【论文笔记】QBSUM: 基于查找的文本摘要数据集_query-based summarization-程序员宅基地
技术标签: nlp 深度学习 论文笔记 自然语言处理 神经网络
QBSUM: a Large-Scale Query-Based Document Summarization Dataset from
Real-world Applications
论文下载地址![]() https://arxiv.org/abs/2010.14108v2
https://arxiv.org/abs/2010.14108v2
摘要
基于查询的文档摘要旨在提取或生成直接回答或与搜索查询相关的文档的摘要。这是一项重要的技术,可以有益于各种应用程序,例如搜索引擎、文档级机器阅读理解和聊天机器人。目前,为基于查询的摘要设计的数据集数量不足,现有数据集的规模和质量也有限。此外,据我们所知,没有公开可用的基于中文查询的文档摘要数据集。在本文中,我们提出了 QBSUM,这是一个由 49,000 多个数据样本组成的高质量大规模数据集,用于基于中文查询的文档摘要任务。我们还为该任务提出了多种无监督和有监督的解决方案,并通过离线实验和在线 A/B 测试展示了它们的高速推理和卓越性能。发布 QBSUM 数据集是为了促进该研究领域的未来发展。
引言
基于查询的文档摘要旨在生成给定文档的紧凑和流畅的摘要,该摘要回答或与导致文档的搜索查询相关。提取或生成基于查询的文档摘要是搜索引擎 [37、34]、新闻系统 [20] 和机器阅读理解 [13、4、38] 的一项关键任务。对网页文档进行摘要回答用户查询,有助于用户快速掌握文档的要旨,判断检索到的网页是否相关,从而提高搜索效率。在实际应用中,基于查询的文档摘要也可以作为机器阅读理解的一项重要上游任务,旨在根据文章生成问题的答案。摘要可以被视为证据或支持文本,从中可以进一步找到确切的答案。
现有的文本摘要研究可分为通用文本摘要和基于查询的文本摘要。通用文本摘要生成文档的简明摘要,传达文档 [2]、[21]、[10]、[8] 的总体思想。已经开发了许多不同的数据集,包括 Gigaword [11]、New York Times Corpus [33]、CNN/Daily Mail [14] 和 NEWSROOM [12] 等。相比之下,基于查询的文档摘要必须产生一个查询偏向的结果回答或解释搜索查询,同时仍然与文档内容相关,这是一项更具挑战性的任务。迄今为止为该任务创建的数据集通常规模很小,例如 DUC 2005 [6],或者基于使用网络爬取信息 [25] 的人工规则构建。据我们所知,目前还没有为基于中文查询的文档摘要开发的任何公开可用的数据集。
该数据集由<query,document,summarization>tuples,其中每个查询-文档对的摘要是从文档中提取的文本片段的集合(示例如图 1 所示),由腾讯的五位专业产品经理和一位软件工程师标记。 QBSUM 包含超过 49,000 篇新闻文章的 49,000 多个数据样本,其中查询和文档是根据 QQ 浏览器中真实用户的查询和搜索日志提取的.
