Ubuntu20.04下深度学习环境配置(持续维护)_ubuntu深度学习-程序员宅基地
技术标签: cuda ubuntu 系统安装 深度学习 linux
Ubuntu20.04下深度学习环境配置
Ubuntu20.04下深度学习环境配置
这篇文章记录了我在配置深度学习环境时的坑(会持续维护,遇到坑时会回来补)。具体操作和安装包在文章中都有(可能不是最全面的,但一定都指出了在哪里下载,怎么操作)。先介绍一下我的配置环境:Ubuntu20.04, X86_64, RTX3090, Nvidia-smi 455, Cuda 11.1。不同版本的安装过程大同小异,如果有需要注意的地方,会在文中指明。
安装过程共分为以下几大部分:1. 换国内源;2. gpu驱动;3. anaconda安装;4. pytorch-cpu安装;5. cuda安装;6. cudnn安装;7. pytorch-gpu安装;8. tensorflow安装(cpu+gpu)。
【注】:
- 以上8个部分可以交叉安装(但最好按顺序进行,如果你是复制粘贴党的话,许多安装是建立在之前的基础上的,直接复制容易导致错误)。如果有哪部分看不懂我的文章,可以多看看别人对这部分的安装教程,总有一款可以安好。
- 若代码中出现xxx,为Ubuntu中user的名称全拼或缩写,是你设置的用户名。/home/xxx/,将xxx替换为你的用户名。
- 安装的东西很多,而且99.999999999%的可能你会出现本文中没有提及的error提示(尽管本文中尽可能指出了你可能会遇到的bug),不要慌!正常,每个人的硬件设备和软件以及之前的使用情况都不一致,所以都会出现不一样的情况。这时复制粘贴你的error提示,找度娘,解决了这个bug,然后回来继续看该文执行后的安装过程。
- 在正式安装前,以上这些话如果你是第一次配环境希望你看一看,做好心理准备,尽可能少踩点坑。超级感谢yzw!!!从深坑里捞了我一把
- 更新:感谢评论区各位小伙伴的指路!我一个人走过的坑和写出的配置过程难免有不足,各位在配置时也多看看评论区啊,大家的指路很有用!
一、换国内源
深度学习环境配置过程中,需要下载很多东西,直接用默认源下载速度很绝望,所以我们直接在最开始就换源,解决一切下载慢的问题。
常见的国内源有清华源,阿里源等。大多都推荐使用阿里源。
换源的方式有2种。
[注]:最近发现阿里,清华源也超级慢,强烈推荐尝试豆瓣源!!!神快!!每次安装时用这条语句:pip install 包名 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com。(详细使用可参考八、tensorflow安装)
- 命令行换源
(略麻烦,但有助于熟悉之后的安装环境)
使用gedit文本编辑器打开sources.list进行修改。(还有的教程用vim打开sources.list,其实都可以,但如果ubuntu是刚装的系统,是没有vim的)
\\打开Ubuntu的终端
$ sudo gedit /etc/apt/sources.list
将目前的源全部注释掉,即每行开头没有“#”的都加上#。
然后打开该网页Ubuntu阿里源,选择自己对应的Ubuntu版本号将下面的源进行复制粘贴到刚刚打开的sources.list文件中。

换完后别忘了更新一下。
$sudo apt-get update
$sudo apt-get upgrade
这里顺便下载vim文本编辑器,之后会用到。
$sudo apt-get Install vim
- 图形界面进行换源。可参考图形界面换源
二、gpu驱动
gpu驱动安装分为:1. 禁用nouveau, 2. 卸载旧的驱动(如果你是第一次安装驱动,这步可以省略),3.gcc安装,4,安装驱动
【注】:这部分参考https://www.cnblogs.com/fanminhao/p/8902296.html。
- 禁用nouveau
Ubuntu系统集成的显卡驱动程序是nouveau,它是第三方为NVIDIA开发的开源驱动,我们需要先将其屏蔽才能安装NVIDIA官方驱动。 所以我们要先把驱动加到黑名单blacklist.conf里。
// 修改属性
$sudo chmod 666 /etc/modprobe.d/blacklist.conf
//用gedit打开
$sudo gedit /etc/modprobe.d/blacklist.conf
// 在最后一行加入以下几句,保存退出
blacklist vga16fb
blacklist nouveau
blacklist rivafb
blacklist rivatv
blacklist nvidiafb
// 对刚才修改的文件进行更新
$sudo update-initramfs -u
记得重启计算机,打开终端检查nouveau是否被禁用
$lsmod | grep nouveau \\若执行完该句,没有任何输出,则nouveau被成功禁用
- 卸载旧的驱动
如果你是第一次安装gpu驱动,这一步可以省略。当然如果你不是第一次安装驱动,亲测也可以忽略这一步。
$sudo apt-get remove --purge nvidia*
执行完上述命令后会有提示有残留,按照提示进行删除。
- 安装gcc
必须先安装gcc, 才能安装gpu驱动。
$sudo apt-get install build-essential \\安装gcc,不要怀疑,就是build-essential,我也不知道为啥
$gcc --version \\检查gcc是否安装成功
这里我只安装了gcc,gpu驱动就可以成功安装了,如果你执行到下面,提示你make,g++没有安装的话,再回来执行以下语句进行安装即可。
$sudo apt-get install g++
$sudo apt-get install make
- 下载对应版本的gpu驱动
安装gpu驱动的方法分为2种:ppa源安装和利用run文件进行安装。
这里推荐使用run文件安装。因此需要根据你的显卡类型选择合适的run文件下载,官网下载链接(速度较快,可直接使用):gpu驱动下载链接.


