【深度学习:MPT-30B】提高开源基础模型的标准-程序员宅基地

【深度学习:MPT-30B】提高开源基础模型的标准
隆重推出 MPT-30B,它是我们开源模型基础系列中功能更强大的新成员,在 NVIDIA H100 Tensor Core GPU 上使用 8k 上下文长度进行训练。
在这里尝试 HuggingFace 上的 MPT-30B-Chat!
自 5 月份推出 MPT-7B 以来,ML 社区热切地接受开源 MosaicML 基础系列模型。 MPT-7B 基础、-Instruct、-Chat 和 -StoryWriter 模型的总下载量已超过 300 万次!
我们对社区使用 MPT-7B 构建的内容感到不知所措。强调几个:LLaVA-MPT 为 MPT 添加了视觉理解,GGML 在 Apple Silicon 和 CPU 上优化 MPT,GPT4All 允许您使用 MPT 作为后端模型在笔记本电脑上运行类似 GPT4 的聊天机器人。
今天,我们很高兴通过 MPT-30B 扩展 MosaicML 基础系列,MPT-30B 是一种获得商业用途许可的新型开源模型,其功能明显比 MPT-7B 更强大,并且性能优于原始的 GPT-3。此外,我们还发布了两个经过微调的变体:MPT-30B-Instruct 和 MPT-30B-Chat,它们构建在 MPT-30B 之上,分别擅长单轮指令跟踪和多轮对话。
所有 MPT-30B 模型都具有与其他 LLM 不同的特殊功能,包括训练时的 8k 令牌上下文窗口、通过 ALiBi 支持更长的上下文,以及通过 FlashAttention 实现高效的推理 + 训练性能。由于其预训练数据混合,MPT-30B 系列还具有强大的编码能力。该模型已扩展到 NVIDIA H100 GPU 上的 8k 上下文窗口,使其(据我们所知)成为第一个在 H100 GPU 上训练的法学硕士,现在可供 MosaicML 客户使用!
