,在对不同的数据进行计算的时候,我们需要的底层环境也是不同的。最下边的一层是部署和数据的最底层,Flink 默认支持两种部署模式,一种是单独部署,也就是指 Flink 直接部署在集群上,作为独立计算工具运行。另一种是 Yarn 部署,就是将 Flink 认知为是 Hadoop 中的一个组件,和 Yarn 对接来使用。这样做可以充分利用各个组件的优势,组件之间互相结合来进行工作的执行。
2.Flink 的数据结构
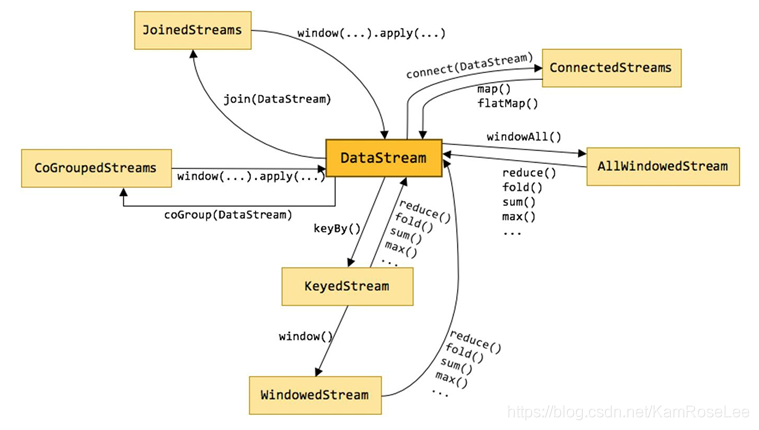
DataStream 是数据模型,所有的数据在进入 Flink 到从 Flink 输出都必须要按照 DataStream 的模型来进行计算和数据的转换。Flink 用类 DataStream 来表示程序中的流式数据。用户可以认为它们是含有重复数据的不可修改的集合(collection),DataStream 中元素的数量是无限的。这里有两个重点,首先, Stream 流式数据可能会存在有重复的数据,这点本身无可厚非,我们在实际写入数据的时候,不同的用户提交相同的数据是很有可能的,而系统也必须要对每一个相同的数据做都做相关的计算操作。那么流数据还有一个特点就是元素是无限的。我们认为流式数据是一个无头无尾的表,旧的数据已经计算完成就被淘汰,而新的数据会被切分成数据分片添加到数据流的结尾。
DataStream 之间的算子操作:
(1) 含有 Window 的是窗口操作,与后面的窗口操作相关连,之间的关系可以通过 reduce,fold,sum,max 函数进行管关联。
(2) connect:进行 Stream 之间的连接,可以通过 flatmap,map 函数进行操作。
(3) JoinedStream :进行 Stream 之间的 join 操作,类似于数据库中的 join,可以通过 join 函数等进行关联。
(4) CoGroupedStream:Stream 之间的联合,类似于关系数据库中的 group 操作,可以通过 coGroup 函数进行关联。
(5) KeyedStream:主要是对数据流依据 key 进行处理,可以通过 keyBy 函数进行处理。
DataStream 在计算中一共分为了三个步骤:DataSource、Transformation 和DataSink。
(1) Data source:流数据源的接入,支持 HDFS 文件、kafka、文本数据等。
(2) Transformations:流数据转换。
(3) Data sink:数据输出,支持 HDFS、kafka、文本等。

在 DataStream 中,数据流转换流程与 Spark 类似:
(1) 从 HDFS 读取数据到 DataStream 中
(2) 接下来进行相关算子操作,如 flatMap,Map,keyBy
(3) 接下来是窗口操作或算子操作(4) 最后处理结果 sink 到 HDFS
三、Flink 执行流程
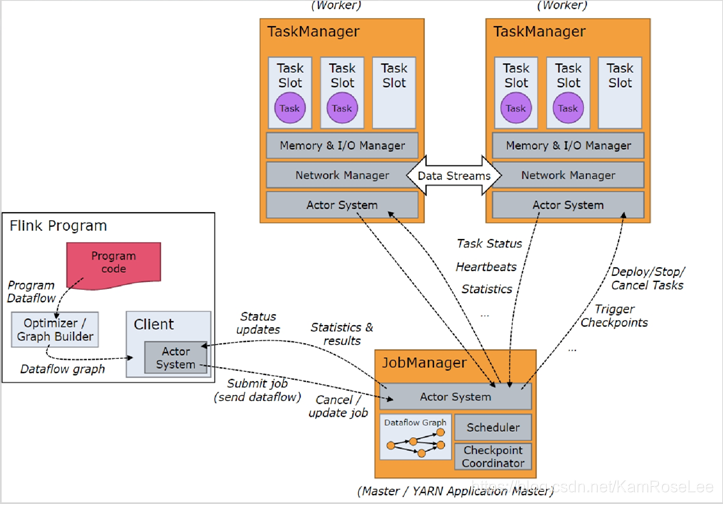
(1) Client:Flink Client 主要给用户提供向 Flink 系统提交用户任务(流式作业)的能力。