- 安装驱动
先按Ctrl+Alt+F1,关闭图形界面(过程中出现星号则证明需要输入密码)。再在新出现的界面输入以下命令:
$sudo service lightdm stop
然后cd进入到下载好的.run文件目录中(我安装的是Ubuntu20.04中文版,所以直接下载后的目录为/home/xxx/下载,但是这里不会正常显示中文,因此推荐把下载后的.run文件换个位置再进行下面的操作。
//以移动后的目录为/homg/xxx/为例
$cd /home/xxx/
//修改权限
$sudo chmod a+x NVIDIA-Linux-x86_64-xxx.run
//执行安装
$sudo ./NVIDIA-Linux-x86_64-xxx.run -no-x-check -no-nouveau-check -no-opengl-files
过程中根据提示,选择Accept等。
- 完成安装并验证
//启动图形界面
$sudo service lightdm start
再按Ctrl+Alt+F7回到图形界面即可,这里一定要先按住Ctrl+Alt,再按F7,不然容易黑屏(我每次这个时候只能强制重启了)
//执行此语句,出现显卡信息则证明安装成功。
$nvidia-smi

7. 注意
如果你不是第一次安装驱动,并且这次安装驱动已经距离上次安装已有较久的时间了,尽可能重新安装最新默认的gcc和在官网重新下载驱动。(我就是存了很久前下载的驱动,结果和GCC版本不匹配,一直安装出现ERROR)
撒花!!!gpu驱动已安装完成!
三、Anaconda安装
- 安装Anaconda
已经在windows/Mac os系统下安装过anaconda的同学这步就很简单了,链接(下载速度较快): anaconda下载链接.
 下载完成后的文件为Anaconda3-2020.07-Linux-x86_64.sh,会直接存放在“/home/xxx/下载”中。
下载完成后的文件为Anaconda3-2020.07-Linux-x86_64.sh,会直接存放在“/home/xxx/下载”中。
这时我们就对下载的文件进行安装了。
\\cd到Anaconda3-2020.07-Linux-x86_64.sh所在的目录
$cd /home/xxx/下载
\\执行bash进行安装
$bash Anaconda3-2020.07-Linux-x86_64.sh
然后一直按回车键,直到出现“Do you accept the license terms”, 输入“no”
出现“Anaconda3 will now be installed into this location: /home/xxx/anaconda3”,直接按回车键,安装在该目录中。
出现“Do you wish the installer to initialize Anaconda3 by running condo init?”, 输入“no”。
这时anaconda已经基本安装完成了。
- 区分Ubuntu自带python和anaconda中的python
Linux中会自带python, Ubuntu20.04中自带python3,已经没有python2了。这时不区分不影响anaconda的正常使用,但pytorch和tensorflow对这Linux中自带的python3和anaconda中的python的使用需求不同,后期需要进行两者的切换。所以最好在这里就对他们进行区分。
先退回到根目录
$cd ~
在1. 换国内源中已经安装过vim文本编辑器了,这里我们用vim打开.bashrc文件,并进行修改。
$sudo vim .bashrc \\利用vim打开.bashrc文件
输入小写字母i,进行vim的编辑模式。此时可以在.bashrc文件进行编辑了,在文件最后加入以下命令:
alias python3="/usr/bin/python3.8"\\给系统自带的python起一个别名,就叫python3
export PATH="/home/xxx/anaconda3/bin:$PATH"\\anaconda3中的python
然后按下esc键,再输入:wq!进行保存,再按esc键退出vim编辑器。
继续在终端中对刚才修改的. bashrc文件执行以下。
$source .bashrc
试试刚才进行区分的设置。
$python \\本条命令应该启动anaconda3中的python
$exit() \\退出
$python3 \\本条命令应该启动系统的python
$exit() \\退出
进行了这样的区分后,以后可以根据输入的不同对两种python进行任意地切换了。
- 创建Deeplearning的环境
\\这步中Deeplearning可以换成任何你喜欢的名字
