PostgreSQL插件_pg数据库安装postgres插件-程序员宅基地
技术标签: postgresql PG 服务器 数据库
PostgreSQL插件
说明
PostgreSQL是一个可扩展的关系型数据库,支持插件机制。插件可以增强PostgreSQL的功能,例如添加新的数据类型、查询优化器、存储引擎等等。以上是一些常用的PostgreSQL插件,它们可以帮助开发者扩展PostgreSQL的功能,提高数据库的性能和灵活性。
PostgreSQL 最常用的插件 ](https://www.cnblogs.com/88223100/p/The-most-common-plug-ins-of-PostgreSQL.html)
列出插件
您可以使用以下命令来查看 PostgreSQL 中已安装的插件:
SELECT * FROM pg_available_extensions;
这将列出所有可用的扩展和其描述。
您还可以使用以下命令来查看已安装的插件:
SELECT * FROM pg_extension;
dx
这将列出所有已安装的扩展及其状态和版本信息。
示例
pgAudit
pgAudit是一个用于审计PostgreSQL数据库的插件,可以记录每个SQL语句的执行情况,包括执行时间、执行用户、执行结果等信息。下面是pgAudit插件的使用方法:
- 安装pgAudit插件
首先需要安装pgAudit插件,可以使用以下命令:
sudo apt-get install postgresql-contrib
安装完成后,需要在postgresql.conf文件中添加以下配置:
shared_preload_libraries = 'pgaudit'
pgaudit.log = 'ddl, read, write'
- 重启PostgreSQL服务器
添加配置后,需要重启PostgreSQL服务器使配置生效:
sudo service postgresql restart
- 创建审计日志表
在使用pgAudit插件之前,需要先创建一个审计日志表,可以使用以下命令:
CREATE TABLE audit.logged_actions (
schema_name text NOT NULL,
table_name text NOT NULL,
user_name text NOT NULL,
action_tstamp timestamp with time zone NOT NULL default current_timestamp,
action text NOT NULL,
original_data text,
new_data text,
query text,
action_reason text,
client_addr inet,
client_port integer,
session_user_name text,
session_id text,
application_name text
);
- 开启审计日志记录
在创建审计日志表后,需要使用以下命令开启审计日志记录:
SET pgaudit.log = 'all';
- 查看审计日志
审计日志记录完成后,可以使用以下命令查看审计日志:
SELECT * FROM audit.logged_actions;
以上就是pgAudit插件的使用方法,通过使用pgAudit插件,可以方便地对PostgreSQL数据库进行审计和监控。
SET pgaudit.log = 'all'; 是一个 PostgreSQL pgaudit 插件的设置命令,它的作用是启用 pgaudit 插件并将所有数据库操作记录到日志中。
pgaudit 是一个第三方插件,它可以用于审计 PostgreSQL 数据库的所有操作。它可以记录用户登录、数据库对象的创建、修改和删除、SQL 查询语句等操作,以及失败的登录尝试、未授权的访问等安全事件。
在设置 pgaudit.log 为 'all' 后,pgaudit 将记录所有数据库操作,包括成功和失败的操作。这将产生大量的日志数据,因此建议仅在需要详细审计时使用该设置。您可以根据需要将其设置为 'ddl'、'read' 或 'write' 等选项,以记录特定类型的操作。
请注意,启用 pgaudit 插件会对数据库的性能产生一定的影响,因此在生产环境中建议谨慎使用。
postgres_fdw
PostgreSQL Foreign Data Wrapper (FDW) 是一种 PostgreSQL 扩展,它使得 PostgreSQL 数据库可以通过外部数据源连接到其他数据库或数据存储系统。FDW 允许 PostgreSQL 数据库通过 SQL 查询访问外部数据源的表、视图和函数,就好像它们是本地表一样。
FDW 通过实现 PostgreSQL 外部表(Foreign Table)的概念,将外部数据源映射到 PostgreSQL 数据库中。外部表的定义包括外部数据源的连接信息、表结构信息、索引和约束等。当查询外部表时,PostgreSQL 会将查询转换为外部数据源的查询语言,并将结果集返回到客户端。
