python毕业设计 深度学习OCR中文识别 - opencv python_定位中文文字区域的模型-程序员宅基地
0 前言
这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
**基于深度学习OCR中文识别系统 **
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
选题指导,项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md
1 课题背景
在日常生产生活中有大量的文档资料以图片、PDF的方式留存,随着时间推移 往往难以检索和归类 ,文字识别(Optical Character Recognition,OCR )是将图片、文档影像上的文字内容快速识别成为可编辑的文本的技术。
高性能文档OCR识别系统是基于深度学习技术,综合运用Tensorflow、CNN、Caffe 等多种深度学习训练框架,基于千万级大规模文字样本集训练完成的OCR引擎,与传统的模式识别的技术相比,深度学习技术支持更低质量的分辨率、抗干扰能力更强、适用的场景更复杂,文字的识别率更高。
本项目基于Tensorflow、keras/pytorch实现对自然场景的文字检测及OCR中文文字识别。
2 实现效果
公式检测

纯文字识别

3 文本区域检测网络-CTPN
对于复杂场景的文字识别,首先要定位文字的位置,即文字检测。
简介
CTPN是在ECCV 2016提出的一种文字检测算法。CTPN结合CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,效果如图1,是目前比较好的文字检测算法。由于CTPN是从Faster RCNN改进而来,本文默认读者熟悉CNN原理和Faster RCNN网络结构。

相关代码
def main(argv):
pycaffe_dir = os.path.dirname(__file__)
parser = argparse.ArgumentParser()
# Required arguments: input and output.
parser.add_argument(
"input_file",
help="Input txt/csv filename. If .txt, must be list of filenames.\
If .csv, must be comma-separated file with header\
'filename, xmin, ymin, xmax, ymax'"
)
parser.add_argument(
"output_file",
help="Output h5/csv filename. Format depends on extension."
)
# Optional arguments.
parser.add_argument(
"--model_def",
default=os.path.join(pycaffe_dir,
"../models/bvlc_reference_caffenet/deploy.prototxt.prototxt"),
help="Model definition file."
)
parser.add_argument(
"--pretrained_model",
default=os.path.join(pycaffe_dir,
"../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel"),
help="Trained model weights file."
)
parser.add_argument(
"--crop_mode",
default="selective_search",
choices=CROP_MODES,
help="How to generate windows for detection."
)
parser.add_argument(
"--gpu",
action='store_true',
help="Switch for gpu computation."
)
parser.add_argument(
"--mean_file",
default=os.path.join(pycaffe_dir,
'caffe/imagenet/ilsvrc_2012_mean.npy'),
help="Data set image mean of H x W x K dimensions (numpy array). " +
"Set to '' for no mean subtraction."
)
parser.add_argument(
"--input_scale",
type=float,
help="Multiply input features by this scale to finish preprocessing."
)
parser.add_argument(
"--raw_scale",
type=float,
default=255.0,
help="Multiply raw input by this scale before preprocessing."
)
parser.add_argument(
"--channel_swap",
default='2,1,0',
help="Order to permute input channels. The default converts " +
"RGB -> BGR since BGR is the Caffe default by way of OpenCV."
)
parser.add_argument(
"--context_pad",
type=int,
default='16',
help="Amount of surrounding context to collect in input window."
)
args = parser.parse_args()
mean, channel_swap = None, None
if args.mean_file:
mean = np.load(args.mean_file)
if mean.shape[1:] != (1, 1):
mean = mean.mean(1).mean(1)
if args.channel_swap:
channel_swap = [int(s) for s in args.channel_swap.split(',')]
if args.gpu:
caffe.set_mode_gpu()
print("GPU mode")
else:
caffe.set_mode_cpu()
print("CPU mode")
# Make detector.
detector = caffe.Detector(args.model_def, args.pretrained_model, mean=mean,
input_scale=args.input_scale, raw_scale=args.raw_scale,
channel_swap=channel_swap,
context_pad=args.context_pad)
# Load input.
t = time.time()
print("Loading input...")
if args.input_file.lower().endswith('txt'):
with open(args.input_file) as f:
inputs = [_.strip() for _ in f.readlines()]
elif args.input_file.lower().endswith('csv'):
inputs = pd.read_csv(args.input_file, sep=',', dtype={
'filename': str})
inputs.set_index('filename', inplace=True)
else:
raise Exception("Unknown input file type: not in txt or csv.")