除了从现实世界的搜索查询和日志中收集的大规模和高质量数据之外,QBSUM 数据集的创建还考虑了各种质量测量,包括相关性、信息量、丰富性和可读性。首先,所选摘要必须与查询相关以及相应文档的主要焦点。如果查询可以直接翻译成问题,摘要应包含问题的答案(如果适用),或提供有助于回答问题的信息。此外,摘要应传达与查询相关的丰富且非冗余的信息。最后,在简洁的同时,自然语言摘要还必须流利以提高可读性——几个文本片段的简单连接可能并不总是能达到目的。为了解决基于查询的文档摘要的任务,我们设计并实现了三种解决方案:i)基于[30]中定义的相关性的无监督排名模型; ii) 基于一系列特征的无监督排名模型; iii) 基于 BERT [7] 的基于查询的摘要模型。我们在 QBSUM 数据集上评估了不同模型的性能和推理效率,并与多种现有的基于查询的摘要基线方法进行了比较。我们最好的模型实现了 57.4% 的 BLEU-4 分数和 73.6% 的 ROUGE-L 分数,这显着优于基线方法。
基于 QBSUM 数据集,我们训练并部署了基于查询的文档摘要解决方案,并将其部署到 QQ 浏览器和手机 QQ 这两个真实世界的应用程序中,涉及全球超过 2 亿日活跃用户。我们的解决方案目前作为这些商业应用程序中的核心摘要系统,用于根据用户查询提取和呈现简洁且信息丰富的摘要,以提高这些应用程序的搜索效率和效率。此外,我们在 QQ 浏览器移动应用中对超过 1000 万真实用户进行了大规模的在线 A/B 测试。实验结果表明,我们的模型能够通过符合用户查询和注意力的 Web 文档摘要来改进搜索结果。将我们的系统纳入搜索引擎后,点击率 (CTR) 提高了 2.25%。为了促进相关研究和任务的进展,我们开源了 QBSUM 数据集 1,稍后还将发布我们的实验代码。
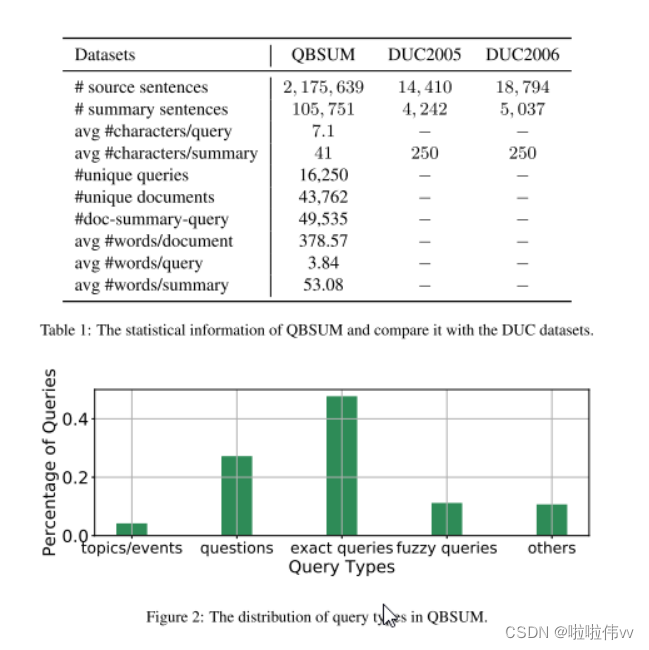
查询和文档管理。我们从最受欢迎的中文新闻网站之一腾讯 QQ 搜索 (http://post.mp.qq.com) 收集数据集中的查询和文档。我们检索了 2019 年 6 月至 2019 年 9 月之间发布的大量查询及其点击率最高的文章。对于每篇文章,我们使用标点符号 [[,?!。] 进行文本分割,并过滤掉少于 15 个文本段的短文章,以及10段以上的长篇文章。检索到的样本涵盖了广泛的主题,例如近期事件、娱乐、经济等。之后,我们对每个查询和文章进行标记,并过滤出文章和查询不具有标记重叠的样本。表 1 提供了关键数据统计数据以及与两个现有的基于查询的摘要数据集的比较。 QUSUM 数据集的词汇量为 103,005。查询、文章和摘要的平均长度(字数)分别为 3.82、378.57 和 53.08。与 DUC2005 和 DUC2006 相比,QBSUM 的规模扩大了两个数量级,涵盖的学科范围更广,满足了基于查询的摘要研究领域对大规模数据集的迫切需求。
摘要注释: 该文档表示为由m个文本片段组成的D,S = {S1,S2,···,Sm}。而一个查询Q是n个查询词q1q2···qn的序列。注释者被要求选择最多 k = 10 个与 Q 最相关并向用户传达有价值信息的文本片段 Si ∈ S。摘要 Y 是通过按照它们在文档中出现的顺序连接选定的文本片段来构建的。
