案例:使用seaborn分析泰坦尼克号生还者数据_使用seaborn自带的泰坦尼克号生还乘客的数据集,其中各字节所代表的含义如下:survi-程序员宅基地
目录
3.3 绘制年龄分布图,通过seaborn的distplot函数查看乘客的年龄分布
3.4 从上图可以看出年龄呈现正态分布-- 对年龄缺失值进行填充,再次可视化
4.5 舱位等级、是否有家属字段与生还关系 (绘制图例分析)
数据背景:
泰坦尼克号是一艘英国的豪华邮轮,在1912年4月14日夜晚与一座冰山相撞后沉没。当时,这艘船上共有2224名乘客和船员,其中1517人丧生,大多数是在没有足够救生艇的情况下死亡。
根据官方记载,共有706人幸存了下来。经过调查和研究,我们知道以下几个关于泰坦尼克号幸存者的数据:
1. 船上的女性和儿童更容易幸存:其中妇女幸存率约为75%,儿童(年龄小于14岁)幸存率约为52%,而成年男性的幸存率仅为20%左右。
2. 社会地位也影响了幸存的机会:头等舱乘客中有63%的人幸存,二等舱乘客中有47%的人幸存,而三等舱乘客中只有24%的人幸存。
3. 幸存者多集中在逃生艇上:逃生艇上有1175人幸存,逃生艇上的幸存率高达61%。但同时,仅有499张逃生艇票被发放,造成了大量无法幸存的人员死亡。
总的来说,这些数据表明在泰坦尼克号上生还与性别、年龄和社会地位等因素有密切关系,同时逃生艇能力也是影响幸存率的重要因素。
seaborn 库介绍
Seaborn是基于Matplotlib的Python可视化库,能够轻松绘制美观、有吸引力的统计图表。Seaborn拥有独特的数据可视化风格和配色方案,可以帮助研究人员更加直观地展示数据,以及探索和理解数据之间的关系。
Seaborn常用的统计图表包括:
1. 直方图 2. 密度图 3. 散点图 4. 热图 5. 箱线图 6. 折线图
Seaborn还提供了多种工具,简化了某些常见可视化操作,比如聚类分析(clustermap)和时间序列图绘制等。此外,Seaborn集成了Pandas的数据结构,并提供了内置的数据集,可方便用户快速测试和尝试不同图形的生成方法。
总的来说,Seaborn简单易用,代码量较少,同时通过使用优雅的颜色主题和设计,让绘制出来的图像看起来非常漂亮和专业,成为Python数据科学领域中广泛使用的可视化库之一。
一、数据来源(数据的导入)
titanic.csv -- 泰坦尼克号生还者数据集
# 导入所需要的库
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np查看数据集信息,打印列名
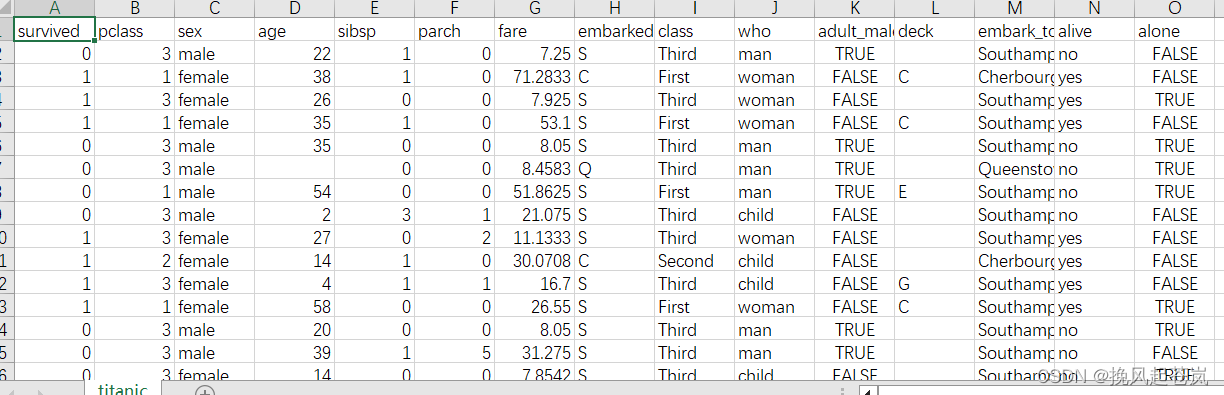
titanic = pd.read_csv('./data/titanic.csv')
titanic_columns = list(titanic.columns)
print(titanic_columns)
titanic.head()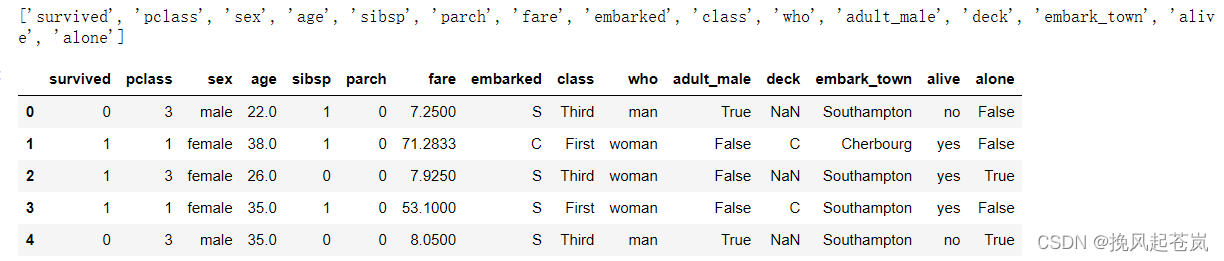
主要字段信息:
survived: 标识乘客是否生还,其中0代表未生还,1代表生还。该字段将作为本次可视化和分析的主要指标。
pclass: 乘客所在的船舱等级,取值范围为1至3。该字段可以用于探索船舱等级对生存率的影响。
sex: 乘客的性别,取值为 male 或 female。该字段可以用于探索不同性别对生存率的影响。
age: 乘客的年龄,取值范围为0.42至80岁。该字段可以用于探索不同年龄段对生存率的影响。
sibsp: 乘客在船上的兄弟姐妹或配偶数目,取值范围为0至8。该字段可以用于探索乘客在家庭中的地位对生存率的影响。
parch: 乘客在船上的父母或孩子数目,取值范围为0至6。该字段可以用于探索乘客在家庭中的地位对生存率的影响。
fare: 乘客购买的票价,取值范围为0至512.33。该字段可以用于探索票价对生存率的影响。
embarked: 乘客登船口岸,取值为 S(Southampton)、C(Cherbourg)或 Q(Queenstown)。该字段可以用于探索不同口岸对生存率的影响。
class: pclass 字段的别名。
who: 按性别通常使用的词语,即 man、woman 或 child。该字段可以用于探索不同性别和年龄段对生存率的影响。
adult_male: 标识乘客是否为成年男性,其中 True 代表成年男性,False 代表其他类型的乘客。该字段可以用于根据乘客类型分析其对生存率的影响。
deck: 乘客所属甲板,取值为 A-G 和 T(不明甲板)。该字段可以用于探索甲板位置对生存率的影响。
embark_town: embarked 字段的别名。
alive: survived 字段的别名。
alone: 标识乘客是否独自一人旅行,其中 True 代表独自旅行,False 代表与家庭成员一起旅行。该字段可以用于探索单身乘客对生存率的影响。二、主要分析的内容(定义问题)
本次分析中主要分析两个问题。。。。。
泰坦尼克号乘客基本信息分布情况??
