CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)_github ceemdan-cnn-bilstm-attention-程序员宅基地
目录
2.1 划分数据集,按照8:2划分训练集和测试集, 然后再按照前7后4划分分量数据
3 基于CEEMADN的BiLSTM-Attention模型预测
3.2 定义CEEMDAN-BiLSTM-Attention预测模型
4.1 数据加载,训练数据、测试数据分组,四个分量,划分四个数据集

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-程序员宅基地
风速预测(二)基于Pytorch的EMD-LSTM模型-程序员宅基地
风速预测(三)EMD-LSTM-Attention模型-程序员宅基地
风速预测(四)基于Pytorch的EMD-Transformer模型-程序员宅基地
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-程序员宅基地
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-程序员宅基地
风速预测(七)VMD-CNN-BiLSTM预测模型-程序员宅基地
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-程序员宅基地
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)-程序员宅基地
CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)-程序员宅基地
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)-程序员宅基地
多特征变量序列预测(一)——CNN-LSTM风速预测模型-程序员宅基地
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型-程序员宅基地
多特征变量序列预测(三)——CNN-Transformer风速预测模型-程序员宅基地
多特征变量序列预测(四)Transformer-BiLSTM风速预测模型-程序员宅基地
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型-程序员宅基地
多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型-程序员宅基地
多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型-程序员宅基地
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型-程序员宅基地
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型-程序员宅基地
多特征变量序列预测(八)基于麻雀优化算法的CEEMDAN-SSA-BiLSTM预测模型-程序员宅基地
多特征变量序列预测(九)基于麻雀优化算法的CEEMDAN-SSA-BiGRU-Attention预测模型-程序员宅基地
多特征变量序列预测(10)基于麻雀优化算法的CEEMDAN-SSA-Transformer-BiLSTM预测模型-程序员宅基地
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-程序员宅基地
基于麻雀优化算法SSA的预测模型——代码全家桶-程序员宅基地
前言
本文基于前期介绍的风速数据(文末附数据集),介绍一种综合应用完备集合经验模态分解CEEMDAN与混合预测模型(BiLSTM-Attention + ARIMA)的方法,以提高时间序列数据的预测性能。该方法的核心是使用CEEMDAN算法对时间序列进行分解,接着利用BiLSTM-Attention模型和ARIMA模型对分解后的数据进行建模,最终通过集成方法结合两者的预测结果。
风速数据集的详细介绍可以参考下文:
1 风速数据CEEMDAN分解与可视化
1.1 导入数据