MPT-30B 的尺寸也经过专门选择,以便轻松部署在单个 GPU 上 - 1x NVIDIA A100-80GB(16 位精度)或 1x NVIDIA A100-40GB(8 位精度)。其他类似的 LLM(例如 Falcon-40B)具有更大的参数数量,并且无法在单个数据中心 GPU 上提供服务(目前);这需要 2 个以上的 GPU,从而增加了最低推理系统成本。
如果您想开始在生产中使用 MPT-30B,可以通过多种方法使用 MosaicML 平台对其进行自定义和部署。
-
MosaicML 培训。 通过微调、特定领域预训练或从头开始训练,使用您的私人数据定制 MPT-30B。您始终拥有最终模型权重,并且您的数据永远不会存储在我们的平台上。定价按 GPU 分钟计算。
-
MosaicML 推理。 使用我们的 Python API 与我们托管的 MPT-30B-Instruct(和 MPT-7B-Instruct)端点进行对话,并按每 1K 代币的标准定价。
我们很高兴看到我们的社区和客户接下来使用 MPT-30B 构建什么。要了解有关模型以及如何使用 MosaicML 平台自定义模型的更多信息,请继续阅读!
MPT-30B家族
Mosaic Pretrained Transformer (MPT) 模型是 GPT 风格的仅解码器变压器,具有多项改进,包括更高的速度、更高的稳定性和更长的上下文长度。得益于这些改进,客户可以有效地训练 MPT 模型 (40-60% MFU),而不会偏离损失峰值,并且可以通过标准 HuggingFace 管道和 FasterTransformer 为 MPT 模型提供服务。