在注释摘要的质量控制方面,我们参考以下四个标准: 相关性:摘要必须在语义上与用户查询相关。它们可能包含查询的关键字。 • 信息量大。摘要应包括对查询的回答,并提供有价值的信息或解释,如果此类信息在文件中可用。据说,它应该减少用户对查询的不确定性。 • 丰富。摘要应包含与查询相关的多样化和非冗余信息。 • 可读性。摘要应保持一致,以使实际用户具有良好的可读性。
对于每个文本片段,我们通过 TextRank [22] 估计其重要性,并指出它是否在查询中包含至少一个内容词。注释的详细过程介绍如下:
2、检查与Q内容词相同的文本,并阅读它们所属的上下文句子。找出与问题最相关和最重要的文本。
3.、如果文档中选定的文本片段不一致或不流畅,请决定是否将其展开以包括相邻的文本片段。如果相邻块有助于提高摘要Y的可读性,并包含与Q相关的非冗余信息,则会选择相邻块。每个选定的文本块Si将扩展为不超过3个相邻块。Y中的文本条总数不得超过k,最大字数设置为70。
DUC 2005 和 2006 任务是以问题为中心的总结任务,专注于总结和整合从多个文档中提取的信息以回答问题。
• 热门话题/事件。这种类型的查询侧重于最近的热门话题或事件。相应的摘要主要是对事件发展、地点、相关实体、时间等方面的描述。 • 问题。此类别涵盖用户问题,例如“GMAT 570 分推荐哪些大学”。摘要是问题的答案或证据句。 • 精确查询。这样的查询是关于一些具体的概念或实体的,比如“深圳100平方米以下的乡间别墅”。摘要包含与查询相关的有用信息。 • 模糊查询。这类查询包括模糊或主观的概念或问题,例如“十大省油汽车”。相应的摘要提供相关实体的信息或对查询的明确回答。 • 不清楚/不完整的查询。对于这种类型,用户可能不清楚如何表达他们的意图。因此,摘要不能对查询给出具体答案。
3 方法
我们开发了三种基于查询的文档摘要模型,包括两种快速无监督方法和一种基于预训练BERT的高性能有监督模型[7]。
直观地说,在基于查询的摘要中,如果摘要能够有效地了解查询所关注的领域,那么它对用户来说是有利可图的。在形式上,相关性衡量摘要Y的分布与所请求的知识域(即查询Q)之间的信息损失,通过交叉熵CE(Y,Q)定义的:
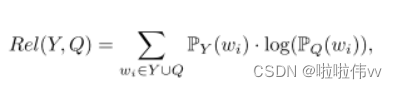
2.Ranking with Dual Attention 双重注意力排名
图 4 展示了我们的在线无监督摘要模型的架构。我们首先使用预训练的词嵌入获取查询和文档的表示。我们通过它包含的查询词的嵌入向量集合来表示查询。文档表示由其文本片段形成,其中每个文本片段的嵌入向量是通过取其词向量的平均值来计算的。然后,我们的模型利用派生的表示来计算关于样本不同维度的各种特征分数。图 4 所示的主要特征包括:
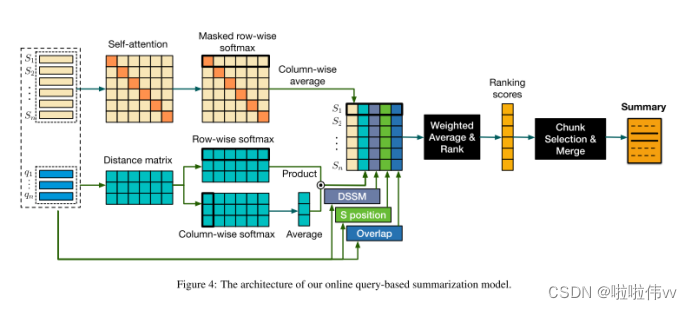
S-D self-attention. 此功能通过与文档中其他剩余的文本片段交互并计算S的自我注意分数,衡量每个文本片段与D的重要性, 我们遵循[35]计算注意力得分。摘要应披露文件的重要信息。
S-Q co-attention S-Q 共同关注。该特征通过计算 Q 与其自身之间的共同注意力分数来衡量每个句子 S ∈ S 与 Q 的相关性。我们假设摘要应该与查询高度相关。