$conda create -n Deeplearning python=3.8
\\查看你创建的环境
$conda env list
\\激活创建的环境
$conda activate Deeplearning
\\关闭环境
$conda deactivate
【注】:有时候conda activate Deeplearning语句会提示错误,将该句换为“source activate Deeplearning”即可,之后输入conda的任何命令都可以正常进行了。
四、pytorch-cpu版本安装
为了可以在不使用GPU时也可以方便地对代码进行调试,先安装一个pytorch-cpu版本的。
激活你创建的Deeplearning环境,系统需要下载一些东西,这里会耗费一点时间。
$conda activate Deeplearning
根据你的情况选择合适的pytorch安装语句.链接: 选择合适的pytorch版本进行安装
安装pytorch。尽管我们已经切换了国内源,这里安装还是比较费时。而且需要安装多个包,torch,torchvision,mlk这三个尤其耗时。经验发现:按下“ctrl+c”打断安装,再重复执行以下语句,每次重新开始安装时速度大概率会提升。
\\这里以conda安装为例进行展示,实际上使用pip安装会更快。
$conda install pytorch torchvision cpuonly -c pytorch
安装测试。1. 进入python界面的语句和上一节“区分Ubuntu自带python和anaconda中的python”中你设置的alias有关;2. import torch语句执行后,若无任何提示,撒花!恭喜你:pytorch安装成功!若提示没有该模块,回去检查吧,哪步有问题,再重新开始执行;3. exit(), 退出python执行界面
$python \\进入python执行界面
$import torch \\若无任何提示,安装成功
$exit() \\退出python执行界面
五、cuda安装
- 安装cuda
由于系统不同,每个人安装cuda的语句不尽相同,在该页面中链接: 选择合适的cuda版本进行安装

【注】:根据该选择界面,我下载的是cuda11.1版本,3.3G,而且截止写该文章的时候,cuda11.1还没有镜像文件,我只能等待漫长的几个小时的下载,哭泣。。。如果你需要安装的cuda版本较低,可以在该页面查看自己需要的cuda是哪个版本(点击下载后下载文件的后缀名里有cuda版本号),再百度搜索相应镜像文件下载。

然后直接根据下载页面的语句提示安装即可。
记得在你创建的虚拟环境中进行:
$ conda activate Deeplearning \\Deeplearning是我上面起的名字
如果你像我一样直接在该页面下载cuda.run文件,执行以下2行语句。
\\直接在网页下载cuda
$wget https://developer.download.nvidia.com/compute/cuda/11.1.0/local_installers/cuda_11.1.0_455.23.05_linux.run
\\安装cuda
$sudo sh cuda_11.1.0_455.23.05_linux.run
如果你在其他网站下载的镜像文件,执行以下2行语句。
\\已经下载好cuda.run的镜像文件,先cd到对应目录
$cd /home/xxx/下载 \\默认下载目录
\\安装cuda
$sudo sh cuda_11.1.0_455.23.05_linux.run \\输入完语句后不要着急,稍微等一两分钟
"Do you accept the above EULA?"输入accept

然后将Driver前面的选项按回车,去掉;其他的保持不动,选择“Install”,稍等几分钟就装好了,会出现以下的界面。

- 配置环境
类似于以上章节中区分两种python的环境,这里也要打开.bashrc文件添加路径。
$sudo vim ~/.bashrc \\进入vim界面。输入字母i,进入编辑模式
\\在bashrc文件中输入以下命令,注意修改你的cuda版本
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.1/lib64
export PATH=$PATH:/usr/local/cuda-11.1/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.1
\\输入完成后,点击esc键并输入:wq!,再按esc键退出vim。
\\这时候返回终端了
$source ~/.bashrc \\运行.bashrc文件
- 安装完成检查
nvcc --version
若出现以下的界面,则表示cuda安装完成,撒花!!!
