elasticsearch 7.4.2 进阶_elasticsearch 索引下面还能划分type-程序员宅基地
技术标签: elasticsearch 搜索
elasticsearch 7.4 进阶
SearchApi
ES支持两种基本方式检索
- 通过Rest request URI 发送搜索参数(uri + 检索参数)
- 通过Rest request body 发送 (uri + 请求体)
在kibana工具箱Dev Tools执行
GET /bank/_search?q=*&sort=account_number:asc
说明:
- /bank 查询bank索引下的数据
- _search 固定语法,查询
- q=* 查询所有
- sort=account_number:asc 排序规则,按照account_number字段升序排序
查询结果如下
{
"took" : 121,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "0",
"_score" : null,
"_source" : {
"account_number" : 0,
"balance" : 16623,
"firstname" : "Bradshaw",
"lastname" : "Mckenzie",
"age" : 29,
"gender" : "F",
"address" : "244 Columbus Place",
"employer" : "Euron",
"email" : "[email protected]",
"city" : "Hobucken",
"state" : "CO"
},
"sort" : [
0
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "1",
"_score" : null,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "[email protected]",
"city" : "Brogan",
"state" : "IL"
},
"sort" : [
1
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "2",
"_score" : null,
"_source" : {
"account_number" : 2,
"balance" : 28838,
"firstname" : "Roberta",
"lastname" : "Bender",
"age" : 22,
"gender" : "F",
"address" : "560 Kingsway Place",
"employer" : "Chillium",
"email" : "[email protected]",
"city" : "Bennett",
"state" : "LA"
},
"sort" : [
2
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "3",
"_score" : null,
"_source" : {
"account_number" : 3,
"balance" : 44947,
"firstname" : "Levine",
"lastname" : "Burks",
"age" : 26,
"gender" : "F",
"address" : "328 Wilson Avenue",
"employer" : "Amtap",
"email" : "[email protected]",
"city" : "Cochranville",
"state" : "HI"
},
"sort" : [
3
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "4",
"_score" : null,
"_source" : {
"account_number" : 4,
"balance" : 27658,
"firstname" : "Rodriquez",
"lastname" : "Flores",
"age" : 31,
"gender" : "F",
"address" : "986 Wyckoff Avenue",
"employer" : "Tourmania",
"email" : "[email protected]",
"city" : "Eastvale",
"state" : "HI"
},
"sort" : [
4
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "5",
"_score" : null,
"_source" : {
"account_number" : 5,
"balance" : 29342,
"firstname" : "Leola",
"lastname" : "Stewart",
"age" : 30,
"gender" : "F",
"address" : "311 Elm Place",
"employer" : "Diginetic",
"email" : "[email protected]",
"city" : "Fairview",
"state" : "NJ"
},
"sort" : [
5
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "6",
"_score" : null,
"_source" : {
"account_number" : 6,
"balance" : 5686,
"firstname" : "Hattie",
"lastname" : "Bond",
"age" : 36,
"gender" : "M",
"address" : "671 Bristol Street",
"employer" : "Netagy",
"email" : "[email protected]",
"city" : "Dante",
"state" : "TN"
},
"sort" : [
6
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "7",
"_score" : null,
"_source" : {
"account_number" : 7,
"balance" : 39121,
"firstname" : "Levy",
"lastname" : "Richard",
"age" : 22,
"gender" : "M",
"address" : "820 Logan Street",
"employer" : "Teraprene",
"email" : "[email protected]",
"city" : "Shrewsbury",
"state" : "MO"
},
"sort" : [
7
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "8",
"_score" : null,
"_source" : {
"account_number" : 8,
"balance" : 48868,
"firstname" : "Jan",
"lastname" : "Burns",
"age" : 35,
"gender" : "M",
"address" : "699 Visitation Place",
"employer" : "Glasstep",
"email" : "[email protected]",
"city" : "Wakulla",
"state" : "AZ"
},
"sort" : [
8
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "9",
"_score" : null,
"_source" : {
"account_number" : 9,
"balance" : 24776,
"firstname" : "Opal",
"lastname" : "Meadows",
"age" : 39,
"gender" : "M",
"address" : "963 Neptune Avenue",
"employer" : "Cedward",
"email" : "[email protected]",
"city" : "Olney",
"state" : "OH"
},
"sort" : [
9
]
}
]
}
}
参数说明
-
took – Elasticsearch运行查询所需的时间(以毫秒为单位)
-
timed_out –搜索请求是否超时
-
_shards –搜索了多少个分片,以及成功,失败或跳过了多少个分片。
-
max_score –找到的最相关文件的分数
-
hits.total.value -找到了多少个匹配的文档
-
hits.sort -文档的排序位置(不按相关性得分排序时)
-
hits._score-文档的相关性得分(使用时不适用match_all)
