【Python爬虫必备—>Scrapy框架快速入门篇——上】_scrpy框架教学-程序员宅基地
技术标签: 爬虫框架 万字博文 快速入门 原力计划 Scrapy框架从入门到实战 scrapy
- 相信不少小伙伴们在经历过我的上几篇关于爬虫技术的万字博文的轮番轰炸后,已经可以独立开发出属于自己的爬虫项目!!!——爬虫之路,已然开启!
第一篇之爬虫入坑文;一篇万字博文带你入坑爬虫这条不归路(你还在犹豫什么&抓紧上车)
第二篇之爬虫库requests库详解。两万字博文教你python爬虫requests库,看完还不会我把我女朋友都给你
第三篇之解析库Beautiful Soup库详解。Python万字博文教你玩透Beautiful Soup库【️建议收藏系列️】
第四篇之Selenium详解。【️爬虫必备->Selenium从黑铁到王者️】初篇——万字博文详解(建议收藏)
- 但是 前几日有很多粉丝私聊我反馈说:"自己爬虫基础库已经学差不多了,实战也做了不少,但是好多自己接的爬虫单或者老板都要求使用scrapy框架来爬取数据,自己没有接触过scrapy框架不知道如何下手!"
其实我已经有一个scrapy一条龙教学的分栏,也有不少人订阅并且反响不错,【Scrapy框架详解】。但是呢?我又想了想,确实少了篇总结性的文章——来从总体上介绍Scrapy框架。
-
所以应粉丝们要求,本博主花了假期周六周日两天时间,肝出本文(共分上中下三篇),目的在于带领想要学习scrapy的同学走近scrapy的世界!并在文末附带一整套scrapy框架学习路线,如果你能认认真真看完这三篇文章,在心里对scrapy有个印象,然后潜心研究文末整套学习路线,那么,scrapy框架对你来说——手到擒来!!!
-
我会尽量把技术文写的通俗易懂/生动有趣,保证每一个想要学习知识&&认认真真读完本文的读者们能够有所获,有所得。当然,如果你读完感觉本文写的还可以,真正学习到了东西,希望给我个「 赞 」 和 「 收藏 」,这个对我很重要,谢谢了!
第一部分:走近scrapy!
0.简介及安装
1️⃣简介:
scrapy设计目的:用于爬取网络数据,提取结构性数据的框架,其中,scrapy使用了Twisted异步网络框架,大大加快了下载速度!
2️⃣安装:
直接pip安装(一句命令&&一步到位):
pip install scrapy
1.scrapy项目开发流程:
- 创建项目:scrapy startproject mySpider
- 生成一个爬虫:scrapy genspider baidu baidu.com
- 提取数据:根据网站结构在spider中实现数据采集相关内容
- 保存数据:使用pipeline进行数据后续处理和保存
2.scrapy框架运行流程:
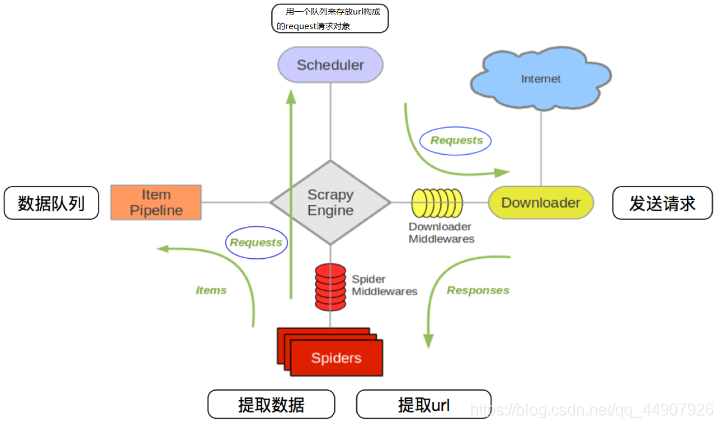

原理描述:
- 爬虫中起始url构造的url对象–>爬虫中间件–>引擎–>调度器
- 调度器把request–>引擎–>下载中间件–>下载器
- 下载器发送请求,获取response响应—>下载中间件—>引擎–>爬虫中间件—>爬虫
- 爬虫提取url地址,组装成request对象—>爬虫中间件—>引擎—>调度器,重复步骤2
- 爬虫提取数据—>引擎—>管道处理和保存数据
| 注意:爬虫中间件和下载中间件只是运行的逻辑的位置不同,作用是重复的:如替换UA等! |
拓展——scrapy中三个内置对象:
三个内置对象:(scrapy框架中只有三种数据类型)
request请求对象:由url,method,post_data,headers等构成;
response响应对象:由url,body,status,headers等构成;
item数据对象:本质是一个字典。
第二部分:创建&&运行你的第一个scrapy项目!
