水文分析提取河网
The topic of this article is the application of information technologies in environmental science, namely, in hydrology. Below is a description of the algorithm for ranking rivers and the plugin we implemented for the open-source geographic information system QGIS.
本文的主题是信息技术在环境科学(即水文学)中的应用。 以下是对河流进行排名的算法的说明,以及我们为开源地理信息系统QGIS实现的插件。
An important aspect of hydrological surveys is not only the collection of information received from research expeditions and automatic devices but also the analysis of all the obtained data, including the use of GIS (geoinformation systems). However, exploration of the spatial structure of hydrological systems can be difficult due to a large amount of data. In such cases, we cannot do research without using additional tools that allow us to automate the process.
水文调查的一个重要方面不仅是收集从研究考察和自动装置获得的信息,而且还包括对所有获得的数据进行分析,包括使用GIS(地理信息系统)。 然而,由于大量的数据,探索水文系统的空间结构可能很困难。 在这种情况下,如果不使用允许我们使过程自动化的其他工具,我们将无法进行研究。
Visualization plays an important role when working with spatial data. Correct visual representation of the results of the analysis helps to better understand the structure of spatial objects and to know something new. For the image of rivers in classical cartography, the following method is used: rivers are represented as a solid line with a gradual thickening (depending on the number of tributaries that flow into the river) from the source to the mouth of the river. Moreover, segments of the river network often need to be ranked by the degree of distance from the source. This type of information is important not only for visualization, but also for a more complete perception of the data structure, its spatial distribution, and subsequent processing.
在处理空间数据时,可视化起着重要作用。 分析结果的正确视觉表示有助于更好地了解空间对象的结构并了解新知识。 对于经典制图中的河流图像,使用以下方法:河流表示为一条实线,从源头到河口逐渐增粗(取决于流入河流的支流的数量)。 此外,河网的各部分通常需要按距水源的距离程度进行排序。 这类信息不仅对于可视化很重要,而且对于更完整地了解数据结构,其空间分布和后续处理也很重要。
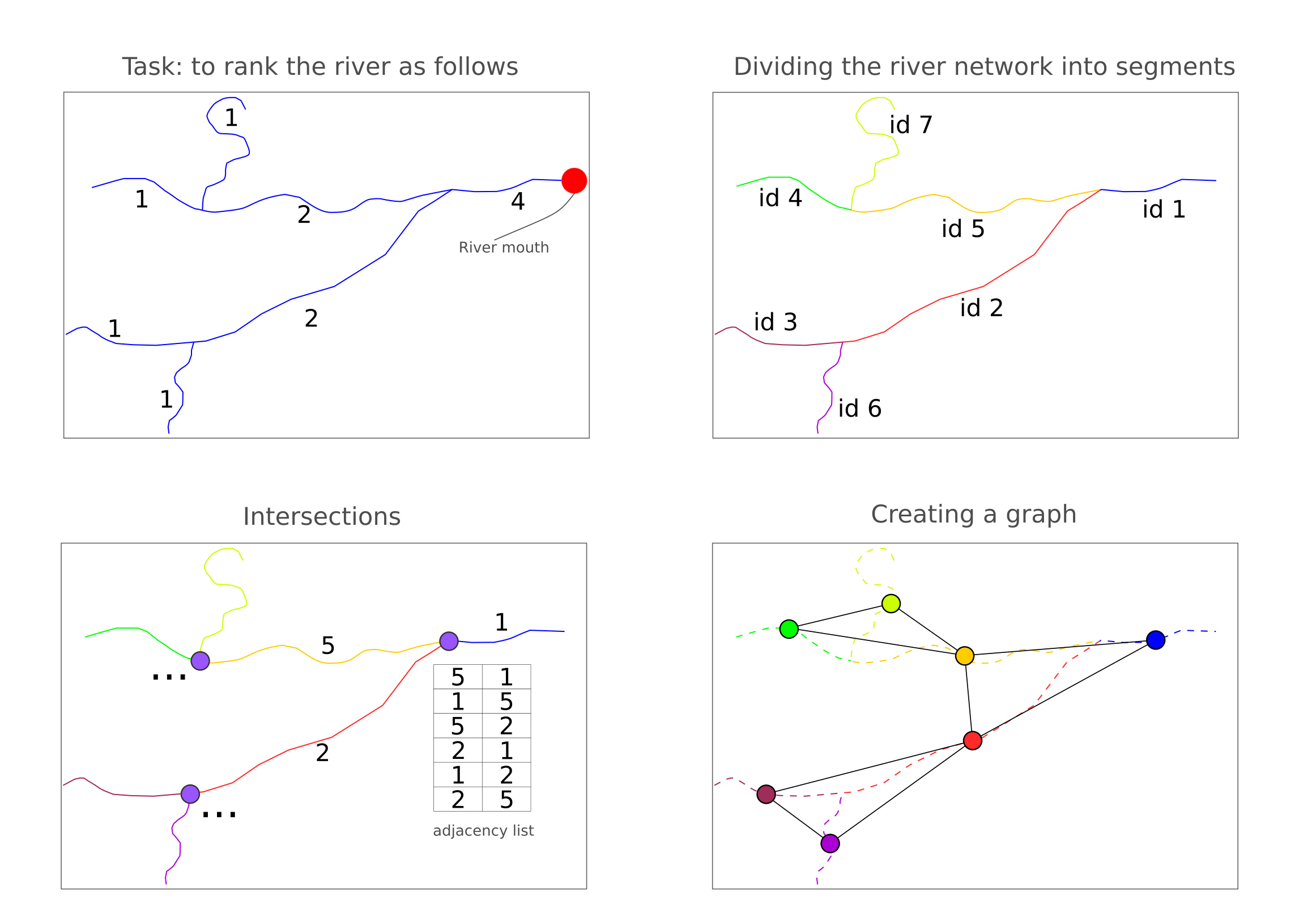
The problem of ranking rivers can be illustrated as follows (Fig. 1):
河流排名问题可以说明如下(图1):
Thus, each segment of the river needs to be mapped to a value that shows how many segments flow into this section.
因此,河流的每个部分都需要映射到一个值,该值显示有多少部分流入该部分。
Modern GIS, such as ArcGIS or its open-source competitor QGIS, have tools for working with river networks. However, the river ranking tool requires a large number of additional auxiliary materials and, as it seems to us, unnecessary transformations. For example, for an existing GIS tool to start working with river networks you need to prepare a digital elevation model. A significant disadvantage, in addition to complex and multi-stage data preparation, is the inability to use already prepared vector layers with a river network for analysis, which limits the possibility of using digital bases from open sources (OpenStreetMap or Natural Earth).
诸如ArcGIS或其开源竞争对手QGIS之类的现代GIS具有用于河网的工具。 但是,河流排名工具需要大量其他辅助材料,并且在我们看来,这是不必要的改造。 例如,要使一个现有的GIS工具开始与河网一起工作,您需要准备一个数字高程模型。 除复杂且多阶段的数据准备外,一个重要的缺点是无法将已经准备好的矢量层与河流网络一起使用来进行分析,这限制了使用来自开源(OpenStreetMap或Natural Earth)的数字基础的可能性。
Of course, you can assign attribute values to segments without using algorithms, but this approach is no longer relevant if you need to rank the network with several thousand segments.
当然,可以在不使用算法的情况下将属性值分配给段,但是如果需要对具有数千个段的网络进行排名,则此方法不再适用。
We decided to automate this procedure by representing the river network as a graph and then applying graph traversal algorithms. To simplify the user’s work with the implemented algorithm, a plugin for the QGIS geoinformation system — “Lines Ranking” was written. The code is distributed freely and is available in the QGIS repository, as well as on GitHub.