MPT-30B (Base)
MPT-30B是商业Apache 2.0许可的开源基础模型,其质量超过了GPT-3(来自原始论文),并且与LLaMa-30B和Falcon-40B等其他开源模型具有竞争力。
使用我们公开提供的 LLM Foundry 代码库,我们在 2 个月的时间内训练了 MPT-30B,随着硬件可用性的变化在多个不同的 NVIDIA A100 集群之间进行转换,平均 MFU >46%。 6 月中旬,在我们从 CoreWeave 收到第一批 256 个 NVIDIA H100 GPU 后,我们将 MPT-30B 无缝移动到新集群,以恢复平均 MFU >35% 的 H100 训练。据我们所知,MPT-30B 是第一个在 H100 GPU 上(部分)训练的公共模型!我们发现每个 GPU 的吞吐量增加了 2.44 倍,并且我们预计随着 H100 软件的成熟,这种加速也会增加。
如前所述,MPT-30B 使用 8k 个 token 的长上下文窗口进行训练(LLaMa 和 Falcon 为 2k),并且可以通过 ALiBi 或微调处理任意长的上下文窗口。为了有效地在 MPT-30B 中构建 8k 支持,我们首先使用 2k 令牌长的序列对 1T 令牌进行预训练,并使用 8k 令牌长的序列继续训练额外的 50B 令牌。
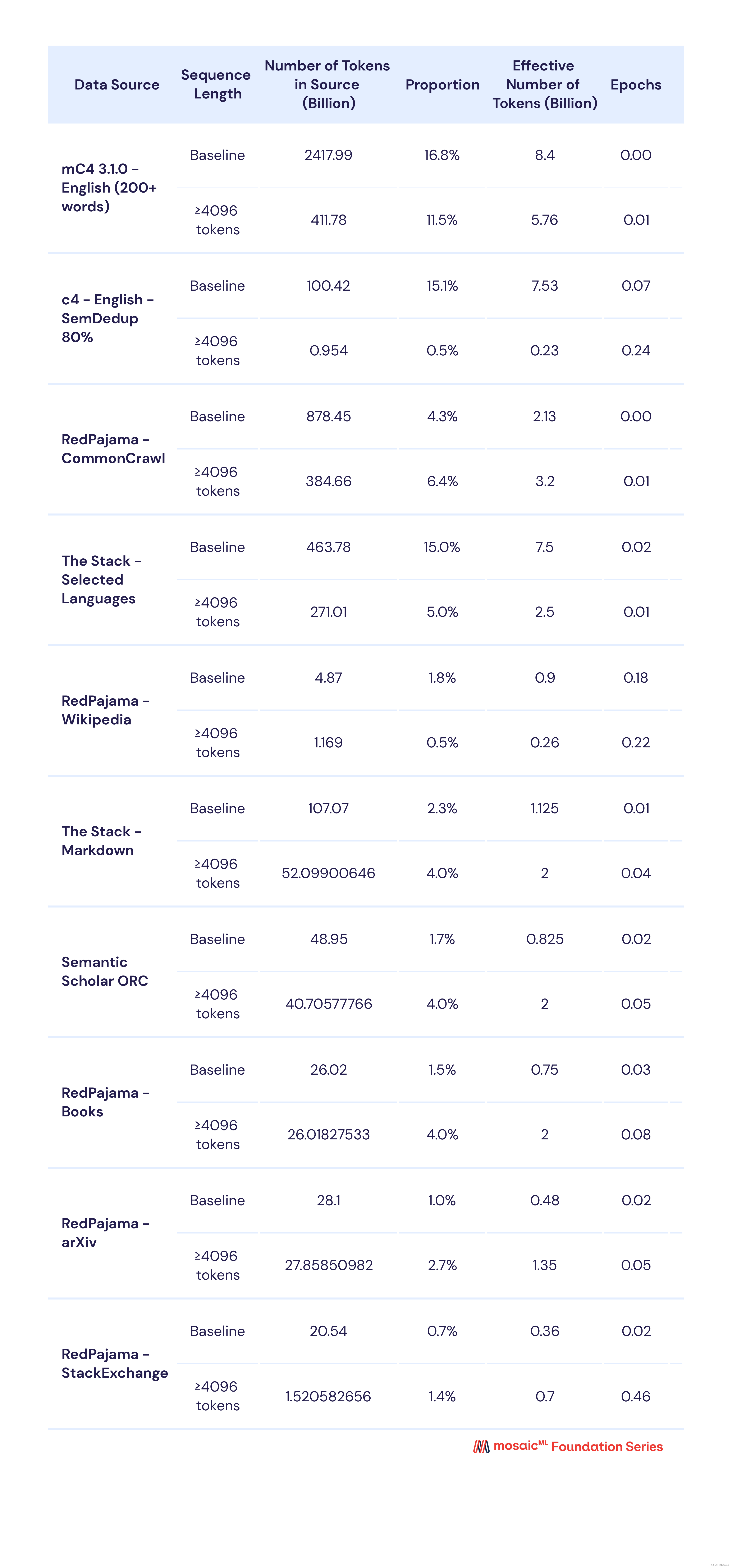
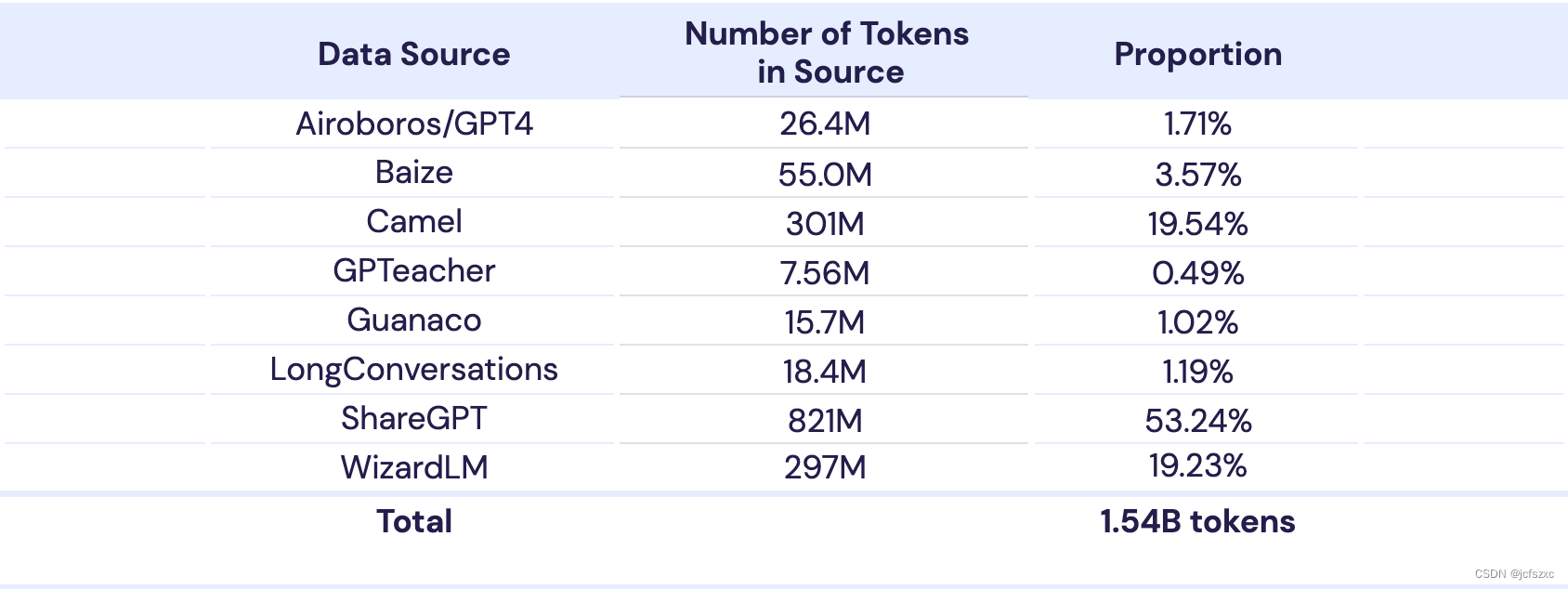
MPT-30B 预训练使用的数据组合与 MPT-7B 非常相似(有关详细信息,请参阅 MPT-7B 博客文章)。对于 2k 上下文窗口预训练,我们使用来自与 MPT-7B 模型相同的 10 个数据子集的 1T 标记(表 1),但比例略有不同。

