Flink项目搭建与使用_建立一个flink项目-程序员宅基地
Flink项目搭建与使用
前言
本文不会介绍flink的概念与原理,如果对于Flink还不了解,先去看看flink的基础知识吧!
本文使用Java演示,Scala…我不会,这里不再展示。
这里提供几个地址:Flink官方文档 、个人感觉比较好的博客
环境准备
环境依赖
- JDK 1.8 及以上
- Maven 3.0.4 及以上
Flink基础依赖库
<properties>
<flink.version>1.10.1</flink.version>
</properties>
<dependencies>
<!--批量计算DataSet API-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!--流式计算DataStream API-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
除了上述的Flink项目中必须依赖的基础库之外,如果还要添加其他依赖,例如Flink中内建的Connector,或者其他第三方依赖库,需要在项目中添加相应的Maven Dependences,并将这些Dependence的Scope配置成compile。
如果需要引入Hadoop相关依赖包,需要将Scope注明为provided,应为Flink集群已经将Hadoop依赖包添加在集群环境中(如下图所示),否则容易造成Jar包冲突。
Flink程序结构
DataStream API 主要可分为三个部分:DataSource模块、Transformation模块、DataSink模块。
官网提供的Flink 程序与数据流结构图如下:
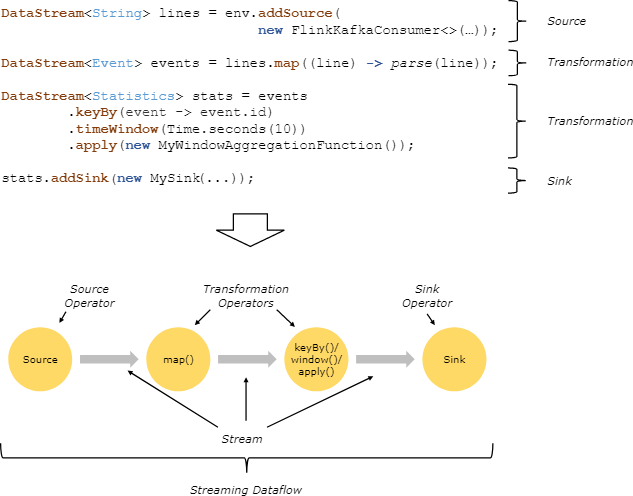
Flink程序一般分为5步,分别为: 设定Flink执行环境、创建和加载数据集、对数据集指定转换操作逻辑、指定计算结果的输出文职、调用execute方法触发程序执行。
批处理代码示例如下
// 批处理word count
public class WordCount {
public static void main(String[] args) throws Exception {
// 第一步:创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 第二步:指定数据源地址,读取输入数据,这里读取本地文件的文本数据
DataSet<String> inputDataSet = env.readTextFile("D:\\project\\flinkLearn\\src\\main\\resources\\hello.txt");
// 第三步:对数据集指定转换操作逻辑, 按照空格分词展开转换成(word, 1)二元组进行统计