我们决定通过将河流网络表示为图形然后应用图形遍历算法来自动化此过程。 为了简化用户使用已实现算法的工作,编写了QGIS地理信息系统的插件“行排名”。 该代码是免费分发的,可以在QGIS存储库以及GitHub中获得 。
Installation
安装
The plugin requires QGIS version >= 3.14, as well as the following dependencies: python libraries — networkx, pandas.
该插件要求QGIS版本> = 3.14,以及以下依赖项:python库-networkx,pandas。
For Linux:
对于Linux:
$ locate pip3
$找到pip3
$ cd <your system pip3 path from previous step>
$ cd <上一步中的系统pip3路径>
$ pip3 install pandas
$ pip3安装熊猫
$ pip3 install networkx
$ pip3安装networkx
For Windows:
对于Windows:
In command line OSGeo4W:
在命令行OSGeo4W中:
$ pip install pandas
$ pip安装熊猫
$ pip install networkx
$ pip安装networkx
Using
使用
Input data is a vector layer consisting of objects with a linear geometry type (Line, MultiLine). Custom attributes are stored in the input layer to the output layer.
输入数据是一个矢量层,由具有线性几何类型(线,多线)的对象组成。 定制属性存储在输入层到输出层中。
We do not recommend using a field named “fid” for the input layer. At the stage of connecting gaps in the river network, using the built — in module of the GRASS package- v.clean where this field name is the “system” one.
我们不建议在输入层使用名为“ fid”的字段。 在连接河网中的差距的阶段,使用GRASS软件包v.clean的内置模块,此字段名称为“系统”。
Also, an obligatory input parameter is a point (Start Point Coordinates) that determines the position of the mouth of the river network. It can be set from the map, from a file, or from a layer uploaded to QGIS. The position of the river mouth can be approximate. The calculation is based on the segment of the river network closest to the point (the closing vertex of the future graph).
同样,强制性输入参数是确定河网口位置的点(起点坐标)。 可以从地图,文件或上传到QGIS的图层中进行设置。 河口的位置可以近似。 该计算基于最接近该点(未来图形的闭合顶点)的河网段。
Optional input data:
可选输入数据:
- the threshold for “tightening” gaps in the river network (Spline Threshold). This operation involves the use of a package of GRASS for QGIS. If the specified package is missing, you should fix the gaps in another way and leave this field empty; 缩小河网差距的阈值(样条阈值)。 此操作涉及将GRASS软件包用于QGIS。 如果缺少指定的程序包,则应以其他方式解决差距,并将此字段留空;
- custom field names for the output layer. Allows the user to assign a field name to record the rank of each segment (Rank fieldname), the number of tributaries (Flow field name), and the distance from the mouth in meters (Distance field name). If parameters are not set , the default names of the fields are Rank, Value, and Distance; 输出层的自定义字段名称。 允许用户分配一个字段名称,以记录每个段的等级(等级字段名称),支流数量(流字段名称)以及到嘴的距离(以米为单位)(距离字段名称)。 如果未设置参数,则字段的默认名称为Rank,Value和Distance;默认值为0。
- location of the output file. If this parameter is omitted, a temporary layer will be created and added to the QGIS layer stack; 输出文件的位置。 如果省略此参数,将创建一个临时层并将其添加到QGIS层堆栈中。
We can define the task performed by the algorithm as follows: compare the total number of tributaries flowing into each segment of the river, calculate the number of tributaries for each segment, as well as the distance of the farthest point of the segment from the mouth.
我们可以定义算法执行的任务,如下所示:比较流入河流各段的支流总数,计算各段支流的数量,以及该段最远点到河口的距离。
算法说明 (Algorithm description)
In GIS, data can be presented in two main formats: raster and vector. A raster is a matrix where a certain parameter value is stored in each pixel. Satellite images, reanalysis grids, various output layers from climate models, and others are often represented in raster format in environmental science. Vector data is represented as simple geometric objects, such as points, lines, and polygons. Each object in a vector format can be associated with some information in the form of attributes. All the actions described below will be performed on the vector layer of the river network.
在GIS中,数据可以两种主要格式表示:栅格和矢量。 栅格是一个矩阵,其中某个参数值存储在每个像素中。 卫星图像,重新分析网格,气候模型的各种输出层等在环境科学中通常以栅格格式表示。 矢量数据表示为简单的几何对象,例如点,线和多边形。 向量格式的每个对象都可以与属性形式的某些信息相关联。 下面描述的所有动作将在河网的矢量层上执行。
As a result, the algorithm returns a vector layer in which each object is assigned attributes that determine the distance of segments from the river mouth and the total number of tributaries that flow into this segment.
结果,该算法返回一个向量层,在该向量层中为每个对象分配了属性,这些属性确定了各段距河口的距离以及流入该段的支流的总数。
Preprocessing input data
预处理输入数据
Note that the topology of the original vector layer may be corrupted. The reason for this may be export / import between different GIS, incorrect file creation, etc. Corrupted layer topology can be expressed in the absence of connections between objects, i.e. the formation of various breaks (Fig. 2), creating additional closures, intersections, etc.
请注意,原始矢量层的拓扑可能已损坏。 造成这种情况的原因可能是在不同的GIS之间进行导出/导入,文件创建不正确等。在对象之间没有连接的情况下,也可以表示损坏的层拓扑,即形成各种中断(图2),从而创建其他闭合,交叉点等
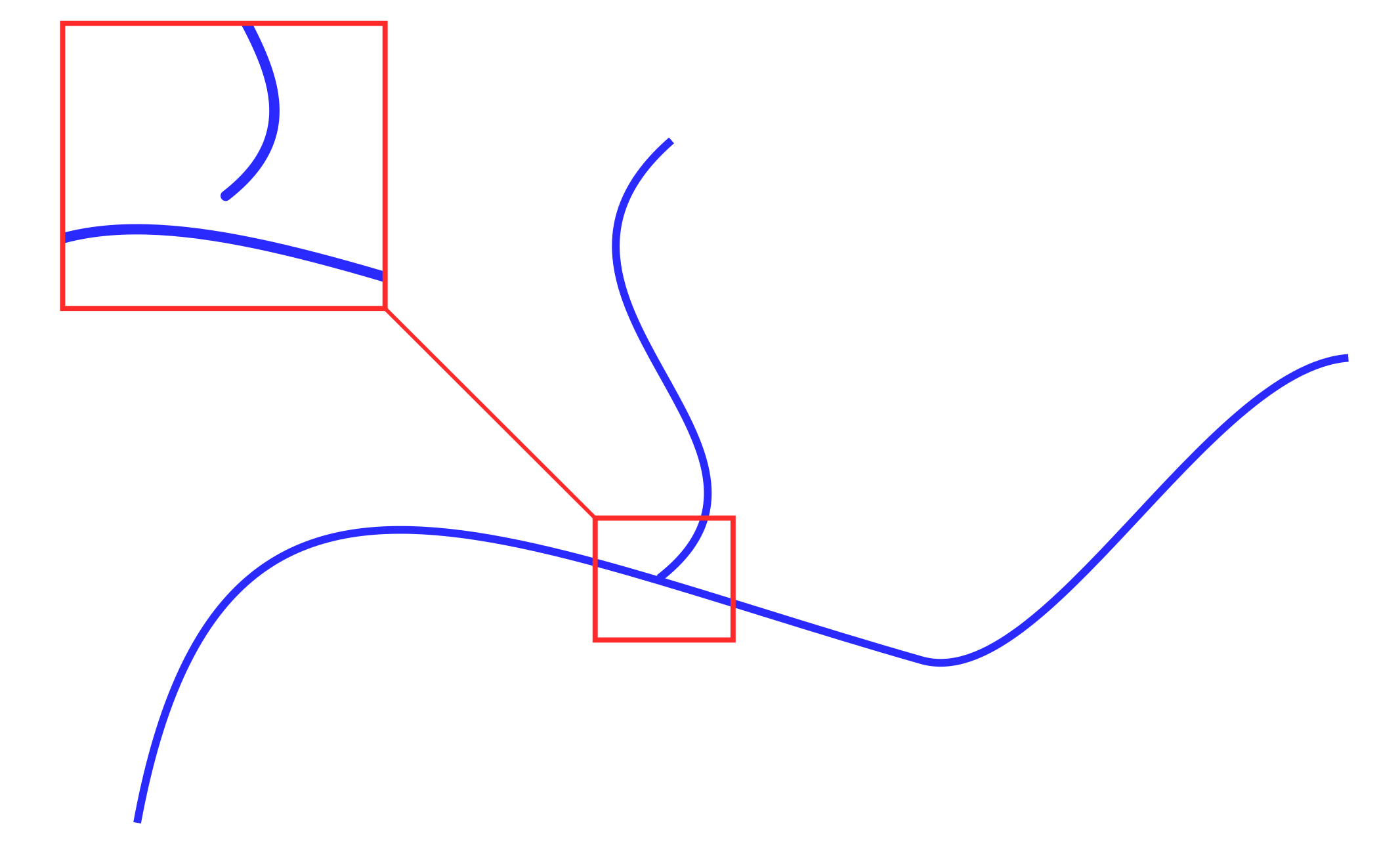
Therefore, the first stage of preprocessing is to correct the topology of objects: “tighten” the nodes, make the original vector layer consistent. To do this, use the tools from the data analysis panel in QGIS — “Fix geometries” (fixgeometries built-in) and v.clean (from the GRASS package).