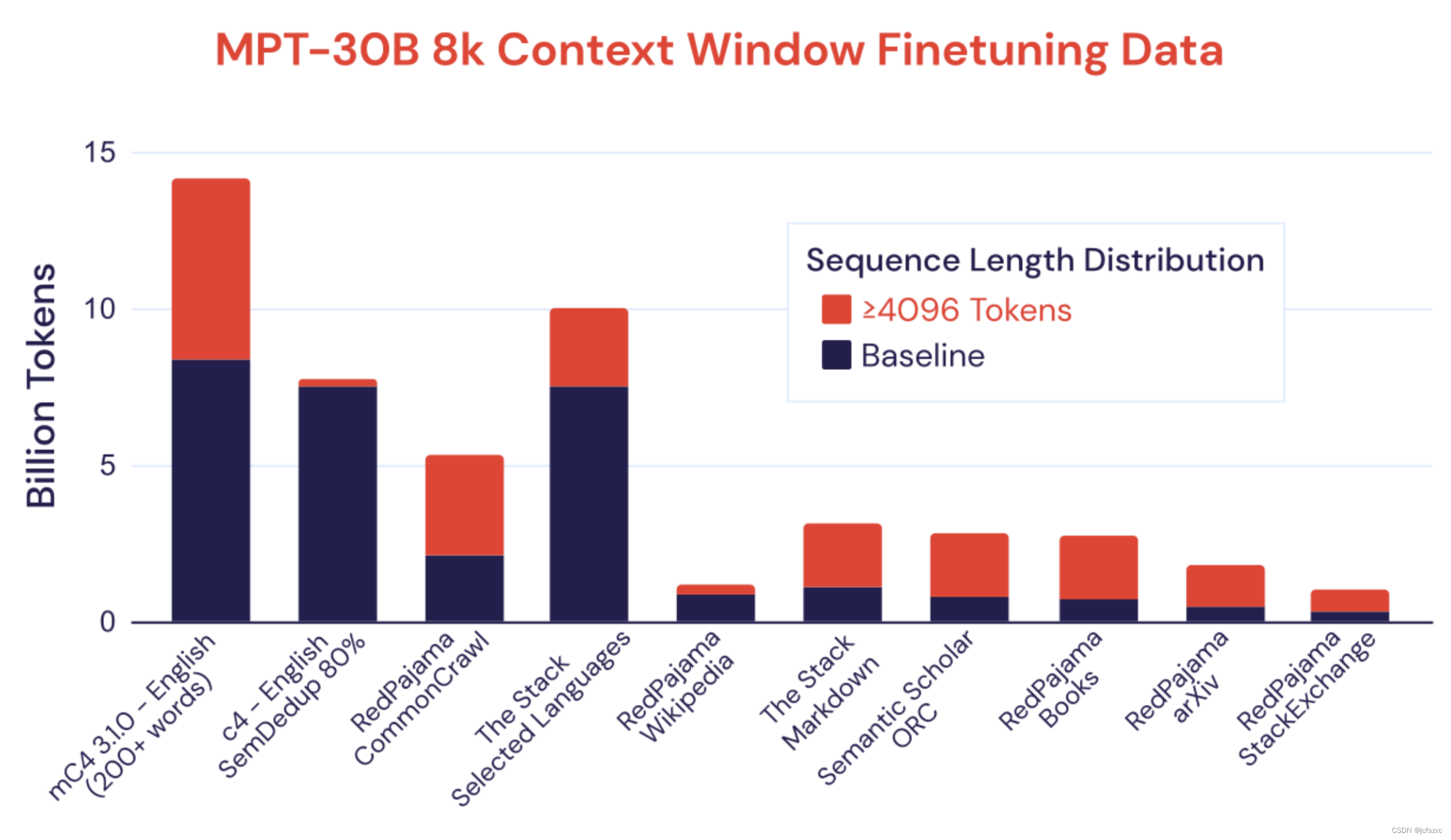
对于 8k 上下文窗口微调,我们从用于 2k 上下文窗口预训练的相同 10 个子集创建了两个数据混合(图 1)。第一个 8k 微调组合与 2k 预训练组合类似,但我们将代码的相对比例增加了 2.5 倍。为了创建第二个 8k 微调组合(我们将其称为“长序列”组合),我们从 10 个预训练数据子集中提取了长度≥ 4096 个标记的所有序列。然后我们对这两种数据混合的组合进行微调。有关 8k 上下文窗口微调数据的更多详细信息,请参阅附录。
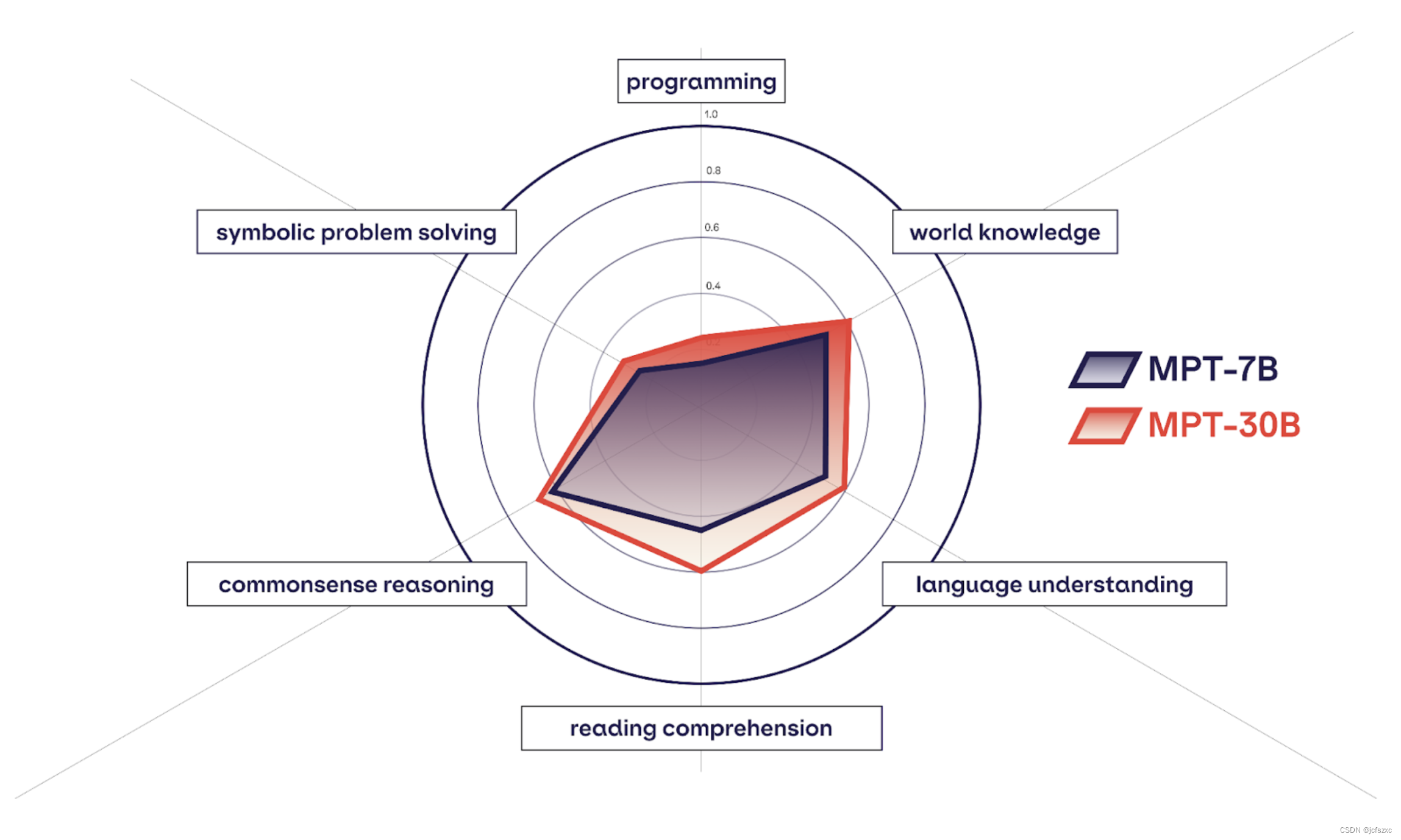
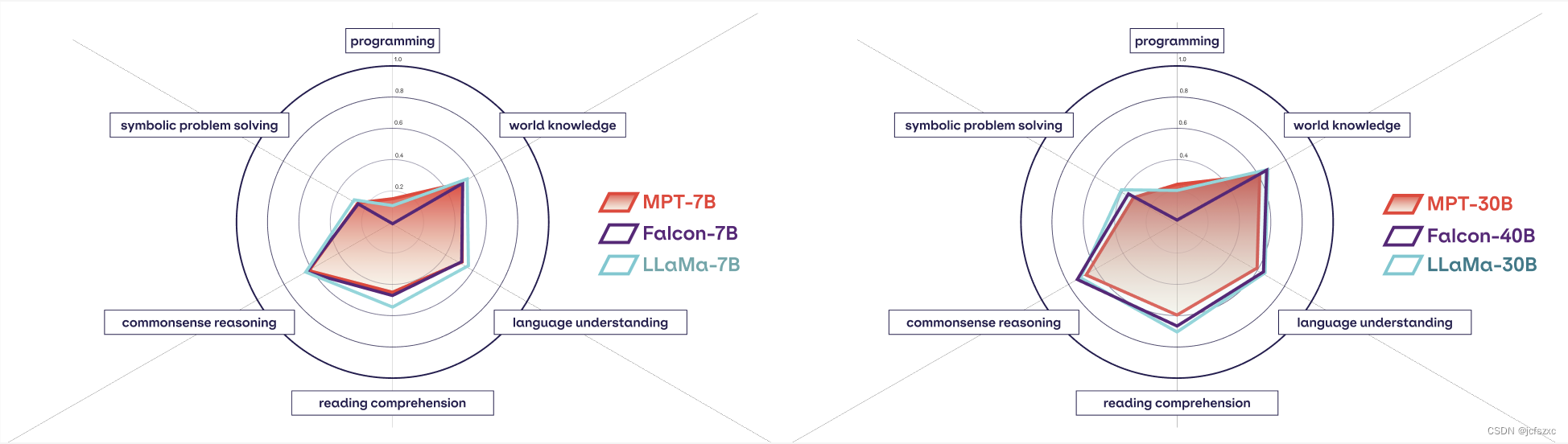
在图2中,我们测量了这六大核心能力,发现MPT-30B在各个方面都比MPT-7B有显着提升。在图 3 中,我们对类似大小的 MPT、LLaMa 和 Falcon 模型进行了相同的比较。总体而言,我们发现不同系列的 7B 型号非常相似。但 LLaMa-30B 和 Falcon-40B 的文本能力略高于 MPT-30B,这与它们较大的预训练预算是一致的:
- MPT-30B FLOPs ~= 6 * 30e9 [参数] * 1.05e12 [令牌] = 1.89e23 FLOPs
- LLaMa-30B FLOPs ~= 6 * 32.5e9 [params] * 1.4e12 [tokens] = 2.73e23 FLOPs (多1.44倍)
- Falcon-40B FLOPs ~= 6 * 40e9 [参数] * 1e12 [令牌] = 2.40e23 FLOps (1.27 倍以上)
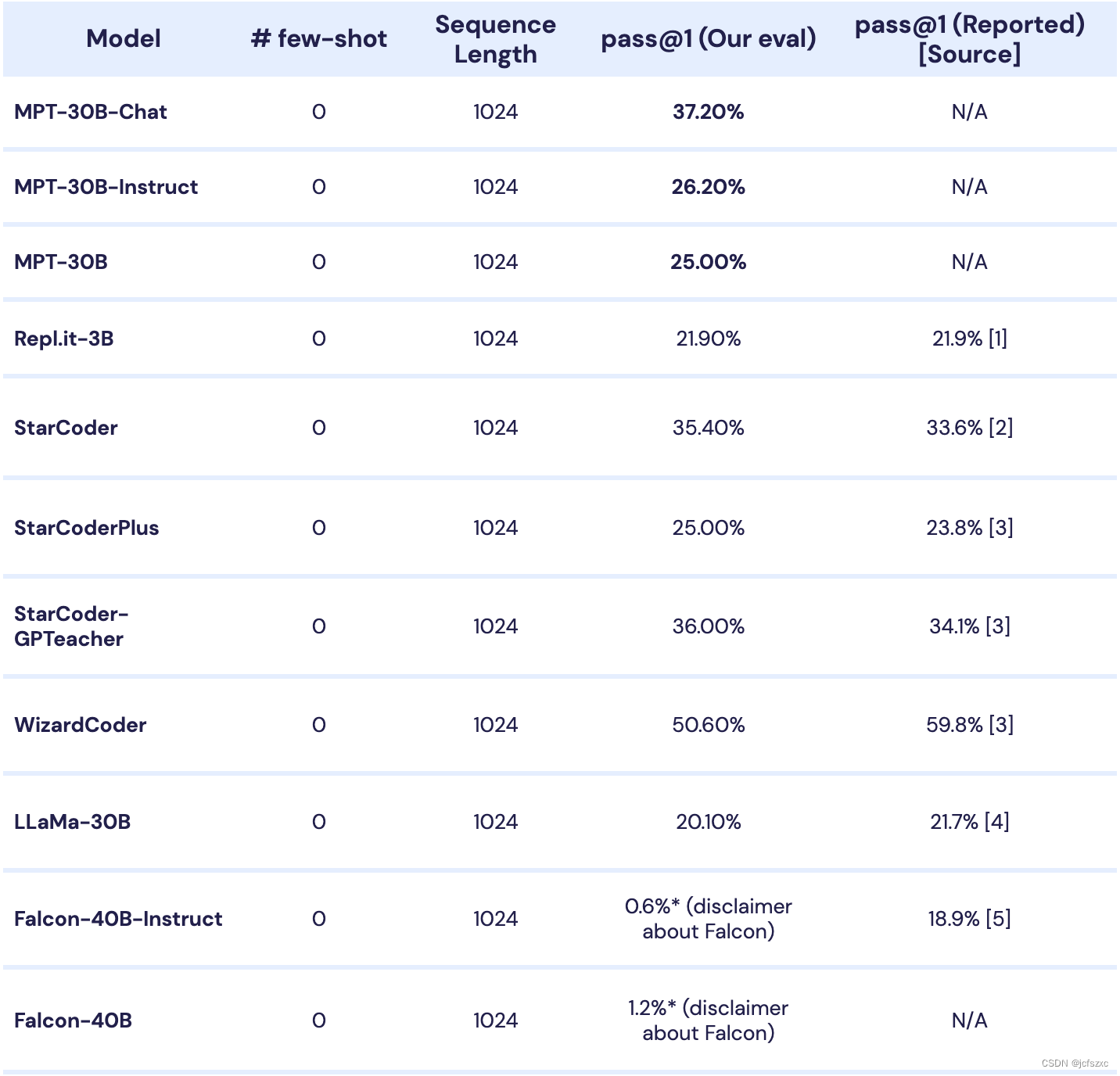