(2) TaskManager :Flink 系统的业务执行节点,执行具体的用户任务。TaskManager 可以有多个,各个 TaskManager 都平等。
(3) JobManager:Flink 系统的管理节点,管理所有的 TaskManager,并决策用户任务在哪些 Taskmanager 执行。JobManager 在 HA 模式下可以有多个,但只有一个主 JobManager。
(4) TaskSlot(任务槽):类似 yarn 中的 container 用于资源隔离,但是该组件只包含内存资源,不包含 cpu 资源。每一个 TaskManager 当中包含 3 个 Task Slot,TaskManager 最多能同时并发执行的任务是可以控制的,那就是 3 个,因为不能超过 slot 的数量。 slot 有独占的内存空间,这样在一个 TaskManager 中可以运行多个不同的作业,作业之间不受影响。slot之间可以共享 JVM 资源, 可以共享 Dataset 和数据结构,也可以通过多路复用(Multiplexing) 共享 TCP 连接和心跳消息(Heatbeat Message)。
(5) Task:任务执行的单元。执行流程:
(1) 任务的执行流程主要是分成了工作流的下发创建和数据流的执行流程两个部分。在执行数据流计算之前,必须先把任务的执行流程先做好。所以 Client 收到用户提交的应用之后,会通过 FlinkProgram 将用户提交的应用转换成为流式作业,以 Topology 的形式提交到 JobManager 中,该流式作业的 Topology 如果没有在用户的强制指定关闭的情况下,会一直持续的按照事件驱动型进行运行。
(2) JobManager 通过 Actor 进程和其他组件进行联系,通过 scheduler 进程检查当前集群中所有 TaskManager 中的集群负载,选择负载最小的TaskManager,将任务下发到不同的 TaskManager 中。
(3) TaskManager 其实可以理解成为是节点,TaskManager 通过 ActorSystem收到 JobManager 的请求之后,下一步会将提交的作业进行下发执行,但是执行之前 TaskManager 还需要检测当前集群资源的使用情况,将内存资源封装成 TaskSlot,下发到其中进行执行。CPU 资源由节点所有进程共享。
(4) 最终 TaskSlot 执行完任务之后,会将执行的结果直接传送到下一个TaskManager 中,而不是反馈给 JobManager。所以作为 JobManager,其只负责了任务的下发,数据的下发,还有结果的接收,对于所有的中间结果,JobManager 都不负责管理。
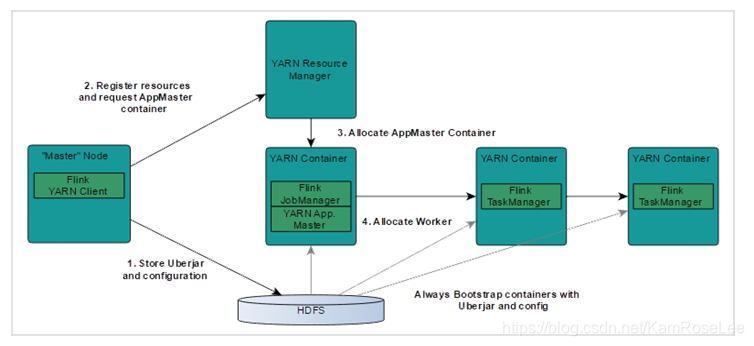
(1) Flink YARN Client 首先会检验是否有足够的资源来启动 YARN 集群,如果资源足够的话,会将 jar 包、配置文件等上传到 HDFS。
(2) Flink YARN Client 首先与 YARN Resource Manager 进行通信,申请启动ApplicationMaster(以下简称 AM)。在 Flink YARN 的集群中,AM 与 Flink JobManager 在同一个 Container 中。
