这个是hibernate的一对多建表实例:一的一端是部门(Department),对的一端是员工(Employee),下面贴上成员源代码:其中@mappedBy是加在@OneToMany一端,并且它的name属性=多的那一端(N端)属性是一的那一端的属性名,mappedBy是定义在Department类中,即Department类不负责维护级联关系.即维护者是Employee类
Department类:
package com.javabean; import java.io.Serializable; import java.util.Set; import javax.persistence.CascadeType; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.OneToMany; import javax.persistence.Table; @SuppressWarnings("serial") @Entity @Table(name="department") public class Department implements Serializable{ @Id @GeneratedValue(strategy=GenerationType.AUTO) private int id; @Column(name="name") private String name; @OneToMany(mappedBy="depart",cascade=CascadeType.ALL) private Set<Employee> emps; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Set<Employee> getEmps() { return emps; } public void setEmps(Set<Employee> emps) { this.emps = emps; } }
//Employee类:
package com.javabean; import java.io.Serializable; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.JoinColumn; import javax.persistence.ManyToOne; import javax.persistence.Table; @SuppressWarnings("serial") @Entity @Table(name="employee") public class Employee implements Serializable { @Id @GeneratedValue(strategy=GenerationType.AUTO) private int id; @Column(name="name") private String name; @ManyToOne @JoinColumn(name="depart_id") private Department depart; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public Department getDepart() { return depart; } public void setDepart(Department depart) { this.depart = depart; } }
补充知识:
注释的含义学习:
双向一对一映射
class Card{
@OneToOne(optional=false,cascade={CascadeType.MERGE,CascadeType.REMOVE},mappedBy="card",fetch=FetchType.EAGER)
Person getPerson(){}
}
mappedBy 单向关系不需要设置该属性,双向关系必须设置,避免双方都建立外键字段
数据库中1对多的关系,关联关系总是被多方维护的即外键建在多方,我们在单方对象的@OneToMany(mappedby=" ")
把关系的维护交给多方对象的属性去维护关系
对于mappedBy复习下:
cascade 设定级联关系,这种关系是递归调用
可以是CascadeType.PERSIST(级联新建)CascadeType.REMOVE(级联删除)CascadeType.REFRESH(级联刷 新)CascadeType.MERGE(级联更新)CascadeType.ALL(全部级联)
fetch 预加载策略和@Basic差不多FetchType.LAZY,FetchType.EAGER
optional 设置关联实体是否必须存在false必须存在 即不是随意的,true关联实体可以不存在即是随意 的。
比如Card(身份证)中的person(人)optional为false意味有身份证就必须有人对应,但是在实体Person中Card的optional为true意味有人不一定要有身份证。
@JoinColumn(name="cardid",referencedColumnName="cid")设置外键,
name该外键的字段名,referencedColumnName外键对应主表的字段
因为card和person是双向关系而在card端已经mappedBy="card"设定card为主表,
所以要在person端的关联项设置外键@JoinColumn
双向一对多与多对一 ,单向一对多与多对一 @OneToMany @ManyToOne 其它的可以参考上面的
双向多对多(实际开发中多对多通常是双向的)
@JoinTable(
name="teacher_student",
joinColumns={@JoinColumn(name="teacher_id",referencedColumnName="tid")},
inverseJoinColumns={@JoinColumn(name="student_id",referencedColumnName="sid")}
)
old:
hibernate调用seeion的工具类:
HibernateUtils类:
package utils; import org.hibernate.Session; import org.hibernate.SessionFactory; import org.hibernate.cfg.Configuration; public class HibernateUtils { private static SessionFactory factory; static{ try{ Configuration cfg=new Configuration().configure(); factory=cfg.buildSessionFactory(); }catch(Exception e){ e.printStackTrace(); } } public static Session getSession(){ return factory.openSession(); } public static void closeSession(Session session){ if(session!=null){ if(session.isOpen()){ session.close(); } } } public static SessionFactory getSessionFactory(){ return factory; } }
测试类:测试类中,标红的部分是建立两个表的维护关系必须有的(想想为什么?)如果缺少标红的部分,那么在employee数据表中(下文提到的表)中depart_id的值就为null