在本示例 相应hits.total.value为1000,但发现记录里只有10条记录,这是因为
默认情况下,hits响应部分包括符合搜索条件的前10个文档,类似于Mysql数据库的分页。Mysql分页使用limt
select *from user limt 5; //返回结果集的前5行记录
select * from user limt 5,5 //从第6行开始,返回5行记录,也就是6, 7, 8, 9,10,这里的行索引是从0开始的
es也有类似的语法,可以使用 from 和 size 两个参数
GET /bank/_search?q=*&sort=account_number:asc&from=10&size=1
结果如下
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "10",
"_score" : null,
"_source" : {
"account_number" : 10,
"balance" : 46170,
"firstname" : "Dominique",
"lastname" : "Park",
"age" : 37,
"gender" : "F",
"address" : "100 Gatling Place",
"employer" : "Conjurica",
"email" : "[email protected]",
"city" : "Omar",
"state" : "NJ"
},
"sort" : [
10
]
}
]
}
}
Query DSL
语法格式
elasticsearch提供了一个可以执行查询的Json风格的DSL(domain-specific-language领域特定语言),这个称为 Query DSL。
Query DSL 基本使用
GET /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": "asc"
},
{
"balance": {
"order": "desc"
}
}
],
"from": 10,
"size": 10,
"_source": ["account_number","balance"]
}
先按照 account_number 升序排序,再按照 balance 降序排序
- query —查询条件
- sort — 排序条件( “account_number”: "asc"为简写方式)
- match_all – 匹配所有
- _source —可以指定返回哪些字段,类似于Mysql中的 select name,age from user
match【匹配查询】
- 基本类型(非字符串),精确匹配
查询 1号用户的数据文档
GET /bank/_search
{
"query": {
"match": {
"account_number": 1
}
}
}
kibana查询结果如下
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "[email protected]",
"city" : "Brogan",
"state" : "IL"
}
}
]
}
}
使用match匹配查询,会有 max_score 以及 _score 得分情况,es会根据这个得分排序返回,得分越高越靠前
match也可以模糊匹配,匹配字段是字符串, es会将 字段匹配值进行分词,查询
GET /bank/_search
{
"query": {
"match": {
"address": "Kings"
}
}
}
结果如下
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 5.9908285,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 5.9908285,
"_source" : {
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "[email protected]",
"city" : "Ribera",
"state" : "WA"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "722",
"_score" : 5.9908285,
"_source" : {
"account_number" : 722,
"balance" : 27256,
"firstname" : "Roberts",
"lastname" : "Beasley",
"age" : 34,
"gender" : "F",
"address" : "305 Kings Hwy",
"employer" : "Quintity",
"email" : "[email protected]",
"city" : "Hayden",
"state" : "PA"
}
}
]
}
}
match_phrase【短语匹配】
将需要匹配的值当成一个整体单词(不会被分词),进行检索
例如: “address”: “mill road”
如果使用match查询,es会将mill road分词成 mill 和road,只要address字段含有mill,road其一就会被检索出来,并给出相关性得分。
如果使用match_phrase,只有address含有 mill road这个短语的才会被检索出来,例如:
xxx mill road xxx会被检索出来, mill xxx road就不会被检索出来
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
multi_match【多字段匹配】
示例: 查询 addrss 或 status 包含 mill的文档数据
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["address","state"]
}
}
}
类似于Mysql中 address like ‘%mill%’ or status like '%mill%'
注意:
multi_match 也会进行分词查询
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill movico",
"fields": ["address","city"]
}
}
}
address字段包含 mill 或 movico
city字段包含 mill 或 movico
都会被检索出来
bool 【复合查询】
在复合查询中,会使用must,must_not以及should组合来查询
- must 必须满足
- must_not 必须不满足
- should 应该,可以满足,也可以不满足,满足最好(相关性得分会高)
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "gender": "F" } },
{"match":{"address":"mill"}}
]
}
}
}
- must 必须满足
含义: 查询 gender包含F的,同时,address包含mill的
除了有 must 还有一个 must_not(必须不是)
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "gender": "F" } },
{"match":{"address":"mill"}}
],
"must_not": [
{"match":{"age":"38"}}
]
}
}
}
说明:
查询 age 不是 38的数据
查看官方文档可知,must 和 should 会贡献相关性得分,换言之,must 和 should 匹配成功的话,相关性得分会高
filter【结果过滤】
filter会把不满足 fiter定义规则的给过滤掉,同时,filter不会贡献相关性得分
GET /bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
term 查询
term级别查询将按照存储在倒排索引中的确切字词进行操作,这些查询通常用于数字,日期和枚举等结构化数据,而不是全文本字段。 或者,它们允许您制作低级查询,并在分析过程之前进行。
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个。
所以: 查询数字,日期这种的可以使用term,查询文本类型的使用match
总结: 精确匹配的几种方式
方式一: match_phrase
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "Madison Street"
}
}
}
方式二: match + 字段.keyword
GET /bank/_search
{
"query": {
"match": {
"address.keyword": "Madison Street"
}
}
}
那么二者的区别是什么?