1.2 CEEMDAN分解
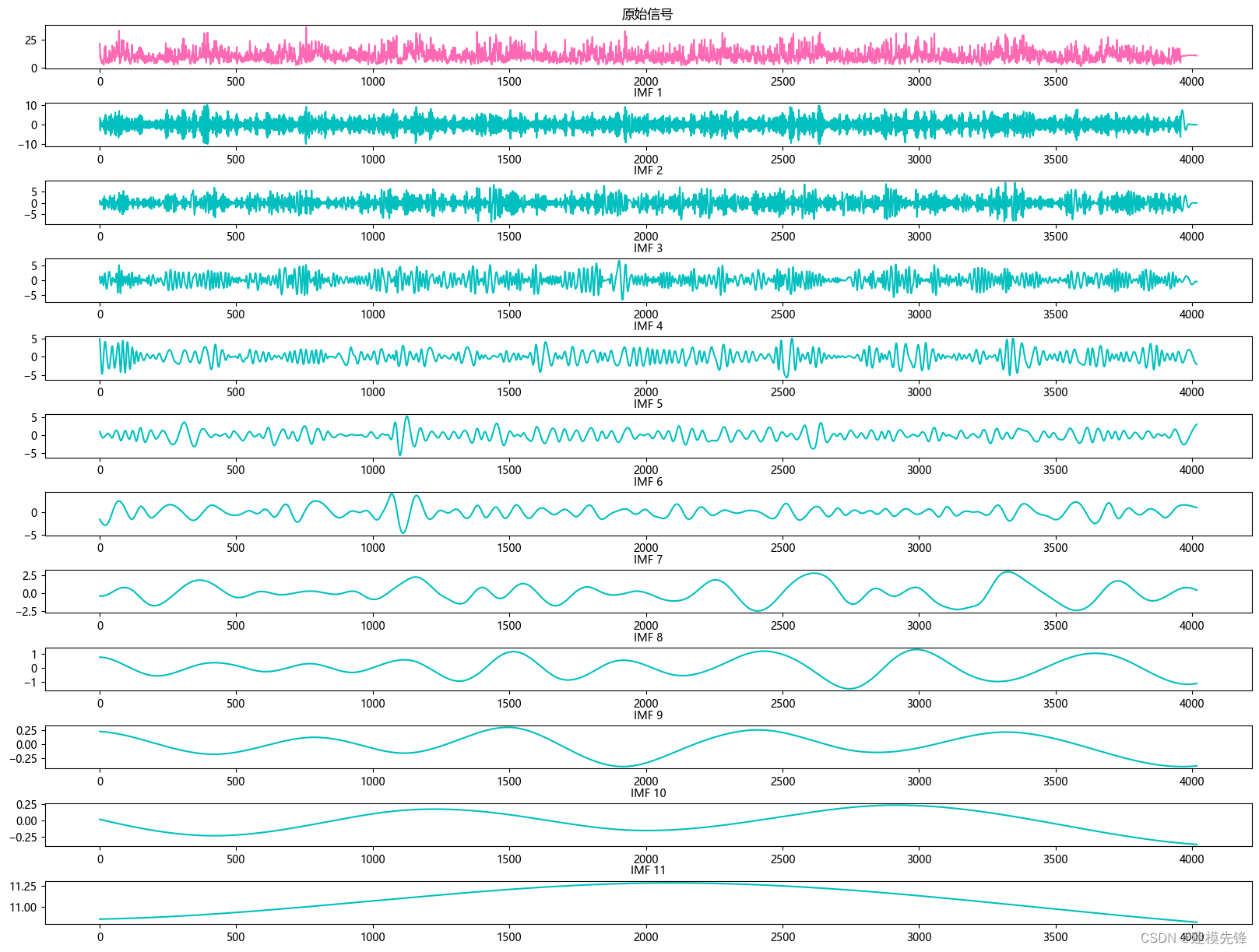
根据分解结果看,CEEMDAN一共分解出11个分量,我们大致把前7个高频分量作为BiLSTM-Attention模型的输入进行预测,后4个低频分量作为ARIMA模型的输入进行预测
2 数据集制作与预处理
2.1 划分数据集,按照8:2划分训练集和测试集, 然后再按照前7后4划分分量数据

2.2 设置滑动窗口大小为7,制作数据集
# 定义滑动窗口大小
window_size = 7
# 分量划分分界
imf_no = 7
# 第一步,划分数据集
dataset1, dataset2 = make_wind_dataset(wind_emd_imfs, imf_no)
# 第二步,制作数据集标签 滑动窗口
# BiLSTM-Attention 模型数据
train_set1, train_label1 = data_window_maker(dataset1[0], window_size)
test_set1, test_label1 = data_window_maker(dataset1[1], window_size)
# ARIMA 模型数据
train_data_arima = dataset2[0]
test_data_arima = dataset2[1]
# 保存数据
dump(train_set1, 'train_set1')
dump(train_label1, 'train_label1')
dump(test_set1, 'test_set1')
dump(test_label1, 'test_label1')
dump(train_data_arima, 'train_data_arima')
dump(test_data_arima, 'test_data_arima')
分批保存数据,用于不同模型的预测
3 基于CEEMADN的BiLSTM-Attention模型预测
3.1 数据加载,训练数据、测试数据分组,数据分batch
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据集
def dataloader(batch_size, workers=2):
# 训练集
train_set = load('train_set1')
train_label = load('train_label1')
# 测试集
test_set = load('test_set1')
test_label = load('test_label1')
# 加载数据
train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_set, train_label),
batch_size=batch_size, num_workers=workers, drop_last=True)
test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_set, test_label),
batch_size=batch_size, num_workers=workers, drop_last=True)
return train_loader, test_loader
batch_size = 64
# 加载数据
train_loader, test_loader = dataloader(batch_size)3.2 定义CEEMDAN-BiLSTM-Attention预测模型