# Detect.
if args.crop_mode == 'list':
# Unpack sequence of (image filename, windows).
images_windows = [
(ix, inputs.iloc[np.where(inputs.index == ix)][COORD_COLS].values)
for ix in inputs.index.unique()
]
detections = detector.detect_windows(images_windows)
else:
detections = detector.detect_selective_search(inputs)
print("Processed {} windows in {:.3f} s.".format(len(detections),
time.time() - t))
# Collect into dataframe with labeled fields.
df = pd.DataFrame(detections)
df.set_index('filename', inplace=True)
df[COORD_COLS] = pd.DataFrame(
data=np.vstack(df['window']), index=df.index, columns=COORD_COLS)
del(df['window'])
# Save results.
t = time.time()
if args.output_file.lower().endswith('csv'):
# csv
# Enumerate the class probabilities.
class_cols = ['class{}'.format(x) for x in range(NUM_OUTPUT)]
df[class_cols] = pd.DataFrame(
data=np.vstack(df['feat']), index=df.index, columns=class_cols)
df.to_csv(args.output_file, cols=COORD_COLS + class_cols)
else:
# h5
df.to_hdf(args.output_file, 'df', mode='w')
print("Saved to {} in {:.3f} s.".format(args.output_file,
time.time() - t))
CTPN网络结构

4 文本识别网络-CRNN
CRNN 介绍
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。
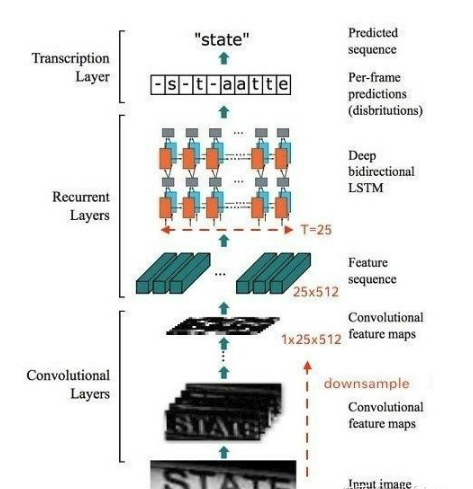
整个CRNN网络结构包含三部分,从下到上依次为:
- CNN(卷积层),使用深度CNN,对输入图像提取特征,得到特征图;
- RNN(循环层),使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;
- CTC loss(转录层),使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
CNN
卷积层的结构图:
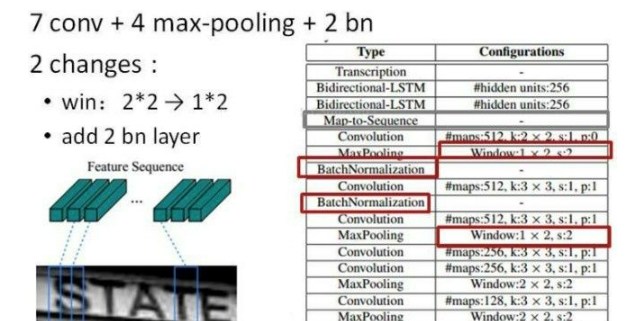
这里有一个很精彩的改动,一共有四个最大池化层,但是最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次(除以 2^4 ),而宽度则只减半了两次(除以2^2),这是因为文本图像多数都是高较小而宽较长,所以其feature map也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。
CRNN 还引入了BatchNormalization模块,加速模型收敛,缩短训练过程。
输入图像为灰度图像(单通道);高度为32,这是固定的,图片通过 CNN 后,高度就变为1,这点很重要;宽度为160,宽度也可以为其他的值,但需要统一,所以输入CNN的数据尺寸为 (channel, height, width)=(1, 32, 160)。
CNN的输出尺寸为 (512, 1, 40)。即 CNN 最后得到512个特征图,每个特征图的高度为1,宽度为40。
Map-to-Sequence
我们是不能直接把 CNN 得到的特征图送入 RNN 进行训练的,需要进行一些调整,根据特征图提取 RNN 需要的特征向量序列。
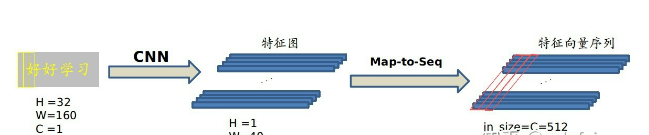
现在需要从 CNN 模型产生的特征图中提取特征向量序列,每一个特征向量(如上图中的一个红色框)在特征图上按列从左到右生成,每一列包含512维特征,这意味着第 i 个特征向量是所有的特征图第 i 列像素的连接,这些特征向量就构成一个序列。
由于卷积层,最大池化层和激活函数在局部区域上执行,因此它们是平移不变的。因此,特征图的每列(即一个特征向量)对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。特征序列中的每个向量关联一个感受野。
如下图所示:

这些特征向量序列就作为循环层的输入,每个特征向量作为 RNN 在一个时间步(time step)的输入。
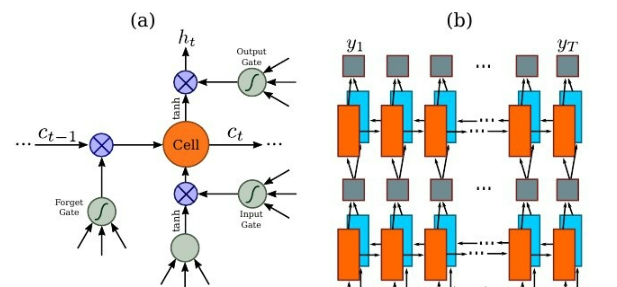
RNN
因为 RNN 有梯度消失的问题,不能获取更多上下文信息,所以 CRNN 中使用的是 LSTM,LSTM 的特殊设计允许它捕获长距离依赖,不了解的话可以看一下这篇文章 对RNN和LSTM的理解。
LSTM 是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象。
这里采用的是两层各256单元的双向 LSTM 网络:
通过上面一步,我们得到了40个特征向量,每个特征向量长度为512,在 LSTM 中一个时间步就传入一个特征向量进行分类,这里一共有40个时间步。
我们知道一个特征向量就相当于原图中的一个小矩形区域,RNN 的目标就是预测这个矩形区域为哪个字符,即根据输入的特征向量,进行预测,得到所有字符的softmax概率分布,这是一个长度为字符类别数的向量,作为CTC层的输入。
因为每个时间步都会有一个输入特征向量 x^T ,输出一个所有字符的概率分布 y^T ,所以输出为 40 个长度为字符类别数的向量构成的后验概率矩阵。
如下图所示:

然后将这个后验概率矩阵传入转录层。
CTC loss
这算是 CRNN 最难的地方,这一层为转录层,转录是将 RNN 对每个特征向量所做的预测转换成标签序列的过程。数学上,转录是根据每帧预测找到具有最高概率组合的标签序列。
端到端OCR识别的难点在于怎么处理不定长序列对齐的问题!OCR可建模为时序依赖的文本图像问题,然后使用CTC(Connectionist Temporal Classification, CTC)的损失函数来对 CNN 和 RNN 进行端到端的联合训练。
相关代码
def inference(self, inputdata, name, reuse=False):
"""
Main routine to construct the network
:param inputdata:
:param name:
:param reuse:
:return:
"""
with tf.variable_scope(name_or_scope=name, reuse=reuse):
# centerlized data
inputdata = tf.divide(inputdata, 255.0)
#1.特征提取阶段
# first apply the cnn feature extraction stage
cnn_out = self._feature_sequence_extraction(
inputdata=inputdata, name='feature_extraction_module'
)
#2.第二步, batch*1*25*512 变成 batch * 25 * 512
# second apply the map to sequence stage
sequence = self._map_to_sequence(
inputdata=cnn_out, name='map_to_sequence_module'
)
#第三步,应用序列标签阶段
# third apply the sequence label stage
# net_out width, batch, n_classes
# raw_pred width, batch, 1
net_out, raw_pred = self._sequence_label(
inputdata=sequence, name='sequence_rnn_module'
)
return net_out
选题指导,项目分享:
https://gitee.com/yaa-dc/warehouse-1/blob/master/python/README.md
智能推荐
CDN架构原理、流量模型、网络调优_cdn 95带宽算法优化-程序员宅基地
文章浏览阅读1k次。详细的知识参考 :https://www.cnblogs.com/zousong/p/10925445.htmlCDN全称:Content Delivery Network或Content Ddistribute Network,即内容分发网络基本思路:尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离.._cdn 95带宽算法优化
nodejs安装之后,npm命令拒绝访问_npm -v 拒绝访问-程序员宅基地
文章浏览阅读5.7k次。@[T标题OC](这里写自定义目录标题)欢迎使用Markdown编辑器你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。新的改变我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博..._npm -v 拒绝访问
单片机通信接口:UART、I2C、SPI、TTL、RS232、RS422、RS485、CAN、USB_单片机通讯接口-程序员宅基地