package test; import java.util.HashSet; import java.util.Set; import com.javabean.Department; import com.javabean.Employee; public class Many2One { public static void main(String[] args) { Many2oneDao mvso=new Many2oneDao(); Employee e1=new Employee(); e1.setName("wanglitao_guodiantong"); Employee e2=new Employee(); e2.setName("wuwenzhao_guodiantong"); Department depart=new Department(); depart.setName("guodiantong_guowang"); e1.setDepart(depart); e2.setDepart(depart); Set<Employee> emps=new HashSet<Employee>(); emps.add(e1); emps.add(e2); depart.setEmps(emps); mvso.saveObject(depart); } }
测试结果:

数据库中的表:
多的那一端的表:(employee)
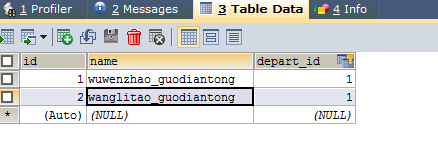
一的那一端的数据表(department表):
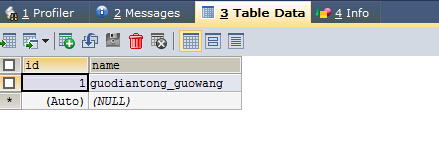
结果说明:在employee的表中,depart_id是关联外键。
另附一篇比较好的一对多建表实例,作为共同参考:
package oneToMany; import java.util.Set; import javax.persistence.*; /* 注意导入时,是导入:import javax.persistence.*; 非导入org.hibernate的相关类:import org.hibernate.annotations.Entity; */ @Entity @Table(name="classes") public class Classes implements Serializable { @Id @GeneratedValue(strategy=GenerationType.AUTO) private int id; private String name; @OneToMany(cascade=CascadeType.ALL,mappedBy="classes") private Set<Student> students; //getter,setter省略 } package oneToMany; import javax.persistence.*; @Entity @Table(name="student") public class Student implements Serializable { @Id @GeneratedValue(strategy=GenerationType.AUTO) private int sid; private String sname; //若有多个cascade,可以是:{CascadeType.PERSIST,CascadeType.MERGE} @ManyToOne(cascade={CascadeType.ALL}) @JoinColumn(name="classid") //student类中对应外键的属性:classid private Classes classes; //getter,setter省略 } public class TestOneToMany { /* CREATE TABLE student ( --要定义外键!!!!!!! `sid` double NOT NULL auto_increment, `classid` double NULL, `sname` varchar(255) NOT NULL, PRIMARY KEY (sid), INDEX par_ind (classid), FOREIGN KEY (classid) REFERENCES classes(id) ON DELETE CASCADE ON UPDATE CASCADE ) ENGINE=InnoDB */ public static void main(String[] args) throws SQLException { try { SessionFactory sf = new AnnotationConfiguration().configure().buildSessionFactory(); Session session=sf.openSession(); Transaction tx=session.beginTransaction(); /* 因为mappedBy是定义在classes中,即classes类不负责维护级联关系.即维护者是student.所以, 1.要将clsses的数据,赋给student,即用student的setClasses()方法去捆定class数据; 2.在进行数据插入/更新session.save()/session.update()时,最后操作的是student. */ Classes classes=new Classes(); classes.setName("access"); Student st1=new Student(); st1.setSname("jason"); st1.setClasses(classes); session.save(st1); Student st2=new Student(); st2.setSname("hwj"); st2.setClasses(classes); session.save(st2); tx.commit(); /* 输出如下: Hibernate: insert into classes (name) values (?) Hibernate: insert into student (classid, sname) values (?, ?) Hibernate: insert into student (classid, sname) values (?, ?) */ /* 因为一端维护关系另一端不维护关系的原因,我们必须注意避免在应用中用不维护关系的类(class)建立关系,因为这样建立的关系是不会在数据库中存储的。 如上的代码倒过来,则插入时,student的外键值为空.如下: */ // Student st1=new Student(); // st1.setSname("jason"); // session.save(st1); // // Student st2=new Student(); // st2.setSname("hwj"); // session.save(st2); // // Set<Student> students=new HashSet<Student>(); // students.add(st1); // students.add(st2); // // Classes classes=new Classes(); // classes.setName("access"); // classes.setStudents(students); // session.save(classes); /* 输出如下: Hibernate: insert into student (classid, sname) values (?, ?) Hibernate: insert into student (classid, sname) values (?, ?) Hibernate: insert into classes (name) values (?) */ } catch(HibernateException e) { e.printStackTrace(); } } }