简析过拟合与欠拟合_过拟合和欠拟合图像-程序员宅基地
技术标签: 图像识别和分类
欠拟合与过拟合问题是机器学习中的经典问题,尽管相关的讨论和预防方法非常多,但目前在许多任务中仍经常会出现过拟合等问题,还没有找到一个十分通用、有效的解决方法。不过总体上看,现在人们常用的一些很简洁的方法基本上能够较好地解决欠拟合与过拟合问题,总结如下。
欠拟合与过拟合的概念的成因比较简单,观点统一,这里不再介绍。现在常用的判断方法是从训练集中随机选一部分作为一个验证集,采用K折交叉验证的方式,用训练集训练的同时在验证集上测试算法效果。在缺少有效预防欠拟合和过拟合措施的情况下,随着模型拟合能力的增强,错误率在训练集上逐渐减小,而在验证集上先减小后增大;当两者的误差率都较大时,处于欠拟合状态(high bias, low variance);当验证集误差率达到最低点时,说明拟合效果最好,由最低点增大时,处与过拟合状态(high variance, low bias)。下图的横坐标用拟合函数多项式的阶数笼统地表征模型拟合能力:
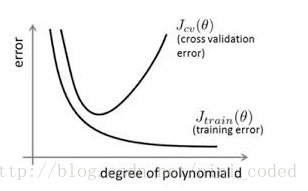
下面详细介绍预防解决模型欠拟合与过拟合的常用方法及原理:
欠拟合
因为对于给定数据集,欠拟合的成因大多是模型不够复杂、拟合函数的能力不够。
为此可以增加迭代次数继续训练、尝试换用其他算法、增加模型的参数数量和复杂程度,或者采用Boosting等集成方法。
过拟合
过拟合成因是给定的数据集相对过于简单,使得模型在拟合函数时过分地考虑了噪声等不必要的数据间的关联。或者说相对于给定数据集,模型过于复杂、拟合能力过强。方法如下:
1.数据扩增:
人为增加数据量,可以用重采样、上采样、增加随机噪声、GAN、图像数据的空间变换(平移旋转镜像)、尺度变换(缩放裁剪)、颜色变换、增加噪声、改变分辨率、对比度、亮度等。其中增加噪声,可以在原始数据上直接加入随机噪声(更接近真实环境),也可以在权重上增加噪声。
2.直接降低模型复杂度:
即减少模型参数数量。例如:对于LR,减少目标函数的因子数;对于DT,减少树的深度、剪枝等;对于DNN,减少层数和每层权向量长度。
3.针对神经网络,采用dropout方法:
间接减少参数数量,也相当于进行了数据扩增。弱化了各个参数(特征)之间的单一联系,使起作用的特征有更多组合,使从而模型不过分依赖某个特征。
4.提前停止训练:
也就是减少训练的迭代次数。从上面的误差率曲线图可以看出,理论上能够找到一个训练程度,此时验证集误差率最低,视为拟合效果最好的点。
5.多模型投票方法:
类似集成学习方法的思想,不同模型可能会从不同角度去拟合,互相之间取长补短,即使单独使用某个模型已出现过拟合,但综合起来却有可能减低过拟合程度,起到正则作用,提高了泛化效果。特别是使用多个非常简单的模型,更不容易产生过拟合。
以下是一系列常用的正则化方法:
秉承奥卡姆剃刀原理,许多正则化项(惩罚项)的引入,是为了使算法学习到更简单的模型,也就是让最终学习到的参数绝对值变小(即参数长度变短:shrinkage),因为这样可以让模型在较小的参数空间中搜寻最优参数,从而简化了模型。而且若sigmoid作为激活函数,当参数权值较小时,激活函数工作在线性区,此时模型的拟合能力较弱,也降低了过拟合的可能性。
从贝叶斯理论角度看,加入正则项相当于引入了一个参数的先验信息,即人为给参数的选择增加了一些规则(先验),把人们的知识数学化告诉给模型的损失函数,从而缩小了解空间倾向于产生唯一解,使拟合出错的概率变小,同时解决了逆问题的不适定性(多解问题)。不同的正则化项具有不同先验分布,具体介绍如下。
6.L0正则化:
损失函数后面加上在加入L0范数 λ||w||0,也就是权向量中非零参数的个数。
它的特点是可以实现参数的稀疏性,使尽可能多的参数值为0,这与稀疏编码的思想吻合。但它的缺点是在优化时是NP难问题,很难优化。因此实际任务中更常用L1范数。
7.L1正则化:
损失函数L0后面加上参数(权向量w)的L1范数项:λ||w||1=λ∑ni=1||wi||1 , 其中 n 是权向量 w 的长度(参数数量),λ 是正则化参数,用来调和L0 与正则项,此时损失函数如下:
L=L0+λ||w||1
L1正则项等价于先验概率服从拉普拉斯分布;此时若针对线性回归就是Lasso Regression。L1范数是L0范数的最优凸近似,比L0范数容易优化,而且也可以很好地实现参数稀疏性,常别称作“稀疏规则算子”,因此相对L0正则化更常用。同时L1和L0因为具有使参数稀疏的特点,常用于特征选择。
8.L2正则化:
损失函数L0后面加上参数L2范数的平方项:λ2n||w||22=λ2n∑ni=1w2i ,其大小由参数weight-decay(权值衰减)调节,此时损失函数如下:
L=L0+λ2n||w||22
其中分母有无n均可,L2正则项等价于先验概率服从高斯分布;此时针对线性回归就是Ridge Regression,即常说的“岭回归”。与L0,L1不同的是,L2很难使某些参数达到0,它只能使参数接近0。如今在许多问题中,更常用L2正则是因为:一方面我们通常想考虑更多的参数对问题的影响(因此不能让参数稀疏),另一方面在优化时,L2范数有利于解决condition number: k(A)=||A||||A−1|| 太大(远大于1)的情况下(此时存在某些参数,对结果有过大的影响)矩阵求逆很困难的问题,这使得优化求解变得更快更稳定。
现在有些任务中会同时使用L1和L2正则项,用各自的两个正则化参数去权衡“部分稀疏”与“整体接近0”这一对trade-off问题。 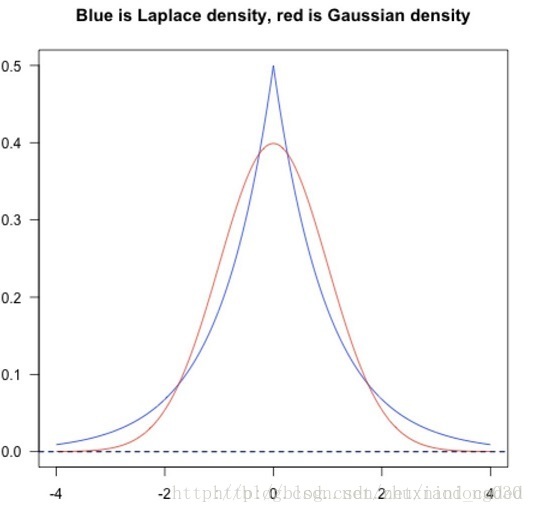
上图可以看出,服从拉普拉斯分布的L1正则项更倾向于产生稀疏参数,而服从高斯分布的L2正则项在0处相对比较平滑,在参数绝对值较大处抑制效果更好,使整体数据的分布更接近0。
9.(针对DNN)batch normalization:即BN,既能够提高泛化能力,又大大提高训练速度,现在被广泛应用在DNN中的激活层之前。BN的提出最初是针对DNN在训练过程中会出现数据内部的协方差偏移现象,导致输出数据分布发生额外的改变,并随着层数的增加偏移加剧,使得模型不得不根据输出分布的改变重新学习,这又导致训练速度减慢。
公式如下: 
具体过程:首先对某层的输入样本做白化处理,等价于零均值化处理(均值为0,方差为1),使输入样本之间互不相关,且每层的输入服从相同分布,克服了内部协方差偏移的影响。采用分批处理数据的方式,减少了计算量。
主要优势:减小了梯度对参数大小和初始值的依赖,将参数值(特征)缩放在[0,1]区间(若针对Relu还限制了输出的范围),这样反向传播时梯度控制在1左右,使网络即使在较高学习率下也不易发生梯度爆炸或弥散(也预防了在使用sigmoid作为激活函数时训练容易陷入梯度极小饱和或极大的极端情况)。
智能推荐
egret4.X版本项目无法与egret 5.X项目共存解决_egret 4.x老项目升级-程序员宅基地
文章浏览阅读367次。在编译egret 5.X 项目项目中执行egret clean_egret 4.x老项目升级
CentOS7下初始化hive,failed to get schema version,大神们帮忙看看怎么解决,弄了好几天了_初始化hive元数据库失败显示failed to get schema version-程序员宅基地
文章浏览阅读705次。_初始化hive元数据库失败显示failed to get schema version
Java核心技术卷一 -第五章:装箱和拆箱_自动装箱和自动拆箱在java第几章-程序员宅基地
文章浏览阅读340次。系列文章目录Java核心技术卷一 -第一章:java“白皮书”的关键术语Java核心技术卷一 -第三章:数据类型Java核心技术卷一 -第三章:变量与常量Java核心技术卷一 -第三章:运算符Java核心技术卷一 -第三章:字符串Java核心技术卷一 -第三章:输入与输出Java核心技术卷一 -第三章:数组Java核心技术卷一 -第四章:类之间的关系-依赖Java核心技术卷一 -第四章:预定义类-LocalDate类小应用Java核心技术卷一 -第四章:构造器Java核心技术卷一 -第_自动装箱和自动拆箱在java第几章
hadoop2.x常用端口、定义方法及默认端口、hadoop1.X端口对比-程序员宅基地
文章浏览阅读489次。问题导读:1.DataNode的http服务的端口、ipc服务的端口分别是哪个?2.NameNode的http服务的端口、ipc服务的端口分别是哪个?3.journalnode的http服务的端口、ipc服务的端口分别是哪个?4.ResourceManager的http服务端口是哪个?5.NodeManager的http服务端口是哪个?6.Master的http服务的端口、
协变张量和逆变张量(纯代数角度理解)-程序员宅基地
文章浏览阅读241次。_协变张量
Matlab在概率统计中的应用问题及解决方案集锦_matlab数学建模 概率题-程序员宅基地
