欠拟合、过拟合现象,及解决办法_svm过拟合怎么解决-程序员宅基地
@创建于:2022.05.27
@修改于:2022.05.27
文章目录
1、过拟合与欠拟合
机器学习中模型的泛化能力强的模型才是好模型。对于训练好的模型:
- 若在训练集表现差,不必说在测试集表现同样会很差,这可能是欠拟合导致;
- 若模型在训练集表现非常好,却在测试集上差强人意,则这便是过拟合导致的。
过拟合与欠拟合也可以用 Bias 与 Variance 的角度来解释:
- 欠拟合会导致高 Bias
- 过拟合会导致高 Variance
所以模型需要在 Bias 与 Variance 之间做出一个权衡。
| 现象 | 训练集表现 | 验证集表现 | 导致后果 |
|---|---|---|---|
| 欠拟合 | 不好 | 不好 | 高 Bias |
| 过拟合 | 好 | 不好 | 高 Variance |
| 适度拟合 | 好 | 好 | Bias 和 Variance 的折中 |
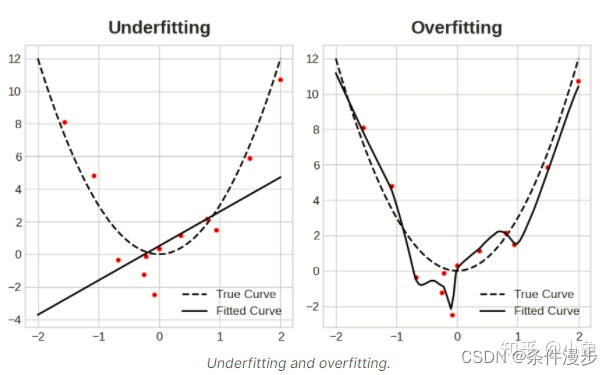
2、欠拟合
2.1 出现的原因
使用的模型复杂度过低
使用的特征量过少
【其他的,如果您知道,请告诉我!感谢】
2.2 解决的办法
1、对于机器学习
- 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数
- 使用非线性模型,比如核SVM 、决策树、深度学习等模型
- 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力。对于神经网络,这在很大程度上取决于它有多少神经元以及它们如何连接在一起。
- 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging
2、对于深度学习
欠拟合的原因以及解决办法(深度学习)
- 对原始数据做归一化处理,这个会加速模型的收敛
- 减少使用正则化,减少的dropout
- 增加单层的神经元个数,加深网络层次
- 正确使用激活函数
3、过拟合
3.1 出现的原因
1、对于机器学习
-
建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则
-
样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则
-
假设的模型无法合理存在,或者说是假设成立的条件实际并不成立
参数太多,模型复杂度过高 -
对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集
2、对于神经网络模型
- a)对样本数据可能存在分类决策面不唯一,随着学习的进行,BP算法使权值可能收敛过于复杂的决策面;
- b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征
3.2 解决的办法
- 正则化(Regularization)(L1和L2)
- 数据扩增,即增加训练数据样本(Data augmentation)
- Dropout
- Early stopping
- 降低模型复杂度
- 使用交叉验证
4. Early stopping
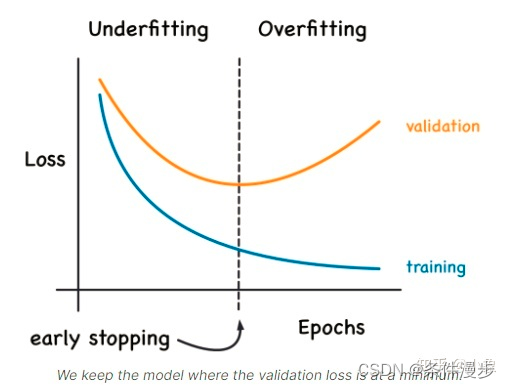
在训练期间验证损失(validation loss)可能会开始增加,为了防止这种情况,在验证损失(validation loss)不再减少时停止训练。以这种方式中断训练称为early stopping。
一旦检测到验证损失开始再次上升,可以将权重重置为最小值出现的位置。这可确保模型不会继续学习噪声和过度拟合数据。
提前停止训练也意味着不太可能在网络完成学习信号之前过早停止训练。所以除了防止过拟合训练时间过长之外,提前停止还可以防止欠拟合训练时间不够长。只需将您的训练时期设置为一个较大的数字(比您需要的多),早期停止将处理其余部分。
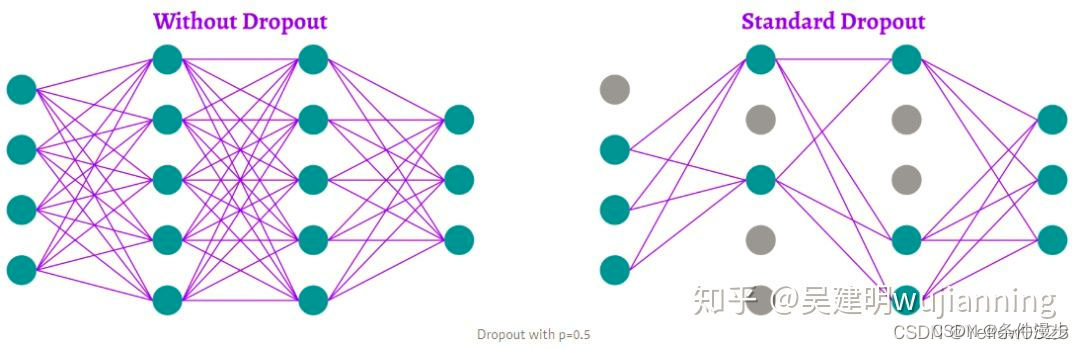
5、Dropout
深度学习入门五----Dropout and Batch Normalization
过拟合的原因以及解决办法(深度学习)
在训练的每一步随机丢弃层输入单元的一部分,使网络更难学习训练数据中的那些虚假模式。相反,它必须搜索广泛的、通用的模式,其权重模式往往更加稳健。
