机器学习模型调优方法(过拟合、欠拟合、泛化误差、集成学习)_在机器学习实验中,一般通过什么方法进行模型调优?-程序员宅基地
机器学习模型调优方法
过拟合和欠拟合
过拟合是指模型对于训练数据拟合呈过当的情况,反映到评估指标上,就是模型在训练集上的表现很好,但在测试集和新数据上的表现较差。
欠拟合指的是模型在训练和预测时表现都不好的情况。
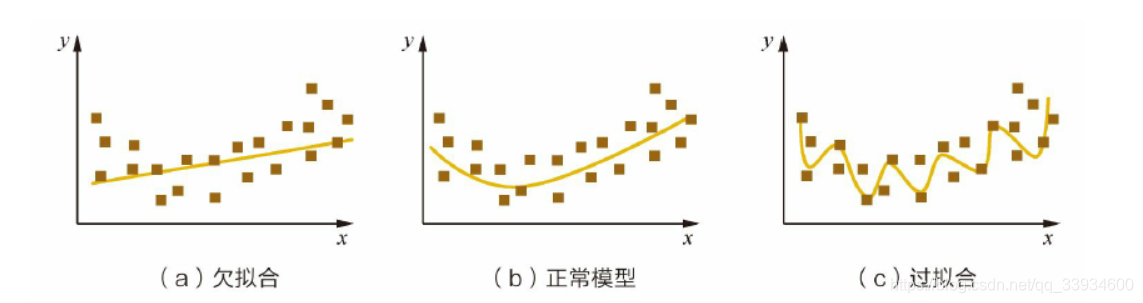
可以看出,图(a)是欠拟合的情况,拟合的黄线没有很好地捕捉到数据的特征,不能够很好地拟合数据。
图(c)则是过拟合的情况,模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化能力下降,在后期应用过程中很容易输出错误的预测结果。
降低过拟合风险的方法
(1)从数据入手,获得更多的训练数据。使用更多的训练数据是解决过拟合问题最有效的手段,因为更多的样本能够让模型学习到更多更有效的特征,减小噪声的影响。当然,直接增加实验数据一般是很困难的,但是可以通过一定的规则来扩充训练数据。比如,在图像分类的问题上,可以通过图像的平移、旋转、缩放等方式扩充数据;更进一步地,可以使用生成式对抗网络来合成大量的新训练数据。
(2)降低模型复杂度。在数据较少时,模型过于复杂是产生过拟合的主要因素,适当降低模型复杂度可以避免模型拟合过多的采样噪声。例如,在神经网络模型中减少网络层数、神经元个数等;在决策树模型中降低树的深度、进行剪枝等。
(3)正则化方法。给模型的参数加上一定的正则约束,比如将权值的大小加入到损失函数中。以L2正则化为例:在优化原来的目标函数C0的同时,也能避免权值过大带来的过拟合风险。
(4)集成学习方法。集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,如Bagging方法。
降低欠拟合风险的方法
(1)添加新特征。当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。通过挖掘“上下文特征”“ID类特征”“组合特征”等新的特征,往往能够取得更好的效果。在深度学习潮流中,有很多模型可以帮助完成特征工程,如因子分解机、梯度提升决策树、Deep-crossing等都可以成为丰富特征的方法。
(2)增加模型复杂度。简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。例如,在线性模型中添加高次项,在神经网络模型中增加网络层数或神经元个数等。
