mysql中的Redo log_redolog刷盘-程序员宅基地
技术标签: java mysql 面试题 - mysql 数据库
目录标题
前言
redolog保证持久性
我们都知道,事务的四大特性里面有一个是 持久性 ,具体来说就是只要事务提交成功,那么对数据库做的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态 。
那么 mysql是如何保证一致性的呢?最简单的做法是在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题,主要体现在两个方面:
因为 Innodb 是以 页 为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差!
因此 mysql 设计了 redo log , 具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题了(相对而言文件更小并且是顺序IO)。
redolog工作过程
redo log(重做日志)是InnoDB存储引擎独有的,它让MySQL拥有了崩溃恢复能力。
比如MySQL实例挂了或宕机了,重启时,InnoDB存储引擎会使用redo log恢复数据,保证数据的持久性与完整性。

MySQL中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到Buffer Pool中。
后续查询都是先从Buffer Pool中找,没有命中再去硬盘加载,减少硬盘IO开销,提升性能。
更新数据,也是先从Buffer Pool查找要更新的数据,就直接在Buffer Pool里更新;如果没有找到要更新的数据,则从硬盘加载到Buffer Pool。
然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(redo log buffer)里,接着刷盘到redo log文件里。
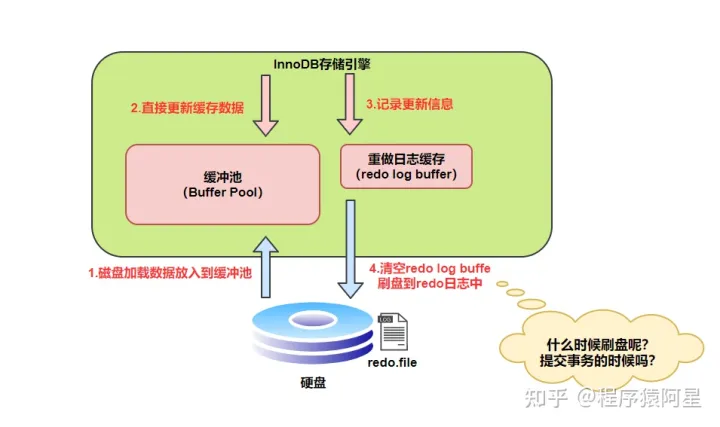
理想情况,事务一提交就会进行刷盘操作,但实际上,刷盘的时机是根据策略来进行的。
每条redo记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成
redo log中的WAL(先写日志,再写磁盘【写入redo log file】)
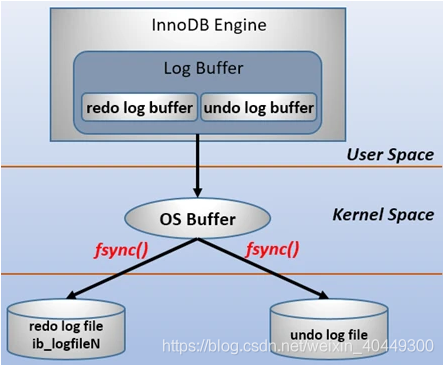
redo log 包括两部分:一个是内存中的日志缓冲( redo log buffer ),另一个是磁盘上的日志文件( redo log file )。 mysql 每执行一条 DML 语句,先将记录写入 redo log buffer ,后续某个时间点再一次性将多个操作记录写到 redo log file 。这种 先写日志,再写磁盘 的技术就是 MySQL里经常说到的 WAL(Write-Ahead Logging) 技术。