因此,预处理的第一步是纠正对象的拓扑:“拧紧”节点,使原始矢量层保持一致。 为此,请使用QGIS中数据分析面板中的工具-“修复几何”(内置的固定几何)和v.clean(来自GRASS软件包)。
After the topology is fixed, the layer is divided into segments at the points where the lines have intersections. The result after splitting is illustrated below (Fig. 3).
固定拓扑后,在直线相交的点将图层分为几部分。 拆分后的结果如下图所示(图3)。
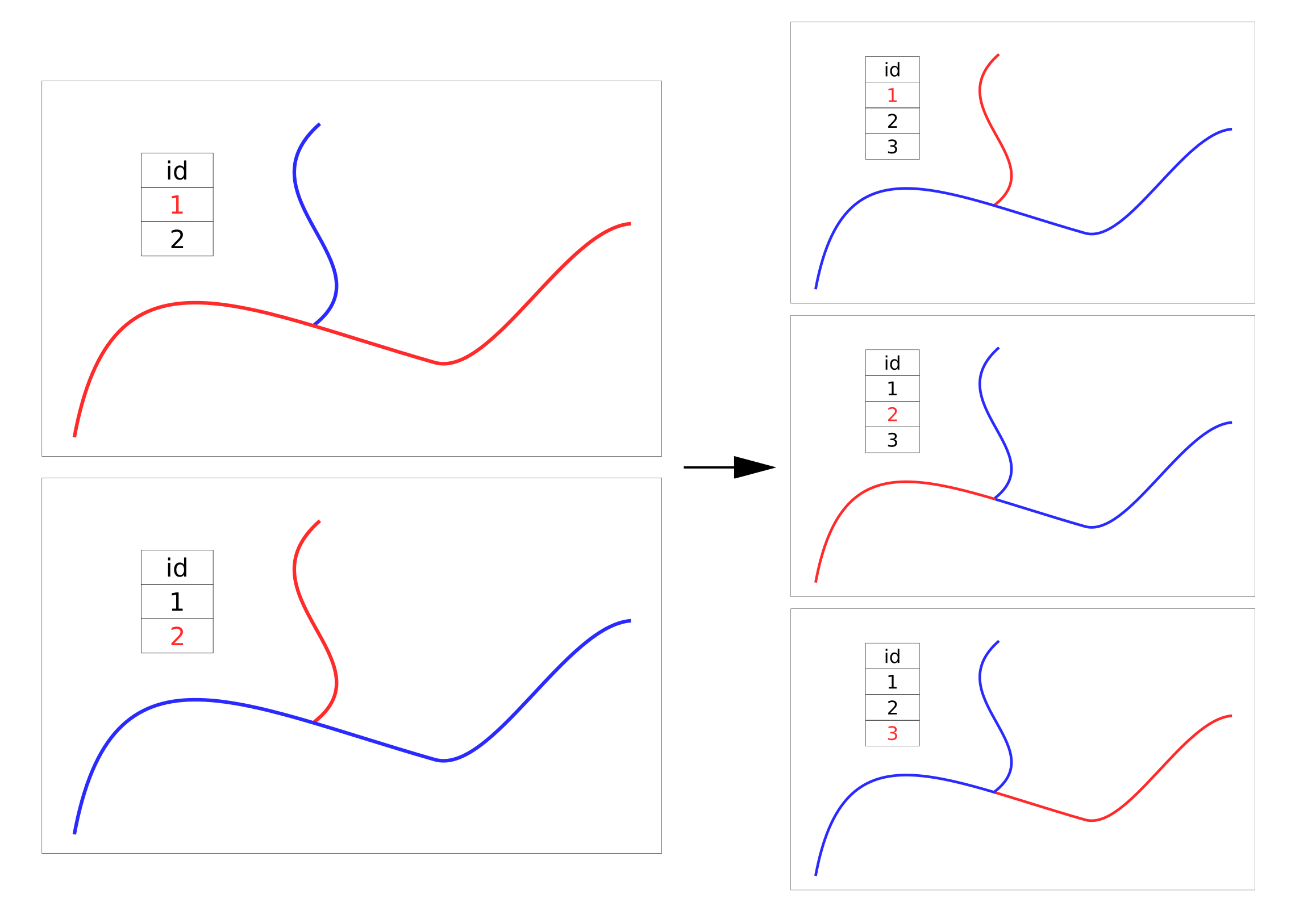
Thus, using the “splitwithlines” tool in QGIS, we divide the source layer into segments.
因此,使用QGIS中的“ splitwithlines”工具,我们将源层划分为多个段。
For each segment, we use QGIS to calculate the length and enter data in the attribute table of the layer (Fig. 4). the segment Length is calculated according to the user settings of the project (Project -> Properties -> General -> Ellipsoid).