DataSet<Tuple2<String, Integer>> resultSet = inputDataSet.flatMap(new MyFlatMapper())
.groupBy(0) // 按照第一个位置的word分组
.sum(1); // 将第二个位置上的数据求和
// 第四步:指定就按结果输出位置,这里只做标准输出
resultSet.print();
// 批处理情况下print不需要execute
// env.execute("Streaming WordCount");
}
// 自定义类,实现FlatMapFunction接口
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 按空格分词
String[] words = value.split(" ");
// 便利所有words包成二元组输出
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
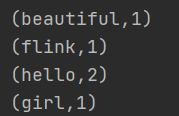
hello.txt:
hello beautiful girl
hello flink
结果如下:
流处理代码示例如下
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 第一步:创建流处理执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 用flink自带的parameter tool 工具从程序启动参数中提取配置项
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 第二步:指定数据源地址,读取输入数据,这里从socket文本流读取数据
DataStreamSource<String> inputDataStream = env.socketTextStream(hostname, port);
// 第三步:对数据集指定转换操作逻辑, 按照空格分词展开转换成(word, 1)二元组进行统计
SingleOutputStreamOperator<Tuple2<String, Integer>> resultStream
= inputDataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
// 第四步:指定就按结果输出位置,这里只做标准输出
resultStream.print();
// 第五步:指定名称并触发流式任务
env.execute("Streaming WordCount");
}
}
测试流处理,使用Liunx中的nc -lk <端口号>模拟数据流

结果:
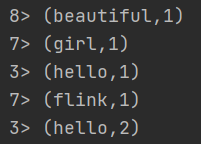
如上图所示,因为电脑cpu是8线程,所以这边没有设置的情况下,默认的slot会在1~8之间