S-Q semantic matching (DSSM).该特征通过深层结构语义匹配(DSSM)模型衡量S和Q之间的语义相关性【16】。DSSM模型是在搜狗搜索引擎的2亿个查询标题对的成对设置中进行训练的,其中我们使用前1个点击文档的查询和标题作为正示例,并从查询标题对的随机组合中进行采样以构建负示例。
S position.它表示S在D中的顺序。我们对序列号应用最小-最大归一化来计算位置分数S-Q重叠。
S-Q overlap.它在单词级别上度量S和Q之间的重叠,并通过no /n进行估计,其中no是S中重叠查询字符的数量,n是查询字符的总数。
在我们的实现中,我们使用不同的权重来组合上述特征分数,其中权重被调整为超参数,并导出一个无监督模型,该模型对属于输出摘要Y的每个S的分数进行排序。还可以通过简单的逻辑回归学习特征权重,从而得到一个有监督的模型。
接下来,我们扩展并组合排序的文本片段以提取基于查询的摘要Y。算法1给出了提取属于Y的文本片段的详细步骤。
我们迭代每个候选文本段Spi,并通过其前面和后面的文本段(如果可用)对其进行扩展,以获得Cpi。我们估计Cpi的冗余度,通过Cpi和Spi之间重叠的bi-grams 的比率。如果冗余度达到或超过某个阈值(我们使用0.5),我们将丢弃Cpi。否则,Cpi将作为Y的一部分追加。我们重复此步骤,直到Y的长度(字数)大于阈值(我们使用70)。

大规模的预训练模型(如BERT[7])极大地提高了NLP任务的性能。我们提出了一个简单的基于BERT的模型,其中预训练的BERT参数为110M,作为编码器,并执行S-Q文本对分类,以确定每个文本块S是否属于摘要Y。
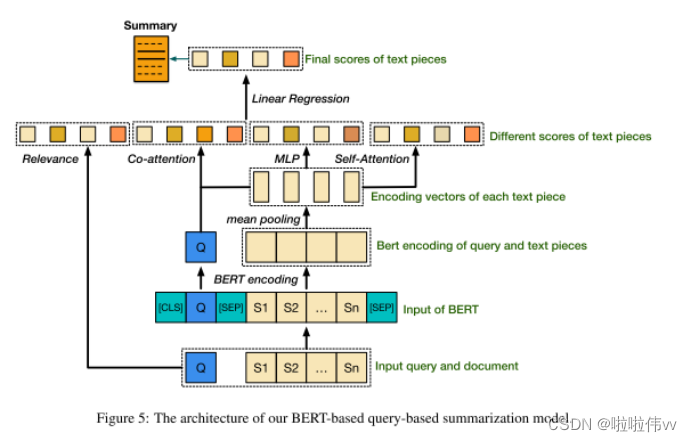
为了区分 BERT 输入中的查询和文档,我们在输入的开头使用 [CLS] 标记,然后是查询标记,然后是 [SEP] 标记,然后是文档标记,以及另一个 [SEP] ] 标记附加在文档的末尾。输入的每个令牌由其令牌嵌入、段嵌入和位置嵌入的总和表示,并被馈送到 BERT 模型以获得其编码的 BERT 表示。 BERT 中采用的自注意力机制允许学习文档或查询中任意两个标记之间的相关性。因此,查询信息也被传送到文档表示。
然后,采用均值池化层,通过取文本片段中所有标记向量的平均值来收集文档中每个文本片段的句子向量表示。此外,在派生的 BERT 句子表示之上,添加了一个转换器层来模拟文档中文本片段之间的相关性并产生文档感知的句子表示,然后通过线性投影层将这些表示转换为标量分数。
受第 3.1 节中的 Rel-QY 和第 3.2 节中的 Rank-DualAttn 的启发,我们在 BERT 预测之外添加了几个模块,包括:i)一个相关性模块,它使用 eq.1 计算给定文本片段与查询之间的相关性; ii) 一个 S-D 自注意力模块,用于测量每个文本片段对文档的重要性,注意我们使用派生的 BERT 表示而不是 Rank-DualAttn 中的预训练词向量; iii) 一个 S-Q 共同注意模块,它计算查询和具有 BERT 表示的文本片段之间的共同注意分数。然后将计算的分数与 BERT 预测分数连接在一起,以进行最终预测,以确定文本片段是否属于输出摘要。
4 实验
三种基线方法:Textrank-DNN, tfidf-DNN, and MDL [19].