对于每个段,我们使用QGIS计算长度并将数据输入到图层的属性表中(图4)。 段长度是根据项目的用户设置(项目->属性->常规->椭圆形)计算的。
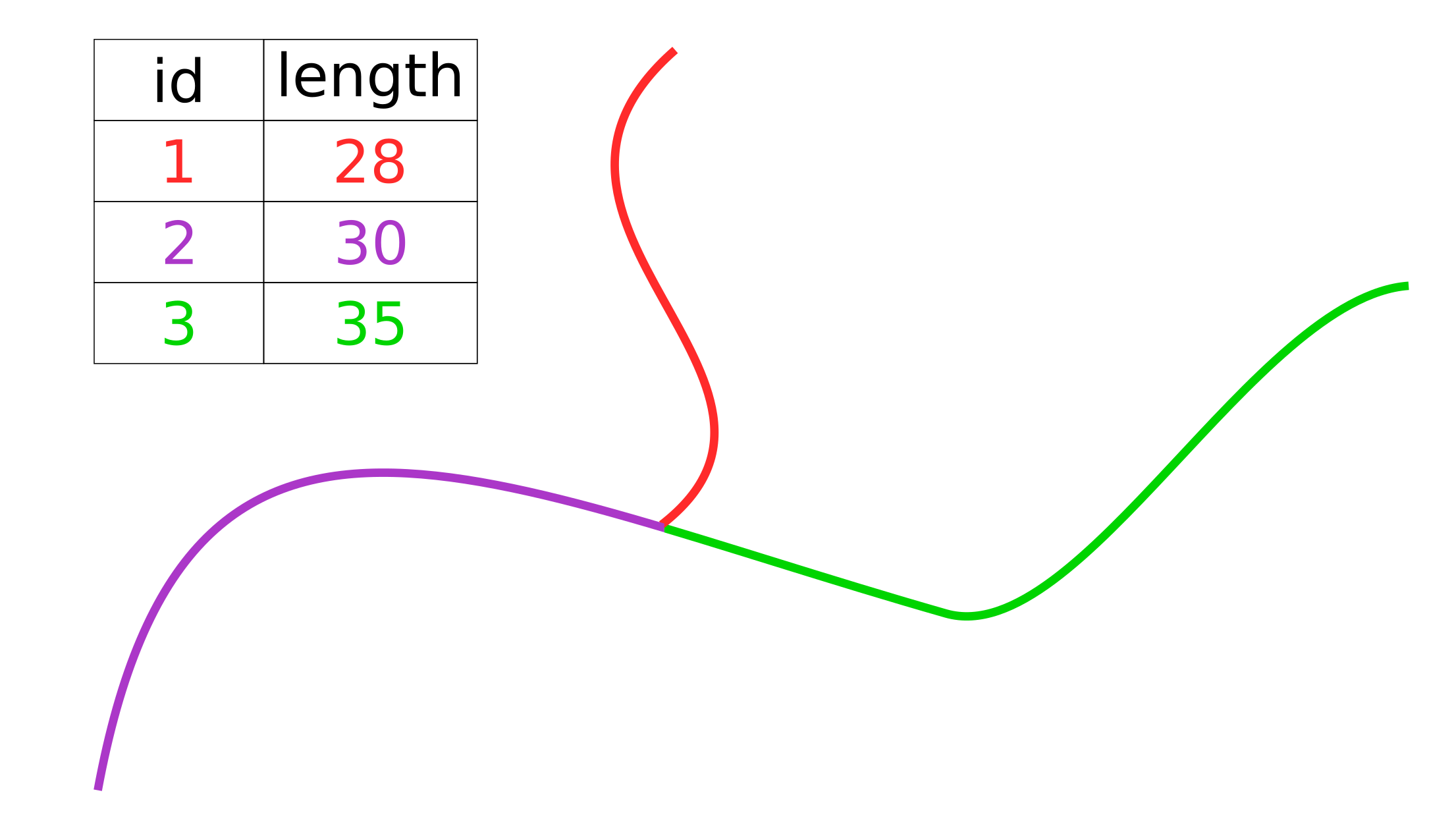
After that, using the “line intersection” tool (built-in tool), we get a point vector layer, where information about segment intersections is set in the attribute table. This attribute table can be interpreted as an adjacency list.
之后,使用“线相交”工具(内置工具),获得一个点矢量层,其中在属性表中设置了有关线段相交的信息。 该属性表可以解释为邻接表。
The preprocessing steps are shown in the following image (Fig. 5).
下图显示了预处理步骤(图5)。
As a result of preprocessing, the graph is formed as a mathematical object of the networkx Python library. Thus, the river segments are vertices in the graph. If the segments are connected to each other (they have intersections), then there are edges between the graph vertices.
预处理的结果是,该图被形成为networkx Python库的数学对象。 因此,河段是图中的顶点。 如果线段彼此连接(它们具有交点),则图顶点之间将存在边。
Algorithm for ranking linear objects
线性物体排序算法
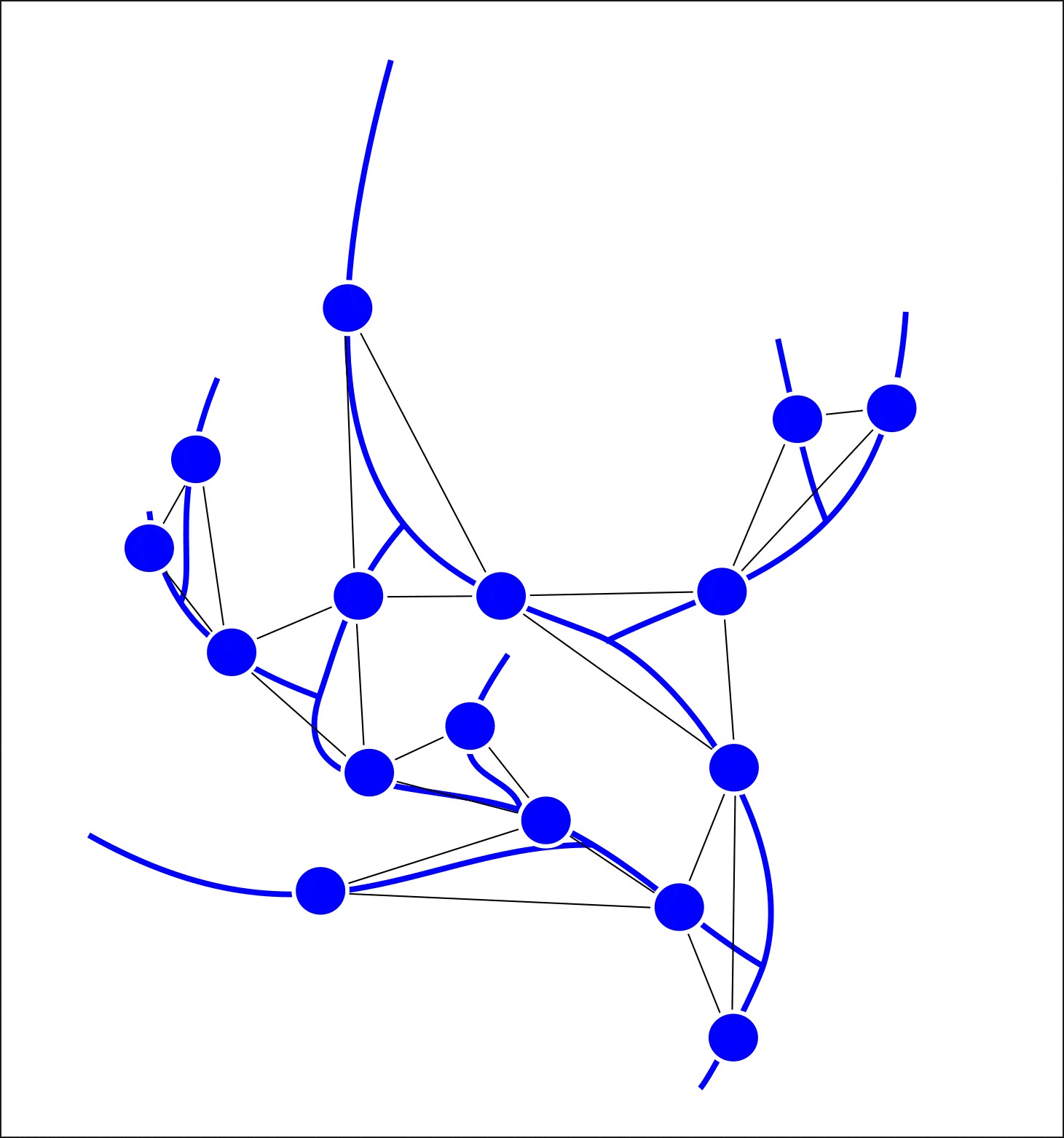
After the graph is formed, we know which vertex to start the search from (the point where it flows from the main river into the lake or sea). Let’s call this vertex the closing one, since all other segments of the river network (vertexes) “flow” into it. We have divided the algorithm into several parts:
形成图后,我们知道从哪个顶点开始搜索(从主要河流流入湖泊或海洋的点)。 我们将此顶点称为闭合顶点,因为河网的所有其他部分(顶点)都“流入”其中。 我们将算法分为几个部分:
- Ranking graph vertexes by distance from the closing segment, assigning the “rank” attribute (a measure of the segment’s distance) and the “offspring” attribute (the number of sections of the river network that flow directly into this segment); 根据与封闭路段的距离对图顶点进行排名,并分配“等级”属性(路段距离的度量)和“后代”属性(直接流入该路段的河网路段数);
- Assigning the “value” attribute for the total number of tributaries flowing into a given section and the “distance” attribute (the distance of the segment’s extreme point from the mouth in meters). 为流入给定路段的支流总数分配“值”属性,并为“距离”属性(路段端点到口的距离,以米为单位)分配。
Both stages are divided into several blocks, but the main idea is a two-stage scheme for assigning attributes.