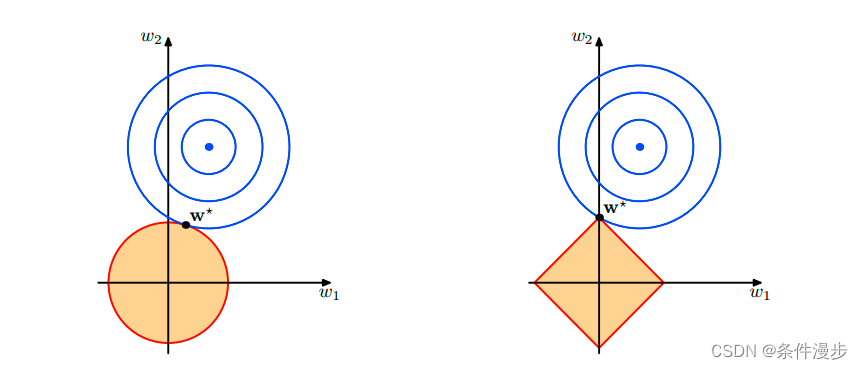
6、L1 和 L2 正则化
L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解(0比较多)。L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),但是同样能够保证解中接近于0(但不是等于0,所以相对平滑)的维度比较多,降低模型的复杂度。
7、参考资料
机器学习防止欠拟合、过拟合方法
欠拟合和过拟合出现原因及解决方案
深度学习入门四----过拟合与欠拟合
深度学习入门五----Dropout and Batch Normalization
智能推荐
阅读笔记-HTTP返回状态码-程序员宅基地
文章浏览阅读124次。HTTP返回状态码1 HTTP超文本协议HTTP是基于客户端/服务端(C/S)的框架模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。一个HTTP“客户端”是一个应用程序(Web浏览器或其他任何客户端),通过连接到服务器达到向服务器发送一个或多个HTTP请求的目的。一个HTTP“服务器”同样也是一个应用程序(通常是一个Web服务,如Apache Web服务器或IIS服务器..._nginx 请求头太大(nginx) nginx 内置代码和 431 类似。
算法:堆排序之每次输入插一次堆&输入完成后建堆_堆排序的过程中,每次进行堆调整后,打印输出堆的次序-程序员宅基地
文章浏览阅读576次。1./*Name:插入堆排序(A[0]为空情况)Coder:Lou JianghuiTime:22:49-23:07*/#include#include#includeusing namespace std;int A[1000];int n;void print(int n){ for (int i = 1;_堆排序的过程中,每次进行堆调整后,打印输出堆的次序
【HLL】使用 HyperLogLog 去重案例_hyperloglog可以处理带重复元素的流数据吗-程序员宅基地
文章浏览阅读695次。1.概述HyperLogLog一个常用的场景就是统计网站的UV。##基数 简单来说,基数(cardinality,也译作势),是指一个集合(这里的集合允许存在重复元素)中不同元素的个数。例如看下面的集合: {1,2,3,4,5,2,3,9,7} 这个集合有9个元素,但是2和3各出现了两次,因此不重复的元素为1,2,3,4,5,9,7,所以这个集合的基数是7。maven <dependency> <groupId>net.agkn</grou._hyperloglog可以处理带重复元素的流数据吗
Navicat模型中的表展示注释的方法_navicat在表对象界面显示表的备注-程序员宅基地
文章浏览阅读1.2w次,点赞3次,收藏8次。先展示下效果图:Navicat不能直接将注释展示在表模型上,需要曲线救国。展示表的中文名方法:选中画布上的一个表模型,然后在左侧的图表页签中将“显示描述”勾选中,表模型上方会自动出现一个描述框,选中描述框右键选择编辑,填写表的中文名即可。展示表字段对应的中文名的方法:选择左侧的新建笔记,然后右键选中笔记,选择样式为标签,对应表字段顺序输入中文名称,最后将标签调整到适当位置即可。标签的样式也可以通过左侧属性配置进行修改,比如间距,字体大小之类。..._navicat在表对象界面显示表的备注
推导部分和【蓝桥杯国赛】_推导部分和 带权并查集 蓝桥-程序员宅基地
文章浏览阅读141次。对于一个长度为N的整数数列A1A2⋯AN,小蓝想知道下标l到r的部分和il∑rAiAlAl1⋯Ar是多少?然而,小蓝并不知道数列中每个数的值是多少,他只知道它的M个部分和的值。其中第i个部分和是下标li到ri的部分和∑jliriAliAli1⋯Ari, 值是Si。_推导部分和 带权并查集 蓝桥
无名对象_class student{public:student(char* pname = "no nam-程序员宅基地