1.创建项目:
创建scrapy项目的命令:scrapy startproject <项目名字>
示例:
scrapy startproject myspider
生成的目录和文件结果如下:

2.爬虫文件的创建:
在项目根路径下执行:
scrapy genspider <爬虫名字> <允许爬取的域名>
示例:
cd myspider
scrapy genspider itcast itcast.cn
讲解:
- 爬虫名字:作为爬虫运行时的参数;
- 允许爬的域名:为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域名不同,则被过滤掉。
3.运行scrapy爬虫:
命令:在项目目录下执行:
scrapy crawl <爬虫名字>
示例:
scrapy crawl itcast
不过,在运行之前,我们先要编写itcast.py爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
class ItcastSpider(scrapy.Spider):
# 爬虫运行时的参数
name = 'itcast'
# 检查允许爬的域名
allowed_domains = ['itcast.cn']
# 1.修改设置起始的url
start_urls = ['见评论区']
# 数据提取的方法:接收下载中间件传过来的response,定义对于网站相关的操作
def parse(self, response):
# 获取所有的教师节点
t_list = response.xpath('//div[@class="li_txt"]')
print(t_list)
# 遍历教师节点列表
tea_dist = {
}
for teacher in t_list:
# xpath方法返回的是选择器对象列表 extract()方法可以提取到selector对象中data对应的数据。
tea_dist['name'] = teacher.xpath('./h3/text()').extract_first()
tea_dist['title'] = teacher.xpath('./h4/text()').extract_first()
tea_dist['desc'] = teacher.xpath('./p/text()').extract_first()
yield teacher
然后再运行,会发现已经可以正常运行!
4.明确了爬虫所爬取数据之后,使用管道进行数据持久化操作:
修改itcast.py爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from ..items import UbuntuItem
class ItcastSpider(scrapy.Spider):
# 爬虫运行时的参数
name = 'itcast'
# 检查允许爬的域名
allowed_domains = ['itcast.cn']
# 1.修改设置起始的url
start_urls = ['见评论区']
# 数据提取的方法:接收下载中间件传过来的response,定义对于网站相关的操作
def parse(self, response):
# 获取所有的教师节点
t_list = response.xpath('//div[@class="li_txt"]')
print(t_list)
# 遍历教师节点列表
item = UbuntuItem()
for teacher in t_list:
# xpath方法返回的是选择器对象列表 extract()方法可以提取到selector对象中data对应的数据。
item['name'] = teacher.xpath('./h3/text()').extract_first()
item['title'] = teacher.xpath('./h4/text()').extract_first()
item['desc'] = teacher.xpath('./p/text()').extract_first()
yield item
注意:
- scrapy.Spider爬虫类中必须有名为parse的解析;
- 如果网站结构层次比较复杂,也可以自定义其他解析函数;
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制;
- 启动爬虫的时候注意启动的位置,是在项目路径下启动;
- parse()函数中使用yield返回数据,注意:解析函数中的yield能够传递的对象只能是:BaseItem, Request, dict, None。
小知识点1——定位元素以及提取数据、属性值的方法:
(解析并获取scrapy爬虫中的数据: 利用xpath规则字符串进行定位和提取)
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法;
- 额外方法extract():返回一个包含有字符串的列表;
- 额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None。
小知识点2——response响应对象的常用属性:
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.requests.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
5.管道保存数据
在pipelines.py文件中定义对数据的操作!