另一方面,我们发现 MPT-30B 在编程方面明显更好,这归功于其包含大量代码的预训练数据混合。我们在表 2 中进一步深入探讨了编程能力,其中我们将 MPT-30B、MPT-30B-Instruct 和 MPT-30B-Chat 的 HumanEval 分数与现有开源模型(包括为代码生成而设计的模型)进行了比较。我们发现 MPT-30B 模型的编程能力非常强,MPT-30B-Chat 的性能优于除 WizardCoder 之外的所有模型。我们希望这种文本和编程功能的结合将使 MPT-30B 模型成为社区的流行选择。
最后,在表 3 中,我们展示了 MPT-30B 如何在原始 GPT-3 论文中提供的较小评估指标集上优于 GPT-3。最初发布后大约 3 年,我们很自豪能够以更小的模型(GPT-3 参数的 17%)和显着更少的训练计算(GPT-3 FLOPs 的 60%)超越这个著名的基线。
如需更详细的评估数据,或者如果您想重现我们的结果,您可以在此处查看我们在 LLM Foundry 评估工具中使用的原始数据和脚本。请注意,我们仍在完善 HumanEval 方法,并将很快通过 Composer 和 LLM-Foundry 发布。

MPT-30B-Instruct

LLM 预训练教导模型根据提供的输入继续生成文本。但在实践中,用户希望法学硕士将输入视为要遵循的说明。指令微调是训练法学硕士遵循指令的过程。通过减少对巧妙提示工程的依赖,指令微调使法学硕士更容易获得、直观且立即可用。指令微调的进展是由 FLAN、P3、Alpaca 和 Dolly-15k 等开源数据集推动的。
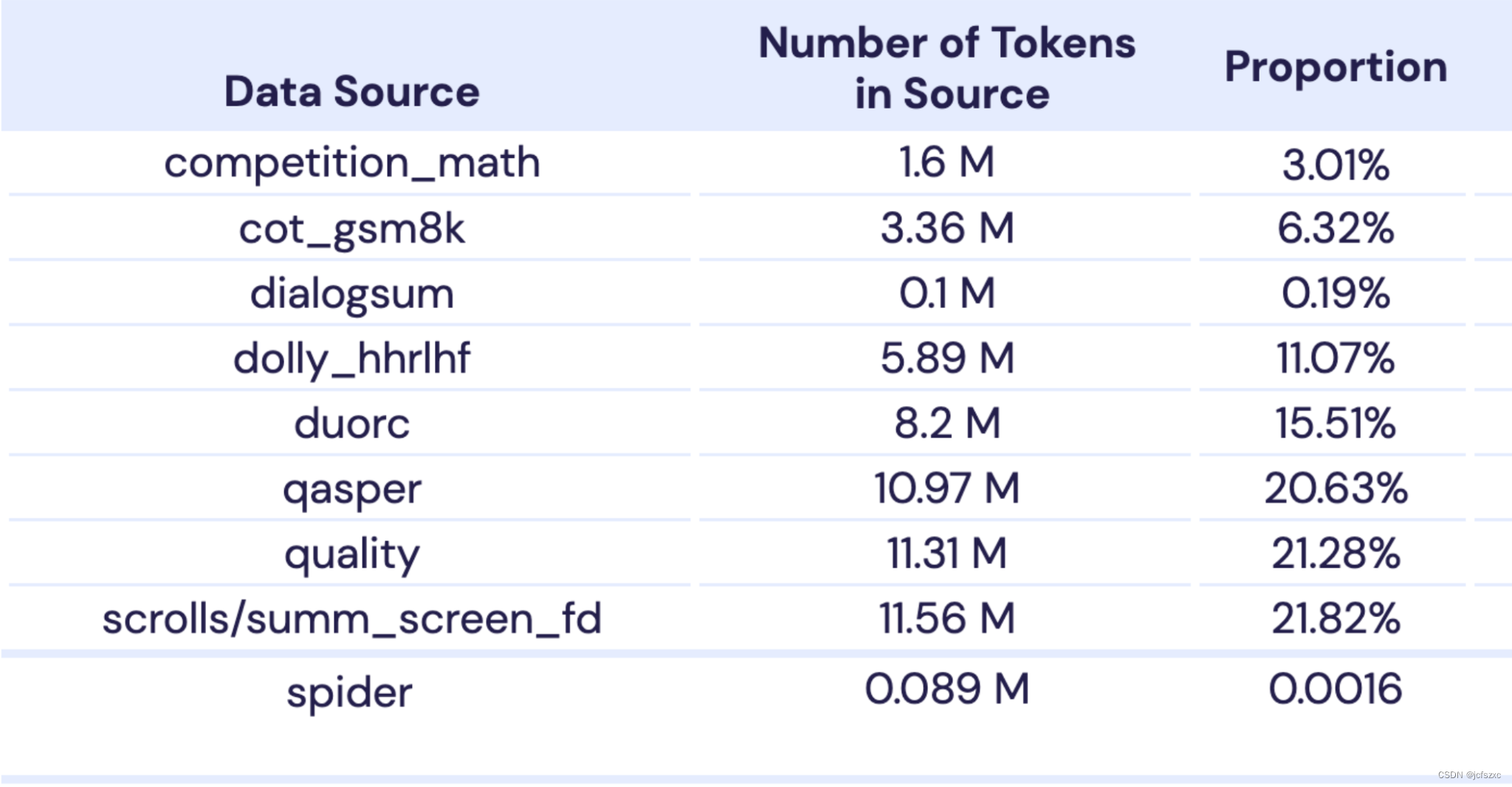