乘客的信息与生还数据是否有关联??
三、数据清洗
3.1 查看是否有缺失值
print(titanic.shape)
titanic.isnull().sum()
3.2 查看数据基本信息
titanic.info() 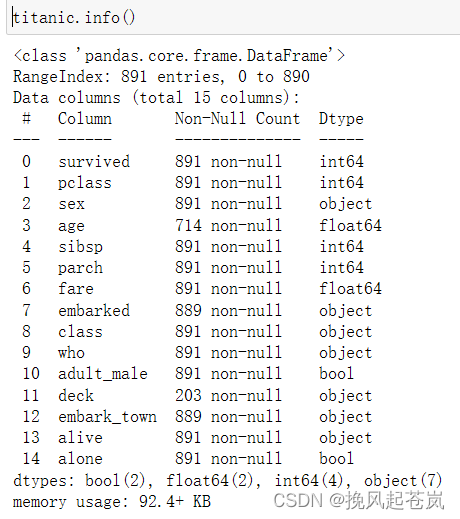
3.3 绘制年龄分布图,通过seaborn的distplot函数查看乘客的年龄分布
import warnings
warnings.filterwarnings('ignore') # 过滤警告信息
# 年龄分布图
plt.figure(figsize=(15,8))
sns.set(style='darkgrid',palette='muted',color_codes=True)
sns.distplot(titanic[titanic['age'].notnull()]['age']) # 取年龄不为空值的数据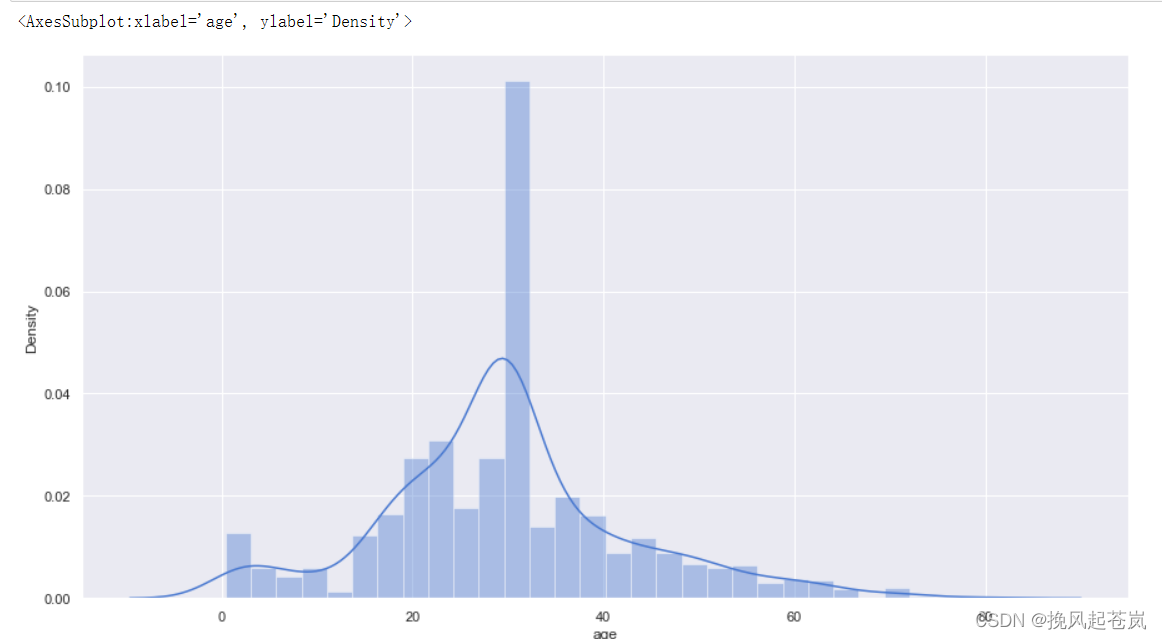
3.4 从上图可以看出年龄呈现正态分布-- 对年龄缺失值进行填充,再次可视化
plt.figure(figsize=(15,8))
titanic['age'] = titanic['age'].fillna(titanic['age'].mean())
sns.distplot(titanic['age'])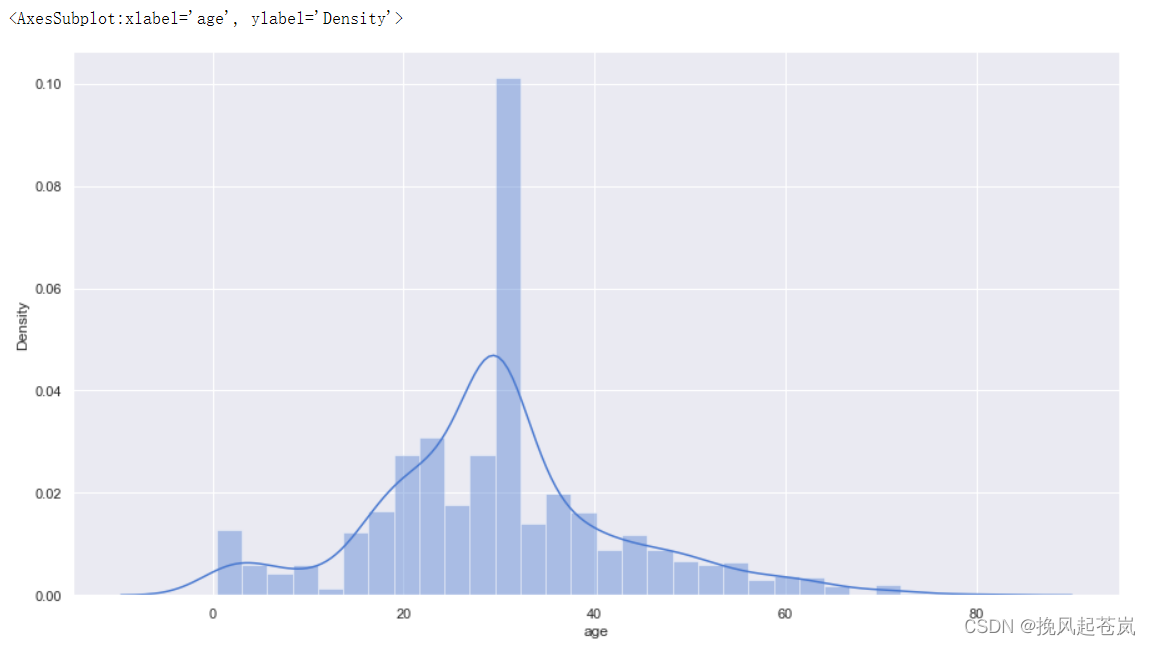
3.5 根据性别 绘制年龄分布图
# 乘客性别-年龄 处理
age_male = titanic[titanic.sex == 'male']['age'] # 男性
age_female = titanic[titanic.sex == 'female']['age'] # 女性# 绘制男性年龄分布图
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
from scipy.stats import norm
plt.figure(figsize=(15,8))
sns.distplot(age_male,bins=30,label='男性',kde=False,norm_hist=True)
sns.distplot(age_male,hist=False,kde=False,fit=norm,fit_kws={'color':'yellow'},label='男性正态分布图')
plt.legend(loc='best')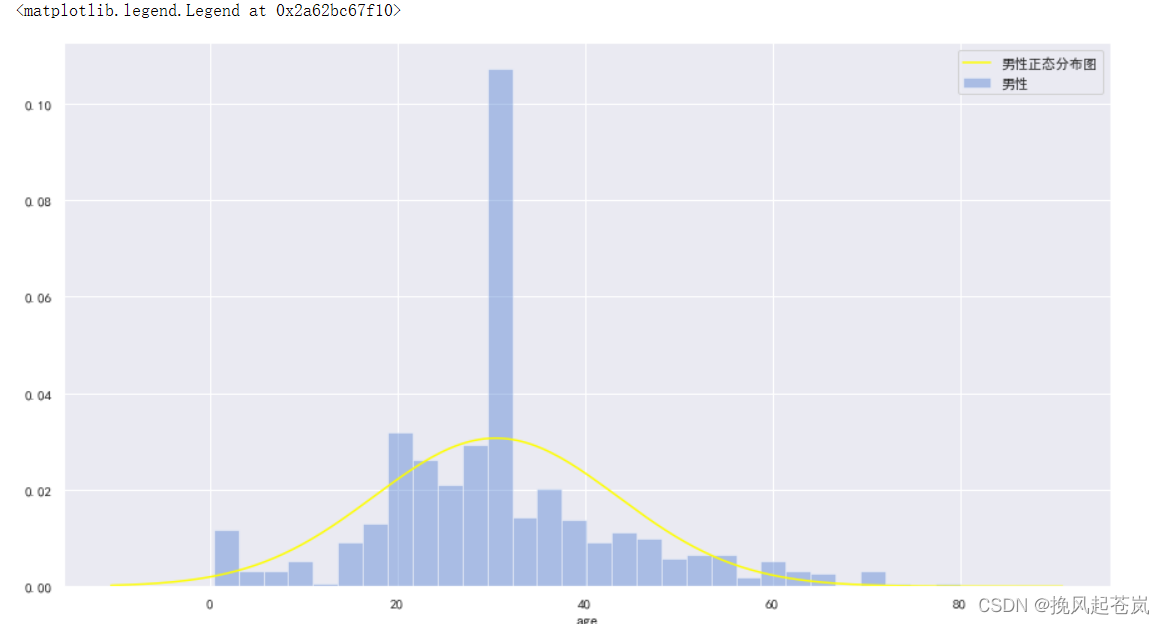
# 绘制女性年龄分布图
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15,8))
sns.distplot(age_female,bins=30,label='女性',kde=False,norm_hist=True,hist_kws={'color':'red'})
sns.distplot(age_female,hist=False,kde=False,fit=norm,fit_kws={'color':'blue'},label='女性正态分布图')