这两个阶段都分为几个块,但是主要思想是分配属性的两阶段方案。
The assignment of the attributes “rank” and “offspring”
属性“等级”和“后代”的分配
The first stage of graph traversal is to rank vertexes by the degree of distance from the closing one. We planned to carry out the assignment of the attribute “rank” with iterative breadth-first search (BFS). Thus, starting from the closing vertex, we would move further and further away at each step, and at the same time, we would assign an attribute “rank”. But in this case, the following conflict may occur (animation below).
图遍历的第一阶段是按距封闭顶点的距离程度对顶点进行排名。 我们计划使用迭代广度优先搜索(BFS)来分配属性“等级”。 因此,从闭合顶点开始,我们将在每一步上走得越来越远,同时,我们将分配一个属性“等级”。 但是在这种情况下,可能会发生以下冲突(以下动画)。
And what rank should we assign to this segment? There may be other problems with this attribute assignment algorithm, but we have listed one of the most vital.
我们应该给这个细分市场分配什么等级? 此属性分配算法可能还有其他问题,但我们列出了最重要的问题之一。
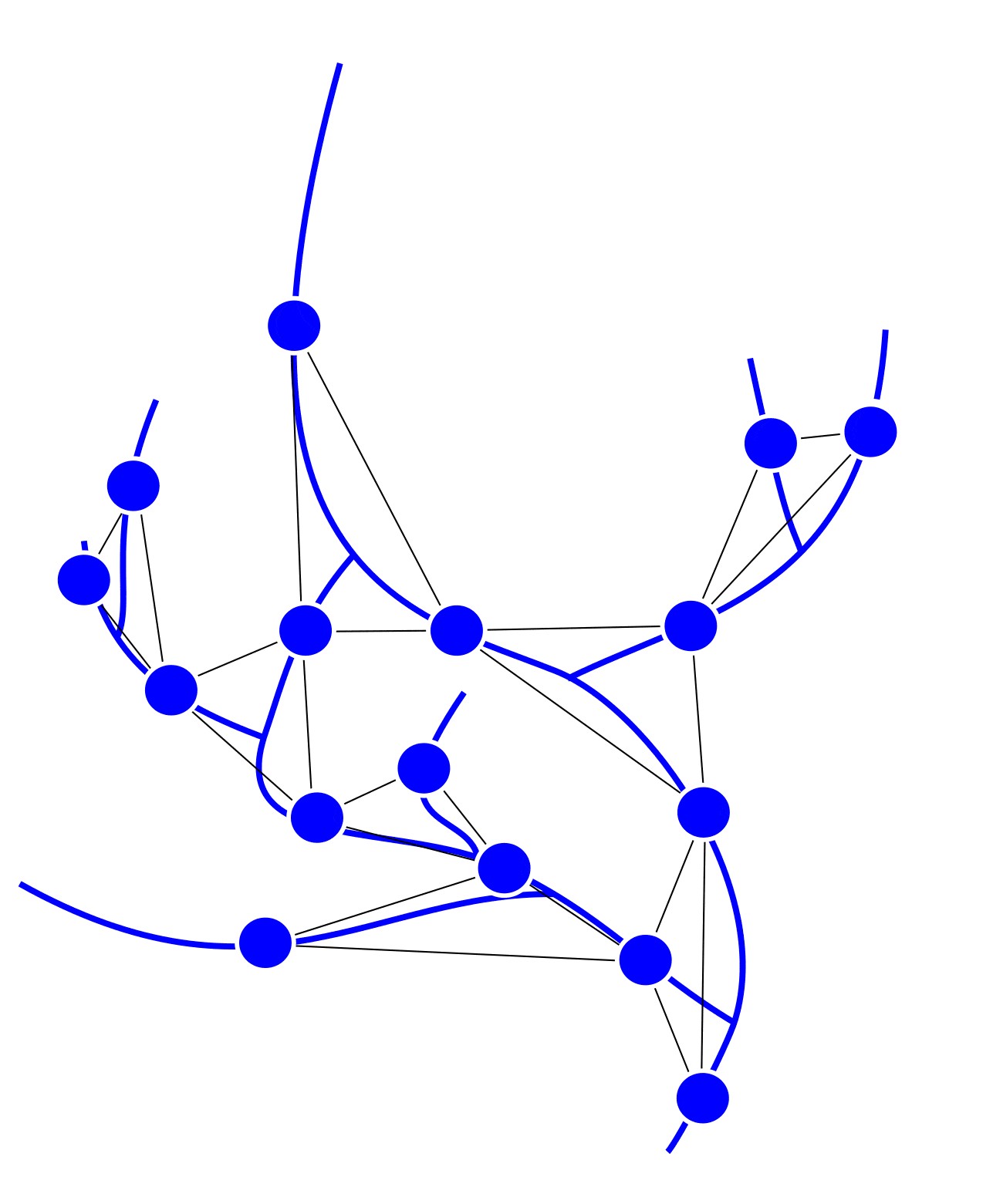
Suggested solution: we can determine the ranks for some part of the river network (the main river), and rank segments based on this information. This approach can be seen on the following picture (Fig. 6).
建议的解决方案:我们可以确定河网某些部分(主要河流)的等级,并根据此信息对路段进行等级划分。 在下面的图片中可以看到这种方法(图6)。
Thus, subgraphs can only join the reference route through 1 edge, and the other edges are excluded.
因此,子图只能通过1条边加入参考路径,而其他边则不包括在内。
This raises the following problem : how can we find such a route? — We will assume that the shortest route between the two most distant vertices in the graph, one of which is the closing one, is the reference route (we will soon add an update so that the user can set this route if they have knowledge of which river is the main one, but in the absence of such information, the reference route is determined by this way). This route can be obtained using the A* (A-star) algorithm, but this algorithm works with a weighted graph, and there are no weights on the edges of our graph yet. But we can set weights for the edges of the graph based on the segment lengths (we calculated them earlier).