- 定义一个管道类;
- 重写管道类的process_item方法;
- process_item方法处理完item之后必须返回给引擎。
️初级篇:
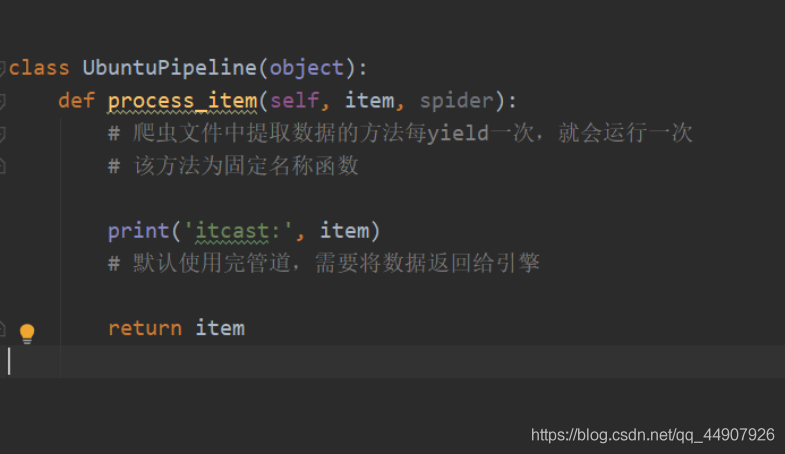
️进阶篇:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class UbuntuPipeline(object):
def __init__(self):
self.file = open('itcast.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
# 将item对象强制转为字典,该操作只能在scrapy中使用
item = dict(item)
# 爬虫文件中提取数据的方法每yield一次,就会运行一次
# 该方法为固定名称函数
# 默认使用完管道,需要将数据返回给引擎
# 1.将字典数据序列化
'''ensure_ascii=False 将unicode类型转化为str类型,默认为True'''
json_data = json.dumps(item, ensure_ascii=False, indent=2) + ',\n'
# 2.将数据写入文件
self.file.write(json_data)
return item
def __del__(self):
self.file.close()
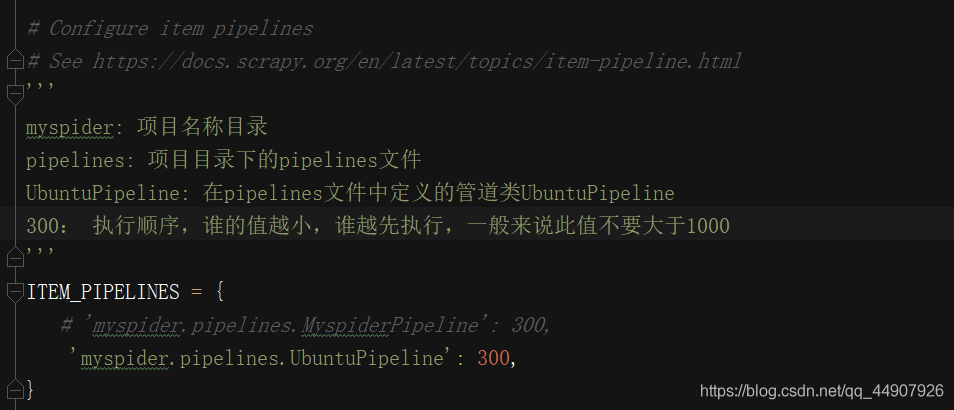
6.settings.py配置启用管道:
在settings文件中,解封代码,说明如下:
7.scrapy数据建模与请求:
(通常在做项目的过程中,在items.py中进行数据建模!)
(1)为什么建模?
- 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查,值不相同会报错;
- 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替;
- 使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类。
(2)本项目中实操:
在items.py文件中操作:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class UbuntuItem(scrapy.Item):
# 讲师名字
name = scrapy.Field()
# 讲师职称
title = scrapy.Field()
# 讲师座右铭
desc = scrapy.Field()
注意:
- from …items import UbuntuItem这一行代码中 注意item的正确导入路径,忽略pycharm标记的错误;
- python中的导入路径要诀:从哪里开始运行,就从哪里开始导入。
8.设置user-agent:
# settings.py文件中找到如下代码解封,并加入UA:
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36',
}
9.到目前为止,一个入门级别的scrapy爬虫已经OK了,基操都使用了!
如何run呢?
现在cd到项目目录下,输入
scrapy crawl itcast
即可运行scrapy!
10.开发流程总结:
-
创建项目:
scrapy startproject 项目名 -
明确目标:
在items.py文件中进行建模! -
创建爬虫:
创建爬虫:
scrapy genspider 爬虫名 允许的域名
完成爬虫:
修改start_urls; 检查修改allowed_domains; 编写解析方法! -
保存数据:
在pipelines.py文件中定义对数据处理的管道
在settings.py文件中注册启用管道
结语:
通过上面的学习,你已经可以独立创建一个scrapy项目并使用此框架进行简单的爬虫项目编写。但是!任何一种功夫都不是一下就能学好学会学精的!所以跟着本专栏,只要你跟着潜心学完,那么!恭喜你!你已经是名优秀的scrapy框架使用者了!!!
第三部分——In The End!

| 从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你! |
智能推荐
leetcode 172. 阶乘后的零-程序员宅基地
文章浏览阅读63次。题目给定一个整数 n,返回 n! 结果尾数中零的数量。解题思路每个0都是由2 * 5得来的,相当于要求n!分解成质因子后2 * 5的数目,由于n中2的数目肯定是要大于5的数目,所以我们只需要求出n!中5的数目。C++代码class Solution {public: int trailingZeroes(int n) { ...