(3) AM 在启动的过程中会和 YARN 的 RM 进行交互,向 RM 申请需要的 Task ManagerContainer,申请到 Task Manager Container 后,在对应的 NodeManager 节点上启动 TaskManager 进程。
(4) AM 与 Fink JobManager 在同一个 container 中,AM 会将 JobManager 的 RPC 地址通过 HDFS 共享的方式通知各个 TaskManager,TaskManager 启动成功后,会向 JobManager 注册。
(5) 等所有 TaskManager 都向 JobManager 注册成功后,Flink 基于 YARN 的集群启动成功,Flink YARN Client 就可以提交 Flink Job 到 Flink JobManager,并进行后续的映射、调度和计算处理。
四、Flink 技术原理
1.流式数据运行原理

用户实现的 Flink 程序是由 Stream 数据和 Transformation 算子组成。Stream 是一个中间结果数据,而 Transformation 是算子,它对一个或多个输入 Stream 进行计算处理,输出一个或多个结果 Stream。
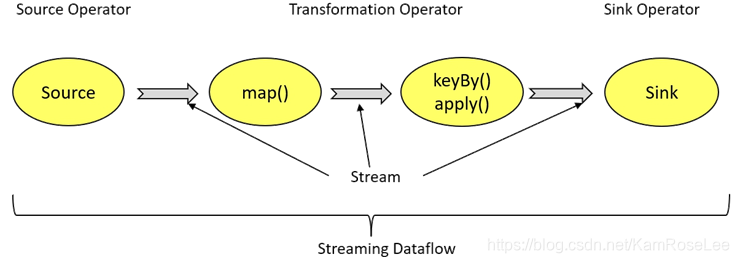
Flink 程序执行时,它会被映射为 Streaming Dataflow 。一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成,它类似于一个DAG 图,在启动的时候从一个或多个 Source Operator 开始,结束于一个或多个Sink Operator。
(1) Source:流数据源的接入,支持 HDFS 文件、kafka、文本数据等。
(2) Sink:数据输出,支持 HDFS、kafka、文本等。
(3) Stream 是 Flink 计算流程中产生的中间数据。Flink 是按 event 驱动的,每个 event 都有一个 event time 就是事件的时间戳,表明事件发生的时间,这个时间戳对 Flink 的处理性能很重要,后面会讲到 Flink 处理乱序数据流时,就是靠时间戳来判断处理的先后顺序。

一个 Stream 可以被分成多个 Stream 分区(Stream Partitions),一个 Operator 可以被分成多个 Operator Subtask,每一个 Operator Subtask 是在不同的线程中独立执行的。一个 Operator 的并行度,等于 Operator Subtask 的个数,一个Stream 的并行度等于生成它的 Operator 的并行度。
1.One-to-one 模式比如从 Source[1]到 map()[1],它保持了 Source 的分区特性(Partitioning)和分区内元素处理的有序性,也就是说 map()[1]的 Subtask 看到数据流中记录的顺序,与 Source[1]中看到的记录顺序是一致的。
2.Redistribution 模式这种模式改变了输入数据流的分区,比如从 map()[1] 、 map()[2] 到 keyBy()/window()/apply()