“match_phrase”: {
“address”: “Madison Street”
}
类似于Mysql中的 address like ‘%Madison Street%’
“match”: {
“address.keyword”: “Madison Street”
}
类似于Mysql中的 address = ‘Madison Street’
aggregations【执行聚合】
聚合提供了从数据中分组和提取数据的能力,最简单的聚合类似于 SQL GROUP BY和聚合函数
聚合简单的结构如下:
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]?
}
[,"<aggregation_name_2>" : { ... } ]*
}
-
需求: 搜索address中包含mill的所有人的年龄分布以及平均年龄
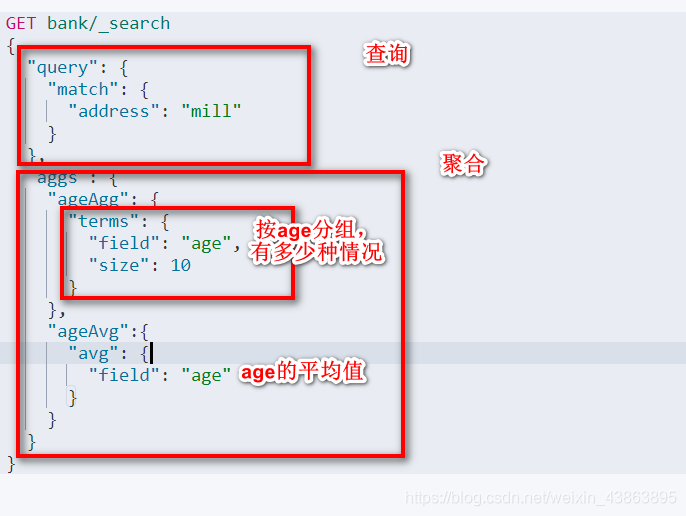

-
需求2 按照年龄聚合,并且求各个年龄段的平均工资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"aggAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}

- 需求3 查出所有年龄分布,这些年龄段中性别为M的平均薪资和性别为F的平均薪资,以及这个年龄段的总体平均薪资
GET bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ageAgg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"genderAgg": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
},
"balanceAvg":{
"avg": {
"field": "balance"
}
}
}
}
}
}
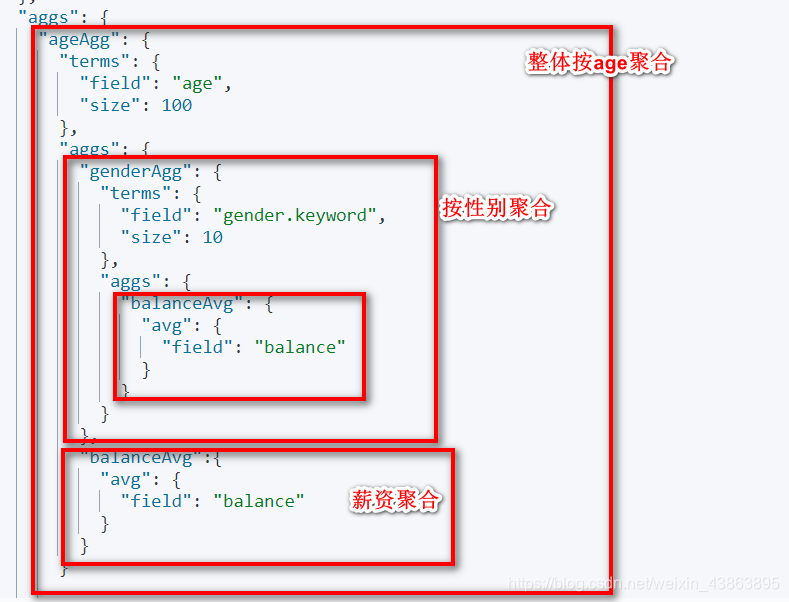
结果如下

mapping
mapping是类似于数据库中的表结构定义。
用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。
比如: 使用mapping用来定义
- 哪些字符串属性应该被看作全文本属性(full text field)
- 哪些属性包含数字、日期或地理位置
- 文档中的属性是否能被索引(_all 配置)
- 日期的格式
- 自定义映射规则来执行动态添加属性
注意

在es8版本将移除(type),所以以后可以将文档直接存储在某一个索引下面。
查询mapping 信息
GET bank/_mapping
结果如下:
{
"bank" : {
"mappings" : {
"properties" : {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"employer" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"firstname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
创建索引并指定映射规则
PUT /my-index
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
注意: type 为 text 的会被分词检索,keyword不会被分词检索,当成关键字整体匹配。
添加新的字段映射
PUT /my-index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
index 为false,表示该字段不需要被索引,
index默认为true
更新映射
对于已经存在的字段映射,不能直接更新。可以创建新的索引,将数据迁移过去。
需求: 创建新的索引 new bank,修改之前字段的mapping映射,将bank数据迁移过去
PUT /newbank
{
"mappings": {
"properties": {
"account_number" : {
"type" : "long"
},
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer"
},