这引起了以下问题:我们如何找到这样的路线? —我们将假设图中两个最远顶点之间的最短路径是参考路径(其中一个是闭合顶点)(我们将很快添加一个更新,以便用户在了解以下情况时可以设置此路径)哪条河流是主要河流,但是在没有此类信息的情况下,参考路线是通过这种方式确定的。 可以使用A *(A-star)算法获得此路线,但是该算法适用于加权图,并且图的边缘上还没有权重。 但是我们可以根据段的长度设置图形边缘的权重(我们之前已经对其进行了计算)。
- Assigning weights to the graph edges based on the lengths of segments. Simultaneously with this stage, one component is selected in the graph. The movement of the column is carried out using a breadth-first search. The assignment of weights can be demonstrated by the following figure (Fig. 7) 根据线段的长度为图形边缘分配权重。 在此阶段的同时,图中选择了一个组件。 使用广度优先搜索进行列的移动。 权重的分配可以通过下图(图7)进行演示。
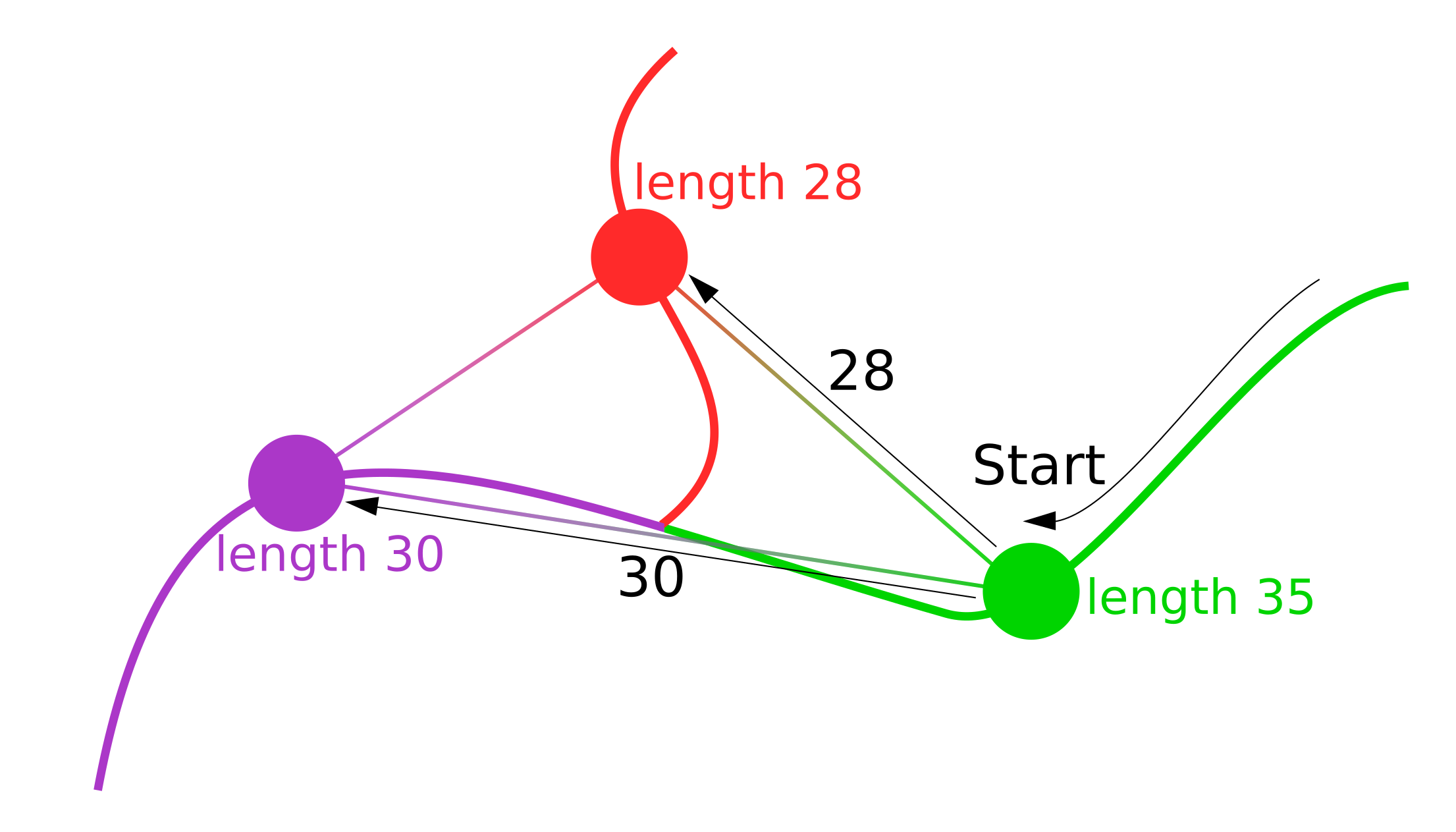
Thus, each vertex of the graph has the “length” attribute, which indicates the length of this segment of the river in meters. We also move attribute values from the graph vertices to the edges iteratively, starting to traverse the graph using BFS from the closing vertex.
因此,图形的每个顶点都具有“长度”属性,该属性指示河流的这一段的长度(以米为单位)。 我们还将属性值从图顶点反复移动到边,开始使用BFS从封闭顶点遍历图。
This task is performed by the following function, where are
此任务由以下功能执行,其中
- G — graph G —图
- start — the vertex from which to start traversal start —从其开始遍历的顶点
- dataframe — pandas dataframe with 2 columns: id_field (segment/vertex ID) and ‘length’ (the length of this segment) 数据框—具有2列的熊猫数据框:id_field(段/顶点ID)和“ length”(此段的长度)
- id_field — the field in the dataframe to use for mapping IDs to graph vertexes id_field —数据框中用于将ID映射到图形顶点的字段
- main_id — index for the main river in the river network (default = None) main_id —河网中主要河流的索引(默认=无)
- A* (A-star) search for the shortest path on a weighted graph between the closing vertex and one of the most distant vertices (a segment in the river network). This shortest route between the two most distant vertices in the graph is called “reference route”; A *(A星)在权重图上的最接近顶点和最远顶点之一(河网中的一段)之间的最短路径上搜索。 图中两个最远顶点之间的最短路径称为“参考路径”;
- Ranking by distance of all vertexes in the reference route. Vertex, from where we start the traversal, the value is assigned rank 1, the next vertex is 2, then — 3, etc. 按参考路径中所有顶点的距离排序。 顶点,从此处开始遍历,将值指定为等级1,下一个顶点为2,然后为3,依此类推。
- Iterative traversal of a graph with the beginning at the vertices of the reference route with isolation of the considered subgraphs. If one of the graph branches already has a connection to the vertices of the reference route, the edges that link the subgraph to other reference vertices are removed. 在参考路径的顶点处开始且没有考虑的子图分离的情况下,迭代遍历图。 如果图形分支之一已经与参考路径的顶点建立了连接,则将子图链接到其他参考顶点的边将被删除。
You can see the source code here
您可以在此处查看源代码
- G — graph G —图
- start — the vertex from which to start traversal start —从其开始遍历的顶点
- last_vertex — one of the farthest vertices from the closing one in the graph last_vertex-距离图中结束点最远的顶点之一
You can see a demonstration of the described algorithm in the animation below.
您可以在下面的动画中看到所描述算法的演示。
Thus, the reference route can be considered as the main river in the river network, when all other segments are tributaries to the main one.