[1] 、keyBy()/window()/apply()[2] , 上 游 的Subtask 向下游的多个不同的 Subtask 发送数据,改变了数据流的分区,这与实际应用所选择的 Operator 有关系。 Subtask 的个数,一个 Stream 的并行度总是等于生成它的 Operator 的并行度。
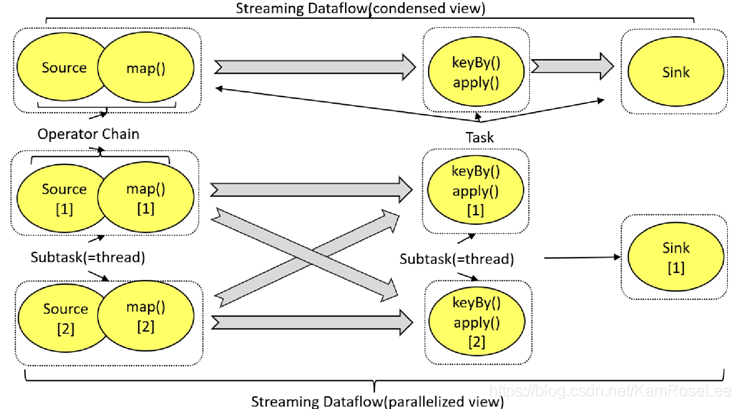
Flink 内部有一个优化的功能,根据上下游算子的紧密程度来进行优化。紧密度高的算子可以进行优化,优化后可以将多个 Operator Subtask 串起想·来组成一个 Operator Chain,实际上就是一个执行链,每个执行链会在 TaskManager 上一个独立的线程中执行。上半部分表示的是将两个紧密度高的算子优化后串成一个 Operator Chain,实际上一个 Operator Chain 就是一个大的 Operator 的概念。途中的 Operator Chain 表示一个 Operator,keyBy 表示一个 Operator,Sink 表示一个 Operator,他们通过 Stream 连接,而每个 Operator 在运行时对应一个 Task,也就是说图中的上半部分 3 个 Operator 对应的是 3 个 Task。下半部分是上半部分的一个并行版本,对每一个 Task 都并行华为多个 Subtask,这里只是演示了 2 个并行度,sink 算子是 1 个并行度。
2.Flink 窗口技术
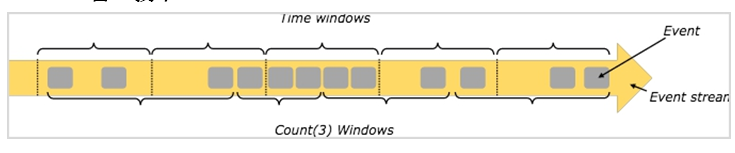
Flink 支持基于时间窗口操作,也支持基于数据的窗口操作:
(1) 按分割标准划分:timeWindow、countWindow。
(2) 按窗口行为划分:Tumbling Window、Sliding Window、自定义窗口。窗口按驱动的类型分为时间窗口(timeWindow)和事件窗口(countWindow)。窗口可以是时间驱动的(Time Window,例如:每 30 秒钟),也可以是数据驱动的(Count Window,例如:每一百个元素)。
窗口按照其想要实现的功能分为:
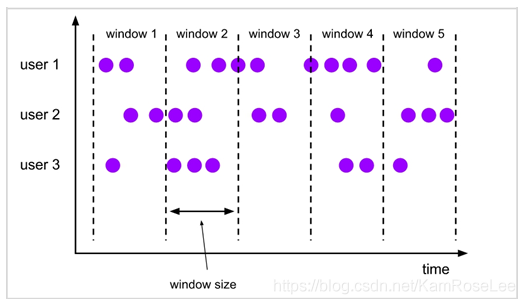
翻滚窗口(Tumbling Window,无时间重叠,固定时间划分或者固定事件个数划分)
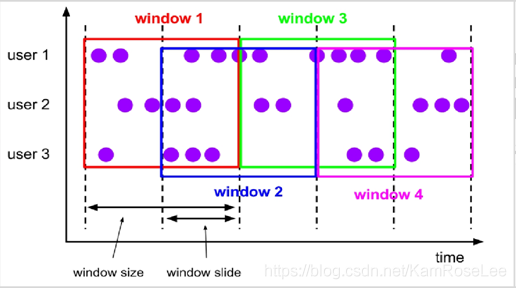
滚动窗口(Sliding Window,有时间重叠)
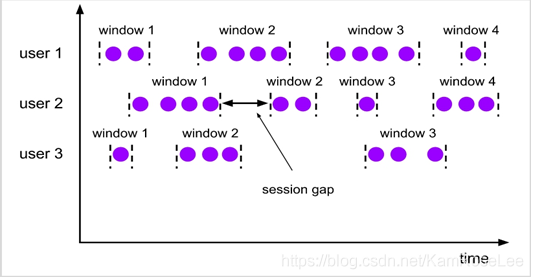
会话窗口(Session Window,将事件聚合到会话窗口中,由非活跃的间隙分隔开)。
3.Flink 容错机制
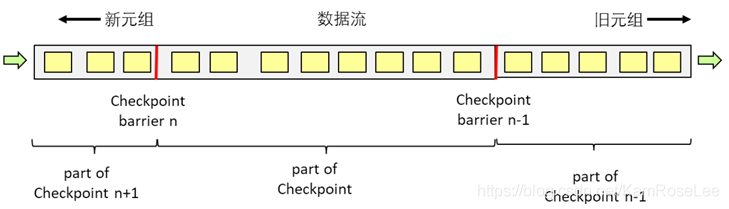