注意:输入风速数据形状为 [64, 7, 7], batch_size=64, 维度7维代表7个分量,7代表序列长度(滑动窗口取值)。
3.3 定义模型参数
# 定义模型参数
batch_size = 64
input_len = 48 # 输入序列长度为96 (窗口值)
input_dim = 7 # 输入维度为7个分量
hidden_layer_sizes = [32, 64] # LSTM 层 结构 隐藏层神经元个数
attention_dim = hidden_layer_sizes[-1] # 注意力层维度 默认为 LSTM输出层维度
output_size = 1 # 单步输出
model = BiLSTMAttentionModel(batch_size, input_len, input_dim, attention_dim, hidden_layer_sizes, output_size=1)
# 定义损失函数和优化函数
model = model.to(device)
loss_function = nn.MSELoss() # loss
learn_rate = 0.003
optimizer = torch.optim.Adam(model.parameters(), learn_rate) # 优化器3.4 模型训练

训练结果

100个epoch,MSE 为0.00559,BiLSTM-Attention预测效果良好,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以适当增加BiLSTM层数和隐藏层的维度,微调学习率;
-
调整注意力维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
保存训练结果和预测数据,以便和后面ARIMA模型的结果相组合。
4 基于ARIMA的模型预测
传统时序模型(ARIMA等模型)教程如下:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-程序员宅基地
4.1 数据加载,训练数据、测试数据分组,四个分量,划分四个数据集
# 加载数据
from joblib import dump, load
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 训练集
train_set = load('train_data_arima')
# 测试集
test_set = load('test_data_arima')
# IMF1-Model1
model1_train = train_set[0, :]
model1_test = test_set[0, :]
# IMF2-Model2
model2_train = train_set[1, :]
model2_test = test_set[1, :]
# IMF3-Model3
model3_train = train_set[2, :]
model3_test = test_set[2, :]
# IMF4-Model4
model4_train = train_set[3, :]
model4_test = test_set[3, :]4.2 介绍一个分量预测过程(其他分量类似)
第一步,单位根检验和差分处理

ADF检验P值远小于0.05,故拒绝原假设,即数据是平稳的时间序列数据,也确定了d=0
第二步,模型识别,采用AIC指标进行参数选择

采用AIC指标进行参数选择,得到最小的AIC值的组合为p=2,q=0,选择其作为模型进行拟合,因此针对原数据可知最终确定模型为ARIMA(2,0,0)(结合代码指标结果来看)
第三步,模型预测

第四步,模型评估

保存预测的数据,其他分量预测与上述过程一致,保留最后模型结果即可。
5 结果可视化和模型评估
5.1 组合预测,加载各模型的预测结果
# 训练集
arima_train_set = load('train_data_arima')
# 测试集
arima_test_set = load('test_data_arima')
# IMF1-Model1
model1_imf_arima_pre = load('model1_imf_arima_pre')
# IMF2-Model2
model2_imf_arima_pre = load('model2_imf_arima_pre')
# IMF3-Model3
model3_imf_arima_pre = load('model3_imf_arima_pre')
# IMF4-Model4
model4_imf_arima_pre = load('model4_imf_arima_pre')
# BiLSTM-Attention
original_label_bilstmatt = load('original_label_bilstmatt')
pre_data_bilstmatt = load('pre_data_bilstmatt')5.2 结果可视化