plt.legend(loc='best') 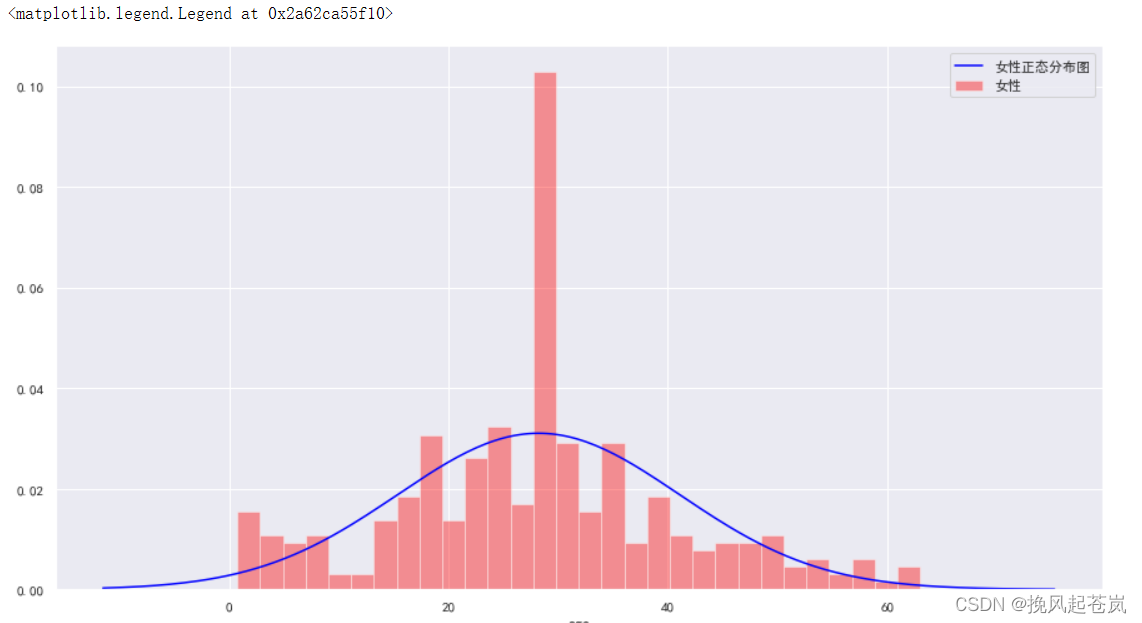
# 合并俩个图
plt.figure(figsize=(15,8))
sns.distplot(age_male,bins=30,label='男性',kde=False,norm_hist=True)
sns.distplot(age_male,hist=False,kde=False,fit=norm,fit_kws={'color':'yellow'},label='男性正态分布图')
plt.legend(loc='best')
sns.distplot(age_female,bins=30,label='女性',kde=False,norm_hist=True,hist_kws={'color':'red'})
sns.distplot(age_female,hist=False,kde=False,fit=norm,fit_kws={'color':'blue'},label='女性正态分布图')
plt.legend(loc='best') 
3.6 登船地点分布情况(用countplot函数可视化)
plt.figure(figsize=(15,8))
sns.countplot(x='embarked',data=titanic)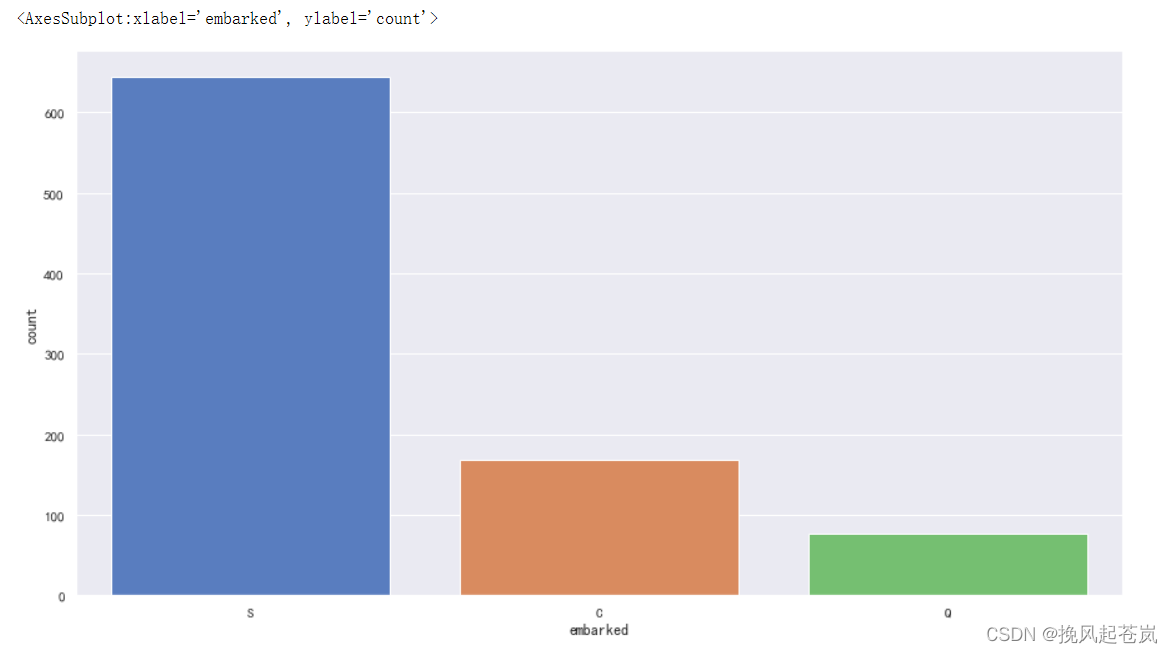
可以看到s点占比比较多,用s点填充embarked列的空值
titanic['embarked'] = titanic['embarked'].fillna('s')
titanic.isnull().sum()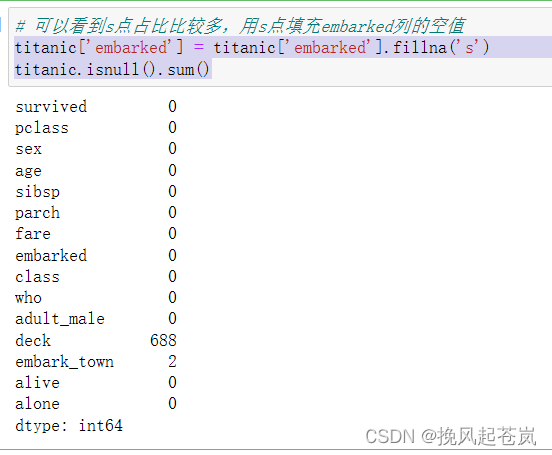
3.7 对所定义的问题起无用的列 一并删除
这里删除('survived', 'pclass', 'sibsp', 'parch', 'who', 'adult_male', 'deck', 'embark_town')
# 对于deck字段,由于缺失值太多,因此将该列删除,同时数据中多余字段对需求分析不起作用,也可以一起删除
titanic = titanic.drop(['survived', 'pclass', 'sibsp', 'parch', 'who', 'adult_male', 'deck', 'embark_town'],axis=1)
titanic.head()
# titanic.to_csv('./data/titanic_cleared.csv')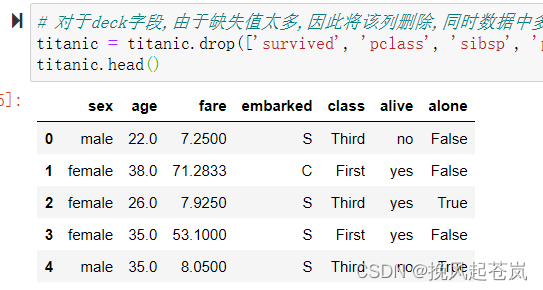
四、数据探索
4.1 数据探索的作用
数据探索是指对一组数据进行初步的分析和洞察,主要目的是了解数据本身的特征和规律性,并提取出其中的有用信息。数据探索过程中可以使用多种工具和技术,包括统计学方法、数据可视化、机器学习等等。
在数据探索中,通常会进行以下步骤:
1. 数据获取:从各种来源收集数据并整理处理。
2. 数据预处理:清洗数据并填充缺失值或去除异常值等预处理步骤。
3. 数值分布分析:使用直方图、密度图等可视化方式展现数据的总体分布情况以及某些属性之间的关系。
4. 相关性分析:通过相关系数矩阵计算不同属性之间的相关性,并可视化展示帮助发现变量之间的相互关系。
