LR(0)分析表的构建_lr分析表-程序员宅基地
技术标签: 编译原理(C) LR(0)分析表 源代码 编译原理
LR(0)分析表的构建
一、实验要求
构建LR(0)分析表
例:
G[E]:
E->aA
E->bB
A->cA
A->d
B->cB
B->d
二、实验原理
在网上找了好久,发现大多数都是概念和复杂公式,
因此为了使大家能够更好的理解LR(0)分析表的构建,我准备举一个例子进行详细解析,一步步进行分析,直到最后画出分析表。
文法:
E->aA
E->bB
A->cA
A->d
B->cB
B->d
- 给初始符再构建一个初始符E’->E(I0)
- 为该初始符加上 . . .,变成E’->.E
- 查看小圆点后字符是否为非终结符,是,将左部为该非终结符的文法加入其中,并为其添加小圆点;反之进行下一步。(I0变成E’->.E E->.aA E->.bB)
- 对I项目中的文法进行分析,若小圆点在最后,则不做处理;若小圆点不在最后,则将根据每个文法的小圆点后的字符来开辟出新的I项目,该文法为新项目的首句文法(I0的文法进行开辟,I0不变,生成I1、I2和I3,I1:E’>.E I2:E->.aA I3:E->.bB),然后将新开辟项目的文法小圆点向后移一位(I1:E’>E. I2:E->a.A I3:E->b.B)。注:若开辟的项目和重复,则不进行开辟,再次利用已存在的项目)
- 对开辟的项目重复3-4步骤,直到不再有项目开辟
具体结果请见下图
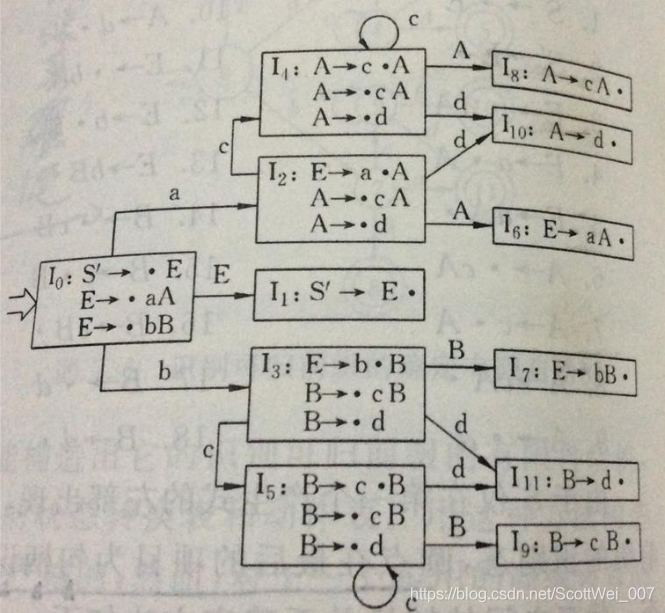
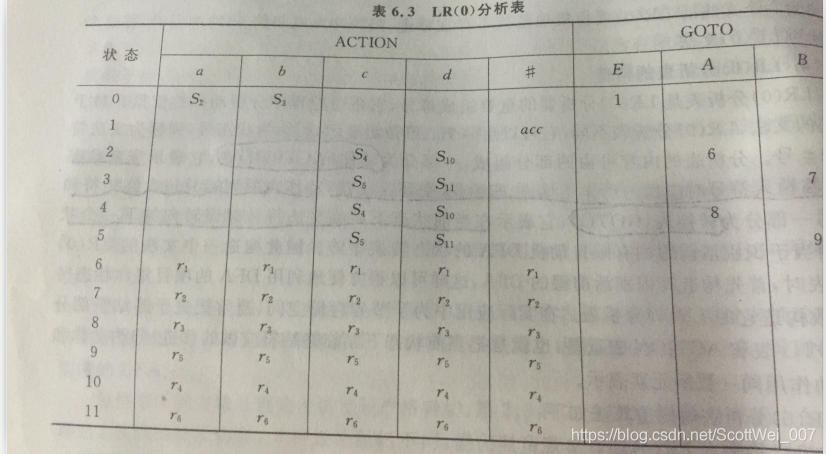
6.然后根据上图,构建出相应的分析表
三、算法设计
- 设计字符串存储文法,采用结构体存储生成的项目以及项目的去向
- 为项目0赋予新的初始符,并添加小圆点
- 判断小圆点后的字符:
若为终结符,进行下一步;若为非终结符,将该非终结符为左部的文法加入该项目当中,并为其添加小圆点。 - 判断小圆点位置:
若在该句文法最后,则进行下一步;反之,开辟新的项目,该句文法为新项目的首句文法,并将新项目文法的小圆点后移一位
注:若开辟的项目中文法和已有的项目重复,则该文法不进行开辟,再次利用已存在的项目。 - 重复执行3-4,直到不再有新的空间开辟出来。
四、模块设计
- 变量定义
char str[10][10];//存储文法
int n;//存储文法行数
int v=0;//存储生成项的个数
char r[20][10];//存储分析表的float值
int rr[20][10];//存储分析表的int值
struct DFA{
int num;//记录生成项的序号
int c[10];//存储该项目各个文法的去向(子代)
int f;//记录该项目的来源(父代)
char ss[10][10];//存储该项的文法
int count;//记录该项的文法行数
int l;//存储第一行字符串'.'的位置
}LR[20];
- 输入模块
从键盘输入上下文无关文法,存储到char类型的字符串数组当中
//初始化,输入上下文无关文法,以#号结尾
void Init(){
int i,j;