Day15-【Java SE进阶】IO流(一):File、IO流概述、File文件对象的创建、字节输入输出流FileInputStream FileoutputStream、释放资源。_outputstream释放-程序员宅基地
文章浏览阅读992次,点赞27次,收藏15次。UTF-8是Unicode字符集的一种编码方案,采取可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节。文件字节输入流:每次读取多个字节到字节数组中去,返回读取的字节数量,读取完毕会返回-1。注意1:字符编码时使用的字符集,和解码时使用的字符集必须一致,否则会出现乱码。定义一个与文件一样大的字节数组,一次性读取完文件的全部字节。UTF-8字符集:汉字占3个字节,英文、数字占1个字节。GBK字符集:汉字占2个字节,英文、数字占1个字节。GBK规定:汉字的第一个字节的第一位必须是1。_outputstream释放
jeecgboot重新登录_jeecg 登录自动退出-程序员宅基地
文章浏览阅读1.8k次,点赞3次,收藏3次。解决jeecgboot每次登录进去都会弹出请重新登录问题,在utils文件下找到request.js文件注释这段代码即可_jeecg 登录自动退出
数据中心供配电系统负荷计算实例分析-程序员宅基地
文章浏览阅读3.4k次。我国目前普遍采用需要系数法和二项式系数法确定用电设备的负荷,其中需要系数法是国际上普遍采用的确定计算负荷的方法,最为简便;而二项式系数法在确定设备台数较少且各台设备容量差..._数据中心用电负荷统计变压器
HTML5期末大作业:网页制作代码 网站设计——人电影网站(5页) HTML+CSS+JavaScript 学生DW网页设计作业成品 dreamweaver作业静态HTML网页设计模板_网页设计成品百度网盘-程序员宅基地
文章浏览阅读7k次,点赞4次,收藏46次。HTML5期末大作业:网页制作代码 网站设计——人电影网站(5页) HTML+CSS+JavaScript 学生DW网页设计作业成品 dreamweaver作业静态HTML网页设计模板常见网页设计作业题材有 个人、 美食、 公司、 学校、 旅游、 电商、 宠物、 电器、 茶叶、 家居、 酒店、 舞蹈、 动漫、 明星、 服装、 体育、 化妆品、 物流、 环保、 书籍、 婚纱、 军事、 游戏、 节日、 戒烟、 电影、 摄影、 文化、 家乡、 鲜花、 礼品、 汽车、 其他 等网页设计题目, A+水平作业_网页设计成品百度网盘
【Jailhouse 文章】Look Mum, no VM Exits_jailhouse sr-iov-程序员宅基地
文章浏览阅读392次。jailhouse 文章翻译,Look Mum, no VM Exits!_jailhouse sr-iov
随便推点
chatgpt赋能python:Python怎么删除文件中的某一行_python 删除文件特定几行-程序员宅基地
文章浏览阅读751次。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。AI职场汇报智能办公文案写作效率提升教程 专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具。_python 删除文件特定几行
Java过滤特殊字符的正则表达式_java正则表达式过滤特殊字符-程序员宅基地
文章浏览阅读2.1k次。【代码】Java过滤特殊字符的正则表达式。_java正则表达式过滤特殊字符
CSS中设置背景的7个属性及简写background注意点_background设置背景图片-程序员宅基地
文章浏览阅读5.7k次,点赞4次,收藏17次。css中背景的设置至关重要,也是一个难点,因为属性众多,对应的属性值也比较多,这里详细的列举了背景相关的7个属性及对应的属性值,并附上演示代码,后期要用的话,可以随时查看,那我们坐稳开车了······1: background-color 设置背景颜色2:background-image来设置背景图片- 语法:background-image:url(相对路径);-可以同时为一个元素指定背景颜色和背景图片,这样背景颜色将会作为背景图片的底色,一般情况下设置背景..._background设置背景图片
Win10 安装系统跳过创建用户,直接启用 Administrator_windows10msoobe进程-程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏8次。Win10 安装系统跳过创建用户,直接启用 Administrator_windows10msoobe进程
PyCharm2021安装教程-程序员宅基地
文章浏览阅读10w+次,点赞653次,收藏3k次。Windows安装pycharm教程新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入下载安装PyCharm1、进入官网PyCharm的下载地址:http://www.jetbrains.com/pycharm/downl_pycharm2021
《跨境电商——速卖通搜索排名规则解析与SEO技术》一一1.1 初识速卖通的搜索引擎...-程序员宅基地
文章浏览阅读835次。本节书摘来自异步社区出版社《跨境电商——速卖通搜索排名规则解析与SEO技术》一书中的第1章,第1.1节,作者: 冯晓宁,更多章节内容可以访问云栖社区“异步社区”公众号查看。1.1 初识速卖通的搜索引擎1.1.1 初识速卖通搜索作为速卖通卖家都应该知道,速卖通经常被视为“国际版的淘宝”。那么请想一下,普通消费者在淘宝网上购买商品的时候,他的行为应该..._跨境电商 速卖通搜索排名规则解析与seo技术 pdf