checkpoint 机制是 Flink 运行过程中容错的重要手段。 checkpoint 机制不断绘制流应用的快照,流应用的状态快照被保存在配置的位置(如:JobManager 的内存里,或者 HDFS 上)。Flink 分布式快照机制的核心是 barriers,这些 barriers 周期性插入到数据流中,并作为数据流的一部分随之流动。barrier 是一个特殊的元组,这些元组被周期性注入到流图中并随数据流在流图中流动。每个 barrier 是当前快照和下一个快照的分界线。在同一条流中 barriers 并不会超越其前面的数据,严格的按照线性流动。一个 barrier 将属于本周期快照的数据与下一个周期快照的数据分隔开来。每个 barrier 均携带所属快照周期的 ID,barrier 并不会阻断数据流,因此十分轻量。Checkpoint 机制是 Flink 可靠性的基石,可以保证 Flink 集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。该机制可以保证应用在运行过程中出现失败时,应用的所有状态能够从某一个检查点恢复,保证数据仅被处理一次(Exactly Once)。另外,也可以选择至少处理一次(at least once)。
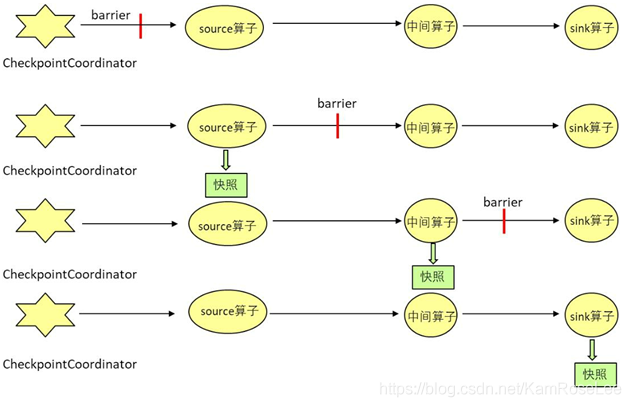
每个需要 checkpoint 的应用在启动时,Flink 的 JobManager 为其创建一个CheckpointCoordinator,CheckpointCoordinator 全权负责本应用的快照制作。用 户 通 过 CheckpointConfig 中 的 setCheckpointInterval() 接 口 设 置checkpoint 的周期。
CheckPoint 机制
CheckpointCoordinator 周期性的向该流应用的所有 source 算子发送barrier。当某个 source 算子收到一个 barrier 时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向 CheckpointCoordinator 报告自己快照制作情况,同时向自身所有下游算子广播该 barrier,恢复数据处理。下游算子收到 barrier 之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向 CheckpointCoordinator 报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。每个算子按照步骤 3 不断制作快照并向下游广播,直到最后 barrier 传递到 sink 算子,快照制作完成。当 CheckpointCoordinator 收到所有算子的报告之后,认为该周期的快照制作成功;否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
智能推荐
物联网与大数据(三)从大数据看物联网_物联网与最大数据-程序员宅基地
文章浏览阅读3.9k次。前言物联网、大数据、人工智能是近几年经常相提并论的概念。每一个概念背后都涵盖了丰富的技术和应用,三者各有特点,也互有重叠,甚至还有依赖。物联网侧重于让物体联网,形成万物互联的局面,这是物理世界深刻的数字化过程,必然带来大量的数据,并且是各种类型的数据;大数据不仅在于数据量大,更在于数据的维度复杂,它们来自于真实世界、可在线访问,并且对真实世界有独特的指导作用(价值);人工智能是指通过机器学习算法,让机器能够具备人类的智能特征,可以完成一些通常需要人类智能才能完成的复杂工作,甚至比人类完成得更好。._物联网与最大数据