我们创建了一个商业可用的、遵循指令的模型变体,称为 MPT-30B-Instruct。我们喜欢 Dolly 的商业许可,但我们想添加更多训练数据,因此我们使用 Anthropic 的 Helpful & Harmless 数据集的子集来增强 Dolly,将数据集大小加倍,同时保留商业 CC-By-SA-3.0 许可。然后,为了利用 MPT-30B 的 8,192 个 token 上下文长度,我们使用一些开源数据集进一步增强了数据:CompetitionMath、GradeSchoolMath、DialogSum、DuoRC、QASPER、QuALITY、SummScreen 和 Spider。
这个新的指令跟踪数据集是对我们用于训练 MPT-7B-Instruct 的数据集的改进,我们计划在不久的将来发布更新的 MPT-7B-Instruct-v2,使其与 MPT-30B 持平-指导。
MPT-30B-Chat
我们还创建了 MPT-30B-Chat,这是 MPT-30B 的对话版本。 MPT-30B-Chat 已经在大量聊天数据集上进行了微调,确保它为各种对话任务和应用程序做好了准备。组合微调数据集由 15.4 亿个 token 组成,模型训练了 6 个 epoch。数据集采用ChatML格式,提供了一种便捷、标准化的方式将系统消息传递给模型,有助于防止恶意提示注入。
MPT-30B-Chat 是一个研究工件,不适合商业用途,因此我们相应地使用了非商业 CC-By-NC-SA-4.0 许可证。我们发布它是因为它展示了 MPT-30B 与大型、高质量微调数据集结合时的强大功能。
尽管被训练为通用会话模型,MPT-30B-Chat 的编程能力也令人惊讶,在 HumanEval 上得分为 37.2%;这使得它凌驾于WizardCoder 之外的几乎所有开源模型之上。更多详情请参见上表2!