FDW 的优点包括:
- 可以轻松地将外部数据源集成到 PostgreSQL 中,无需复制数据或维护 ETL 流程。
- 可以在 PostgreSQL 中使用 SQL 查询和操作外部数据源,无需了解外部数据源的查询语言或 API。
- 可以通过 FDW 扩展实现 PostgreSQL 与其他数据库或数据存储系统的集成,例如 MySQL、Oracle、Hadoop、Elasticsearch 等。
PostgreSQL FDW 扩展提供了以下特性:
- 通过外部表将外部数据源映射到 PostgreSQL 数据库中。
- 支持连接到多种数据源,例如 PostgreSQL、Oracle、MySQL、SQLite、SQL Server 等。
- 允许使用 SQL 查询和操作外部数据源。
- 支持在外部数据源上创建索引和约束。
- 提供了安全性和隔离性,可以限制对外部数据源的访问权限。
- 支持在外部数据源上执行远程事务。
使用 PostgreSQL FDW 扩展,可以轻松地将其他数据库和数据存储系统集成到 PostgreSQL 中,从而实现数据的统一管理和查询。需要注意的是,FDW 查询外部数据源的性能受到外部数据源的性能和网络通信的影响。在使用 FDW 时,需要评估外部数据源的性能和可用性,以确保查询效率和数据一致性。
dblink
pg_dblink是一个PostgreSQL扩展模块,它允许在PostgreSQL中使用SQL语句来连接其他的PostgreSQL数据库,或者连接其他数据库系统(如Oracle、MySQL等)。它使用动态语句执行(Dynamic SQL)来实现连接和操作外部数据,因此需要编写更多的代码来完成相同的任务。
pg_dblink的主要功能包括:
- 在PostgreSQL中连接其他数据库系统,包括其他的PostgreSQL数据库、Oracle、MySQL等;
- 在PostgreSQL中执行远程SQL语句,并返回结果;
- 在PostgreSQL中使用动态参数,可以在执行远程SQL语句时动态传递参数;
- 可以在PostgreSQL中使用事务控制来管理远程数据库的操作;
- 支持在PostgreSQL中使用函数和触发器来操作远程数据库。
使用pg_dblink需要先安装该扩展模块,可以使用CREATE EXTENSION命令来安装。安装后,可以使用dblink_connect函数来连接其他数据库系统,使用dblink_exec函数来执行远程SQL语句,使用dblink_fetch函数来获取远程SQL语句执行的结果。同时,pg_dblink还提供了其他的函数和操作,可以满足不同的需求。
postgres_fdw是PostgreSQL Foreign Data Wrapper的缩写,可以将其他数据库系统中的数据表映射到PostgreSQL中,让用户可以像操作本地数据表一样操作外部数据表,它实现了PostgreSQL的外部数据访问功能。
而dblink是一个PostgreSQL扩展模块,可以在PostgreSQL中连接其他的PostgreSQL数据库或其他数据库系统,并执行远程SQL语句,它实现了PostgreSQL的远程数据访问功能。
因此,两者的功能和用途不同。postgres_fdw主要用于访问外部数据表,而dblink主要用于访问远程数据库。
file_fdw
PostgreSQL file_fdw 是 PostgreSQL 中的一种扩展,它可以将文件系统中的文件映射到 PostgreSQL 数据库中,从而允许在 PostgreSQL 中访问这些文件。file_fdw 扩展提供了一种简单的方法来将文件系统中的数据集成到 PostgreSQL 中,无需复制数据或维护 ETL 流程。
file_fdw 扩展提供了以下特性:
- 通过外部表将文件系统中的文件映射到 PostgreSQL 数据库中。
- 支持连接到多种文件格式,例如 CSV、JSON、XML 等。
- 允许使用 SQL 查询和操作文件系统中的文件。
- 支持在文件系统上创建索引和约束。
- 提供了安全性和隔离性,可以限制对文件系统的访问权限。
使用 PostgreSQL file_fdw 扩展,可以轻松地将文件系统中的数据集成到 PostgreSQL 中,从而实现数据的统一管理和查询。例如,您可以将 CSV 文件作为外部表导入到 PostgreSQL 中,并使用 SQL 查询来访问和操作这些数据。
pg_cron
pg_cron 是一个用于 PostgreSQL 数据库的扩展,它提供了在数据库中执行定期任务的功能。pg_cron 扩展允许您在 PostgreSQL 数据库中定义和调度基于时间的作业,并以预定的时间间隔自动执行这些作业。
pg_cron 扩展的作用包括:
-
定期任务调度:pg_cron 允许您在 PostgreSQL 数据库中创建定期任务,例如定时备份、数据清理、统计计算等。您可以使用类似于 cron 的语法定义作业的执行时间表。