普林斯顿大学计算机科学研究生条件,普林斯顿大学计算机科学硕士专业-程序员宅基地
文章浏览阅读97次。普林斯顿大学计算机科学硕士专业接受初级和高级研究生的学习和研究,程足够灵活,可以适应个人的学习和研究计划。入学最初为工程科学硕士,可选择转到工程硕士。学生选择一个计算机科学的分区来集中他们的课程,必须保持B平均分。普林斯顿大学计算机科学硕士专业课程设置1编程语言Programming Languages2理论机器学习Theoretical Machine Learning3关于软件的自动推理Aut..._普林斯顿大学计算机学术研究
解决pyqt5中self.sender()无法获取到控件名称的问题_self.sender()-程序员宅基地
文章浏览阅读4.7k次,点赞6次,收藏10次。第一次写csdn,小白一个,和大家分享一个今天遇到的问题。我遇到一个问题就是自己在使用qt designer写了一个小功能程序之后,然后将ui文件转换为py文件然后我的控件中有一个槽函数需要被多个按钮所响应,而且我还需要分辨出到底是哪个按钮所按的,所以我就查找有没有什么方法能够解决这个问题,开始使用的是传参的方法QPushButton.clicked.connect(lambda:self.信号槽方法) 然后在槽函数中对传过来的参数进行判断就可以了。 其实已经能够解决我的问题了,但是感觉肯._self.sender()
vue 使用 three.js 展示3D模型 gltf glb fbx_vue three3d fbx-程序员宅基地
文章浏览阅读1.3k次,点赞5次,收藏5次。vue 使用 three.js 展示3D模型 gltf glb fbx_vue three3d fbx
python 多进程实现文件下载传输_python多进程tcp文件下载-程序员宅基地
文章浏览阅读3.6k次。需求: 实现文件夹拷贝功能(包括文件内的文件),并打印拷贝进度模块: 利用 os模块 multiprocessing 模块import multiprocessingimport osdef deal_file(old_dir,new_dir,file_name,queue): # 打开以存在文件 old_file = open(os.path.join(old_dir,f_python多进程tcp文件下载
回归统计在 echarts 中的实现---在散点图中加趋势线_echarts散点图 怎么添加趋势线-程序员宅基地
文章浏览阅读1.6w次,点赞6次,收藏24次。回归统计在 echarts 中的实现贵在随心关注0.52019.03.13 13:55字数 432阅读 483评论 0喜欢 3在做数据的统计的时候,难免会涉及到线性拟合问题,也就是回归统计问题。接下来我们看看回归算法如何把数据分析与echarts 图表结合的.这里我们需要借助 echarts 的一个扩展库: echarts-stat.jsecStat 是EChart..._echarts散点图 怎么添加趋势线
随便推点
FreeRTOS移植详解-程序员宅基地