cout<<"输入上下文无关文法:"<<endl;
for(i=1;;i++){
cin>>str[i];
if(str[i][0]=='#')
break;
}
strcat(str[0],"Z->");
str[0][3]=str[1][0];
n=i+1;
}
我在源代码里还附录了一个输入模块的代码,因为那个是直接将文法输入到字符串中,这样就可减少在进行测试时重复输入文法的时间。
即:
//在一开始编程时可先给定文法,避免每次测试重复输入
void input(){
int i,j;
strcat(str[0],"Z->E");
strcat(str[1],"E->aA");
strcat(str[2],"E->bB");
strcat(str[3],"A->cA");
strcat(str[4],"A->d");
strcat(str[5],"B->cB");
strcat(str[6],"B->d");
n=7;
for(i=0;i<n;i++)
cout<<str[i]<<endl;
cout<<"***************************"<<endl;
}
-
LR(0)规范集构建模块
进行算法分析中第2、3、4三步,记住几个关键点,小圆点位置、小圆点后的字符、项目的开辟(递归)
当中为使测试方便,调用了几个子函数
以下只附录子函数代码,具体请看最后源代码
设置小圆点位置 -
输出模块
将生成的项目以分析表的形式得出,因水品有限,采用的是cout结合二维数组进行输出,代码较多,主要是为了使得输出的格式更加的整齐。
这部分就不重复贴出代码,大家请从源代码里查看。
- 设置小圆点位置
//为文法添加小数点
void AddD(int a,int b){//为LR[a]的ss第b行字符串添加'.'
int i,j=0;
char c[10];
for(i=0;i<3;i++)
c[j++]=LR[a].ss[b][i];
c[3]='.';
j++;
for(i=3;i<strlen(LR[a].ss[b]);i++)
c[j++]=LR[a].ss[b][i];
memset(LR[a].ss[b],0,sizeof(LR[a].ss[b]));
for(i=0;i<j;i++)
LR[a].ss[b][i]=c[i];
}
- 添加移进项目的文法
//添加移进项目的文法
void AddG(int a,char s){//把str文法中左部非终结符与s相同的文法,添加进LR[a]中
int i,j,k;
for(i=0;i<n;i++){
if(str[i][0]==s){
for(j=0;j<strlen(str[i]);j++)
LR[a].ss[LR[a].count][j]=str[i][j];
AddD(a,LR[a].count);
LR[a].count++;
}
}
}
- 小圆点后移一位
//将文法小圆点向后移一位
void add(int a,int j){
int i,k;
char temp;
for(i=0;i<strlen(LR[a].ss[j]);i++){
LR[v].ss[0][i]=LR[a].ss[j][i];
if(LR[a].ss[j][i]=='.')