5. 建模与预测:根据已有数据建立数学模型,进行预测未来趋势。
数据探索能够帮助我们快速了解数据的特点、隐含信息和规律性,为进一步分析和处理数据任务做好准备。
4.2 探索性别、年龄、船舱等级之间的关系(绘图分析)
# 性别分组
sns.countplot(x='sex',data=titanic)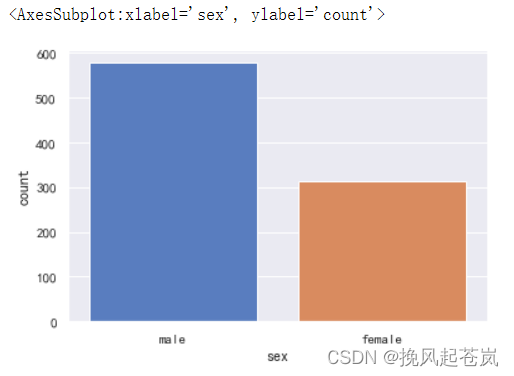
# 乘客性别,年龄分布
sns.boxplot(x='sex',y='age',data=titanic) 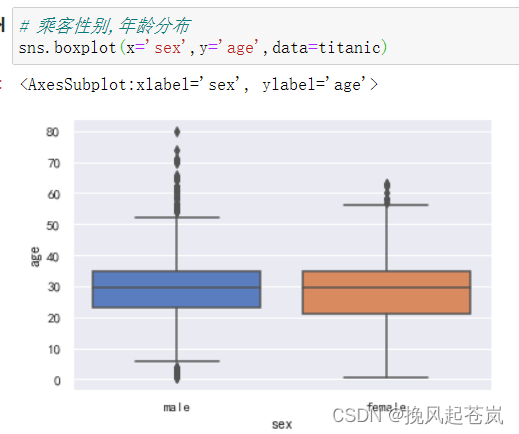
# 船舱等级数量分布
sns.countplot(x='class',data=titanic) 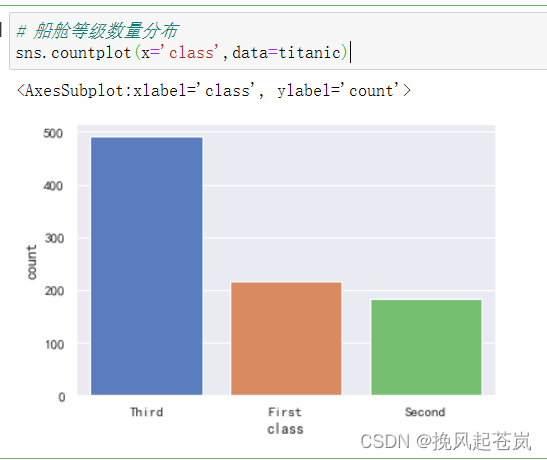
# 船舱等级年龄分布
sns.violinplot(x='class',y='age',data=titanic) 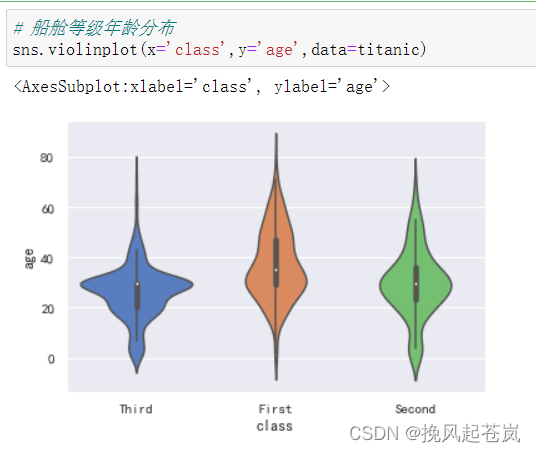
4.2 结论: 头等舱的年龄跨度比较大,第三船舱的中年人分布最多
4.3 对生还者计数分析
# 生还乘客计数
# alone(有无携带家属)
sns.countplot(x='alone',data=titanic)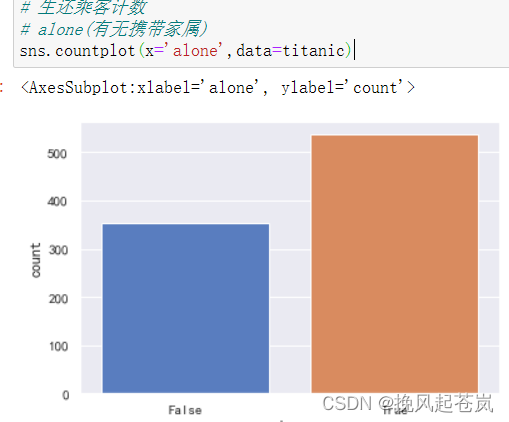
# 生还乘客计数
sns.countplot(x='alive', data=titanic)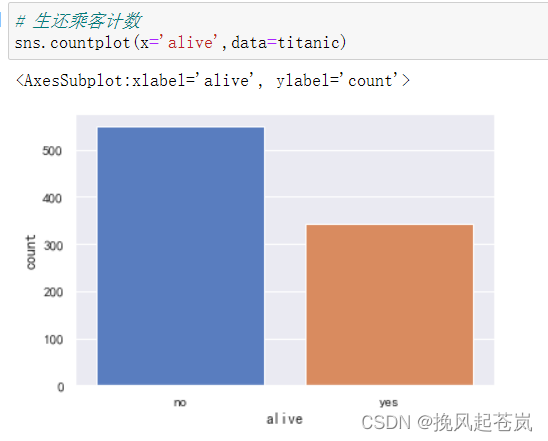
可见,生还乘客较少。按下来重点分析生还乘客与其他字段是否有关联。
# 乘客性别与生还关系图
sns.countplot(x='alive',hue='sex',data=titanic)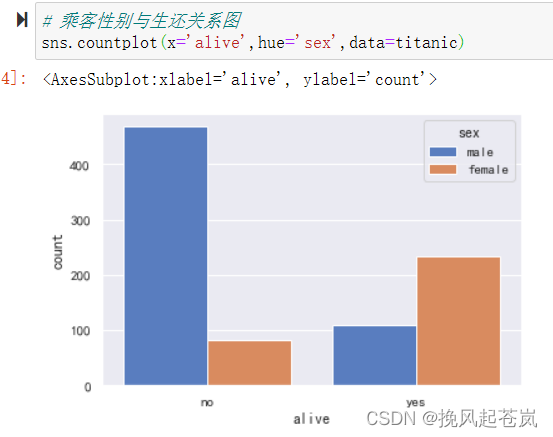
# 乘客年龄分段
titanic['age_level'] = pd.cut(titanic['age'],bins=[0,16,60,100], labels=['child', 'midlife', 'aged'])
titanic 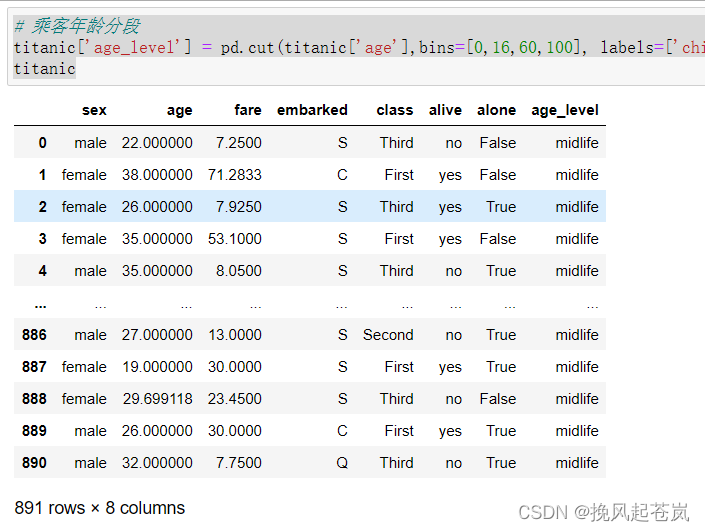
# 年龄分段方法二
def agelevel(age):
if age<16:
return 'child'
elif age>=60:
return 'aged'
else:
return 'midlife'
titanic['age'].map(agelevel)
# 乘客年龄段分布
sns.countplot(x='age_level', data=titanic) 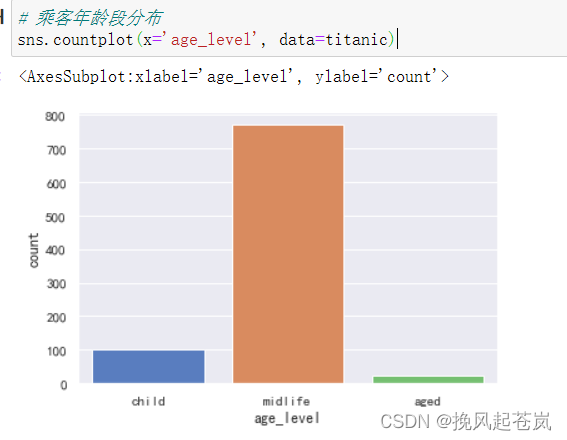
4.4 绘制乘客年龄段与生还关系图
# 乘客年龄段与生还关系图1
sns.countplot(x='alive', hue='age_level', data=titanic)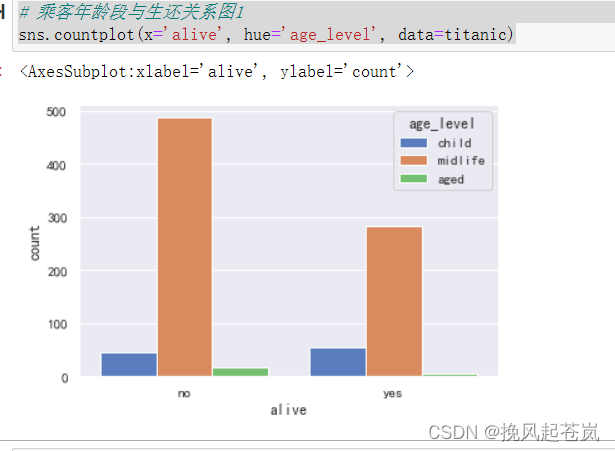
# 乘客年龄段与生还关系图2
sns.countplot(x='age_level', hue='alive', data=titanic)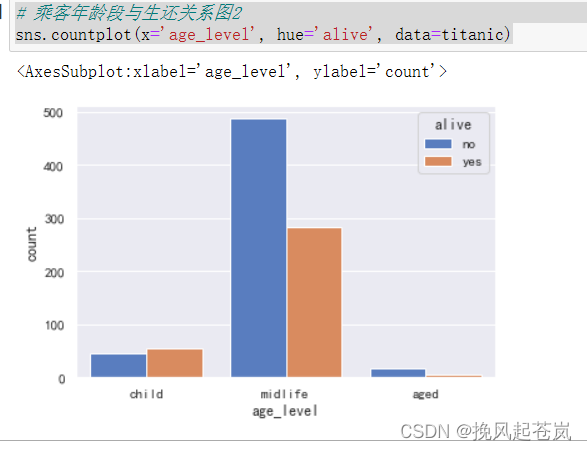