使用 MosaicML Inference 部署 MPT-30B 模型
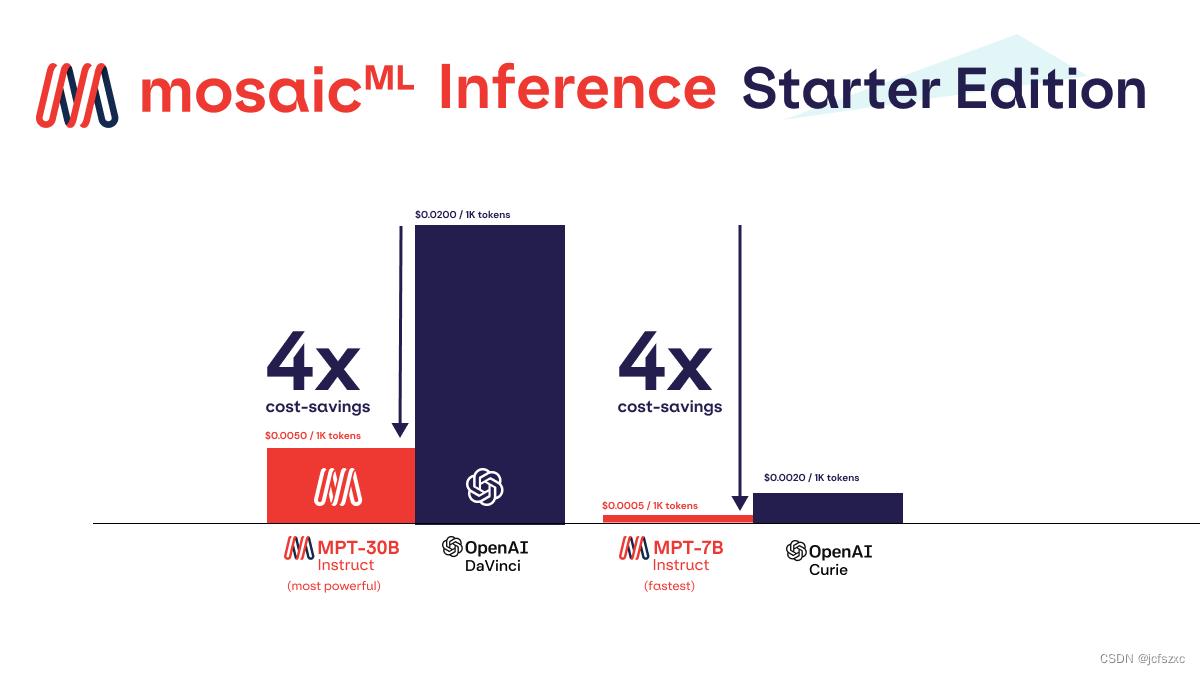
随着 MosaicML 推理服务的推出,我们为 MPT 和 Llama 等开源模型提供低延迟、高吞吐量的托管。您可以使用我们的推理软件堆栈在 MosaicML 硬件或您自己的私有硬件上为这些模型提供服务。借助 MosaicML Inference,您可以向 MosaicML 托管的端点发送 MPT-7B-Instruct、MPT-30B-Instruct 以及其他开源文本生成和嵌入模型的 API 请求。这些端点按代币定价,并且比相同质量的同类 OpenAI API 便宜得多(见图 6)。 MosaicML Inference 是快速制作人工智能功能原型的绝佳选择。如果可以接受与第三方 API 共享数据,那么它也可能是一个合适的选择。
通过 MosaicML 培训定制 MPT-30B
MPT-30B 具有开箱即用的强大生成能力。但为了在特定任务中获得最佳性能,我们建议对您的私人数据进行微调 MPT-30B。这个过程可以在几个小时内完成,只需几百美元。
对于更高级的用例,例如自定义语言、自定义域(例如 Replit 的代码生成模型)或自定义任务(长文档问答),您可以通过添加特定于域的预训练或从头开始训练自定义模型。
LLM Foundry
为了使自定义语言模型的训练尽可能简单,我们将可用于生产的训练代码开源为 LLM Foundry。这与我们的 NLP 团队用于构建 MPT-7B 和 MPT-30B 的代码库完全相同。该存储库使用 Composer、StreamingDataset 和 FSDP 在任意数量的 GPU 上训练任意大小的自定义模型。它还可以直接从您的私有对象存储流式传输数据,并轻松将模型导出到 HuggingFace、ONNX 或 FasterTransformer。 LLM Foundry 已经在云端 A100 和 H100 上经过了实际考验,我们正在快速增加对更多硬件选项的支持。
LLM Foundry 还包括用于根据标准评估指标和/或自定义数据评估模型的脚本。得益于我们的多 GPU 和 FSDP 支持,评估速度非常快 - 您可以在几分钟内离线测量评估指标,甚至可以在训练期间实时测量评估指标,从而为您提供有关模型性能的即时反馈。
无论您想要进行小型微调运行还是从头开始训练大型模型,LLM Foundry 都能高效处理所有这些工作负载。查看我们的公开训练表现和推理表现表!
作为 MosaicML 的客户,您还可以访问最新的配方,以确保您的训练运行稳定(无损失峰值)以及我们的 MCLI 编排软件。后者可以优雅地处理硬件故障和自动恢复,这样您就不会浪费计算或需要照顾您的运行。
下一步是什么?
准备好试用我们的新型 MPT-30B 系列了吗?请注意,我们的 Foundation 系列模型完全受 MosaicML 平台支持,为您提供工具和专业知识,以便您在选择的安全云上轻松高效地构建、定制和部署。在此处注册演示。请继续关注我们的基础系列中的更多型号!