文章浏览阅读1.5w次,点赞40次,收藏325次。参考资料:这些单片机接口,一定要熟悉:UART、I2C、SPI、TTL、RS232、RS422、RS485、CAN、USB、SD卡秒懂所有USB接口类型,USB接口大全1. UARTUART(通用异步收发器)指的是一种物理接口形式(硬件)。UART是异步,全双工串口总线。它比同步串口复杂很多。有两根线,一根TXD用于发送,一根RXD用于接收。UART的串行数据传输不需要使用时钟信号来同步传输,而是依赖于发送设备和接收设备之间预定义的配置。对于发送设备和接收设备来说,两者的串行通信配置应该设_单片机通讯接口
11个经典运放电路_运算放大器11种经典电路-程序员宅基地
文章浏览阅读10w+次,点赞205次,收藏1.3k次。运算放大器组成的电路五花八门,令人眼花瞭乱。工程师在分析它的工作原理时常抓不住核心,令人头大。为此小编特地搜罗天下运放电路之应用,来个“庖丁解牛”,希望各位看完后有所收获。遍观所有模拟电子技术的书籍和课程,在介绍运算放大器电路的时候,无非是先给电路来个定性,比如这是一个同向放大器,然后去推导它的输出与输入的关系,然后得出Vo=(1+Rf)Vi,那是一个反向放大器,然后得出Vo=-Rf*V..._运算放大器11种经典电路
s905各种型号的区别_预行式增压缸和直压增压缸有什么区别?-程序员宅基地
文章浏览阅读359次。玖容增压缸的型号有很多,适用在不同的工作环境中,不同的型号是根据不同的使用环境来设计的。我们从工作原理上来划分,增压缸一般分为预行式增压缸和直压增压缸,它们由于使用的环境不同,使用的场合也有所不同,今天就来和大家来分享一下“预行式增压缸和直压增压缸有什么区别?”。首先我们来说说预行式增压缸和直压增压缸的区别之处:预行式增压缸比直压增压缸多了一段预走行程。将增压器直接设计在气缸的后端,接上气压管路,..._玖容 新浪博客
运维面试题-程序员宅基地
文章浏览阅读8.5k次,点赞10次,收藏98次。NETWORK1 请描述 TCP/IP 协议中主机与主机之间通信的三要素参考答案IP 地址(IP address)子网掩码(subnet mask)IP 路由(IP router)2 请描述 IP 地址的分类及每一类的范围参考答案A 类 1-26B 类 128-191C 类 192-223D 类 224-239 组播(多播)E 类 240-254 科研3 请描述 A、B、..._运维面试题
随便推点
绘制男朋友聊天记录的词云_pythin男友聊天词云-程序员宅基地
文章浏览阅读183次。1 数据获取在消息管理中导出全部数据,得到全部消息记录.txt。2 文本处理只筛选和男朋友的聊天记录,从'消息对象:AI男朋友\n'到'2021-05-06 14:42:52 AI男朋友\n'结束,将其保存在AI.txt中,具体如下:f = open('全部消息记录.txt','r',encoding='utf-8')lines = f.readlines()j = 0for line in lines: if line == '消息对象:AI男朋友\n': fla_pythin男友聊天词云
Linux终端(Terminal)与控制台(Console)的区别_linux c terminal-程序员宅基地
文章浏览阅读976次。Linux终端(Terminal)与控制台(Console)的区别_linux c terminal
制作 linux .deb 安装包_构建deb软件升级包-程序员宅基地
文章浏览阅读371次。ubuntu 制作安装包_构建deb软件升级包
(转载)循序渐进学习嵌入式Linux开发技术-程序员宅基地
文章浏览阅读39次。再次申明,本文是转载,为以后查找留个记号。嵌入式时代已经来临,你还在等什么? ---循序渐进学习嵌入式开发技术最近经常有用人单位给我打来电话,问我这有没有嵌入式Linux方面的开发人员,他们说他们单位急需要懂得在嵌入式linux环境下的软件开发人员,我回答说,现在每年毕业的大学生那么多,还招不到合适的软件开发人员吗?他跟我说,毕业大学生虽然多,但大部分都能力不够,不能达到他们的工作的要...
如何成功在M1 macbook上运行Ubuntu20.04_ubuntu20.04 for m1-程序员宅基地
文章浏览阅读8.3k次,点赞5次,收藏19次。如何在搭载M1芯片的苹果电脑上跑UbuntuParallels官方发布了针对搭载apple silcon M1芯片的Mac的测试版虚拟机,笔者已经成功运行,具体步骤总结如下:第一步 安装测试版 Parallels Desktop需要去官网注册账户然后下载专门的测试软件参考地址:官网地址步骤如下:Meet the new Parallels Desktop (官网页面To run a virtual machine on a new Mac computer with the Apple M1 _ubuntu20.04 for m1
STM32单片机智能手环心率计步器体温-程序员宅基地
文章浏览阅读654次,点赞9次,收藏15次。STM32F103C8T6单片机核心板电路、ADXL345传感器电路、心率传感器电路、温度传感器和lcd1602电路组成。通过重力加速度传感器ADXL345检测人的状态,计算出走路步数、走路距离和平均速度。过心率传感器实时检测心率,通过温度传感器检测温度。通过LCD1602实时显示步数、距离和平均速度、心率以及温度值。主要学习ADXL345,心率传感器等等。