-
作业管理:pg_cron 允许您创建、修改、查看和删除作业。您可以轻松管理数据库中的定期任务,而无需使用外部工具或脚本。
-
作业执行控制:pg_cron 提供了对作业执行的灵活控制。您可以暂停和恢复作业的执行,也可以立即执行作业而不必等待预定的执行时间。
-
错误处理和日志记录:pg_cron 记录作业的执行结果和状态,并提供错误处理机制。您可以查看作业的执行日志,并根据需要采取相应的措施。
使用 pg_cron 扩展,您可以在 PostgreSQL 数据库中实现自动化的定期任务管理,避免依赖外部工具和脚本。它简化了定时任务的创建和管理,并提供了灵活的调度和控制选项,以满足您的需求。
CREATE EXTENSION IF NOT EXISTS “pg_cron”;
ERROR: can only create extension in database postgres
DETAIL: Jobs must be scheduled from the database configured in cron.database_name, since the pg_cron background worker reads job descriptions from this database.
HINT: Add cron.database_name = ‘test’ in postgresql.conf to use the current database.
CONTEXT: PL/pgSQL function inline_code_block line 4 at RAISE
cron.database_name 添加需要安装插件的数据库
在 PostgreSQL 中,cron.database_name 是一个配置参数,用于指定 pg_cron 后台工作进程读取作业描述的数据库名称。这个参数的值是一个字符串,表示数据库名称。
答案是可以设置多个数据库。您可以在 cron.database_name 参数的值中指定多个数据库名称,使用逗号进行分隔。例如:
cron.database_name = 'db1, db2, db3'
上述配置将使 pg_cron 后台工作进程从数据库 db1、db2 和 db3 中读取作业描述。
请注意,每个数据库都必须启用了 pg_cron 扩展,并在其中定义了作业。否则,即使配置了多个数据库名称,pg_cron 后台工作进程也无法读取和执行作业。
另外,请确保在修改 PostgreSQL 配置文件后重新加载配置使其生效。可以使用 pg_ctl 命令或 PostgreSQL 的重新启动来实现。
citus
Citus 是一个开源的 PostgreSQL 扩展,它旨在为 PostgreSQL 提供水平扩展能力和分布式数据库功能。它使得在大规模数据集上进行并行查询和分布式数据处理变得更加容易。
以下是 Citus 的一些主要特性和功能:
-
水平扩展:Citus 允许将 PostgreSQL 扩展到多个节点,从而实现数据的水平分片和分布式存储。通过将数据分布在多个节点上,可以实现高度可伸缩性和高吞吐量。
-
分布式查询:Citus 提供了分布式查询引擎,可以将查询计划并行执行在多个节点上。这样可以加快查询速度并减少响应时间。
-
分布式事务:Citus 支持分布式事务处理,使得在分布式环境中维护数据的一致性和完整性变得更加容易。它提供了事务管理和并发控制机制,确保事务的原子性、一致性、隔离性和持久性。
-
扩展性和灵活性:Citus 可以根据需要动态添加或删除节点,以适应不断增长的数据和负载。它还提供了灵活的数据分片策略和查询路由机制,以便根据应用程序的需求进行优化。
-
PostgreSQL 兼容性:Citus 是以 PostgreSQL 为基础开发的扩展,因此保留了 PostgreSQL 的兼容性和丰富的功能集。您可以继续使用 PostgreSQL 的各种功能,如索引、触发器、视图和存储过程。
-
简化的管理和开发:Citus 提供了一组工具和命令,用于管理分布式集群和执行分布式查询。它还提供了用于数据分片和迁移的工具,以及用于监控和调优的仪表板。
Citus 是一个强大的工具,适用于需要处理大规模数据和高并发负载的应用程序。它可以帮助提高查询性能、扩展性和可用性,并简化分布式数据库的管理和开发。
CREATE EXTENSION IF NOT EXISTS “citus”;
ERROR: Citus can only be loaded via shared_preload_libraries
HINT: Add citus to shared_preload_libraries configuration variable in postgresql.conf in master and workers. Note that citus should be at the beginning of shared_preload_libraries.