k=i;//记录小圆点的位置
}
LR[a].c[j]=v;//记录该条文法的跳转(子)项数
LR[v].f=a;//记录跳转项数的来源(父代)
LR[v].count++;
temp=LR[v].ss[0][k+1];//小圆点向后移一位
LR[v].ss[0][k+1]=LR[v].ss[0][k];
LR[v].ss[0][k]=temp;
LR[v].l=k+1;//记录小圆点的位置
}
- 更新项目的上一项(父代)和下一项(子代)
//更新某一项的来源(父代)和每一句文法的跳转项(子代)
void fix(int a,int b){
int i,j,k;
k=LR[b].f;//父代
for(i=0;i<LR[k].count;i++)
if(LR[k].c[i]==b)
LR[k].c[i]=a;//子代
}
- 删除相同的项目
//比较,删除相同的内容
void Compare(int a){
int i,j,k;
for(i=0;i<a;i++){
for(j=i+1;j<=a;j++){
if(strcmp(LR[i].ss[0],LR[j].ss[0])==0){//若相同
fix(i,j);
memset(LR[j].ss,0,sizeof(LR[j].ss));//靠后的文法内容清空
LR[j].count=0;
}
}
}
}
- 主函数
//主函数
int main(){
Init();;//输入上下文无关文法
//input();//输入上下文无关文法
gfj();//规范集的构建
Output();//输出分析表
}
5、结果展示
- 首先编译运行
- 然后输入上下文无关文法,以#键结尾
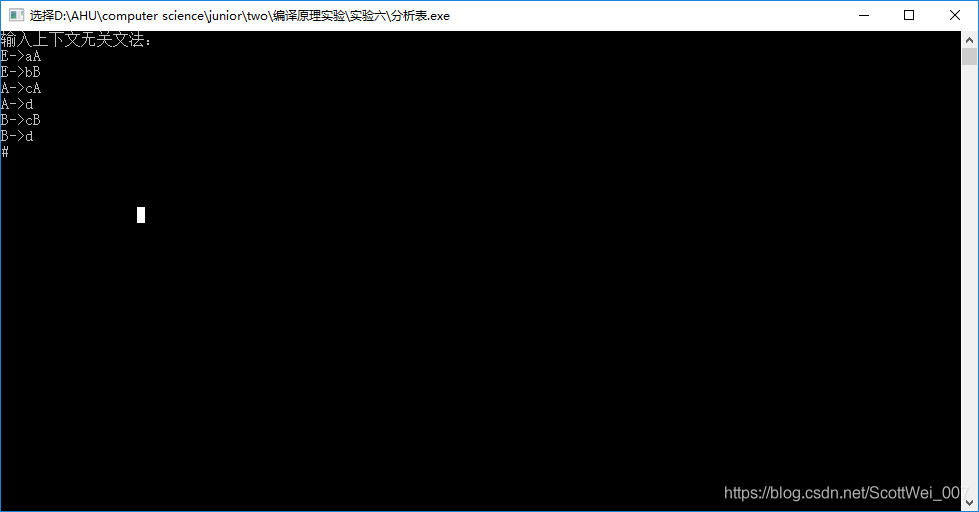
3.然后回车获得结果
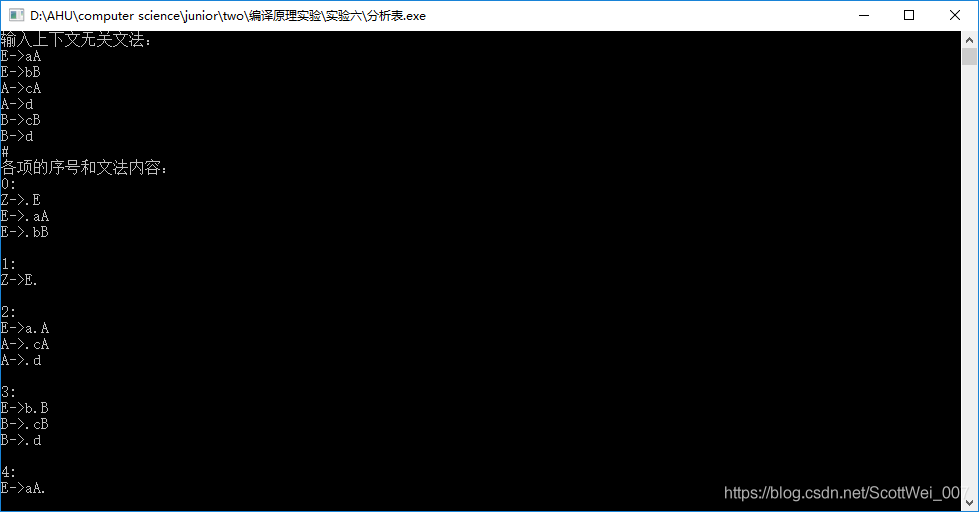