Query-based summarization using mdl principle. 2017
在 Textrank-DNN 和 tfidf-DNN 中,从文档创建无向图,其中节点是文本片段的语义嵌入,边是与查询的余弦相似度。不同之处在于 Textrank-DNN 使用 Textrank 算法 [22] 来计算在 tfidf-DNN 中使用 tf-idf 算法的节点的权重。 MDL 首先选择与给定查询相关的频繁词集,然后通过选择最能覆盖这些集的句子来提取摘要。对于我们的 Bert-QUSUM 模型,我们进行消融分析以研究我们提出的模型的不同模块的有效性并评估以下版本:
• Bert-QBSUM(无相关性)。在这个变体中,我们保留了双注意力模块和转换器句子编码器,并删除了相关模块。
• Bert-QBSUM (no co-attention)
• Bert-QBSUM(无变压器编码器)。 Transformer 句子编码器被移除,因此均值池层的输出用作文本片段的表示,以产生 BERT 预测分数。
我们使用ROUGE和BLEU来评估模型性能。ROUGE【18】通过计算重叠单元的数量,将摘要与参考摘要进行比较,从而衡量摘要的质量。在我们的实验中,基于最长公共子序列(LCS)统计,我们使用n=1、2的n-gram回忆ROUGE-n和ROUGE-L。BLEU【27】通过预测句中的n-gram文本在语料库水平上出现在参考句中的程度来衡量准确性。BLEU-1、BLEU-2、BLEU-3和BLEU-4分别使用1-gram到4-gram进行计算。
对于我们的实验,我们利用了 QBSUM 数据集的一部分,其中包含大约 10,000 个数据样本,因为其余数据是在进行实验后收集的。数据集分为训练集、评估集和测试集,分别由 8787、1099 和 1098 个样本组成。所有性能都在测试集上报告。在我们的无监督模型和基线模型的实现中,我们使用了一个 200 维的中文词嵌入,使用 w2v [23] 对 20 亿个查询进行了训练。生成摘要的最大长度设置为 70 个中文单词。
通过观察结果,我们可以看到,Bert-QBSUM 模型在所有性能指标上都获得了最好的性能,如表 2 所示,与之前的模型相比,获得了巨大的性能提升。我们的 Bert-QBSUM 模型的成功可以归功于 BERT 强大的编码能力以及我们模型中不同特征模块的组合。通过仔细检查 QB-SUM 的不同变体的性能,我们可以看到,当去除 co-attention 和相关性时,性能显着下降,由此我们可以得出结论,对每个文本片段和查询之间的相关性进行建模起到了在基于查询的摘要中起着至关重要的作用。Transformer编码器和自注意力模块也有利于模型性能,因为它们能够在句子级别对文档中的文本片段之间的相关性进行建模,而 BERT 仅对令牌级别的信息进行建模。
然而,Bert-QBSUM 的推理速度比其他方法相当慢,因为它的模型参数很多。基于相关性的摘要模型变体实现了最佳的推理速度,因为它们是无监督的方法,并且在推理过程中需要较少的计算。作为推理速度和性能之间的权衡,我们的在线 Rank-DualAttn 模型在可接受的推理时间内实现了更好的性能,使其成为最适合实际应用的模型。
错误的主要原因是查询语句和文档语句之间的语义相关性估计不准确。作为补充,该模型更强调低级特征,例如关键字重叠或文本相似性。
我们的分析表明,精确查询类型经常发生低相关性错误,而问题类型查询最常出现不完整信息错误。
相关工作
文档摘要方法可以分为抽取式摘要,即通过不加修饰地提取关键词和短语来概括文档,以及生成新句子以形成摘要的抽象摘要。
通用抽取式摘要的工作涉及多种方法:最大边际相关性 (MMR) [2] 是一种广为人知的贪心方法。 [21] [10] 将此问题表述为整数线性规划问题。由于能够构建句子关系 [8] [28] [29],基于图的模型在该领域也发挥着主导作用。最近,强化学习方法已被应用[24]。例如,[24] 将提取摘要概念化为句子排序任务,并通过 RL 目标优化 ROUGE。
【10】A scalable global model for summarization. 2009