六、cudnn安装
cudnn的安装相比以上过程就简洁多了~但是在Nvidia下载cudnn文件时稍微有点麻烦,你需要先注册一个Nvidia账号,再填写一个调查问卷。

然后才能进入cudnn的正式下载页面。链接: 选择合适的cudnn版本进行安装
根据你的cuda版本和电脑系统,选择合适的cudnn进行下载(大概1G多,需要一段时间进行下载)。

下载好后,将.tz文件进行解压缩。
并打开终端,进入解压缩后的目录。以/home/xxx/下载为例。
$cd /home/xxx/下载 \\cd到下载目录
记得在你创建的虚拟环境中进行:
$ conda activate Deeplearning \\Deeplearning是我上面起的名字
输入以下命令:
$sudo cp cuda/include/cudnn*.h /usr/local/cuda/include/
$sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
$sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
安装好后进行检查。许多教程是输入这条语句“cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2”有正确显示即安装成功,但我没任何显示。。。还有其他的验证方法,如用Debian等,但因为这里是Ubuntu20.04,官网并没有给出其安装文件,只有上图所示的所有linux通用版安装压缩包,所以也没法用这种方法验证。
我是在进行完“七、pytorch-gpu安装”后用torch.cuda.is_available()进行验证的。
这里用以下方式进行验证cudnn是否安装成功。
七、pytorch-gpu安装
在“四、pytorch-cpu安装”中已经展示了如何安装pytorch-cpu版本了,这可以让你在不使用gpu时也能对代码进行调试验证,也就是import torch是可以正常导入的,但torch.cuda.is_available()会返回False。这时我们安装pytorch-gpu版本。
安装过程十分简单,截止2020年10月31日,开心的是pytorch已经支持cuda11.1了。所以打开官网,选择对应版本进行安装(下图以pip安装为例)。

在终端输入
pip install torch==1.7.0+cu110 torchvision==0.8.1+cu110 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
[注]:这步有小伙伴提示,最好不要用conda安装,可能导致还是cpu版本,所以最好直接就按图上的提示pip安装。
超级快就可以搞定!然后进行终极验证。
$source activate Deeplearning \\激活你创建的虚拟环境
$python \\运行python (启动命令与你上文中起的别名有关)
$import torch \\导入torch模块,这里应该没有任何输出
$torch.cuda.is_available() \\输出True则安装成功
$exit() \\退出python
$conda deactivate Deeplearning \\退出虚拟环境

八、tensorflow安装
其实tensorflow或pytorch安装好其一就可以进行深度学习了。但有时我们需要学习别人的代码,框架不由自己选择,所以还是都装上吧。
这里先查看你已经安装好的虚拟环境
$conda env list #查看所有的虚拟环境列表
得到下图(我已经装好了,所以图里有好几个环境)