附录
致谢
我们衷心感谢 OCI 的朋友,他们托管了我们用来完成 MPT-30B 初级训练阶段的 NVIDIA A100 GPU。
我们还要衷心感谢 CoreWeave 的朋友,他们托管了我们用来完成 MPT-30B 8k 上下文训练阶段的 NVIDIA H100 GPU,并在我们加快新 GPU 架构的速度时为我们提供了支持。
我们还衷心感谢 AI2 的朋友,他们在我们开发 MPT 系列模型时分享了非常宝贵的技术专业知识。
数据
MPT-30B 8k 上下文窗口微调数据
对于 8k 上下文窗口微调,我们采用每个数据子集并提取具有至少 4096 个标记的所有样本,以创建新的“长序列”数据混合。然后,我们对长序列和原始数据混合的组合进行微调。
MPT-30B-指令微调数据
MPT-30B-聊天微调数据
聊天微调数据。请注意,每个标记出现了 6 次。这些代币计数包括提示及其目标响应,因此并非所有 1.54B 代币都会产生损失。
评估
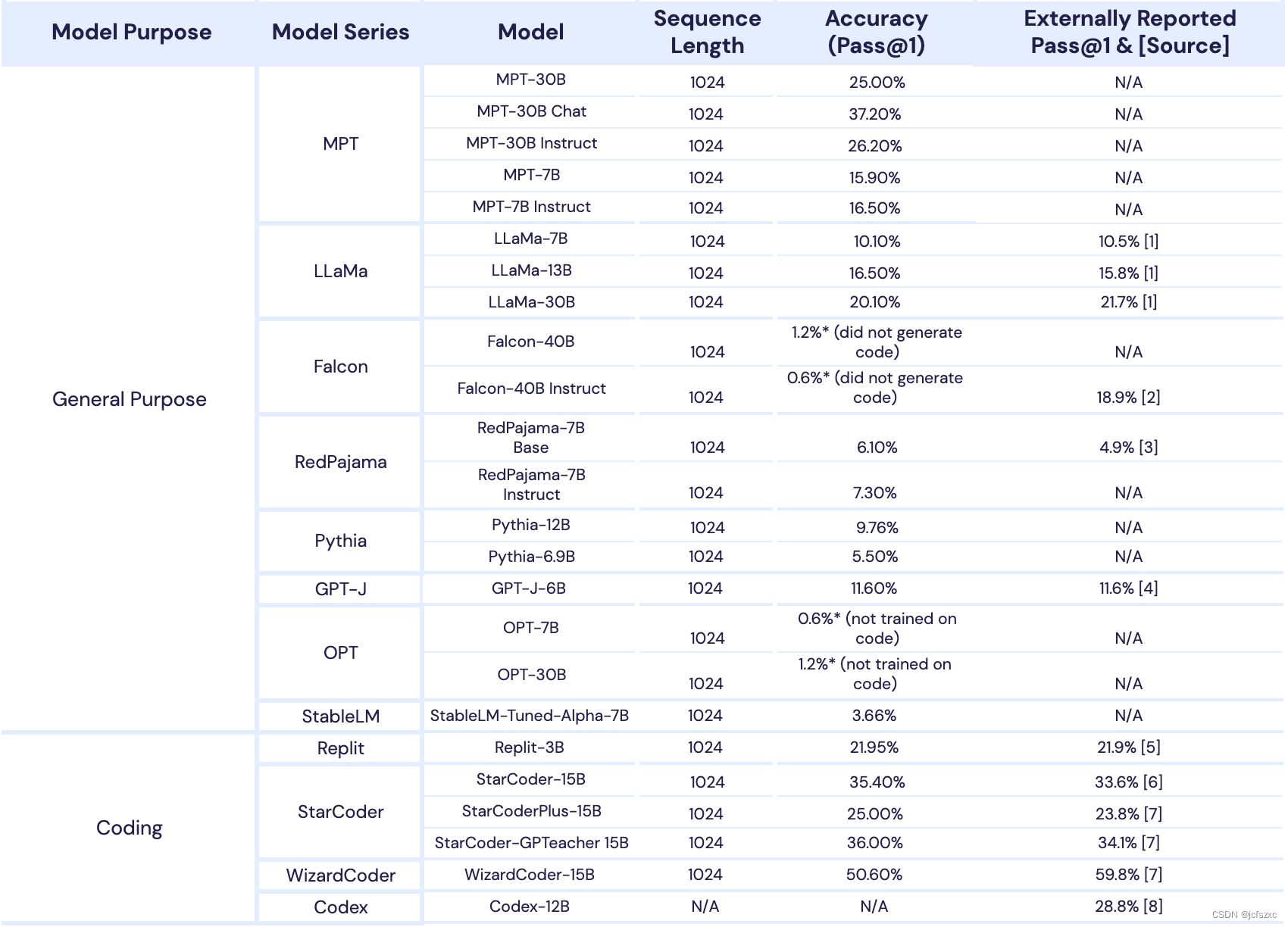
MPT-30B 与我们的代码评估套件上的开源模型。我们在代码提示的 HumanEval 数据集上测试每个模型,使用零样本评估和使用 pass@1 指标的基准测试,或者仅允许生成一个可能的代码延续时模型通过的测试用例的百分比。我们还提供引用的外部值来验证我们内部代码评估套件的可复制性,该套件将在 Composer/LLM-Foundry 的未来版本中作为开源发布。
Falcon 代码评估免责声明
在我们的评估框架中,Falcon-40B 和 Falcon-40B-Instruct 似乎是类似大小模型中的异常值。虽然我们的大多数自我评估分数与外部结果相匹配,但我们的 Falcon-40B-Instruct 通过率明显低于 WizardCoder 中报告的通过率。我们对所有模型使用相同的提示和 LLM Foundry 评估工具。如果您对如何更好地提示/使用Falcon-40B或更多我们可以参考的外部HumanEval分数有建议,请联系我们!
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法