如上图所示,乘客年龄段与生还之间的关系并不明显,但小孩的生还几率还是比较大的,而老人却相对更小。
4.5 舱位等级、是否有家属字段与生还关系 (绘制图例分析)
舱位等级、是否有家属字段与生还关系 图1
# 用分类数据散点图表示
sns.swarmplot(x='class', y='alone', hue='alive', data=titanic)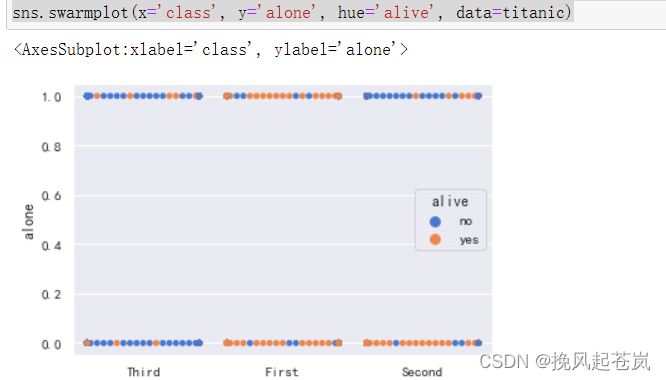
结合class和alone字段进行分析,乘客仓位等级越高,生还几率越大,单独的乘客生还几率也更大一些
舱位等级、是否有家属字段与生还关系 图2
# 在Seaborn中绘制分面网格图,按照指定的变量将数据分割成多个面,在每个面上叠加任意的图形,用于探索一个变量如何影响数据分布的差异
g = sns.FacetGrid(titanic, col='class', row='alone')
g.map(sns.countplot, 'alive')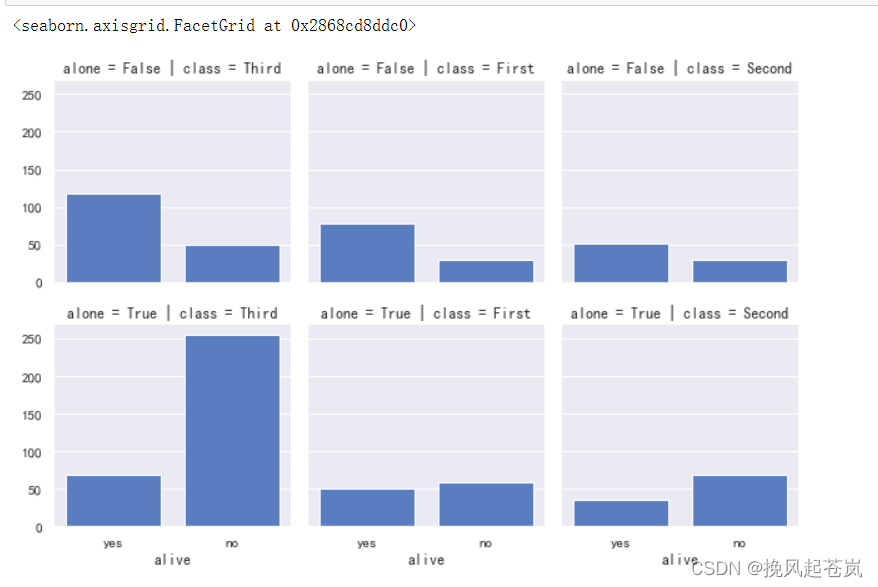
五、结论
5.1 分析结论
男性乘客比女性乘客更多一些。 男性和女性的年龄很接近,但女性乘客的年龄跨度更大一些。 头等舱的年龄跨度较大,第三级船舱的中年人分布最多。 单独的乘客数量更多一些。 未生还的乘客人数更多一些。 生还乘客中女性占大多数。 成年人乘客数量占比很大,而小孩和年长乘客的占比很小。 乘客年龄与生还乘客之间的关系并不明显,但小孩的生还几率还是比较大的,而老人却相对更小。 乘客仓位等级越高,生还几率越大,单独的乘客生还的几率也更大一些。
5.2 所使用的seaborn库函数
1. `distplot()`
`distplot()`函数绘制一维直方图和核密度估计曲线,主要用于描述数据分布情况。可以通过该函数来对单个变量进行探索性数据分析。
sns.distplot(x, bins=None, hist=True, kde=True, rug=False)- x: 需要显示的一组观测值。
- bins: 直方图的柱子数量,默认为自动确定(根据数据适当规模)。
- hist: 是否绘制直方图,默认为True。
- kde: 是否绘制核密度估计曲线,默认为True。
- rug: 是否在x轴上加入小的观测值,默认为False。
2. `countplot()`
`countplot()`函数绘制分类变量数量的柱状图,可以展示各类别数据占比或频数,并用于比较不同类别之间的差异。
sns.countplot(x=None, y=None, data=None)- x: 字符串格式,x轴上需要显示的列名(可以理解为分类变量),默认为空。
- y: 字符串格式,y轴上需要显示的列名(可以理解为分类变量),默认为空。
- data: 数据源,必须为Pandas的dataframe对象。
3. `boxplot()`
`boxplot()`函数可以绘制箱型图,用于展示一组数据的中位数、最大值、最小值、上四分位数和下四分位数等基本信息。
sns.boxplot(x=None, y=None, data=None)- x: 字符串格式,x轴上需要显示的列名(可以理解为分类变量),默认为空。