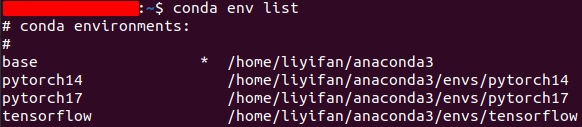 创建新的tensorflow的环境(这里类似于三.3中创建的Deeping learning环境),注意一定要加python=X.X(要不创建好的环境没有bin文件,是没法使用的),这步还是需要耗费一点点时间。
创建新的tensorflow的环境(这里类似于三.3中创建的Deeping learning环境),注意一定要加python=X.X(要不创建好的环境没有bin文件,是没法使用的),这步还是需要耗费一点点时间。
$conda create -n tensorflow python=3.8 #3.8是你的anaconda中python的版本
然后利用pip安装tensorflow和keras了~
目前tensorflow官网还没有给出和cuda11.1对应的tf版本,这里安装tf-nightly,亲测可用。其他小伙伴根据自己cuda的版本安装对应的tensorflow。
【注】:1. 强烈推荐用豆瓣源。。。亲测比阿里和清华源快了不是一点半点,使用方法如下,即在软件包名后加-i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2. tf-nightly-gpu是安装gpu版本,tf-nightly是安装cpu版本。可以按需安装。(这步虽然需要下载7,800兆的包,但豆瓣源还是很香,一会就好了)
$pip install tf-nightly-gpu -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
$pip install tf-nightly -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
然后安装keras(需要注意自己对应的版本)
$pip install keras==2.3 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
正常情况,这里tensorflow就完全安装好了,测试一下:
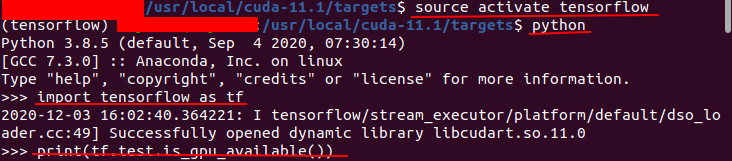
$source activate tensorflow #激活虚拟环境
$python #运行python
$import tensorflow as tf #没有任何提示表明tensorflow-cpu版安装完成
$print(tf.test.is_gpu_available()) #最后得到True表示tensorflow-gpu版安装完成
应该得到下图的结果(蓝色字体是当前路径,无所谓不影响)
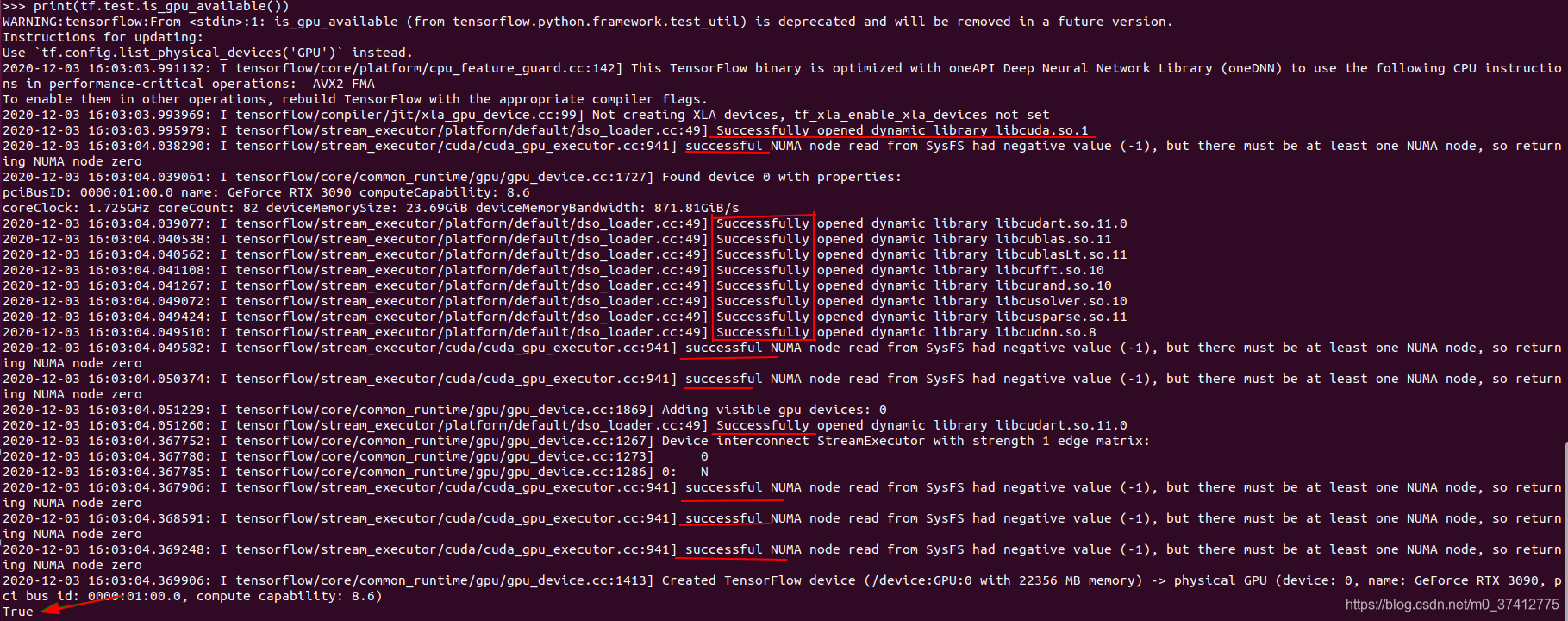 tensorflow-gpu是否安装成功重点看最后一行是True还是False。
tensorflow-gpu是否安装成功重点看最后一行是True还是False。
【出现的错误】:这里容易出现的问题是print(tf.test.is_gpu_available())后显示:** Could not load dynamic library ‘libcusolver.so.10’ **等,就不是上图中用红色线条标注的successfully…比如下图这样的情形(来源于网络):
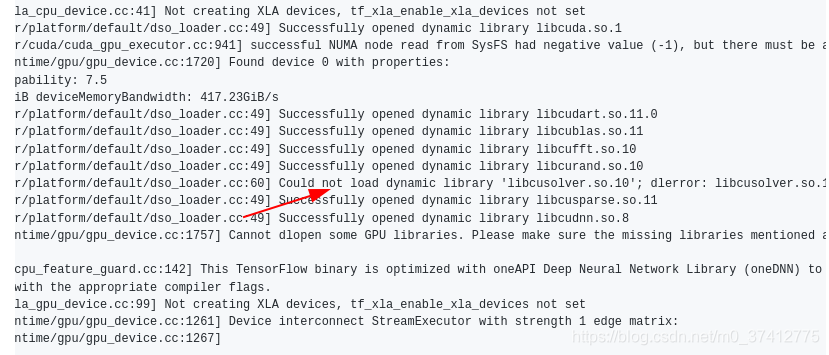
解决办法:建立软链接(缺libcusolver.so.10就将libcusolver.so.11指向libcusolver.so.10),直接在终端输入:
sudo ln -s /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcusolver.so.11 /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcusolver.so.10