Flink项目发布运行
Linux启动Flink
为了运行Flink,Linux只需提前安装好 Java 8 或者 Java 11。你可以通过以下命令来检查 Java 是否已经安装正确。
java -version
下载 release 1.12.0 并解压。
$ tar -xzf flink-1.12.0-bin-scala_2.11.tgz
$ cd flink-1.12.0-bin-scala_2.11
启动集群
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
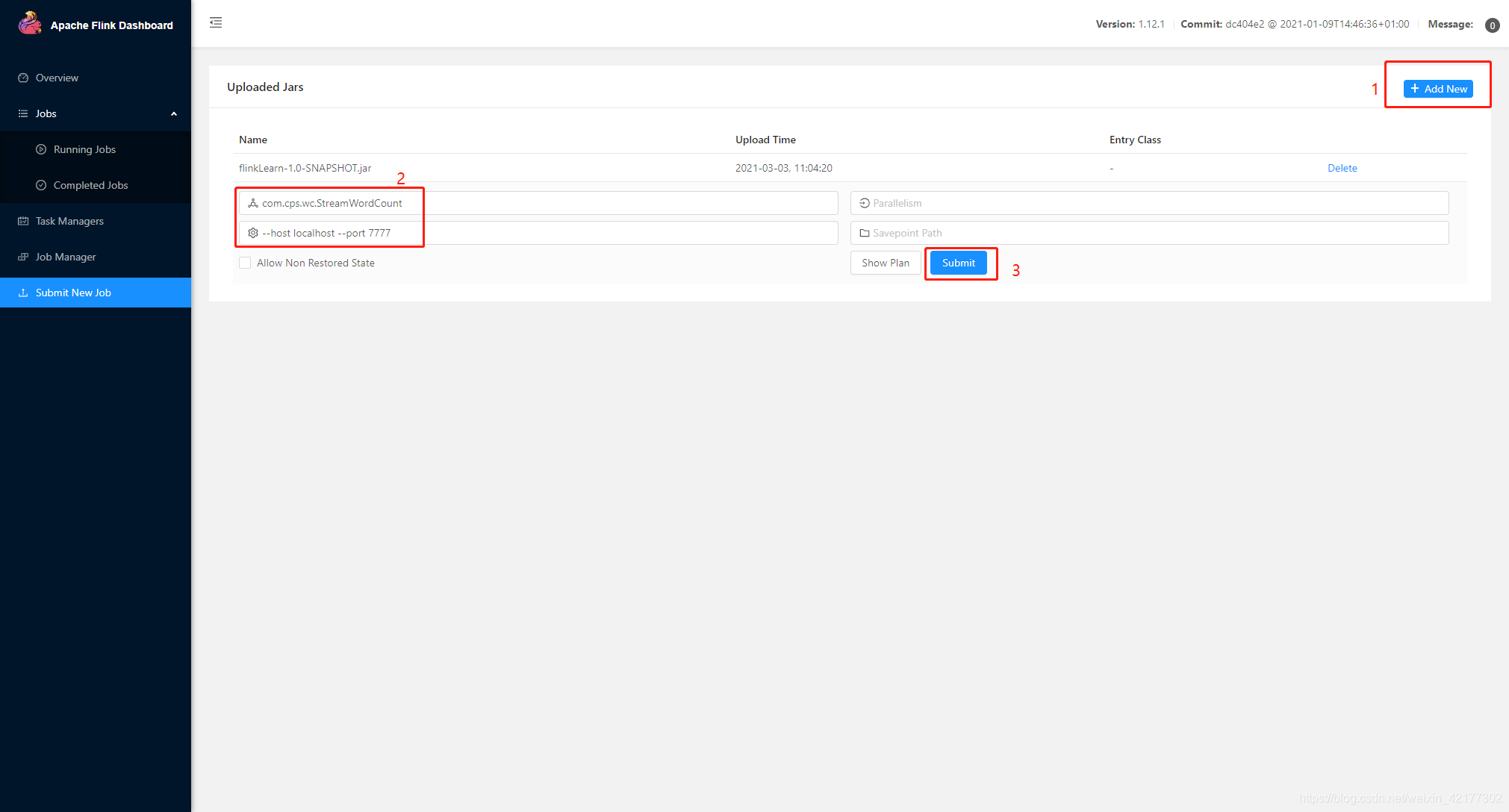
提交作业(Job)
Flink 的 Releases 附带了许多的示例作业。你可以任意选择一个,快速部署到已运行的集群上。
# 这里使用Linux自带的示例jar,如果要运行自己的项目,路径指定为自己的项目路径即可
$ ./bin/flink run examples/streaming/WordCount.jar
$ tail log/flink-*-taskexecutor-*.out
(to,1)
(be,1)
(or,1)
(not,1)
(to,2)
(be,2)
另外,你可以通过 Flink 的 Web UI(http://localhost:8081) 来监视集群的状态和正在运行的作业。如下图所示
下图所示的地方可以查看输出结果
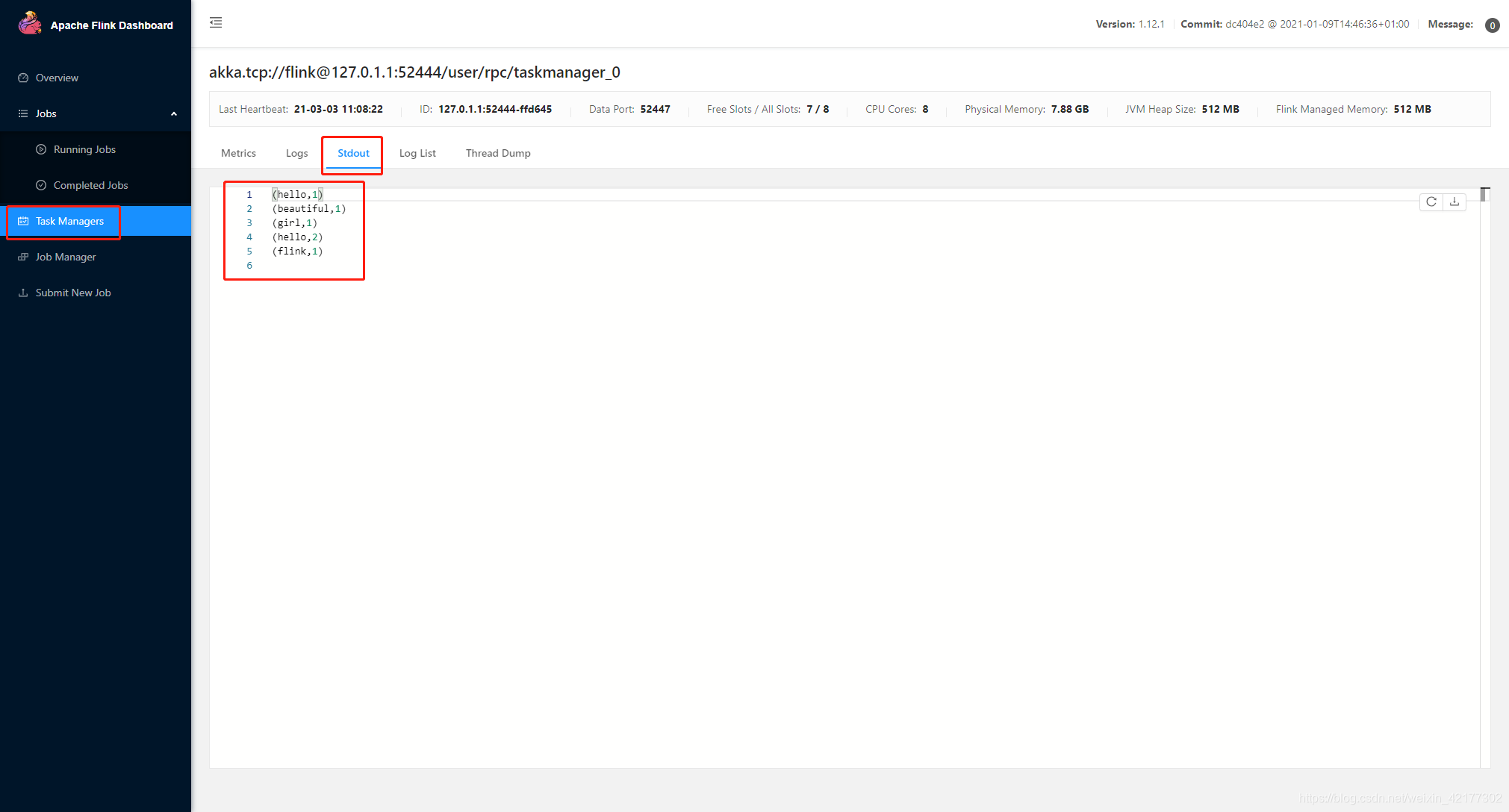
小结
这里介绍了基本的项目的搭建、发布运行的流程。其他的相关概念,比如具体的API的使用、Time、Watermark、Window、State、Checkpoint、Savepoint、集群部署、性能优化等相关内容,以后有机会再总结。
智能推荐
js实现正则表达式验证邮箱_电子邮件需要在js添加正则表达式验证-程序员宅基地
文章浏览阅读3.2w次,点赞3次,收藏13次。js实现正则表达式验证邮箱//这个验证有问题,[email protected]这样子的也能通过function check(){//验证账号是否合法//验证规则:字母,数字,下划线组成,字母开头,4-16位//语法:/^\w$/ \w*\w{0,}//var filter=/^[a-zA-Z]\w{3,15}$/;//var filter=new Re_电子邮件需要在js添加正则表达式验证
3代 C语言刷题程序-程序员宅基地
文章浏览阅读197次。添加随机刷题与顺序刷题(顺序可选定指定题数开始)
内存学习(四):内存映射2_匿名映射和文件映射-程序员宅基地
内存映射2涉及虚拟内存区域的成员和文件映射的虚拟内存区域。虚拟内存区域使用红黑树存储,以提高查找速度。
es6 filter函数的用法_Es6简化操作的一些数组方法使用及原理-程序员宅基地