(3)减小正则化系数。正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数。
泛化误差、偏差和方差
泛化误差
当模型在未知数据(测试集或者袋外数据)上表现糟糕时,我们说模型的泛化程度不够,泛化误差大,模型的效果不好。泛化误差受到模型的结构(复杂度)影响。
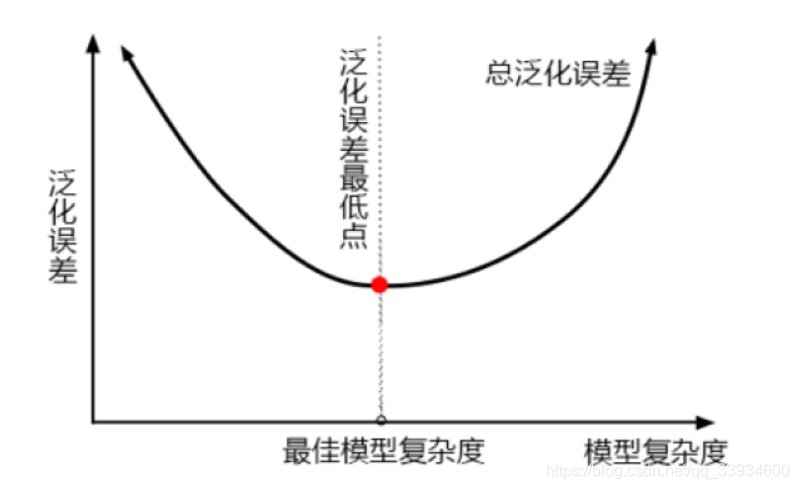 上面这张图,它准确地描绘了泛化误差与模型复杂度的关系,当模型太复杂,模型就会过拟合,泛化能力就不够,所以泛化误差大。当模型太简单,模型就会欠拟合,拟合能力就不够,所以误差也会大。只有当模型的复杂度刚刚好的才能够达到泛化误差最小的目标。
上面这张图,它准确地描绘了泛化误差与模型复杂度的关系,当模型太复杂,模型就会过拟合,泛化能力就不够,所以泛化误差大。当模型太简单,模型就会欠拟合,拟合能力就不够,所以误差也会大。只有当模型的复杂度刚刚好的才能够达到泛化误差最小的目标。
偏差和误差
用过拟合、欠拟合来定性地描述模型是否很好地解决了特定的问题。从定量的角度来说,可以用模型的偏差(Bias)与方差(Variance)来描述模型的性能。
在有监督学习中,模型的泛化误差来源于两个方面——偏差和方差,具体来讲偏差和方差的定义如下:
偏差指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的平均值和真实模型输出之间的偏差。
偏差通常是由于我们对学习算法做了错误的假设所导致的,比如真实模型是某个二次函数,但我们假设模型是一次函数。由偏差带来的误差通常在训练误差上就能体现出来。
方差指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的方差。
方差通常是由于模型的复杂度相对于训练样本数m过高导致的,比如一共有100个训练样本,而我们假设模型是阶数不大于200的多项式函数。由方差带来的误差通常体现在测试误差相对于训练误差的增量上。
上面的定义很准确,但不够直观,为了更清晰的理解偏差和方差,可以用一个射击的例子来进一步描述这二者的区别和联系。
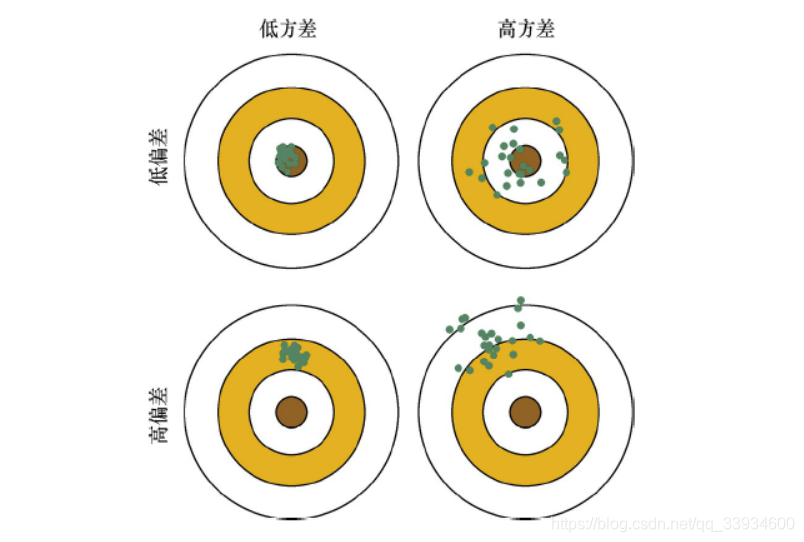
假设一次射击就是一个机器学习模型对一个样本进行预测。射中靶心位置代表预测准确,偏离靶心越远代表预测误差越大。 我们通过n次采样得到n个大小为m的训练样本集合,训练出n个模型,对同一个样本做预测,相当于我们做了n次射击,射击结果如下图所示。
我们最期望的结果就是左上角的结果,射击结果又准确又集中,说明模型的偏差和方差都很小;