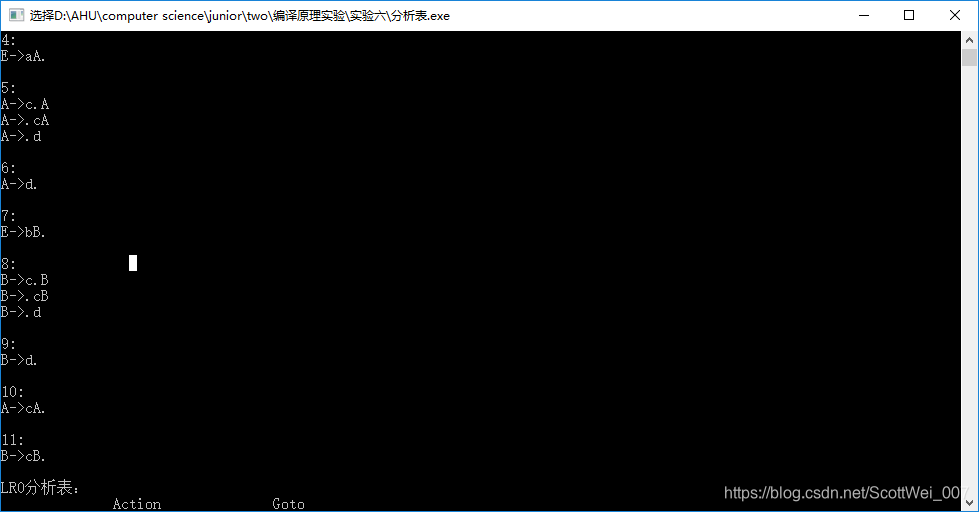
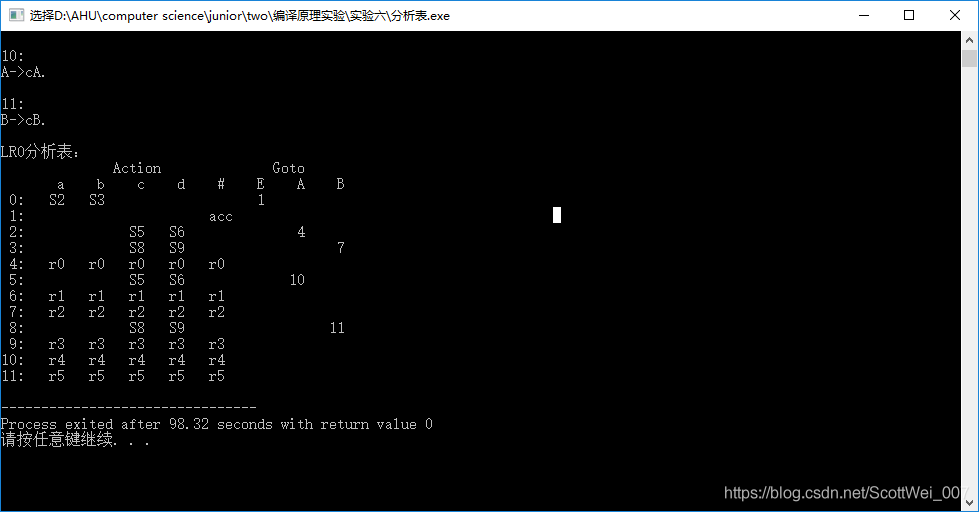
6、源代码
源代码已经过编译,可直接使用。代码都有详细的注释,大家碰到任何问题都可以留言,一起讨论。
#include<iostream>
#include<iomanip>
#include<string.h>
using namespace std;
char str[10][10];//存储文法
int n;//存储文法行数
int v=0;//存储生成项的个数
char r[20][10];//存储分析表的float值
int rr[20][10];//存储分析表的int值
struct DFA{
int num;//记录生成项的序号
int c[10];//存储该项的上一项位置
int f;//记录
char ss[10][10];//存储该项的文法
int count;//记录该项的文法行数
int l;//存储第一行字符串'.'的位置
}LR[20];
//初始化,输入上下文无关文法,以#号结尾
void Init(){
int i,j;
cout<<"输入上下文无关文法:"<<endl;
for(i=1;;i++){
cin>>str[i];
if(str[i][0]=='#')
break;
}
strcat(str[0],"Z->");
str[0][3]=str[1][0];
n=i+1;
}
//在一开始编程时可先给定文法,避免每次测试重复输入
void input(){
int i,j;
strcat(str[0],"Z->E");
strcat(str[1],"E->aA");
strcat(str[2],"E->bB");
strcat(str[3],"A->cA");