文章浏览阅读168次。代码:#include <iostream>#include <cstring> using namespace std;class Student{public:Student(char* pName="no name",int ssId=0){ strncpy(name,pName,40); name[39]='\0'; id = ssId; cout <&..._class student{public:student(char* pname = "no name"){strcpy(name, p
随便推点
spring数据源配置:Tomcat/weblogic数据源切换配置_tomcat 数据库切换-程序员宅基地
文章浏览阅读1.4k次。数据配置方式一般是三种:1.org.springframework.jdbc.datasource.DriverManagerDataSource(没有池概念,有连接就建立一个connection)2.org.apache.commons.dbcp.BasicDataSource(连接池技术)3.org.springframework.jndi.JndiObjectFactoryBea..._tomcat 数据库切换
计算机组成原理 之 计算题、分析题 题解详细总结(已完结)_计算机组成原理计算题-程序员宅基地
文章浏览阅读1.7w次,点赞62次,收藏544次。第1章 计算机系统概述0、1编码第2章 存储系统磁盘存储器第6章 控制器逻辑Intel 8086 指令简介第1章 计算机系统概述0、1编码1、分别求出+1111B和-1001B的真值及其机器数的原码、反码、补码形式。答案:+1111B的真值:15原码01111 反码01111 补码01111-1001B 的真值:-9原码11001 反码10110 补码10111另一种写法:解: +1111B 真值:15D [x]原=01111B [x]反=01111B [x]补=011._计算机组成原理计算题
react-native 0.57 版本更新日志-程序员宅基地
文章浏览阅读647次。[0.57]欢迎来到React Native版本的0.57版!这个版本解决了许多问题,并有一些令人兴奋的改进。我们再次跳过了一个月发布,通过扩展发布候选阶段关注质量,并且兼容之前的版本这个版本包括599提交由73个不同的贡献者!为了响应反馈,我们准备了一个只包含用户影响的更改的变更日志。请分享您的意见,并让我们知道我们如何使这更有用,如果您对此有任何反馈,和往常一样请告知我们let us kn..._react-native 0.57版本文档
【IDEA&Eclipse快捷键对照表】_eclipse的folder对应idea的哪个-程序员宅基地
文章浏览阅读4.6k次,点赞8次,收藏44次。IDEA Comment Eclipse Comment Remark Ctrl+Alt+H 调用层次 Ctrl+Alt+H 开放的调用层次结构 Ctrl+E 展示打开的文件(快速转换编辑器) Alt+7 当前文件结构 Ctrl+O 当前文件结构 Ctrl+H 查看Java类层次结构 Ctrl+....._eclipse的folder对应idea的哪个
修改pycharm目录后,无法打开的问题!!!_为什么修改已安装的pycharm的安装路径会打不开软件-程序员宅基地
文章浏览阅读2.1k次。最近因为一些操作,想将命名不规范的pycharm安装目录的空格删掉,但是删掉以后,发现pycharm怎么也打不开了。在将脑汁都绞尽以后,参考一篇博客,终于发现了问题所在https://blog.csdn.net/weixin_45696455/article/details/106414316在看了上面一篇博客后,谢谢哥,茅塞顿开,原来是我破解的.vmoption文件问题,里面写了破解包路径,一旦修改pycharm路径后,将无法找到该破解包。但当我在文件夹打开.vmoption文件以后,发现我并没有写破_为什么修改已安装的pycharm的安装路径会打不开软件
labview中visa插件安装教程_nivisa安装教程-程序员宅基地
文章浏览阅读2.2w次,点赞7次,收藏29次。1.在NI官网下载VISA,上一篇文章中已经讲到,此处不再赘述。2.关到电脑的所有杀毒软件,非常重要。3.点击运行。4.一直点击next,在需要更改安装目录时,自己更改(最好不要安装在C盘)。5.安装结束后,在最新安装目录下查找NI-MAX。可以直接将他拖动到桌面即可。打开后查看设备与接口若发现里面含有内容,则安装成功,如下图所示。..._nivisa安装教程