shared_preload_libraries = 'citus,pg_stat_statements,pgaudit,pg_cron'
必须要放在第一个!否则会导致数据无法启动
2023-05-25 12:21:21.419 CST [1132] LOG: pgaudit extension initialized
2023-05-25 12:21:21.424 CST [1132] FATAL: Citus has to be loaded first
2023-05-25 12:21:21.424 CST [1132] HINT: Place citus at the beginning of shared_preload_libraries.
2023-05-25 12:21:21.425 CST [1132] LOG: database system is shut down
pg_trgm
pg_trgm是PostgreSQL数据库中的一个扩展模块,用于实现基于n-gram的文本匹配和相似度计算。该扩展模块提供了一种有效的方法来处理文本数据的模糊匹配和相似性搜索。
以下是一些关于pg_trgm扩展的说明:
-
三元组(trigram):
pg_trgm扩展使用三元组(trigram)作为基本单元来表示文本。三元组是由三个连续字符组成的字符串片段。例如,对于字符串"OpenAI",生成的三元组包括"Ope",“pen”,“enA"和"nAI”。 -
文本索引:通过创建基于
pg_trgm的文本索引,可以实现模糊匹配和相似度搜索。该索引存储了文本中所有可能的三元组,并为其建立了索引,以便可以快速进行模糊匹配和相似性计算。 -
模糊匹配:使用
pg_trgm扩展,可以进行模糊匹配,即查找与给定模式相似的文本。例如,可以使用pg_trgm来查找与单词"apple"相似的其他单词,如"aple"或"appple"。 -
相似度计算:
pg_trgm还提供了计算两个文本之间相似度的函数。可以使用这些函数来评估文本之间的相似程度,例如计算两个字符串之间的相似度分数。
pg_trgm扩展提供了一种灵活和高效的方式来处理模糊匹配和相似性搜索,尤其在处理大量文本数据时非常有用。可以通过在PostgreSQL中启用和使用pg_trgm扩展来利用这些功能。
uuid-ossp
uuid-ossp是PostgreSQL数据库中的一个扩展模块,用于生成和操作UUID(通用唯一标识符)。UUID是一种标准的128位标识符,用于在分布式系统中唯一地标识实体。
以下是一些关于uuid-ossp扩展的说明:
-
UUID生成:
uuid-ossp扩展提供了函数来生成不同类型的UUID。其中包括使用随机算法生成的版本4 UUID、使用命名空间和名称生成的版本3和版本5 UUID,以及使用MAC地址和时间戳生成的版本1 UUID。 -
UUID数据类型:
uuid-ossp扩展还引入了UUID数据类型,允许在数据库中存储和处理UUID值。UUID数据类型在语法上与其他基本数据类型类似,并提供了一些函数和操作符用于UUID之间的比较、操作和转换。 -
UUID索引:通过在UUID列上创建索引,可以高效地检索和查询UUID值。
uuid-ossp扩展支持在UUID列上创建B-tree索引,以加速UUID值的查找。 -
UUID操作函数:
uuid-ossp扩展还提供了一些函数,用于在UUID值之间执行各种操作。例如,可以比较两个UUID值的大小,提取UUID的组成部分,将UUID转换为字符串表示等。