- y: 字符串格式,y轴上需要显示的列名(可以理解为连续变量),默认为空。
- data: 数据源,必须为Pandas的dataframe对象。
4. `violinplot()`
`violinplot()`函数可以绘制小提琴图,用于3age_midlife3展示数据分布的形状、位置以及范围等信息。
sns.violinplot(x=None, y=None, data=None)- x: 字符串格式,x轴上需要显示的列名(可以理解为分类变量),默认为空。
- y: 字符串格式,y轴上需要显示的列名(可以理解为连续变量),默认为空。
- data: 数据源,必须为Pandas的dataframe对象。
5. `swarmplot()`
`swarmplot()`函数用于散点图形式表示分类数据。可以清晰地显示各数据类别属性之间的关系,并适用于小的单调变化情形。
sns.swarmplot(x=None, y=None, hue=None, data=None)- x: 字符串格式,x轴上需要显示的列名(可以理解为分类变量),默认为空。
- y: 字符串格式,y轴上需要显示的列名(可以理解为连续变量),默认为空。
- hue: 字符串格式,按照哪一列进行分类(即区分样本来源)。
- data: 数据源,必须为Pandas的dataframe对象。
6. `FacetGrid()`
`FacetGrid()`函数可以创建一个带有子图网格的对象,将数据按照指定变量分割成多个子图,并在每个子图上叠加不同的图形。这个函数即支持面板级别绘图,也支持在一个面板内多次画图。
sns.FacetGrid(data, row=None, col=None, hue=None)- data: 数据源,必须为Pandas的dataframe对象。
- row: 字符串格式,用于按照行分类的标签,通常是字符串格式列名,默认为空。
- col: 字符串格式,用于按照列分类的标签,通常是字符串格式列名,默认为空。
- hue: 字符串格式,按照哪一列进行分类(即区分样本来源)。
以上是这6个主要的Seaborn可视化函数的简单介绍及其用法,具体函数参数还需根据实际应用场景进行选取和设置。
5.3 本案例完整代码
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
titanic = pd.read_csv('./data/titanic.csv')
titanic_columns = list(titanic.columns)
print(titanic_columns)
titanic.head()
print(titanic.shape)
titanic.isnull().sum()
titanic.info()
import warnings
warnings.filterwarnings('ignore') # 过滤警告信息
# 年龄分布图
plt.figure(figsize=(15,8))
sns.set(style='darkgrid',palette='muted',color_codes=True)
sns.distplot(titanic[titanic['age'].notnull()]['age']) # 取年龄不为空值的数据
plt.figure(figsize=(15,8))