"balance" : {
"type" : "long"
},
"city" : {
"type" : "keyword"
},
"email" : {
"type" : "keyword"
},
"employer" : {
"type" : "keyword"
},
"firstname" : {
"type" : "text"
},
"gender" : {
"type" : "keyword"
},
"lastname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"state" : {
"type" : "keyword"
}
}
}
}
数据迁移
POST _reindex
{
"source": {
"index": "bank",
"type": "account"
},
"dest": {
"index": "newbank"
}
}
注意:
将source下的数据迁移到dest下
如果旧索引下有 type,在source下写type,如果没有type就不用写
智能推荐
物联网开发技术栈_物联网技术java技术栈-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏10次。物联网开发技术栈 内容简介作为互联网技术的进化,物联网开发并非孤立的技术栈,而是向上承接了互联网,向下统领了嵌入式硬件开发的一个承上启下的全栈开发技术。虽然我们并不能预测物联网技术栈最终的样子:统一的开发语言是 JavaScript 还是 Python 亦或者其他编程语言;HTTP、WebSockets、MQTT、CoAP 等协议谁会是最后的赢家,并且随着物联网的不断进化,甚至我们..._物联网技术java技术栈
《Git学习笔记:Git入门 & 常用命令》-程序员宅基地
文章浏览阅读674次,点赞10次,收藏11次。Git是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理,通过Git仓库来存储和管理这些文件,Git仓库分为两种:指的是存储在各个开发人员自己本机电脑上的Git仓库指的是远程服务器上的Git仓库commit:提交,将本地文件和版本信息保存到本地仓库push:推送(上传),将本地仓库文件和版本信息上传到远程仓库pull:拉取(下载),将远程仓库文件和版本信息下载到本地仓库。
CPU热点分析——pprof (gperftools)使用_gperftools pprof-程序员宅基地
文章浏览阅读4.6k次。pprof (gperftools)使用谷歌的工具集,可查看CPU采样结果。pprof (google-perftool),用于来分析程序,必须保证程序能正常退出。使用步骤:1.准备工具,先安装工具包libunwind-1.1.tar.gzgperftools-2.1.tar.gz解压后 configure到系统默认路径即可,之后直接-lprofiler 2.再安装图形工具sudo yum ins..._gperftools pprof
JavaScript BOM-程序员宅基地
文章浏览阅读118次。JavaScript BOM:Navigator、History、Location
MongoDB数据库 —— 图形化工具_mongodb数据库图形化工具-程序员宅基地
文章浏览阅读6.2k次,点赞16次,收藏66次。在前面通过使用MongoDB在命令窗口操作数据库,而MySQL数据库也同样可以在命令窗口使用sql语句操作数据库,在安装数据库的时候提到可以安装这个图形化工具的,为了节省安装时间和卡顿选择后续安装MongoDB图形化工具,在MySQL数据中同样也有这个MySQL workbench 图形化工具可以选择进行安装;那么本篇就来安装MongoDB的图形化工具 — MongoDBCompass。_mongodb数据库图形化工具
ChatGPT带给智慧城市的启示——未来城市演进路径的探讨-程序员宅基地
文章浏览阅读1.4k次,点赞13次,收藏10次。未来城市的大模型包括城市总体规划、城市交通运输管理、城市公共安全和应急管理、经济发展和产业园区发展、社区发展、资源承载调控、污染调控、社会资源优化调控、基础设施调控、人口研究等模型。其对城市要素、关键指标、函数、流程、模型、平台、技术、资金、人才、市场、自然环境等内外部因素进行仿真建模。采用物联网、云计算、大数据、数字孪生和人工智能等技术来获取地、物、人、组织、环境、社会、经济、业务逻辑和运营规律等相关数据。、物联网、大数据、云计算、数字孪生、元宇宙、可穿戴生理传感器、分布式新能源等各类新技术。