文章浏览阅读2.1k次,点赞2次,收藏9次。Matlab在概率统计中的应用(0001)问题:假设已知 Rayleigh 分布的概率密度函数为试用解析推导的方法求出该分布的分布函数、均值、方差、中心矩和原点矩。生成一组满足 Rayleigh 分布的伪随机数,用数值方法检验得出的解析结果是否正确。解:工具相应的数学定义的公式,所需的分布函数、均值、方差、中心矩和原点矩等可 以由下面的语句推导出来。>> syms x;syms b positivep=x*exp(-x^2/2/b^2)/b^..._matlab数学建模 概率题
随便推点
pd.DataFrame.to_excel出错,如何解决??_pd.to_excel 出现 临时文件错误-程序员宅基地
文章浏览阅读3k次。各位大佬请问是什么问题?我运行pd.DataFrame.to_excel,结果每个选项都报错,但是库都打足了。# 1.文件读取# 1.1 读取Excel文件import pandas as pddata = pd.read_excel('data.xlsx') # data为DataFrame结构,这里设置是相对路径,也可以改成绝对路径print(data)# 1.2 读取CSV文..._pd.to_excel 出现 临时文件错误
关于a标签,添加:data-toggle="modal" 属性,又添加了:href="#btn_top",属性导致 跳转到另一个页面出现遮罩层_"data-toggle=\"modal"-程序员宅基地
文章浏览阅读7.1k次。1.关于a标签,添加:data-toggle="modal" 属性,又添加了:href="#btn_top",属性导致 跳转到另一个页面出现遮罩层如上图,如果a标签无意添加了:data-toggle="modal"属性,那么你的href标签里对应的modal要能找到,广泛解释就是。添加:data-toggle="modal"属性,添加a标签会寻找此标签的href属性,可刚好你写的href ..._"data-toggle=\"modal"
MySQL的on duplicate key update 的使用_mysql on duplicate key update-程序员宅基地
文章浏览阅读1.5w次,点赞2次,收藏31次。mysql的存在就更新不存在就插入实现先建数据库表,重点要添加主键索引(id列,没有测试)和唯一索引(branch_no列)sqlINSERT INTO t_bank_organ_copy1 ( organ_no, branch_no, branch_name, created_by )VALUES ( 1255, '13', '深圳分行', '小王' ) ON DUPLICATE KEY UPDATE branch_name = '中国银行'测试:1、organ_no, ._mysql on duplicate key update
【JqGrid】JqGrid日期格式化处理-程序员宅基地
文章浏览阅读6.2k次。使用JqGrid显示日期是转换后的结果,即显示的毫秒数。需要自己进行手工处理,处理后的代码如下:{label:'日期',name: 'departure_date',index: 'departure_date',align: "center",formatter:function(cellValue,options,rowObject){ return (moment(rowOb_jqgrid日期格式化
Convert.ToInt32()与Int.Parse()的区别_convert.toint32和int.parse的区别-程序员宅基地
文章浏览阅读619次。1、int适合简单数据类型之间的转换,C#的默认整型是int32(不支持bool型);2、int.Parse(string sParameter)是个构造函数,参数类型只支持string类型;3、Convert.ToInt32()适合将Object类型转换为int型;4、Convert.ToInt32()和int.Parse()的细微差别:对于空值(null)的处理_convert.toint32和int.parse的区别
mysql 常用命令-菜鸟级_mysql数据库命令大全菜鸟-程序员宅基地
文章浏览阅读207次。一、连接MySQL 格式: mysql -h 主机地址 -u 用户名 -p 用户密码 1、例1:连接到本机上的MYSQL。 首先在打开DOS窗口,然后进入目录 mysql bin,再键入命令mysql -uroot -p,回车后提示你输密码,如果刚安装好MYSQL,超级用户root是没有密码的,故直接回车即可进入到MYSQL中了,MYSQL的提示符是: mysql>。 ..._mysql数据库命令大全菜鸟