文章浏览阅读227次。结合Es6数组方法的使用在Vue中使用更加简单数组下面方法都用这个数组es6之前遍历数组我们通常使用for循环来遍历数组 ,拿到数组中的每一项for循环forEach(遍历)forEach: forEach()会遍历数组, 循环体内没有返回值,forEach()循环不会改变原来数组的内容, forEach()有三个参数, 第一个参数是当前数组的每一项元素, 第二个参数是当前数组每一项元素的..._es6 filter 简便写法
MySQL锁表查询不到进程,如何处理_mysql查看表占用但是查不到占用进程-程序员宅基地
文章浏览阅读1.1k次。背景测试同事通过更新某个表的数据进行功能测试,突然说锁表了,也不知道原因为何,一直用的Navicat,然后用show OPEN TABLES where In_use > 0;命令也查询不到具体的进程ID常规解决办法查询是否锁表show OPEN TABLES where In_use > 0;查询进程show processlist;查询到相对应的进程,然后..._mysql查看表占用但是查不到占用进程
java 中 10进制 转为 4位 或者8位 16进制数_java %08x-程序员宅基地
文章浏览阅读3.9k次。int i =789;//输出为16进制数 Integer.toHexString(),String s=Integer.toHexString(Integer.valueOf(value));/对整数进行格式化:%[index$][标识][最小宽度]转换方式//保留 4位,不足补0s=String.format("%04x",Integer.valueOf(s));//保留 8位,不足补0s=String.format("%08x",Integer.valueOf(s));报错:jav_java %08x
随便推点
图像融合数据集,图像融合数据库_2007年图像融合大赛的数据集-程序员宅基地
文章浏览阅读4.5w次,点赞29次,收藏241次。一、论文中常用的网址:http://www.imagefusion.org (论文中经常引用,但是目前打不开)二、多聚焦图像:1、http://www.pxleyes.com/photography-contest/197262、Lytro Multi-focus Dataset(常用,彩色多聚焦图像)“This dataset contains 20 pairs o..._2007年图像融合大赛的数据集
Cadence PSpice 模型1:基于自带库新建二极管的PSpice模型图文教程_pspice二极管参数设置-程序员宅基地
文章浏览阅读3k次,点赞8次,收藏10次。使用Cadence PSpice进行电路图的仿真时,难免会遇到软件自带库中没有合适的元器件的情况,这就需要设计师自己新建元器件模型,本文详细介绍使用PSpice软件修改自带库的元器件模型的参数以得到自己需要的PSpice模型库的方法。_pspice二极管参数设置