【21】A study of global inference algorithms in multi-document summarization. 2007
【8】Lexrank: Graph-based lexical centrality as salience in text summarization. 2004
【28】Topical coherence for graph-based extractive summarization. 2015
【29】Integrating importance, non-redundancy and coherence in graph-based extractive summarization. 2015
【24】Ranking sentences for extractive summarization with reinforcement learning. 2018
许多基于查询的摘要器是通用摘要方法的启发式扩展,通过合并给定查询的信息。定义了多种查询相关特征来衡量相关性,包括 TF-IDF 余弦相似度 [36]、WordNet 相似度 [26] 和单词共现 [31] 等。 [1] 提出了一个联合注意力模型 AttSum 来满足查询需求并计算句子权重。
总结
在这项工作中,我们引入了一个新的基于查询的中文摘要数据集,称为 QBSUM,据我们所知,它是基于查询的摘要中的第一个大规模高质量数据集。 QBSUM 包含从实际应用中收集的超过 49,000 个数据样本,其规模比 DUC2005 和 DUC2006 等现有数据集大两个数量级。 QBSUM 数据集已发布,我们希望该数据集能够促进该研究领域的未来发展。此外,我们提出了几个有监督和无监督的模型,它们结合了查询和文档的不同属性,包括相关性、信息性和重要性。在我们的 QBSUM 数据集上的实验表明,我们的方法超越了其他基线。未来,我们计划进一步研究查询、文档和摘要之间的交互,并在 QBSUM 数据集上开发抽象方法。
智能推荐
pheatmap:绘制聚类热图的函数_pheatmap基于kmeans绘制热图-程序员宅基地
文章浏览阅读342次,点赞4次,收藏6次。该函数还允许使用 kmeans 聚类聚合行。如果行数太大,以至于 R 无法再处理其分层聚类,大约超过 1000 行,则建议这样做。与其单独显示所有行,不如提前对行进行聚类,并仅显示聚类中心。可以通过参数kmeans_k调整集群的数量。来源:https://www.rdocumentation.org/packages/pheatmap/versions/1.0.12/topics/pheatmap。一个绘制聚类热图的函数,可以更好地控制一些图形参数,如单元大小等。Examples 例子。_pheatmap基于kmeans绘制热图
html div四边阴影效果-程序员宅基地
文章浏览阅读369次。<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml..._div四周阴影效果
Java 通过反射获取实体类对应的注释_java获取实体类属性注解-程序员宅基地
文章浏览阅读1.7k次。Java 通过反射获取实体类对应的注释 _java获取实体类属性注解
在使用Mybatis的association属性,两张表中存在相同字段名,联表查询时的冲突解决办法_mybatis association绑定相同对象-程序员宅基地
文章浏览阅读2.3k次,点赞5次,收藏10次。在使用MyBatis进行多表联查时,想要获取关联外键的表的数据信息,使用association进行联查,但当外键表的字段名和主表相同时,外键表的数据就会被覆盖。_mybatis association绑定相同对象
湘潭大学2018年上学期程序设计实践模拟考试3 参考题解_在湘大xx奶茶店夏天推出了新的饮料价格为5元。 很多学生都要买饮料,每个学生-程序员宅基地
文章浏览阅读2.7k次。体验1: 军神太强啦,1小时屯6题,瞬间AK,接下来的90分钟一直在跟榜体验2: A题原题,循环写得好就不麻烦,不然要写很多行,情况要想全并不难。 B题原题,有了上一场的提示之后,这题就不难了。 C题很简单(小声)。 D题卡掉了O(T*N*K*log(N))的方法,卡掉我5发logN ,不过还是可做。 E题水dp(组合数学)。 F题原题,记忆化搜索。体验3: 被DC两题卡到..._在湘大xx奶茶店夏天推出了新的饮料价格为5元。 很多学生都要买饮料,每个学生