在计算机操作系统中,用户空间( user space )下的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间( kernel space )缓冲区( OS Buffer )。因此, redo log buffer 写入redo log file 实际上是先写入 OS Buffer ,然后再通过系统调用fsync()将其刷到redo log file中,过程如下:
刷盘策略 重要参数innodb_flush_log_at_trx_commit
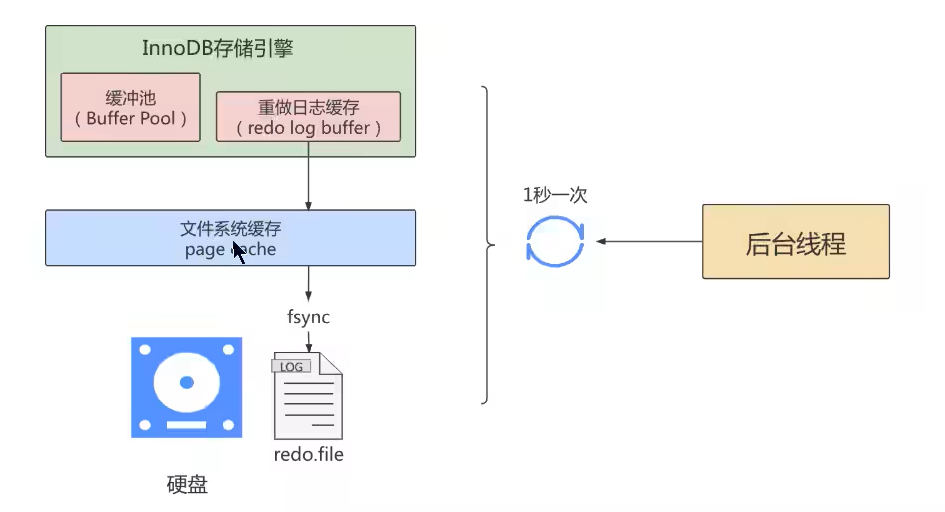
mysql 支持三种将 redo log buffer 写入 redo log file 的时机,可以通过 innodb_flush_log_at_trx_commit 参数配置,各参数值含义如下:
innodb_flush_log_at_trx_commit=0 (延迟写)事务提交时不会将 redo log buffer 中日志写入到 os buffer ,而是InnoDB存储引擎后台有一个线程,每隔1秒,就会把redo log buffer中的内容写入到os buffer 。并调用 fsync() 写入到 redo log file 中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。
innodb_flush_log_at_trx_commit=1(实时写,实时刷) 表示事务每次提交都会将 redo log buffer 中的日志写入 os buffer 并调用 fsync() 刷到 redo log file 中。只要事务提交成功,那么 redo log 就必然在磁盘里了。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。
innodb_flush_log_at_trx_commit=2(实时写,延迟刷) 表示提交事务的时候,都仅写入到 os buffer ,然后是每秒调用 fsync() 将 os buffer 中的日志写入到 redo log file 。
总结:
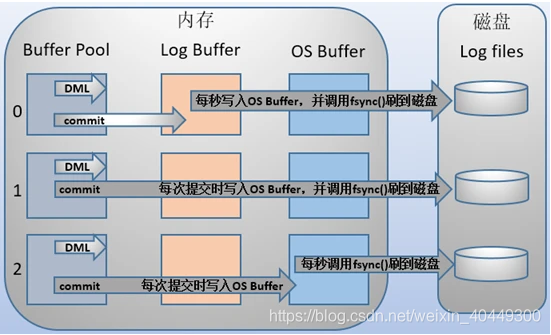
0表示每秒将"log buffer"同步到"os buffer"且从"os buffer"刷到磁盘日志文件中。
1表示每事务提交都将"log buffer"同步到"os buffer"且从"os buffer"刷到磁盘日志文件中。
2表示每事务提交都将"log buffer"同步到"os buffer"但每秒才从"os buffer"刷到磁盘日志文件中。
如何选择
对数据丢失很敏感,设置为1,保证写到磁盘上。但性能较差。
对数据不太敏感,设置为0或2,性能较好。但可能会丢失1秒的数据。
Redo log file日志文件
MySQL默认目录中,有两个文件ib_logfile0和ib_logfile1,每次刷盘都是将数据刷新到这两个文件内
Redo日志文件有很多个,一般以日志文件组的形式出现,文件统一命名,格式是ib_logfile+数字,从0开始