strcat(str[4],"A->d");
strcat(str[5],"B->cB");
strcat(str[6],"B->d");
n=7;
for(i=0;i<n;i++)
cout<<str[i]<<endl;
cout<<"***************************"<<endl;
}
//为文法添加小数点
void AddD(int a,int b){//为LR[a]的ss第b行字符串添加'.'
int i,j=0;
char c[10];
for(i=0;i<3;i++)
c[j++]=LR[a].ss[b][i];
c[3]='.';
j++;
for(i=3;i<strlen(LR[a].ss[b]);i++)
c[j++]=LR[a].ss[b][i];
memset(LR[a].ss[b],0,sizeof(LR[a].ss[b]));
for(i=0;i<j;i++)
LR[a].ss[b][i]=c[i];
}
//添加移进项目的文法
void AddG(int a,char s){//把str文法中左部非终结符与s相同的文法,添加进LR[a]中
int i,j,k;
for(i=0;i<n;i++){
if(str[i][0]==s){
for(j=0;j<strlen(str[i]);j++)
LR[a].ss[LR[a].count][j]=str[i][j];
AddD(a,LR[a].count);
LR[a].count++;
}
}
}
//将文法小圆点向后移一位
void add(int a,int j){
int i,k;
char temp;
for(i=0;i<strlen(LR[a].ss[j]);i++){
LR[v].ss[0][i]=LR[a].ss[j][i];
if(LR[a].ss[j][i]=='.')