微信小程序预览pdf,页面缓存下载过的pdf_微信浏览器请求pdf文件会缓存吗-程序员宅基地
文章浏览阅读2.8k次。需求: 点击预览图标查看该pdf报告问题: 1、最早是直接将请求倒的url放入到<web-view src="{{realUrl}}"></web-view>中展示,ios可以,安卓显示无法查看。 2、通过微信自身的API实现:wx.downloadFile({})、wx.saveFile({})、wx.openDocument({}) 3、对于文件较大的,下载较慢,需要点击过的进行缓存,再次点击无需下载,直接打开。 将点击过的下载的url添加给list的tem_微信浏览器请求pdf文件会缓存吗
随便推点
服务部署之配置网络策略服务(NPS)(基于Windows Server 2022)_windows server 部署网络策略服务-程序员宅基地
文章浏览阅读680次。服务部署之配置网络策略服务(NPS)(基于Windows Server 2022)_windows server 部署网络策略服务
视频异常检测 综述(二)_视频异常检测综述-程序员宅基地
文章浏览阅读4.8k次,点赞6次,收藏29次。基于距离、概率、重构的视频异常检测概述_视频异常检测综述
trajan割点模板-程序员宅基地
文章浏览阅读107次。洛谷P3388#include<bits/stdc++.h>using namespace std;typedef long long ll;typedef unsigned long long ull;const int N=2e4+5;const int mod=1e9+7;vector<int> g[N];set<int> v;int dfn[N],low[N],fa[N];int n,m,tot;void tarjan(int x){
linux如何关闭硬件加速,启用硬件加速是什么意思?如何关闭【详解】-程序员宅基地
文章浏览阅读1k次。导语:小编相信,经常会使用到电脑的朋友们,对于启用硬件加速这个词一定都是不陌生的吧!可是呢,对于一些电脑小白们来说,往往会搞不清楚,这个启用硬件加速到底是个什么意思呢?启用之后,我们的电脑又会发生什么变化呢?也有一些人,在启用之后,却不知道应该如何关闭这个硬件加速,接下来,小编就来为大家介绍一下启用硬件加速是什么意思,以及它应该如何关闭。启用硬件加速是什么意思?简而言之,硬件加速就是利用硬件模块来..._linux 禁用硬件加速合成、图层和素材面板
SHAP: 在我眼里,没有黑箱_python对shap的计算只能针对大数值吗-程序员宅基地
文章浏览阅读8.1k次,点赞13次,收藏191次。1. 写在前面很多高级的机器学习模型(xgboost, lgb, cat)和神经网络模型, 它们相对于普通线性模型在进行预测时往往有更好的精度,但是同时也失去了线性模型的可解释性, 所以这些模型也往往看作是黑箱模型, 在2017年,Lundberg和Lee的论文提出了SHAP值这一广泛适用的方法用来解释各种模型(分类以及回归), 使得前面的黑箱模型变得可解释了,这篇文章主要整理一下SHAP的使用, 这个在特征选择的时候特别好用。这次整理, 主要是在xgboost和lgb等树模型上的使用方式, 并且用一个_python对shap的计算只能针对大数值吗
【操作系统】考研真题攻克与重点知识点剖析 - 第 1 篇:操作系统概述_2021-程序员宅基地
文章浏览阅读625次。这篇文章深入探讨了操作系统的各个方面,以及相关的计算机科学概念。文章的结构包括对操作系统的定义和功能的讨论,涵盖了硬件管理、操作系统特征、启动过程、运行环境等多个方面。作者使用思维导图和具体版本(如哈工大版本、王道版本)作为辅助,系统性地介绍了操作系统的运行机制,包括中断与异常、系统调用等内容。文章还回顾了操作系统的历史发展,按照不同线索(如哈工大版本)进行叙述,涵盖了操作系统的发展与分类、体系结构等方面。最后,文章提到了一些考研真题,强调了对计算机科学相关概念的深入理解。_2021