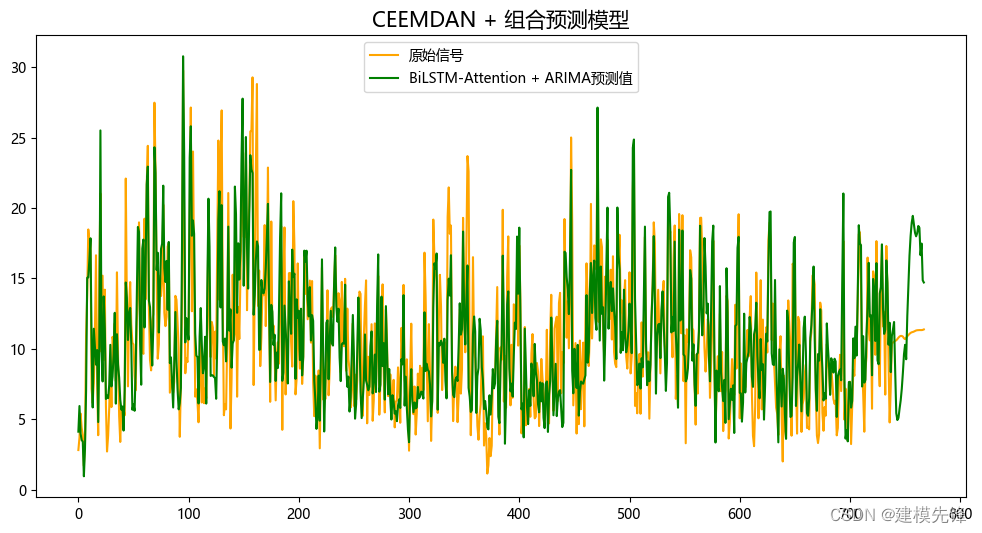
5.3 模型评估
由分量预测结果可见,前7个分量在BiLSTM-Attention预测模型下拟合效果良好,分量9在ARIMA模型的预测下,拟合程度比较好,其他低频分量拟合效果弱一点,调整参数可增强拟合效果。