k=i;//记录小圆点的位置
}
LR[a].c[j]=v;//记录该条文法的跳转(子)项数
LR[v].f=a;//记录跳转项数的来源(父代)
LR[v].count++;
temp=LR[v].ss[0][k+1];//小圆点向后移一位
LR[v].ss[0][k+1]=LR[v].ss[0][k];
LR[v].ss[0][k]=temp;
LR[v].l=k+1;//记录小圆点的位置
}
//更新某一项的来源(父代)和每一句文法的跳转项(子代)
void fix(int a,int b){
int i,j,k;
k=LR[b].f;//父代
for(i=0;i<LR[k].count;i++)
if(LR[k].c[i]==b)
LR[k].c[i]=a;//子代
}
//比较,删除相同的内容
void Compare(int a){
int i,j,k;
for(i=0;i<a;i++){
for(j=i+1;j<=a;j++){
if(strcmp(LR[i].ss[0],LR[j].ss[0])==0){//若相同
fix(i,j);
memset(LR[j].ss,0,sizeof(LR[j].ss));//靠后的文法内容清空
LR[j].count=0;
}
}
}
}
//LR(0)规范集的构建
void gfj(){
int i,j,k,p;
for(i=0;i<20;i++){
LR[i].num=i;//Ii
if(i==0){//第一个,赋予文法的初始符Z->E
for(k=0;k<strlen(str[0]);k++)
LR[0].ss[0][k]=str[0][k];
AddD(0,LR[0].count);//添加小圆点 Z->.E
LR[0].l=3;//小圆点的位置
LR[0].count++;//文法数目+1
if(LR[i].ss[0][4]>='A'&&LR[i].ss[0][4]<'Z')
AddG(i,LR[i].ss[0][4]);//添加移进项目的文法E->aA E->bB
v++;
//为每一个文法进行向外扩散 I1、I2、I3
for(j=0;j<LR[0].count;j++){
p=strlen(LR[0].ss[j]);
if(LR[0].ss[j][p-1]!='.'){
add(0,j);//将向外扩散的文法小圆点向后移一位
v++;
}
}
}
else{//除I0以外的生成项
p=strlen(LR[i].ss[0]);//Ii第一句文法的长度
if(LR[i].count==1&&LR[i].ss[0][p-1]=='.'){//若小圆点再最后则不进行处理
}
else{
p=LR[i].l;//小圆点的位置
if(LR[i].ss[0][p+1]>='A'&&LR[i].ss[0][p+1]<'Z')
AddG(i,LR[i].ss[0][p+1]);//添加移进项目的文法
//为每一个文法进行向外扩散
for(j=0;j<LR[i].count;j++){
add(i,j);//将待向外扩散的文法小圆点向后移一位
v++;
}
}
Compare(i);//对所有已生成的项进行比较,若有重复的则删除i值靠后的
}
}
//将生成的项进行整理,补齐有缺的部分(删除重复的之后可能会有内容为空,从后面补齐)
for(i=0;i<20;i++){
for(j=i+1;j<20;j++){
if(LR[i].count==0&&LR[j].count!=0&&LR[i].num<LR[j].num){
fix(i,j);
LR[i]=LR[j];
LR[j].count=0;
}
}
}
//对当前的生成项进行编号
for(i=0;LR[i].count!=0;)
i++;
v=i;
//输出当前生成项及各项的文法
cout<<"各项的序号和文法内容:"<<endl;
for(i=0;i<v;i++){
cout<<i<<":"<<endl;
for(j=0;j<LR[i].count;j++)
cout<<LR[i].ss[j]<<endl;
cout<<endl;
}
}
//分析表根据第一行进行匹配处理
void match(int a,int b){
int i,j;
char k;
if(b==0&&LR[a].count==1&&strlen(LR[a].ss[b])-1==LR[a].l){//若是终结文法 (即小圆点在最后)
if(LR[a].ss[b][0]=='Z')//且是初始符终结
strcpy(r[a+1],"acc");
else
for(i=0;i<5;i++)//Action都输出r
r[a+1][i]='r';
}
else{//不是终结文法,k储存小圆点后一个字符,进行比较判断