随便推点
从零开始开发Shopify主题:(4)调用自定义配置_shopify自定义主题-程序员宅基地
文章浏览阅读3.6k次。在上一篇文章中,我们知道了如何使用配置文件自定义主题,以允许商店所有者自己更改Shopify主题。 如上所述,这些设置会在用户单击管理面板的在线商店>主题部分中的自定义主题按钮时显示,并在主题开发文件的config / settings_schema.json文件中定义。在这篇文章中,我们将了解如何访问这些设置并在开发主题时调用它们。调用配置要调用模板中的配置信息,需要使用li..._shopify自定义主题
git本地分支与远程分支关联及遇到的问题解决方案_本地分支 '(no branch)' (远程分支 = '(no branch)') 是无效的。引用名-程序员宅基地
文章浏览阅读2.6k次。1.查看本地分支git branch绿色表示当前分支#######################################################2.查看远程分支git branch -a#######################################################3.切换分支git checkout branch_name..._本地分支 '(no branch)' (远程分支 = '(no branch)') 是无效的。引用名称必须遵循
java连接mysql出现The server time zone value '�й���ʱ��' is unrecognized的解决方法_java.lang.runtimeexception: the server time zone v-程序员宅基地
文章浏览阅读2.2w次,点赞18次,收藏28次。java连接mysql出现The server time zone value '�й���ʱ��' is unrecognized的解决方法在Idea中连接数据库是抛出The server time zone value ‘�й���ʱ��’ is unrecogni错误 原因是因为使用了Mysql Connector/J 6.x以上的版本,然后就报了时区的错误。解决办法在配置url中添..._java.lang.runtimeexception: the server time zone value '嚙請對蕭嚙踝蕭
鸿蒙原生应用元服务实战-Serverless华为账户认证登录需尽快适配-程序员宅基地
文章浏览阅读671次,点赞11次,收藏9次。并且在这个固定的serverless服务中去增加这个,应该不是应用元服务开发者有这个加入权限的,应该是要统一解决,类似实现和手机注册验证一样的,直接可以使用或者少量代码配置即可使用。另外就是如果是新的元服务应用,使用的serverless,如果不支持华为账户功能,就没法上架,这个也是比较麻烦的,前面已经使用serverless开发基本完成或者已经完成的,得用其他方式去实现才行吧。对于已经上架的应用和元服务、升级也没法进行。3月1日的时间是快到了。
使用XAMPP可视化管理Mysql,使用JDBC访问数据库执行插入、查询、删除等操作_xammp进入可视化界面-程序员宅基地
文章浏览阅读5.7k次,点赞2次,收藏8次。准备工作:安装XAMPP,登陆apache,mysql,并通过phpadmin来创建数据库,新建一个表,插入一些数据:http://localhost/phpmyadmin,最好设置密码,不然后面连接数据库的时候可能会无法访问设置密码方式:修改密码--->一定要使用生成的密码来登陆,包括后面的数据库url也是。我简历的数据如下:这时候就可以在eclipse中编程开发_xammp进入可视化界面
(转) spring 的jar各包作用-程序员宅基地
文章浏览阅读119次。转自:http://blog.csdn.net/cailiang517502214/article/details/4797642spring.jar是包含有完整发布的单个jar包,spring.jar中包含除了spring-mock.jar里所包含的内容外其它所有jar包的内容,因为只有在开发环境下才会用到spring-mock.jar来进行辅助测试,正式应用系统中是用不得这些类的。...