cifar100.load_data()报错URL fetch failure on https://www.cs.toronto.edu/~kriz/cifar-10-python.tar:None-程序员宅基地
文章浏览阅读1.3k次。今天使用cifar100.load_data()加载cifar100数据集时报错“Exception: URL fetch failure on https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz: None ”刚开始我以为是网络不好,访问超时所以才报错,因为我昨天才用load_data()加载过数据,当时是可以加载的,但是没有等它下载完就关了,所以我换了一个网络试了下,还是不行,怎么回事?之后想到手动下载,再放在.keras/dataset_url fetch failure on
_itoa atoi、atof、itoa、itow _itoa_s 类型转换使用说明__itow_s-程序员宅基地
文章浏览阅读977次。_itoa atoi、atof、itoa、itow _itoa_s 类型转换使用说明 _itoa功能:把一整数转换为字符串用法:char * _itoa(int value, char *string, int radix); 详细解释: _itoa是英文integ__itow_s
vue+ elelment-ui +tree树形组件背景颜色的修改,点击节点背景颜色修改设置为其他颜色,或是样式不生效的原因_vue tree 鼠标放上显示灰色-程序员宅基地
文章浏览阅读2.4w次,点赞16次,收藏37次。本文仅作为我在初次学习vue+element-ui路上碰到的一些问题以及解决的办法的记录,不论问题的难易程度,于我而言是一种成长过程的记录,望大佬勿喷。vue+ elelment-ui +tree树形组件背景颜色的修改,直接在Element官网拷贝过来的树形组件背景颜色是白色,每次点击以及鼠标悬浮上后会有一个偏灰的背景颜色。如图但是如果我需要用树形组件放在一个黑色背景或其他背景颜色时,树形自..._vue tree 鼠标放上显示灰色
实现KMO和Bartlett的球形度检验的两种方法_kmo检验和bartlett球形检验-程序员宅基地
文章浏览阅读10w+次,点赞31次,收藏248次。文章目录实现KMO和Bartlett的球形度检验的两种方法SPSS 实现KMO和Bartlett的球形度检验第一步:选择“因子分析”第二步:选择变量第三步:选择KMO和巴特利特球形度检验输出结果SAS 实现KMO和Bartlett的球形度检验数据集来源参考资料实现KMO和Bartlett的球形度检验的两种方法SPSS 实现KMO和Bartlett的球形度检验第一步:选择“因子分析”导入数据..._kmo检验和bartlett球形检验