使用uuid-ossp扩展可以方便地生成、存储和操作UUID值,特别适用于需要在分布式系统中唯一标识实体的场景,如数据库主键、标识符或跟踪日志等。
要使用uuid-ossp扩展,需要在PostgreSQL中启用该扩展。可以使用CREATE EXTENSION语句来启用uuid-ossp扩展,并通过在查询中调用相关函数来使用其提供的功能。
oracle_fdw
Oracle Foreign Data Wrapper (oracle_fdw) 是一个PostgreSQL扩展,它允许在PostgreSQL数据库中访问和查询Oracle数据库中的数据。它通过创建外部表来实现与Oracle数据库的连接和数据交互。
下面是oracle_fdw的一些说明和特点:
-
安装:在使用oracle_fdw之前,您需要将其安装为PostgreSQL的扩展。安装方法包括从源代码编译、使用包管理器安装或使用预编译的二进制文件安装。
-
配置:安装完成后,需要进行一些配置步骤。这些配置包括创建外部服务器、创建用户和用户映射,并定义外部表的结构。
-
外部服务器:通过创建外部服务器,您可以定义与Oracle数据库的连接信息,包括主机地址、端口号和数据库名称。这样,PostgreSQL就能够通过外部服务器与Oracle数据库建立连接。
-
用户和用户映射:在创建外部服务器后,您需要创建一个PostgreSQL用户,并将其与外部服务器上的Oracle用户进行映射。这样可以确保在查询执行时,正确的用户凭据被传递给Oracle数据库。
-
外部表:一旦外部服务器和用户映射配置完成,您可以创建外部表来映射Oracle数据库中的表。外部表的结构与Oracle表的结构相匹配,并且您可以在PostgreSQL中对这些外部表执行查询和操作。
-
查询和操作:使用oracle_fdw,您可以在PostgreSQL中对Oracle数据库中的数据执行查询、插入、更新和删除操作。这样,您可以方便地在PostgreSQL中访问和处理Oracle数据库的数据,实现数据集成和应用程序的开发。
需要注意的是,使用oracle_fdw连接到Oracle数据库需要确保网络连接可用、具有正确的数据库连接信息和凭据,并且PostgreSQL数据库具有足够的权限来执行这些操作。
总之,oracle_fdw是一个有用的工具,它扩展了PostgreSQL的功能,使其能够与Oracle数据库进行集成,并实现数据的共享和查询。
实操
根据您提供的信息,这些步骤是在PostgreSQL中安装和配置Oracle Foreign Data Wrapper (oracle_fdw) 插件以实现与Oracle数据库的连接。以下是对每个步骤的解释:
- 安装插件:
create extension oracle_fdw;
这条命令用于在PostgreSQL中创建并启用oracle_fdw扩展。这样做后,您就可以在PostgreSQL中使用oracle_fdw功能。
- 创建到Oracle的服务器:
create server to_ora_bpx foreign data wrapper oracle_fdw options (dbserver '//x.x.x.x:1521/orcl');
这条命令创建了一个名为to_ora_bpx的外部服务器,它使用oracle_fdw作为数据包装器,并指定了连接到Oracle数据库的连接信息。这里的dbserver参数指定了Oracle数据库的连接地址。
- 创建用户:
create user oracle_fdw superuser password 'oracle';