日志文件组中每个文件大小相同
每次写入从0开始,然后是1,2,3…
日志文件组
硬盘上存储的redo log日志文件不只一个,而是以一个日志文件组的形式出现的,每个的redo日志文件大小都是一样的。
比如可以配置为一组4个文件,每个文件的大小是1GB,整个redo log日志文件组可以记录4G的内容。
它采用的是环形数组形式,从头开始写,写到末尾又回到头循环写,如下图所示。

redo log刷盘与数据页刷盘
同时我们很容易得知, 在innodb中,既有 redo log 需要刷盘,还有 数据页 也需要刷盘, redo log 存在的意义主要就是降低对 数据页 刷盘的要求 。
在上图中,write pos表示 redo log 当前记录的 LSN(逻辑序列号)位置, check point 表示 数据页更改记录刷盘后对应 redo log 所处的 LSN (逻辑序列号)位置。
write pos 到 check point 之间的部分是 redo log 空着的部分,用于记录新的记录;check point到 write pos 之间是 redo log 待落盘的数据页更改记录。当write pos追上check point时,会先推动 check point 向前移动,空出位置再记录新的日志。
启动 innodb 的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为 redo log 记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如 binlog )要快很多。 重启 innodb 时,首先会检查磁盘中数据页的 LSN ,如果数据页的 LSN 小于日志中的 LSN ,则会从 checkpoint 开始恢复。 还有一种情况,在宕机前正处于checkpoint 的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的 LSN 大于日志中的 LSN ,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
redo log何时刷入磁盘
正常关闭服务器时
事务提交时(innodb_flush_log_at_trx_commit = 1 )
在事务提交时,为了保证持久性,会把log buffer中的日志全部刷到磁盘。注意,这时候,除了本事务的,可能还会刷入其它事务的日志。
后台线程输入(innodb_flush_log_at_trx_commit = 0 or innodb_flush_log_at_trx_commit = 2 )
innodb_flush_log_at_trx_commit = 0:每秒写入 os buffer 并调用 fsync() 写入到 redo log file 中
innodb_flush_log_at_trx_commit = 2:每秒调用 fsync() 将 os buffer 中的日志写入到 redo log file 中