因此,当所有其他路段均是主要路段的支流时,参考路线可被视为河网中的主要河段。
Moreover, this approach allows you to achieve good results when ranking rivers in “difficult” places, such as the mouth, where some branches first depart from the main river, and then, gaining new tributaries, flow into the main river again.
此外,当在“困难”的地方(例如河口)对河流进行排名时,这种方法可以使您获得良好的效果,在这些地方,一些分支首先从主要河流中流出,然后获得新的支流,再次流入主要河流。
Assigning the “value” and “distance” attributes
分配“值”和“距离”属性
So, on the graph, all vertices are assigned the values of the “rank” and “offspring” attributes.
因此,在图形上,所有顶点都被分配了“等级”和“后代”属性的值。
If the vertex has no offspring, it means that no tributaries flow into this segment of the river network. Therefore, this vertex must be assigned the value “value” — 1. Then, for each node that has descendants (the rank of the descendants is always 1 less than the rank of the considering vertex) with the value “value” equal to 1, we need to count the number of descendants. The sum of “value” of all descendants of the considering vertex — the “ value” for considering vertex. Then, this procedure is repeated for other ranks.
如果顶点没有后代,则意味着没有支流流入河网的这一部分。 因此,必须为该顶点分配值“值” -1。然后,对于每个具有后代的节点(后代的等级始终比考虑的顶点的等级小1),其值“值”等于1 ,我们需要计算后代的数量。 考虑顶点的所有后代的“值”之和-考虑顶点的“值”。 然后,对其他等级重复此过程。
Thus, we iteratively move to the closing vertex.
因此,我们迭代地移至封闭顶点。
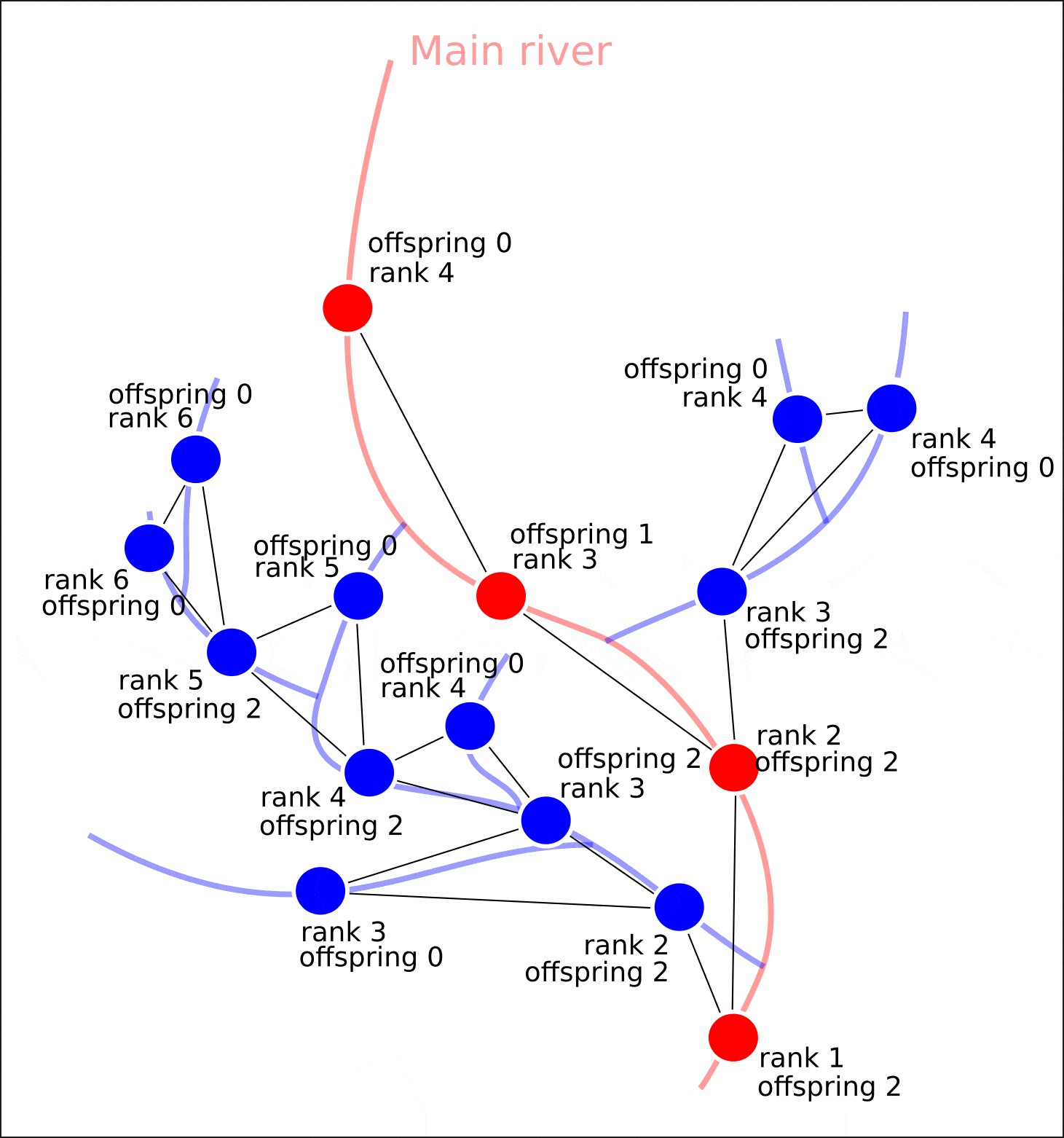
At the same time as assigning the “value” attribute to the graph vertices, the “distance” attribute is assigned, which characterizes the distance of segments from the mouth not by the number of segments that must be overcome to reach the closing one, but by the distance in meters that will need to be overcome to reach the river mouth.