titanic['age'] = titanic['age'].fillna(titanic['age'].mean())
sns.distplot(titanic['age'])
# 乘客性别-年龄 处理
age_male = titanic[titanic.sex == 'male']['age'] # 男性
age_female = titanic[titanic.sex == 'female']['age'] # 女性
# 绘制男性年龄分布图
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
from scipy.stats import norm
plt.figure(figsize=(15,8))
sns.distplot(age_male,bins=30,label='男性',kde=False,norm_hist=True)
sns.distplot(age_male,hist=False,kde=False,fit=norm,fit_kws={'color':'yellow'},label='男性正态分布图')
plt.legend(loc='best')
# 绘制女性年龄分布图
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15,8))
sns.distplot(age_female,bins=30,label='女性',kde=False,norm_hist=True,hist_kws={'color':'red'})
sns.distplot(age_female,hist=False,kde=False,fit=norm,fit_kws={'color':'blue'},label='女性正态分布图')
plt.legend(loc='best')
# 合并俩个图
plt.figure(figsize=(15,8))
sns.distplot(age_male,bins=30,label='男性',kde=False,norm_hist=True)
sns.distplot(age_male,hist=False,kde=False,fit=norm,fit_kws={'color':'yellow'},label='男性正态分布图')
plt.legend(loc='best')
sns.distplot(age_female,bins=30,label='女性',kde=False,norm_hist=True,hist_kws={'color':'red'})
sns.distplot(age_female,hist=False,kde=False,fit=norm,fit_kws={'color':'blue'},label='女性正态分布图')
plt.legend(loc='best')
# 登船地点用countplot函数可视化
plt.figure(figsize=(15,8))
sns.countplot(x='embarked',data=titanic)
# 可以看到s点占比比较多,用s点填充embarked列的空值
titanic['embarked'] = titanic['embarked'].fillna('s')