redo log buffer 空间不足时
redo log buffer 的大小是有限的,如果不停的往这个有限大小的 log buffer 里塞入日志,很快它就会被填满。如果当前写入 log buffer 的redo 日志量已经占满了 log buffer 总容量的大约一半左右,就需要把这些日志刷新到磁盘上。
触发checkpoint规则
重做日志缓存、重做日志文件都是以块(block)的方式进行保存的,称之为重做日志块(redo log block),块的大小是固定的512字节。我们的redo log它是固定大小的,可以看作是一个逻辑上的 log group,由一定数量的log block 组成。
它的写入方式是从头到尾开始写,写到末尾又回到开头循环写。
其中有两个标记位置:
write pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。
checkpoint是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到磁盘。
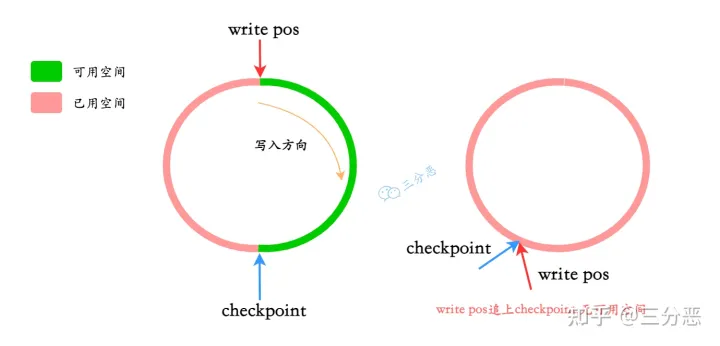
当write_pos追上checkpoint时,表示redo log日志已经写满。这时候就不能接着往里写数据了,需要执行checkpoint规则腾出可写空间。
所谓的checkpoint规则,就是checkpoint触发后,将buffer中日志页都刷到磁盘。
一条更新语句的执行步骤
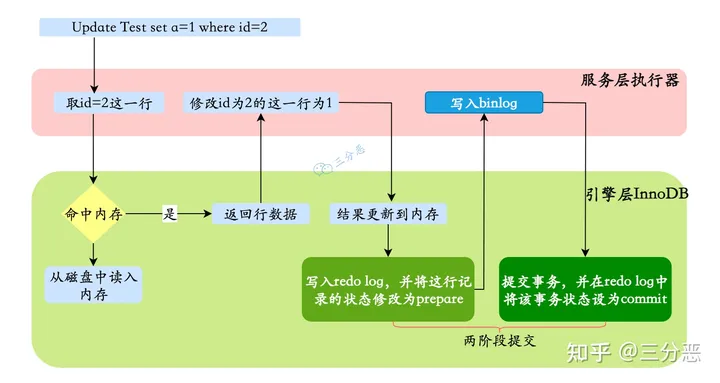
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare状态。然后告知执行器执行完成了,随时可以提交事务。 【写入 redo log(处于 prepare 阶段)】
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。【写 binlog】
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。【提交事务(处于 commit 状态)】
Mysql的两阶段提交

上面的流程采用了两阶段提交,那为什么要采用两阶段提交呢?是为了让 binlog 和 redo log 之间的逻辑一致。
我们假设一下上面的 update 语句在执行的每个时刻,MySQL 崩溃了,看一下两个日志间的逻辑是如何保持一致的。
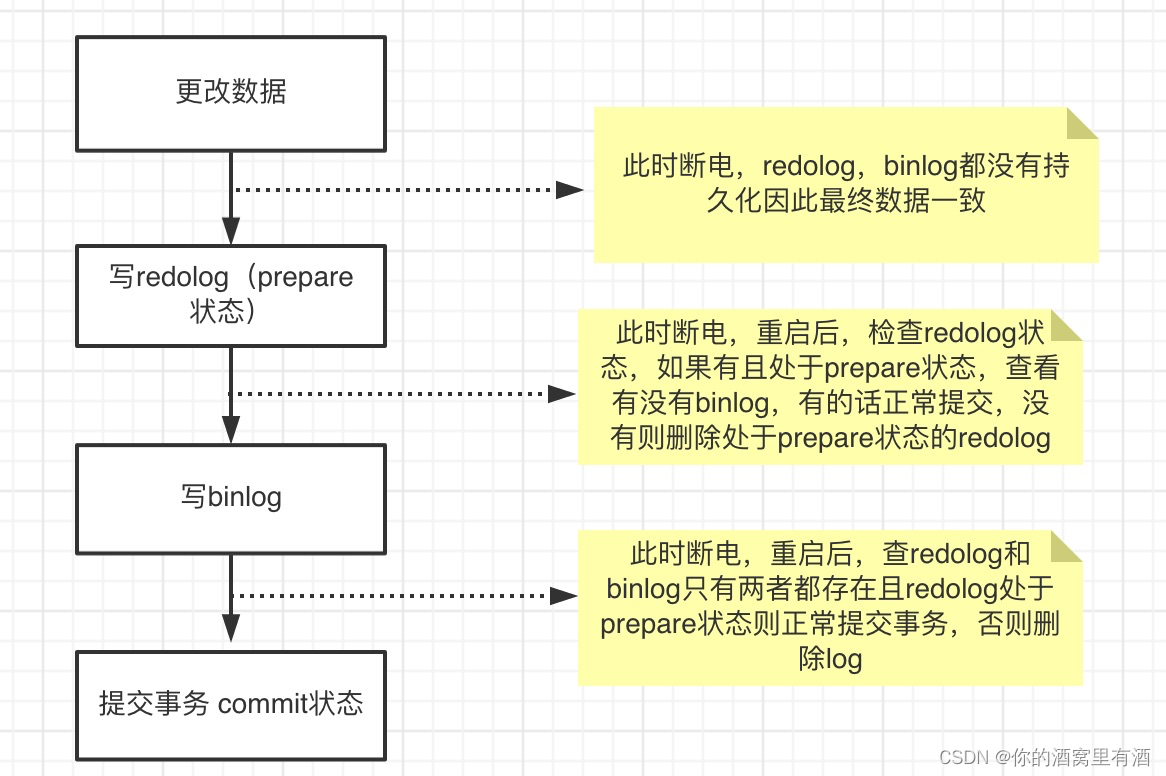
假设在步骤3前,MySQL崩溃重启,那么事务提交失败,不会影响数据。虽然更新了内存,但崩溃后,内存会丢失。
假设在步骤3完成后崩溃,此时已经写入 redo log 了,重启后,发现 redo log 处于 prepare 阶段,就不恢复。
假设在步骤4完成后崩溃,此时已经写入 binlog 了,重启后,发现 binlog 已经写入了,就把对应的 redo log 改为 commit 状态。
这样就能保证 redo log 和 binlog 的逻辑一致性。