这条命令创建了一个名为oracle_fdw的用户,并分配了超级用户权限。该用户用于在PostgreSQL中执行与Oracle数据库相关的操作。
- 映射用户:
create user mapping for oracle_fdw server to_ora_bpx options (user 'bpx', password 'bpx');
这条命令创建了一个用户映射,将PostgreSQL中的oracle_fdw用户与外部服务器to_ora_bpx上的Oracle用户BPX进行映射。这样可以确保在执行查询时,正确的用户凭据被传递给Oracle数据库。
- 创建外部表映射Oracle中的表:
create foreign table oracle_test (id int, name varchar) server to_ora_bpx options (schema 'BPX', table 'BPX');
这条命令创建了一个外部表oracle_test,它映射了Oracle数据库中的BPX模式下的BPX表。外部表允许在PostgreSQL中访问Oracle数据库中的数据。
请注意,在执行这些步骤之前,您需要确保已经安装了oracle_fdw插件,并且PostgreSQL数据库具有足够的权限来执行这些操作。此外,还需要提供正确的连接信息和凭据,以便成功连接到Oracle数据库。
如果您遇到任何问题或需要进一步的帮助,请提供详细的错误消息或问题描述。
psql -h x.x.x.x -p 1014 -U oracle_fdw -d test
select * from oracle_test ;
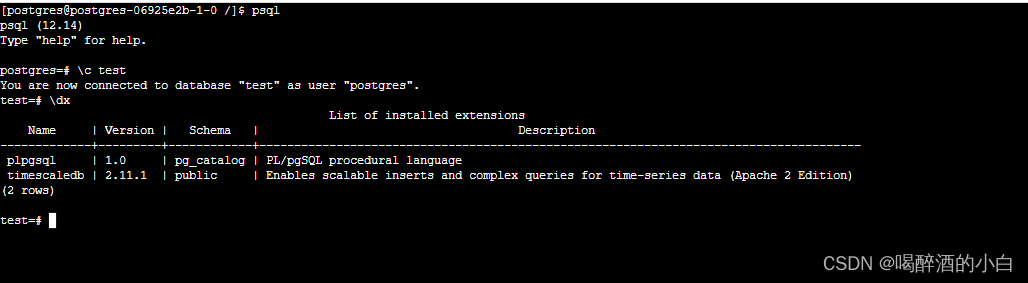
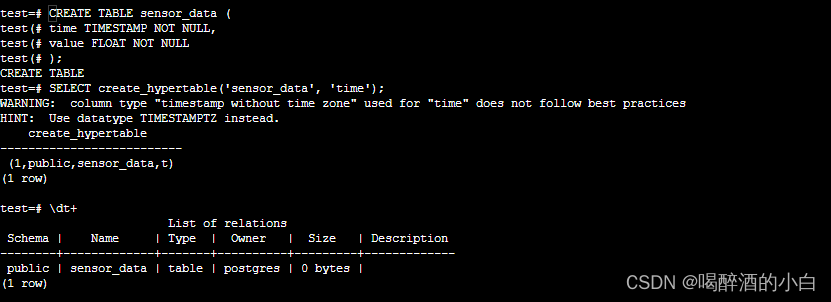
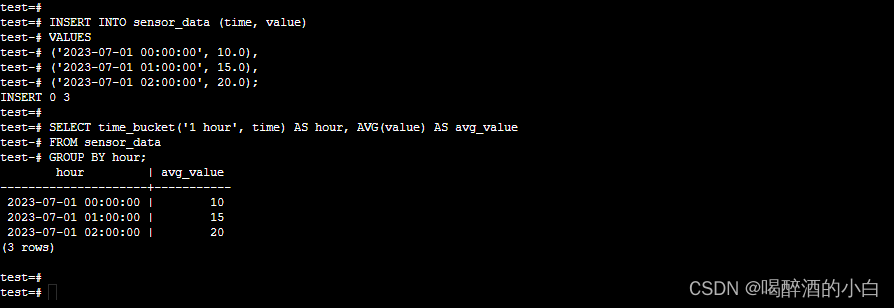
timescaledb
timescaledb
TimescaleDB vs. PostgreSQL
1. 修改实例配置文件的shared_preload_libraries参数,增加 timescaledb 值,如 shared_preload_libraries = 'pgaudit' => shared_preload_libraries = 'pgaudit,timescaledb'
2. 重启数据库使配置生效
3. 连接数据库执行查询启用插件:CREATE EXTENSION timescaledb;
pg_profile
下载链接
https://github.com/zubkov-andrei/pg_profile/issues
select * from take_sample();
select show_samples();
psql -d bpx -qtc "select public.get_report(1,2)" --output /tmp/awr_report_postgres_1_2.html
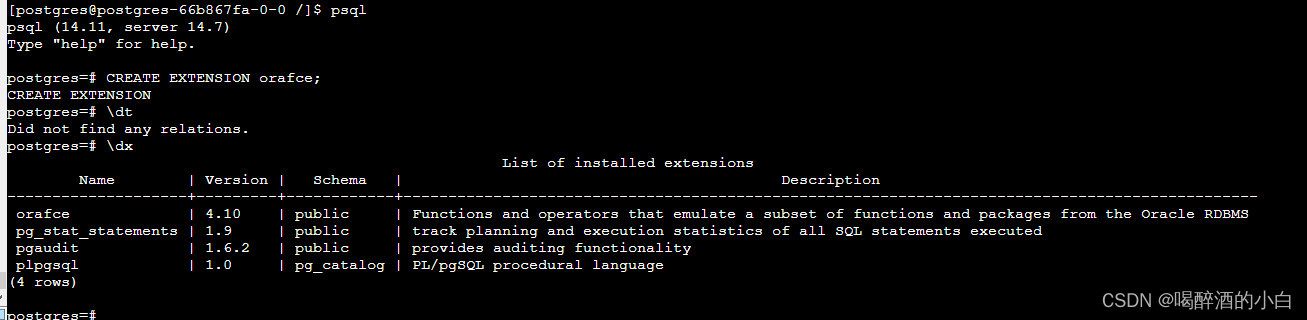
orafce
1、准备依赖
mv /etc/yum.repos.d/pgdg-redhat-all.repo /root
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