右上图虽然射击结果的中心在靶心周围,但分布比较分散,说明模型的偏差较小但方差较大;
同理,左下图说明模型方差较小,偏差较大;
右下图说明模型方差较大,偏差也较大。
模型评估
Holdout检验
Holdout 检验是最简单也是最直接的验证方法,它将原始的样本集合随机划分成训练集和验证集两部分。比方说,对于一个预测模型,我们把样本按照70%~30% 的比例分成两部分,70% 的样本用于模型训练;30% 的样本用于模型验证,包括绘制ROC曲线、计算精确率和召回率等指标来评估模型性能。
Holdout 检验的缺点很明显,即在验证集上计算出来的最后评估指标与原始分组有很大关系。为了消除随机性,引入了“交叉检验”的思想。
交叉检验
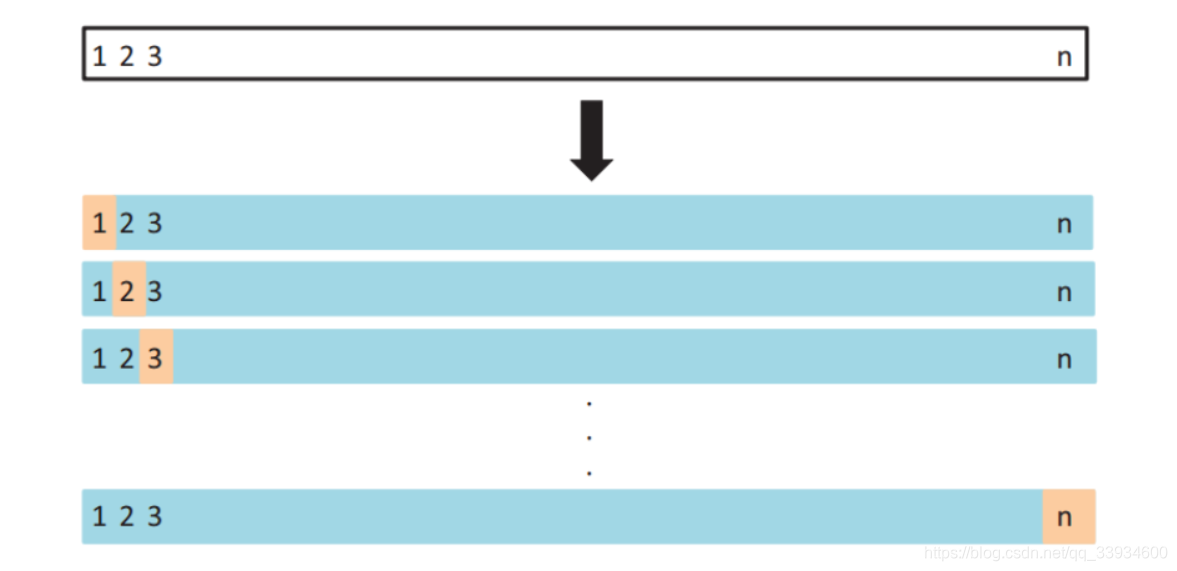
k-fold交叉验证:首先将全部样本划分成k个大小相等的样本子集;依次遍历这k个子集,每次把当前子集作为验证集,其余所有子集作为训练集,进行模型的训练和评估;最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k经常取10。
# 使用红酒数据集,验证10折交叉验证在随机森林和单个决策树效益的对比。
%matplotlib inline
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets 智能推荐
软件测试流程包括哪些内容?测试方法有哪些?_测试过程管理中包含哪些过程-程序员宅基地
文章浏览阅读2.9k次,点赞8次,收藏14次。测试主要做什么?这完全都体现在测试流程中,同时测试流程是面试问题中出现频率最高的,这不仅是因为测试流程很重要,而是在面试过程中这短短的半小时到一个小时的时间,通过测试流程就可以判断出应聘者是否合适,故在测试流程中包含了测试工作的核心内容,例如需求分析,测试用例的设计,测试执行,缺陷等重要的过程。..._测试过程管理中包含哪些过程
政府数字化政务的人工智能与机器学习应用:如何提高政府工作效率-程序员宅基地
文章浏览阅读870次,点赞16次,收藏19次。1.背景介绍政府数字化政务是指政府利用数字技术、互联网、大数据、人工智能等新技术手段,对政府政务进行数字化改革,提高政府工作效率,提升政府服务质量的过程。随着人工智能(AI)和机器学习(ML)技术的快速发展,政府数字化政务中的人工智能与机器学习应用也逐渐成为政府改革的重要内容。政府数字化政务的人工智能与机器学习应用涉及多个领域,包括政策决策、政府服务、公共安全、社会治理等。在这些领域,人工...