两阶段提交是跨系统维持数据逻辑一致性时常用的一个方案。
为什么要引入redolog

修改数据量小,每次写入都写入磁盘造成资源浪费
innodb是以页为单位来管理存储空间的(数据页大小是16KB),任何的增删改差操作最终都会操作完整的一个页,会将整个页加载到buffer pool中,然后对需要修改的记录进行修改,而且仅仅修改了一条记录,刷新一个完整的数据页到磁盘的话过于浪费了
直接写回磁盘,是随机IO,效率低下
数据页刷盘是随机写,因为一个数据页对应的位置可能在硬盘文件的随机位置,所以性能是很差。
如果是写redo log,一行记录可能就占几十Byte,只包含表空间号、数据页号、磁盘文件偏移 量、更新值,同时redo log是循环写入固定的文件,是顺序写入磁盘的,所以刷盘速度很快。
所以用redo log形式记录修改内容,性能会远远超过刷数据页的方式,这也让数据库的并发能力更强。
视频链接:https://www.bilibili.com/video/BV1Pv411h7Ep
文章来源:https://javaguide.cn/database/mysql/mysql-logs.html#redo-log
日志文件:https://blog.csdn.net/Merciful_Lion/article/details/124715392
https://blog.csdn.net/weixin_40449300/article/details/117927295
https://www.cnblogs.com/liang24/p/14089065.html
https://blog.csdn.net/weixin_43213517/article/details/117457184
https://www.zhihu.com/question/486105337/answer/2538190061
智能推荐
js-选项卡原理_选项卡js原理-程序员宅基地
文章浏览阅读90次。【代码】js-选项卡原理。_选项卡js原理
设计模式-原型模式(Prototype)-程序员宅基地
文章浏览阅读67次。原型模式是一种对象创建型模式,它采用复制原型对象的方法来创建对象的实例。它创建的实例,具有与原型一样的数据结构和值分为深度克隆和浅度克隆。浅度克隆:克隆对象的值类型(基本数据类型),克隆引用类型的地址;深度克隆:克隆对象的值类型,引用类型的对象也复制一份副本。UML图:具体代码:浅度复制:import java.util.List;/*..._prototype 设计模式
个性化政府云的探索-程序员宅基地
文章浏览阅读59次。入选国内首批云计算服务创新发展试点城市的北京、上海、深圳、杭州和无锡起到了很好的示范作用,不仅促进了当地产业的升级换代,而且为国内其他城市发展云计算产业提供了很好的借鉴。据了解,目前国内至少有20个城市确定将云计算作为重点发展的产业。这势必会形成新一轮的云计算基础设施建设的**。由于云计算基础设施建设具有投资规模大,运维成本高,投资回收周期长,地域辐射性强等诸多特点,各地在建...