dnf install -y --enablerepo=powertools postgresql14-devel unzip redhat-rpm-config openssl-devel
dnf reinstall gcc
2、下载插件安装包
https://github.com/orafce/orafce
3、安装 orafce
unzip orafce-master.zip
cd orafce-master
make install
智能推荐
解决win10/win8/8.1 64位操作系统MT65xx preloader线刷驱动无法安装_mt65驱动-程序员宅基地
文章浏览阅读1.3w次。转载自 http://www.miui.com/thread-2003672-1-1.html 当手机在刷错包或者误修改删除系统文件后会出现无法开机或者是移动定制(联通合约机)版想刷标准版,这时就会用到线刷,首先就是安装线刷驱动。 在XP和win7上线刷是比较方便的,用那个驱动自动安装版,直接就可以安装好,完成线刷。不过现在也有好多机友换成了win8/8.1系统,再使用这个_mt65驱动
SonarQube简介及客户端集成_sonar的客户端区别-程序员宅基地
文章浏览阅读1k次。SonarQube是一个代码质量管理平台,可以扫描监测代码并给出质量评价及修改建议,通过插件机制支持25+中开发语言,可以很容易与gradle\maven\jenkins等工具进行集成,是非常流行的代码质量管控平台。通CheckStyle、findbugs等工具定位不同,SonarQube定位于平台,有完善的管理机制及强大的管理页面,并通过插件支持checkstyle及findbugs等既有的流..._sonar的客户端区别
元学习系列(六):神经图灵机详细分析_神经图灵机方法改进-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏27次。神经图灵机是LSTM、GRU的改进版本,本质上依然包含一个外部记忆结构、可对记忆进行读写操作,主要针对读写操作进行了改进,或者说提出了一种新的读写操作思路。神经图灵机之所以叫这个名字是因为它通过深度学习模型模拟了图灵机,但是我觉得如果先去介绍图灵机的概念,就会搞得很混乱,所以这里主要从神经图灵机改进了LSTM的哪些方面入手进行讲解,同时,由于模型的结构比较复杂,为了让思路更清晰,这次也会分开几..._神经图灵机方法改进
【机器学习】机器学习模型迭代方法(Python)-程序员宅基地
文章浏览阅读2.8k次。一、模型迭代方法机器学习模型在实际应用的场景,通常要根据新增的数据下进行模型的迭代,常见的模型迭代方法有以下几种:1、全量数据重新训练一个模型,直接合并历史训练数据与新增的数据,模型直接离线学习全量数据,学习得到一个全新的模型。优缺点:这也是实际最为常见的模型迭代方式,通常模型效果也是最好的,但这样模型迭代比较耗时,资源耗费比较多,实时性较差,特别是在大数据场景更为困难;2、模型融合的方法,将旧模..._模型迭代
base64图片打成Zip包上传,以及服务端解压的简单实现_base64可以装换zip吗-程序员宅基地
文章浏览阅读2.3k次。1、前言上传图片一般采用异步上传的方式,但是异步上传带来不好的地方,就如果图片有改变或者删除,图片服务器端就会造成浪费。所以有时候就会和参数同步提交。笔者喜欢base64图片一起上传,但是图片过多时就会出现数据丢失等异常。因为tomcat的post请求默认是2M的长度限制。2、解决办法有两种:① 修改tomcat的servel.xml的配置文件,设置 maxPostSize=..._base64可以装换zip吗
Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字-程序员宅基地
文章浏览阅读1k次,点赞17次,收藏22次。Opencv自然场景文本识别系统(源码&教程)_opencv自然场景实时识别文字
随便推点
ESXi 快速复制虚拟机脚本_exsi6.7快速克隆centos-程序员宅基地
文章浏览阅读1.3k次。拷贝虚拟机文件时间比较长,因为虚拟机 flat 文件很大,所以要等。脚本完成后,以复制虚拟机文件夹。将以下脚本内容写入文件。_exsi6.7快速克隆centos
好友推荐—基于关系的java和spark代码实现_本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。-程序员宅基地
文章浏览阅读2k次。本文主要实现基于二度好友的推荐。数学公式参考于:http://blog.csdn.net/qq_14950717/article/details/52197565测试数据为自己随手画的关系图把图片整理成文本信息如下:a b c d e f yb c a f gc a b dd c a e h q re f h d af e a b gg h f bh e g i di j m n ..._本关任务:使用 spark core 知识完成 " 好友推荐 " 的程序。
南京大学-高级程序设计复习总结_南京大学高级程序设计-程序员宅基地
文章浏览阅读367次。南京大学高级程序设计期末复习总结,c++面向对象编程_南京大学高级程序设计
4.朴素贝叶斯分类器实现-matlab_朴素贝叶斯 matlab训练和测试输出-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏12次。实现朴素贝叶斯分类器,并且根据李航《统计机器学习》第四章提供的数据训练与测试,结果与书中一致分别实现了朴素贝叶斯以及带有laplace平滑的朴素贝叶斯%书中例题实现朴素贝叶斯%特征1的取值集合A1=[1;2;3];%特征2的取值集合A2=[4;5;6];%S M LAValues={A1;A2};%Y的取值集合YValue=[-1;1];%数据集和T=[ 1,4,-1;..._朴素贝叶斯 matlab训练和测试输出
Markdown 文本换行_markdowntext 换行-程序员宅基地
文章浏览阅读1.6k次。Markdown 文本换行_markdowntext 换行
错误:0xC0000022 在运行 Microsoft Windows 非核心版本的计算机上,运行”slui.exe 0x2a 0xC0000022″以显示错误文本_错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行-程序员宅基地
文章浏览阅读6.7w次,点赞2次,收藏37次。win10 2016长期服务版激活错误解决方法:打开“注册表编辑器”;(Windows + R然后输入Regedit)修改SkipRearm的值为1:(在HKEY_LOCAL_MACHINE–》SOFTWARE–》Microsoft–》Windows NT–》CurrentVersion–》SoftwareProtectionPlatform里面,将SkipRearm的值修改为1)重..._错误: 0xc0000022 在运行 microsoft windows 非核心版本的计算机上,运行“slui.ex