撒花!!!所有安装到此结束!!!终于配完事了。。。
智能推荐
软件测试工程_绪论笔记_软件测试绪论笔记-程序员宅基地
文章浏览阅读5.9k次。标签: #课程更新:2021-09-17 11:09链接:理论测试的相关定义:发现软件缺陷,保证(某个可靠度的)软件质量在不测试的代价超过测试的代价之前,进行测试(尽早启动)工程专业的特点产品制造流程:设计——测试和验证——生产理解软件 = 程序 + 文档软件测试 != 程序测试也就是说,测试包括了对文档的检查。测试定义的两面性:正向思维:验证软件是否符合需求,验证软件能否正常工作逆向思维:发现未发现的错误标准定义使用人工或自动手段,来运行或测试.._软件测试绪论笔记
使用LSTM深度学习模型进行温度的时间序列单步和多步预测_预测温度用哪个深度学习模型-程序员宅基地
文章浏览阅读1.1w次,点赞19次,收藏115次。本文的目的是提供代码示例,并解释使用python和TensorFlow建模时间序列数据的思路。本文展示了如何进行多步预测并在模型中使用多个特征。本文的简单版本是,使用过去48小时的数据和对未来1小时的预测(一步),我获得了温度误差的平均绝对误差0.48(中值0.34)度。利用过去168小时的数据并提前24小时进行预测,平均绝对误差为摄氏温度1.69度(中值1.27)。所使用的特征是过去每小时的温度数据、每日及每年的循环信号、气压及风速。使用来自https://openweathermap.org/_预测温度用哪个深度学习模型
【Java基础】Java SPI 一 之SPI(Service Provider Interface)进阶& AutoService_java autoservice-程序员宅基地
文章浏览阅读1.4k次,点赞36次,收藏36次。SPI(Service Provider Interface),是JDK内置的一种 服务提供发现机制(为某个接口寻找服务实现的机制),可以用来启用框架扩展和替换组件,其核心思想就是解耦。模块之间基于接口编程,模块之间不对实现类进行硬编码,当代码里涉及具体的实现类,就违反了可拔插的原则,为了实现在模块装配的时候能不在程序里动态指明,就需要spi了。这里我们要跟API区分开来,简单介绍一下API。_java autoservice
安装好git包后,但在vsc中却提示:“ 未找到 Git。请安装 Git,或在 “git.path“ 设置中配置“的解决处理办法_git path-程序员宅基地
文章浏览阅读5.8k次,点赞9次,收藏19次。安装好git包后,但在vsc中却提示:" 未找到 Git。请安装 Git,或在 "git.path" 设置中配置"的解决处理办法._git path
使用 VMware 安装 docker_vmware安装docker-程序员宅基地
文章浏览阅读9.3k次,点赞11次,收藏90次。在 VMware 虚拟机 linux 环境下安装 Docker,超详细流程_vmware安装docker
5mm方格本打印模板_聪明人的方格笔记术-程序员宅基地
文章浏览阅读2.8k次。我在学生时代,几乎所有的笔记本都是横线本,也是这两年先后发现了不同的笔记方式。上次去图书馆发现了《聪明人用方格笔记本》,顺手带回家放置了很久,终于决定不能再拖下去了,昨天用1个半小时看完了。很多人在学生阶段、工作阶段,都少不了记笔记的经历,那么你有没有想过,记笔记的目的是什么呢?笔记的生命线是“再现性”,这是记笔记的最终目的。 --by《聪明人用方格笔记本》做笔记的过程也是信息整理的过程,我们做笔..._5mm小格子怎么用
随便推点
华为Java社招面试经历详解【已拿到offer】_广州华为java招聘-程序员宅基地