ssm+mysql+微信小程序考研刷题平台_mysql刷题软件-程序员宅基地
文章浏览阅读219次,点赞2次,收藏4次。系统主要的用户为用户、管理员,他们的具体权限如下:用户:用户登录后可以对管理员上传的学习视频进行学习。用户可以选择题型进行练习。用户选择小程序提供的考研科目进行相关训练。用户可以进行水平测试,并且查看相关成绩用户可以进行错题集的整理管理员:管理员登录后可管理个人基本信息管理员登录后可管理个人基本信息管理员可以上传、发布考研的相关例题及其分析,并对题型进行管理管理员可以进行查看、搜索考研题目及错题情况。_mysql刷题软件
根据java代码描绘uml类图_Myeclipse8.5下JAVA代码导成UML类图-程序员宅基地
文章浏览阅读1.4k次。myelipse里有UML1和UML2两种方式,UML2功能更强大,但是两者生成过程差别不大1.建立Test工程,如下图,uml包存放uml类图package com.zz.domain;public class User {private int id;private String name;public int getId() {return id;}public void setId(int..._根据以下java代码画出类图
Flume自定义拦截器-程序员宅基地
文章浏览阅读174次。需求:一个topic包含很多个表信息,需要自动根据json字符串中的字段来写入到hive不同的表对应的路径中。发送到Kafka中的数据原本最外层原本没有pkDay和project,只有data和name。因为担心data里面会空值,所以根同事商量,让他们在最外层添加了project和pkDay字段。pkDay字段用于表的自动分区,proejct和name合起来用于自动拼接hive表的名称为 ..._flume拦截器自定义开发 kafka
java同时输入不同类型数据,Java Spring中同时访问多种不同数据库-程序员宅基地
文章浏览阅读380次。原标题:Java Spring中同时访问多种不同数据库 多样的工作要求,可以使用不同的工作方法,只要能获得结果,就不会徒劳。开发企业应用时我们常常遇到要同时访问多种不同数据库的问题,有时是必须把数据归档到某种数据仓库中,有时是要把数据变更推送到第三方数据库中。使用Spring框架时,使用单一数据库是非常容易的,但如果要同时访问多个数据库的话事件就变得复杂多了。本文以在Spring框架下开发一个Sp..._根据输入的不同连接不同的数据库
随便推点
EFT试验复位案例分析_eft电路图-程序员宅基地
文章浏览阅读3.6k次,点赞9次,收藏25次。本案例描述了晶振屏蔽以及开关电源变压器屏蔽对系统稳定工作的影响, 硬件设计时应考虑。_eft电路图
MR21更改价格_mr21 对于物料 zba89121 存在一个当前或未来标准价格-程序员宅基地
文章浏览阅读1.1k次。对于物料价格的更改,可以采取不同的手段:首先,我们来介绍MR21的方式。 需要说明的是,如果要对某一产品进行价格修改,必须满足的前提条件是: ■ 1、必须对价格生效的物料期间与对应会计期间进行开启; ■ 2、该产品在该物料期间未发生物料移动。执行MR21,例如更改物料1180051689的价格为20000元,系统提示“对于物料1180051689 存在一个当前或未来标准价格”,这是因为已经对该..._mr21 对于物料 zba89121 存在一个当前或未来标准价格
联想启天m420刷bios_联想启天M420台式机怎么装win7系统(完美解决usb)-程序员宅基地
文章浏览阅读7.4k次,点赞3次,收藏13次。[文章导读]联想启天M420是一款商用台式电脑,预装的是win10系统,用户还是喜欢win7系统,该台式机采用的intel 8代i5 8500CPU,在安装安装win7时有很多问题,在安装win7时要在BIOS中“关闭安全启动”和“开启兼容模式”,并且安装过程中usb不能使用,要采用联想win7新机型安装,且默认采用的uefi+gpt模式,要改成legacy+mbr引导,那么联想启天M420台式电..._启天m420刷bios
冗余数据一致性,到底如何保证?-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏9次。一,为什么要冗余数据互联网数据量很大的业务场景,往往数据库需要进行水平切分来降低单库数据量。水平切分会有一个patition key,通过patition key的查询能..._保证冗余性
java 打包插件-程序员宅基地
文章浏览阅读88次。是时候闭环Java应用了 原创 2016-08-16 张开涛 你曾经因为部署/上线而痛苦吗?你曾经因为要去运维那改配置而烦恼吗?在我接触过的一些部署/上线方式中,曾碰到过以下一些问题:1、程序代码和依赖都是人工上传到服务器,不是通过工具进行部署和发布;2、目录结构没有规范,jar启动时通过-classpath任意指定;3、fat jar,把程序代码、配置文件和依赖jar都打包到一个jar中,改配置..._那么需要把上面的defaultjavatyperesolver类打包到插件中
VS2015,Microsoft Visual Studio 2005,SourceInsight4.0使用经验,Visual AssistX番茄助手的安装与基本使用9_番茄助手颜色-程序员宅基地
文章浏览阅读909次。1.得下载一个番茄插件,按alt+g才可以有函数跳转功能。2.不安装番茄插件,按F12也可以有跳转功能。3.进公司的VS工程是D:\sync\build\win路径,.sln才是打开工程的方式,一个是VS2005打开的,一个是VS2013打开的。4.公司库里的线程接口,在CmThreadManager.h 里,这个里面是我们的线程库,可以直接拿来用。CreateUserTaskThre..._番茄助手颜色