STM32问题集之BOOT0和BOOT1的作用_stm32boot0和boot1作用-程序员宅基地
文章浏览阅读9.4k次,点赞2次,收藏20次。一、功能及目的 在每个STM32的芯片上都有两个管脚BOOT0和BOOT1,这两个管脚在芯片复位时的电平状态决定了芯片复位后从哪个区域开始执行程序。BOOT1=x BOOT0=0 // 从用户闪存启动,这是正常的工作模式。BOOT1=0 BOOT0=1 // 从系统存储器启动,这种模式启动的程序_stm32boot0和boot1作用
C语言函数递归调用-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏22次。C语言函数递归调用_c语言函数递归调用
明日方舟抽卡模拟器wiki_明日方舟bilibili服-明日方舟bilibili服下载-程序员宅基地
文章浏览阅读410次。明日方舟bilibili服是一款天灾驾到战斗热血的创新二次元废土风塔防手游,精妙的二次元纸片人设计,为宅友们源源不断更新超多的纸片人老婆老公们,玩家将扮演废土正义一方“罗德岛”中的指挥官,与你身边的感染者们并肩作战。与同类塔防手游与众不同的几点,首先你可以在这抽卡轻松获得稀有,同时也可以在战斗体系和敌军走位机制看到不同。明日方舟bilibili服设定:1、起因不明并四处肆虐的天灾,席卷过的土地上出..._明日方舟抽卡模拟器
随便推点
Maven上传Jar到私服报错:ReasonPhrase: Repository version policy: SNAPSHOT does not allow version: xxx_repository version policy snapshot does not all-程序员宅基地
文章浏览阅读437次。Maven上传Jar到私服报错:ReasonPhrase: Repository version policy: SNAPSHOT does not allow version: xxx_repository version policy snapshot does not all
斐波那契数列、素数、质数和猴子吃桃问题_斐波那契日-程序员宅基地
文章浏览阅读1.2k次。斐波那契数列(Fibonacci Sequence)是由如下形式的一系列数字组成的:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …上述数字序列中反映出来的规律,就是下一个数字是该数字前面两个紧邻数字的和,具体如下所示:示例:比如上述斐波那契数列中的最后两个数,可以推导出34后面的数为21+34=55下面是一个更长一些的斐波那契数列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584,_斐波那契日
PHP必会面试题_//该层循环用来控制每轮 冒出一个数 需要比较的次数-程序员宅基地
文章浏览阅读363次。PHP必会面试题1. 基础篇1. 用 PHP 打印出前一天的时间格式是 2017-12-28 22:21:21? //>>1.当前时间减去一天的时间,然后再格式化echo date('Y-m-d H:i:s',time()-3600*24);//>>2.使用strtotime,可以将任何字符串时间转换成时间戳,仅针对英文echo date('Y-m-d H:i:s',str..._//该层循环用来控制每轮 冒出一个数 需要比较的次数
windows用mingw(g++)编译opencv,opencv_contrib,并install安装_opencv mingw contrib-程序员宅基地
文章浏览阅读1.3k次,点赞26次,收藏26次。windows下用mingw编译opencv貌似不支持cuda,选cuda会报错,我无法解决,所以没选cuda,下面两种编译方式支持。打开cmake gui程序,在下面两个框中分别输入opencv的源文件和编译目录,build-mingw为你创建的目录,可自定义命名。1、如果已经安装Qt,则Qt自带mingw编译器,从Qt安装目录找到编译器所在目录即可。1、如果已经安装Qt,则Qt自带cmake,从Qt安装目录找到cmake所在目录即可。2、若未安装Qt,则安装Mingw即可,参考我的另外一篇文章。_opencv mingw contrib
5个高质量简历模板网站,免费、免费、免费_hoso模板官网-程序员宅基地
文章浏览阅读10w+次,点赞42次,收藏309次。今天给大家推荐5个好用且免费的简历模板网站,简洁美观,非常值得收藏!1、菜鸟图库https://www.sucai999.com/search/word/0_242_0.html?v=NTYxMjky网站主要以设计类素材为主,办公类素材也很多,简历模板大部个偏简约风,各种版式都有,而且经常会更新。最重要的是全部都能免费下载。2、个人简历网https://www.gerenjianli.com/moban/这是一个专门提供简历模板的网站,里面有超多模板个类,找起来非常方便,风格也很多样,无须注册就能免费下载,_hoso模板官网
通过 TikTok 联盟提高销售额的 6 个步骤_tiktok联盟-程序员宅基地
文章浏览阅读142次。你听说过吗?该计划可让您以推广您的产品并在成功销售时支付佣金。它提供了新的营销渠道,使您的产品呈现在更广泛的受众面前并提高品牌知名度。此外,TikTok Shop联盟可以是一种经济高效的产品或服务营销方式。您只需在有人购买时付费,因此不存在在无效广告上浪费金钱的风险。这些诱人的好处是否足以让您想要开始您的TikTok Shop联盟活动?如果是这样,本指南适合您。_tiktok联盟