if(b==0)
k=LR[a].ss[b][LR[a].l+1];
else
k=LR[a].ss[b][4];
for(i=0;i<strlen(r[0]);i++){
if(r[0][i]==k)
rr[a+1][i]=LR[a].c[b];
}
}
}
//进行分析表的构建和输出
void Output(){
int i,j,k,temp;
strcpy(r[0],"abcd#EAB");//分析表的第一行
cout<<"LR0分析表:"<<endl;
cout<<setw(20)<<"Action"<<setw(18)<<"Goto"<<endl;
//分析表根据第一行进行匹配
for(i=0;i<v;i++){
for(j=0;j<LR[i].count;j++)
match(i,j);//进行匹配处理
}
//进行分析表输出形式的处理
for(i=0;i<v+1;i++){
temp=0;
//保证输出对其
if(i==0)
cout<<" ";
if(i>0&&i<=10)
cout<<" "<<i-1<<":";
if(i>10)
cout<<i-1<<":";
if(strcmp(r[i],"acc")==0)
cout<<setw(24);
//先输出Action部分
for(j=0;j<5;j++){
if(r[i][j]=='r'){//输出终结文法
cout<<setw(4)<<r[i][j]<<k;
temp=1;
}
else if(strcmp(r[i],"acc")==0)//输出起始符的终结欸文法
cout<<r[i][j];
else{
if(i==0)
cout<<setw(5)<<r[i][j];
else if(rr[i][j]==0)
cout<<setw(5)<<" ";
else
cout<<setw(4)<<"S"<<rr[i][j];
}
}
if(temp==1)
k++;//进行对r1、r2、r3等下标的处理
//再输出Goto部分
for(j=5;j<strlen(r[0]);j++){
if(i==0)
cout<<setw(5)<<r[i][j];
else if(rr[i][j]==0)
cout<<setw(5)<<" ";
else
cout<<setw(5)<<rr[i][j];
}
cout<<endl;
}
}
//主函数
int main(){
int i,j;
Init();
//input();//输入上下文无关文法
gfj();//规范集的构建
//Excels();
Output();//输出分析表
}

智能推荐
oracle voting disk 大小,2.Oracle Voting Disk 管理-程序员宅基地
文章浏览阅读178次。Oracle Voting Disk 管理2018-01-17 Oracle 宅必备上节介绍运行集群环境所需的进程,这节总体上说Oracle集群的安装,升级以及克隆等Oracle Clusterware 包含了2个重要的组件用来管理配置和节点成员,分别是Oracle Cluster Registry (OCR)以及voting disks,其中OCR还包含一个本地的组件Oracle Local R..._oracle asm vote disk 大小
nginx 404会执行302跳转-程序员宅基地
文章浏览阅读1k次。这个问题是应用中比较常见的一个问题了。尤其是对于静态文件,一般而言在nginx中会利用error_page指令对一些错误吗指定错误页。此时,如果请求命中了改规则,就会跳转的响应的页面。比如:error_page 400 404 500 'http://xxx.error.html';上述的命令会导致302或301跳转。 一般的网站为了节省流量或者提高响..._nginx 404 转302
nginx 增加 lua模块-程序员宅基地
文章浏览阅读254次。Nginx中的stub_status模块主要用于查看Nginx的一些状态信息.本模块默认是不会编译进Nginx的,如果你要使用该模块,则要在编译安装Nginx时指定:./configure –with-http_stub_status_module 这个模块如果需要也可以加入######################### 下面是 lua模块unkno..._unknown directive "access_by_lua
大语言模型下载,huggingface和modelscope加速_modelscope下载 huggingface-程序员宅基地
文章浏览阅读1.1k次,点赞8次,收藏11次。大模型下载速度较快的方式,huggingface,modelscope_modelscope下载 huggingface