在将“值”属性分配给图形顶点的同时,还分配了“距离”属性,该属性表示段到嘴的距离不是通过达到闭合点必须克服的段数来表征的,而是到达河口需要克服的距离(以米为单位)。
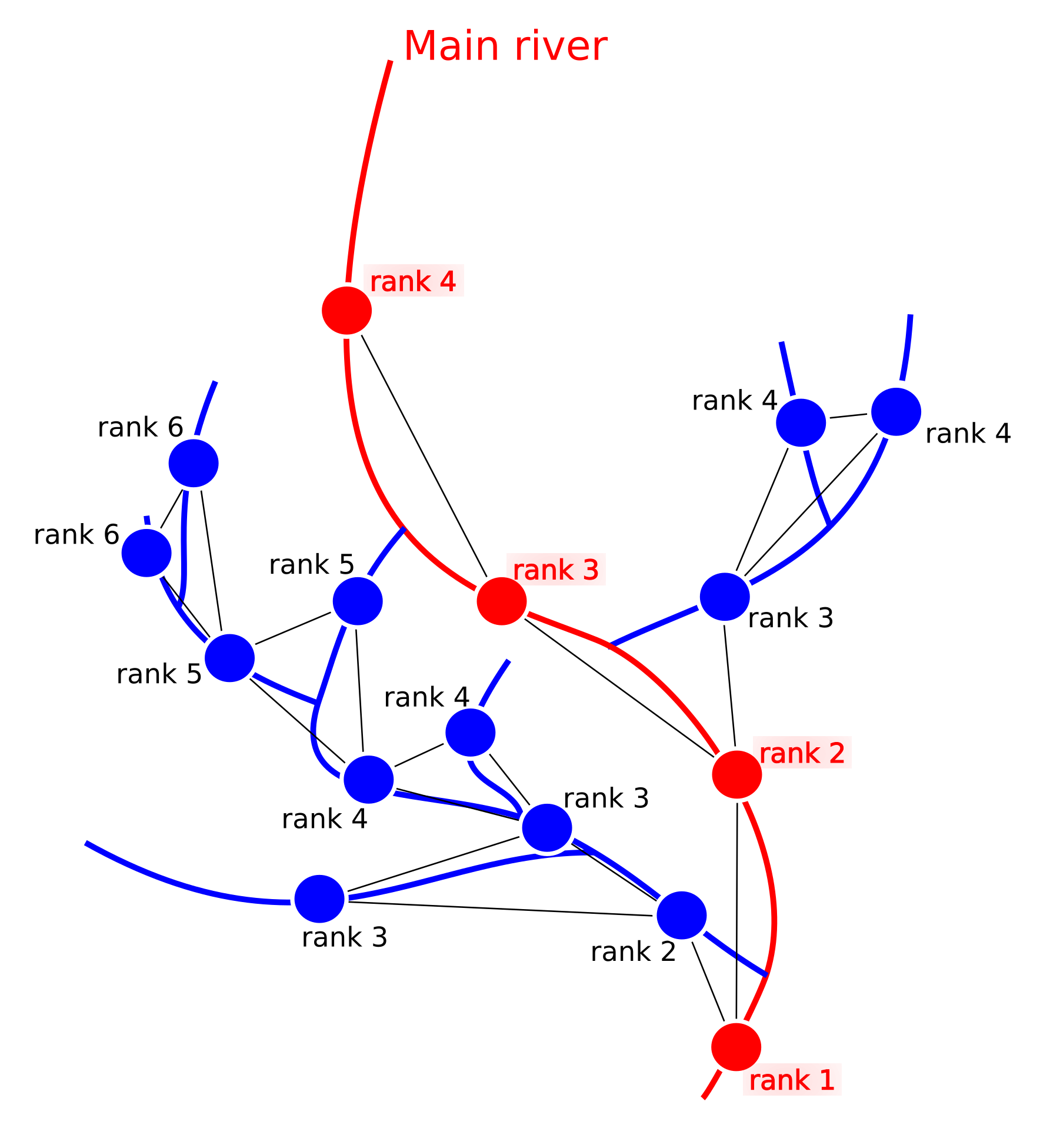
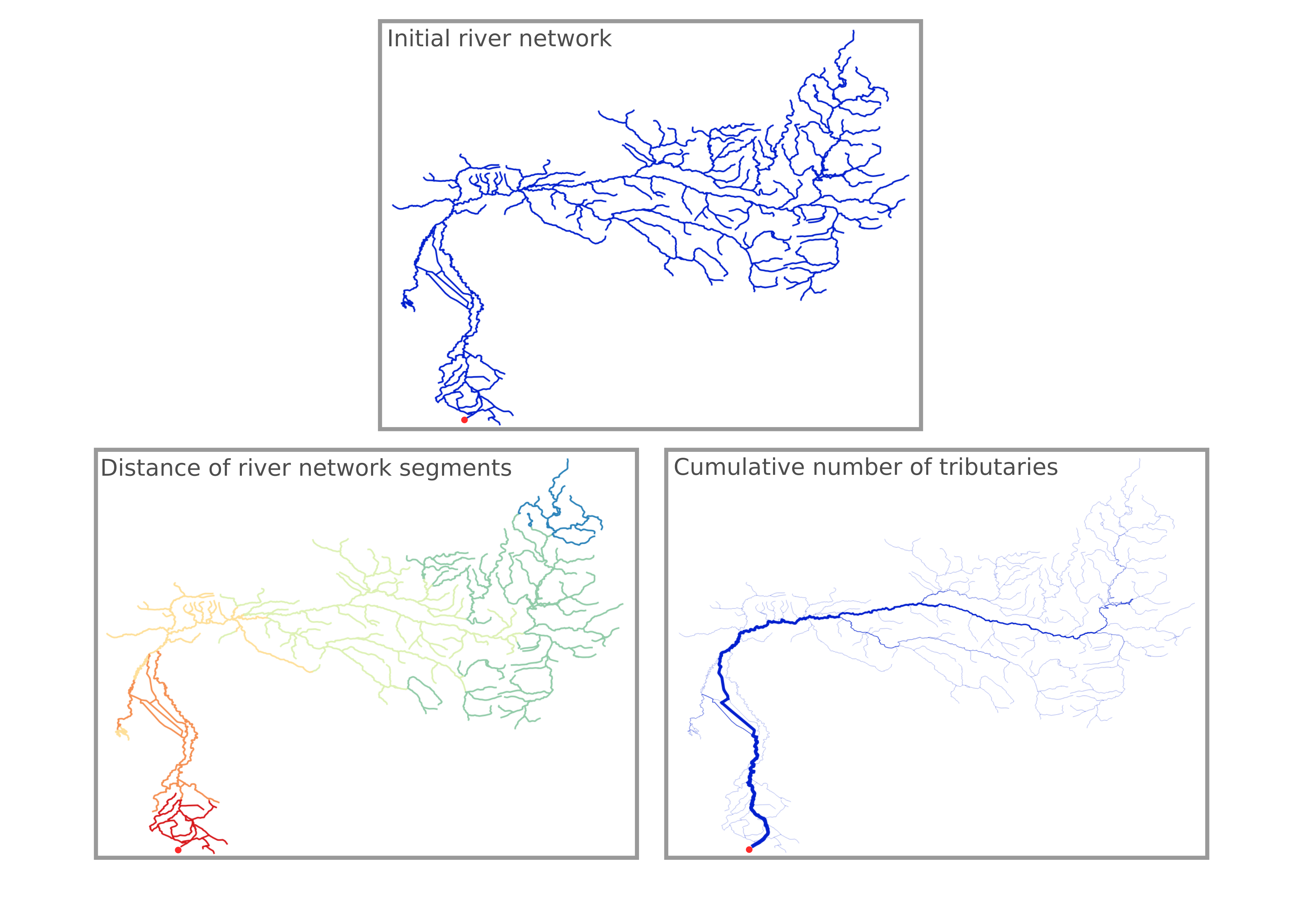
The result of using the algorithm can be seen in figure 8. the Distance of river network segments is shown based on the “rank” attribute and the total number of tributaries is shown based on the “value” attribute.
使用该算法的结果如图8所示。河网段的距离基于“等级”属性显示,支流总数基于“值”属性显示。
结论 (Conclusion)
As you can see, the presented algorithm allows you to rank rivers without using additional information, such as digital elevation model. The obligatory input parameter, except for the main layer of the river network, is the position of the closing segment (where the river flows into the sea or lake), which can be specified as a point.
如您所见,该算法可以让您对河流进行排名,而无需使用其他信息,例如数字高程模型。 除河网的主层外,强制性输入参数是闭合线段的位置(河流流入大海或湖泊的位置),可以指定为一个点。
Thus, with the minimum amount of required input data, it is possible to obtain structured derived information that characterizes the elements of the river basin using the implemented algorithm.
因此,利用最少的所需输入数据量,可以使用所实现的算法来获得表征流域要素的结构化派生信息。
An open implementation of the algorithm in Python, as well as a plugin for QGIS, can be used by anyone. All processing is carried out by one thread, the user does not need to run all the functions separately.
任何人都可以使用Python中算法的开放式实现以及QGIS插件。 所有处理均由一个线程执行,用户无需单独运行所有功能。
We are glad to answer your questions and see your comments.
我们很高兴回答您的问题并查看您的评论。
Repository with the code:
带有代码的存储库:
Feel free to contact us by e-mail:
随时通过电子邮件与我们联系:
水文分析提取河网