文章浏览阅读3.2k次,点赞4次,收藏28次。这篇文章主要介绍了华为Java社招面试经历,详细记录了华为java面试的流程、相关面试题与参考答案,需要的朋友可以参考下。看看自己能答对多少,如果能回答70%的题目,就大胆去阿里以及各互联网公司试试身手吧。本篇建议大家收藏、备用~华为Java社招面试(已拿到offer)之前月底华为cloudsop部门打电话叫我要不要面试,当时正处于换工作的期间,于是就把简历发给华为hr,人事审核后经过一些列面试、机试,最终顺利拿到了offer,出于未来职业规划的考量,本人手里还有其他的一些offer,还没有定下来,顺_广州华为java招聘
IDCNAR 账龄未清应收负数问题解决 F-51清账 示意_sap idcnar-程序员宅基地
文章浏览阅读1k次。_sap idcnar
linux线程的基本知识_linux加锁失败的状态符-程序员宅基地
文章浏览阅读2.6k次。使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会忙等待,直到拿到锁。2、 fork两次,第一次fork的子进程在fork完成后直接退出,这样第二次fork得到的子进程就没有爸爸了,它会自动被老祖宗init收养,init会负责释放它的资源,这样就不会有“僵尸”产生了。线程的等待,第一个参数是线程的id,第二个一般为NULL,表示不关心退出的状态。第一个参数是线程id的地址。互斥锁加锁失败后,会从用户态陷入到内核态,让内核帮助我们切换线程,虽然简化了使用锁的难度,但是存在一定的性能开销成本。_linux加锁失败的状态符
000_coolprop_in_matlab在Matlab中使用CoolProp-程序员宅基地
文章浏览阅读1.2k次,点赞26次,收藏12次。在Matlab中调用Python需要先设置Python的路径(pyenv在Matlab中调用Python的函数有两种方式,一种是使用py函数,一种是使用函数;在Matlab中调用Python的CoolProp接口,需要导入CoolProp模块,然后调用函数即可。可以写一个Matlab函数,来调用PropsSI函数。使用函数;在Matlab中调用Python的CoolProp接口,需要导入CoolProp模块,然后调用函数即可。可以写一个Matlab函数,来调用PropsSI函数。_matlab中使用coolprop
认识数据湖加速器(Data Lake Accelerator Goose FileSystem,GooseFS)-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏3次。数据湖加速器(Data Lake Accelerator Goose FileSystem,GooseFS),是由腾讯云推出的高可靠、高可用、弹性的数据湖加速服务。依靠对象存储(Cloud Object Storage,COS)作为数据湖存储底座的成本优势,为数据湖生态中的计算应用提供统一的数据湖入口,加速海量数据分析、机器学习、人工智能等业务访问存储的性能;采用了分布式集群架构,具备弹性、高可靠、高可用等特性,为上层计算应用提供统一的命名空间和访问协议,方便用户在不同的存储系统管理和流转数据。_goosefs
人工智能:语音合成技术介绍_语音合成需要什么知识和技能-程序员宅基地
文章浏览阅读2.3k次,点赞17次,收藏22次。今天介绍给大家介绍语音合成相关的技术,希望对大家能有所帮助!语音合成简单来说就是把文字信息转换为标准语音的过程,最终可以输出对应的音频文件。可以实现让机器像人类一样可以实时的说话。涉及的领域有声学、语言学、数字信号处理、计算机管理等方面的知识。主要包括:获取输入的文本→语言处理→韵律处理→声学处理→输出音频文件。其中语音识别主要是语言处理、韵律处理、声学处理_语音合成需要什么知识和技能