titanic.isnull().sum()
# 对于deck字段,由于缺失值太多,因此将该列删除,同时数据中多余字段对需求分析不起作用,也可以一起删除
titanic = titanic.drop(['survived', 'pclass', 'sibsp', 'parch', 'who', 'adult_male', 'deck', 'embark_town'],axis=1)
titanic.head()
# titanic.to_csv('./data/titanic_cleared.csv')
# 数据探索
# 性别分组
sns.countplot(x='sex',data=titanic)
# 乘客性别,年龄分布
sns.boxplot(x='sex',y='age',data=titanic)
# 船舱等级数量分布
sns.countplot(x='class',data=titanic)
# 船舱等级年龄分布
sns.violinplot(x='class',y='age',data=titanic)
# 如上所示,头等舱的年龄跨度比较大,第三船舱的中年人分布最多
# 生还乘客计数
# alone(有无携带家属)
sns.countplot(x='alone',data=titanic)
# 生还乘客计数
sns.countplot(x='alive',data=titanic)
# 乘客性别与生还关系图
sns.countplot(x='alive',hue='sex',data=titanic)
# 乘客年龄分段
titanic['age_level'] = pd.cut(titanic['age'],bins=[0,16,60,100], labels=['child', 'midlife', 'aged'])
titanic
# 年龄分段方法二
def agelevel(age):
if age<16:
return 'child'
elif age>=60:
return 'aged'
else:
return 'midlife'
titanic['age'].map(agelevel)
# 乘客年龄段分布
sns.countplot(x='age_level', data=titanic)
# 乘客年龄段与生还关系图1
sns.countplot(x='alive', hue='age_level', data=titanic)
# 乘客年龄段与生还关系图2
sns.countplot(x='age_level', hue='alive', data=titanic)
# 舱位等级、是否有家属字段与生还关系1
# 用分类数据散点图表示
sns.swarmplot(x='class', y='alone', hue='alive', data=titanic)
# 舱位等级、是否有家属字段与生还关系2
# 在Seaborn中绘制分面网格图,按照指定的变量将数据分割成多个面,在每个面上叠加任意的图形,用于探索一个变量如何影响数据分布的差异
g = sns.FacetGrid(titanic, col='class', row='alone')
g.map(sns.countplot, 'alive')智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数