代码、数据如下:
对数据集和代码感兴趣的,可以关注最后一行
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#代码和数据集:https://mbd.pub/o/bread/ZZiam5lx
智能推荐
如何配置filezilla服务端和客户端_filezilla server for windows (32bit x86)-程序员宅基地
文章浏览阅读7.8k次,点赞3次,收藏9次。如何配置filezilla服务端和客户端百度‘filezilla server’下载最新版。注意点:下载的版本如果是32位的适用xp和win2003,百度首页的是适用于win7或更高的win系统。32和64内容无异。安装过程也是一样的。一、这里的filezilla包括服务端和客户端。我们先来用filezilla server 架设ftp服务端。看步骤。1选择标准版的就可以了。 _filezilla server for windows (32bit x86)
深度学习图像处理01:图像的本质-程序员宅基地
文章浏览阅读724次,点赞18次,收藏8次。深度学习作为一种强大的机器学习技术,已经成为图像处理领域的核心技术之一。通过模拟人脑处理信息的方式,深度学习能够从图像数据中学习到复杂的模式和特征,从而实现从简单的图像分类到复杂的场景理解等多种功能。要充分发挥深度学习在图像处理中的潜力,我们首先需要理解图像的本质。本文旨在深入探讨深度学习图像处理的基础概念,为初学者铺平通往高级理解的道路。我们将从最基础的问题开始:图像是什么?我们如何通过计算机来理解和处理图像?
数据探索阶段——对样本数据集的结构和规律进行分析_数据分析 规律集-程序员宅基地
文章浏览阅读62次。在收集到初步的样本数据之后,接下来该考虑的问题有:(1)样本数据集的数量和质量是否满足模型构建的要求。(2)是否出现从未设想过的数据状态。(3)是否有明显的规律和趋势。(4)各因素之间有什么样的关联性。解决方案:检验数据集的数据质量、绘制图表、计算某些特征量等,对样本数据集的结构和规律进行分析。从数据质量分析和数据特征分析两个角度出发。_数据分析 规律集
上传计算机桌面文件图标不见,关于桌面上图标都不见了这类问题的解决方法-程序员宅基地
文章浏览阅读8.9k次。关于桌面上图标都不见了这类问题的解决方法1、在桌面空白处右击鼠标-->排列图标-->勾选显示桌面图标。2、如果问题还没解决,那么打开任务管理器(同时按“Ctrl+Alt+Del”即可打开),点击“文件”→“新建任务”,在打开的“创建新任务”对话框中输入“explorer”,单击“确定”按钮后,稍等一下就可以见到桌面图标了。3、问题还没解决,按Windows键+R(或者点开始-->..._上传文件时候怎么找不到桌面图标
LINUX 虚拟网卡tun例子——修改_怎么设置tun的接收缓冲-程序员宅基地
文章浏览阅读1.5k次。参考:http://blog.csdn.net/zahuopuboss/article/details/9259283 #include #include #include #include #include #include #include #include #include #include #include #include _怎么设置tun的接收缓冲
UITextView 评论输入框 高度自适应-程序员宅基地
文章浏览阅读741次。创建一个inputView继承于UIView- (instancetype)initWithFrame:(CGRect)frame{ self = [superinitWithFrame:frame]; if (self) { self.backgroundColor = [UIColorcolorWithRed:0.13gre
随便推点
字符串基础面试题_java字符串相关面试题-程序员宅基地
文章浏览阅读594次。字符串面试题(2022)_java字符串相关面试题
VSCODE 实现远程GUI,显示plt.plot, 设置x11端口转发_vscode远程ssh连接服务器 python 显示plt-程序员宅基地
文章浏览阅读1.4w次,点赞12次,收藏21次。VSCODE 实现远程GUI,显示plt.plot, 设置x11端口转发问题服务器 linux ubuntu16.04本地 windows 10很多小伙伴发现VSCode不能显示figure,只有用自带的jupyter才能勉强个截图、或者转战远程桌面,这对数据分析极为不方便。在命令行键入xeyes(一个显示图像的命令)会failed,而桌面下会出现:但是Xshell能实现X11转发图像,有交互功能,但只能用Xshell输入命令plot,实在不方便。其实VScode有X11转发插件!!方法_vscode远程ssh连接服务器 python 显示plt
Java SE | 网络编程 TCP、UDP协议 Socket套接字的使用_javase套接字socket-程序员宅基地
文章浏览阅读529次。网络编程_javase套接字socket
element-ui switch开关打开和关闭时的文字设置样式-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏2次。element switch开关文字显示element中switch开关把on-text 和 off-text 属性改为 active-text 和 inactive-text 属性.怎么把文字描述显示在开关上?下面就是实现方法: 1 <el-table-column label="状态"> 2 <template slot-scope="scope">..._el-switch 不同状态显示不同字
HttpRequestUtil方法get、post、JsonToPost_httprequestutil.httpget-程序员宅基地
文章浏览阅读785次。java后台发起请求使用的工具类package com.cennavi.utils;import org.apache.http.Header;import org.apache.http.HttpResponse;import org.apache.http.HttpStatus;import org.apache.http.client.HttpClient;import org.apache.http.client.methods.HttpPost;import org.apach_httprequestutil.httpget
App-V轻量级应用程序虚拟化之三客户端测试-程序员宅基地
文章浏览阅读137次。在前两节我们部署了App-V Server并且序列化了相应的软件,现在可谓是万事俱备,只欠东风。在这篇博客里面主要介绍一下如何部署客户端并实现应用程序的虚拟化。在这里先简要的说一下应用虚拟化的工作原理吧!App-V Streaming 就是利用templateServer序列化出一个软件运行的虚拟环境,然后上传到app-v Server上,最后客户..._app-v 客户端