Gson [Maven依赖] 和一些简单的例子_gson maven依赖-程序员宅基地
文章浏览阅读4.3w次,点赞9次,收藏15次。Mavne依赖<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.2.4</version></dependency>G_gson maven依赖
2024年美国大学生数学建模竞赛思路与源代码【2024美赛A题】_2024年美赛a题-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏15次。幼体的生长速度生长速度受到食物供应的影响。在食物供应较少的环境中、生长速度就会降低,雄性海灯鱼的比例可达到78%左右。在食物更容易获得的环境中,雄性的百分比据观察,雄性约占种群的56%。尽管许多物种在出生时的性别比例为1:1,但其他物种物种则偏离了均匀的性别比例。例如美洲鳄孵卵巢的温度会影响其出生时的性别比例。我们的任务是研究一个物种能够根据资源供应情况改变性别比例的利弊。灯鱼的作用十分复杂。而在世界上的一些地区,如斯堪的纳维亚半岛、波罗的海地区,以及太平洋地区的一些土著居民眼中,灯鱼也是一种食物来源。_2024年美赛a题
随便推点
关于JVM-三色标记算法剖析-程序员宅基地
文章浏览阅读424次。白色:表示对象未被垃圾收集器访问过,这是可达性分析开始的阶段,所有的对象都是白色,如果分析结束阶段,还是白色,即代表不可达。灰色:表示对象被垃圾收集器访问过,但是至少还有一个引用没有被扫描过。黑色:表示对象已被垃圾收集器访问过了,并且这个对象所有对象都被扫描过了,它是安全存活的,如果有其它对象引用指向了黑色对象,无须重新扫描一遍。黑色对象不可能直接指向某个白色对象。
如何快速调出软键盘_天生我材必有用 | 如何快速的计算和调用防火阀、调节阀、铝合金风口等材料价格...-程序员宅基地
文章浏览阅读291次。应用场景:在项目中,通常会遇到防火阀、调节阀、铝合金风口等材料,已知其规格尺寸,需要通过计算公式,得出其价格,如下表所示。在品茗胜算软件里,在“工料汇总”界面调用我材助手,找到对应材料,点击“风阀风口”,软件内置了计算公式,自动读取规格尺寸,自动算出价格,点击“应用价格”,价格就直接应用到项目中了,省去了翻找公式、敲计算器的时间。当然也可以点击“扫描件”,调出当期这些材料的计算公式。如果..._品茗计价中风口信息价换算在哪里
设计模式系列-第二章(设计原则-SOLID)_设计模式第二章完整代码-程序员宅基地
文章浏览阅读108次。前言:SOLID 原则并非单纯的 1 个原则,而是由 5 个设计原则组成的,它们分别是:单一职责原则、开闭原则、里式替换原则、接口隔离原则和依赖反转原则,依次对应 SOLID 中的 S、O、L、I、D 这 5 个英文字母。一、单一职责原则(SRP) 单一职责原则的英文是 Single Responsibility Principle,缩写为 SRP。一个类或者模块只负责完成一个职责(或者功能)。单一职责原则是为了实现代码高内聚、低耦合,提高代码的复用性、可读性、可维护性。单一职责原则通过..._设计模式第二章完整代码
mysql-workbench双击后无法启动解决方案_workbench双击无反应-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏8次。好久没更新了 这个问题我遇到了两次,一次是腾讯云服务器上,一次是我的电脑上,都是安装后点mysql-workbench没有任何反应。网上别的解决方案我就不说了,要是好使你们也不会找到这里。**很简单!你们首先去mysql-workbench得安装目的地哪里,找到这个东西**双击它!看看是不是这个结果然后去下载这个.dll文件之后把这个文件放到C:\Windows\System32 ..._workbench双击无反应
spoj8222 Substrings (后缀自动机)_spoj 8222-程序员宅基地
文章浏览阅读379次。spoj8222 Substrings题意:f[x]表示所有长度为 x 的子串中,出现次数的最大值。求所有f[x]方法:建立SAM,根据拓扑序找到长度为 x 的子串个数,更新一下就行了#include <stdio.h>#include <string.h>#define N 250010char str[N];int root,cnt=0,n,last..._spoj 8222
ERP系统之比较——SAP Oracle BAAN JDE SSA_jjdssap-程序员宅基地
文章浏览阅读1.1k次。ERP系统之比较——SAP Oracle BAAN JDE SSA_jjdssap