文章浏览阅读987次,点赞8次,收藏8次。以上即是本次的内容。我也是第一次使用RTOS,如有错误的,欢迎大家讨论交流。完整的代码我已经打包上传到我的博客,欢迎大家使用其作为自己的模板。当然最好是能自己建一个自己的模板,起码对移植中的bug有点了解,有利于更好理解RTOS。
【Linux从入门到放弃】冯诺依曼体系机构、操作系统及管理的本质_冯诺依曼机构-程序员宅基地
文章浏览阅读1.1k次,点赞44次,收藏51次。在学习linux的过程中,有一个特别重要的知识点就是关于进程的学习,那么在学习进程之前,首先对硬件做一些了解,然后再学习软件,在软硬件都学完之后再取去了解进程的概念。以上就是在学习进程之前该了解的一些知识,主要明白操作系统管理的本质,而这个本质也是始终贯穿于Linux的整个学习。_冯诺依曼机构
python串口数据采集 保存_python 中Arduino串口传输数据到电脑并保存至excel表格-程序员宅基地
文章浏览阅读1.8k次。起因:学校运河杯报了个项目,制作一个天气预测的装置。我用arduino跑了BME280模块,用蓝牙模块实现两块arduino主从机透传。但是为了分析,还需要提取出数据。因此我用python写了个上位机程序,用pyserial模块实现arduiho和电脑的串口通讯,再用xlwt模块写入excel表格,用time模块获取时间作为excel的文件名。 import xlwtimport timeimpo..._python串口数据采集并保存
2023最新快手H5红包互换源码免公众号快手版+对接支付/附带教程-程序员宅基地
文章浏览阅读973次。9./www/wwwroot7bn.sfgsfgrs.press/extend/DiDiPay/Config.php修改成自己的支付地址 20行 25行 商户ID和密钥。/www/wwwroot7bn.sfgsfgrs.press/extend/EPay/Config.php修改一下修改成自己的支付地址。下载链接:https://pan.baidu.com/s/1bgazfGLuNCgkvLVDNxcj4w?原文来自:阿里源码http://www.alym.cn。2.创建网站 运行目录选择public。_红包互换源码
Linux的学习之路:6、Linux编译器-gcc/g++使用-程序员宅基地
文章浏览阅读1k次,点赞28次,收藏31次。本文主要是说一些gcc的使用,g++和gcc使用一样就没有特殊讲述。目录摘要一、背景知识二、gcc如何完成1、预处理(进行宏替换)2、编译(生成汇编)3、汇编(生成机器可识别代码4、链接(生成可执行文件或库文件)5、函数库6、静态库和动态库7、gcc选项三、思维导图。
计算机启动一下就停机,电脑主机亮一下就灭了,电脑开机3秒就循环重启怎么办...-程序员宅基地
文章浏览阅读2.4w次。故障现象一:我的电脑主机开不了机了,一直灯亮一下就灭了,不停的电脑开机3秒就循环重启怎么办?解决方法一:电脑主机先是启动困难,一般是电源或主板的问题,先尝试用相同型号的电源替换,如果一样,主板问题,需要维修。替换后正常就是电源问题。再就是键盘不亮,显示器也没显示,这种情况是主板没有正常启动。1,如果电源灯不亮,更换开关电源。2,如果更换后还是一样,主板问题,如果电源灯亮,但不能开机,关机,取出内存..._电脑主机启动一下又灭一直反复