Spark最佳实践之如何有效分配资源_spark怎么分配任务-程序员宅基地
技术标签: 资源分配 spark 大数据系统 Spark emr YARN 大数据
一个企业的大数据系统通常由三层构成:底层基础设施、大数据平台、数据智能化应用。随着云计算的发展,大多数中小型企业越来越依赖云厂商提供的服务来构建自己的大数据平台,而不再自己维护底层基础设施。比如,我们公司目前主要使用AWS EMR服务来构建Spark系统。EMR可以帮助我们根据需要快速建立一个Spark集群,让我们从底层机器的维护、集群的部署等繁杂的工作中解放出来,更多的关注在应用层。
基于EMR构建Spark系统时,有两个选择:第一个,构建一个大的EMR集群,在里面跑多个Spark应用;第二个,一个EMR集群只跑一个Spark应用。我们推荐尽量采用后者,这种方式可以充分利用云的优势,达到资源即用即启,应用间相互隔离。在这样的建设模式下,我们的性能调优工作主要包括以下几点:
- 将一个集群的资源充分分配给Spark
- 将Spark拿到的资源充分利用起来
- 优化Spark的使用方法,避免不必要的计算
本文主要探讨第一点,即如何在EMR下为Spark有效分配资源,从而榨干一个集群的所有可用资源。文中所述均基于AWS EMR 5.20、Spark 2.4版本。
1. 整体分析
我们先来谈谈在EMR中通过YARN Cluster模式来部署一个Spark集群时,会涉及到哪些角色与概念,从而搞清楚这中间有哪些与资源相关的事情。
一个EMR集群包含了一组AWS EC2机器,按照功能划分为三种角色:Master、Core、Task。Master机器负责整体的协调与管理;Core和Task机器负责具体任务的执行,区别在于Core机器上会运行HDFS程序用来存储数据。
YARN是Hadoop的一个独立组件,用于集群资源管理,被广泛应用在各种大数据计算引擎的部署中。YARN系统有两种角色:Resource Manager(RM)、Node Manager(NM)。NM运行在每台EMR Core/Task机器上面,负责本机的资源管理;RM运行在EMR Master机器上,负责整个集群的资源管理。YARN在资源管理上主要考虑两点要素:CPU和内存,表现形式是根据申请的CPU和内存数创建一个Container,然后将对应的程序跑在Container进程中。
Spark系统由两个角色组成:Driver、Executor,Driver负责任务的调度,Executor负责具体任务的执行。在YARN Cluster模式下,Driver通常跑在第一个Container中,即Application Master中,之后会根据配置的Executor的资源大小和数量向RM申请创建相应的Container,并将Executor跑在里面。
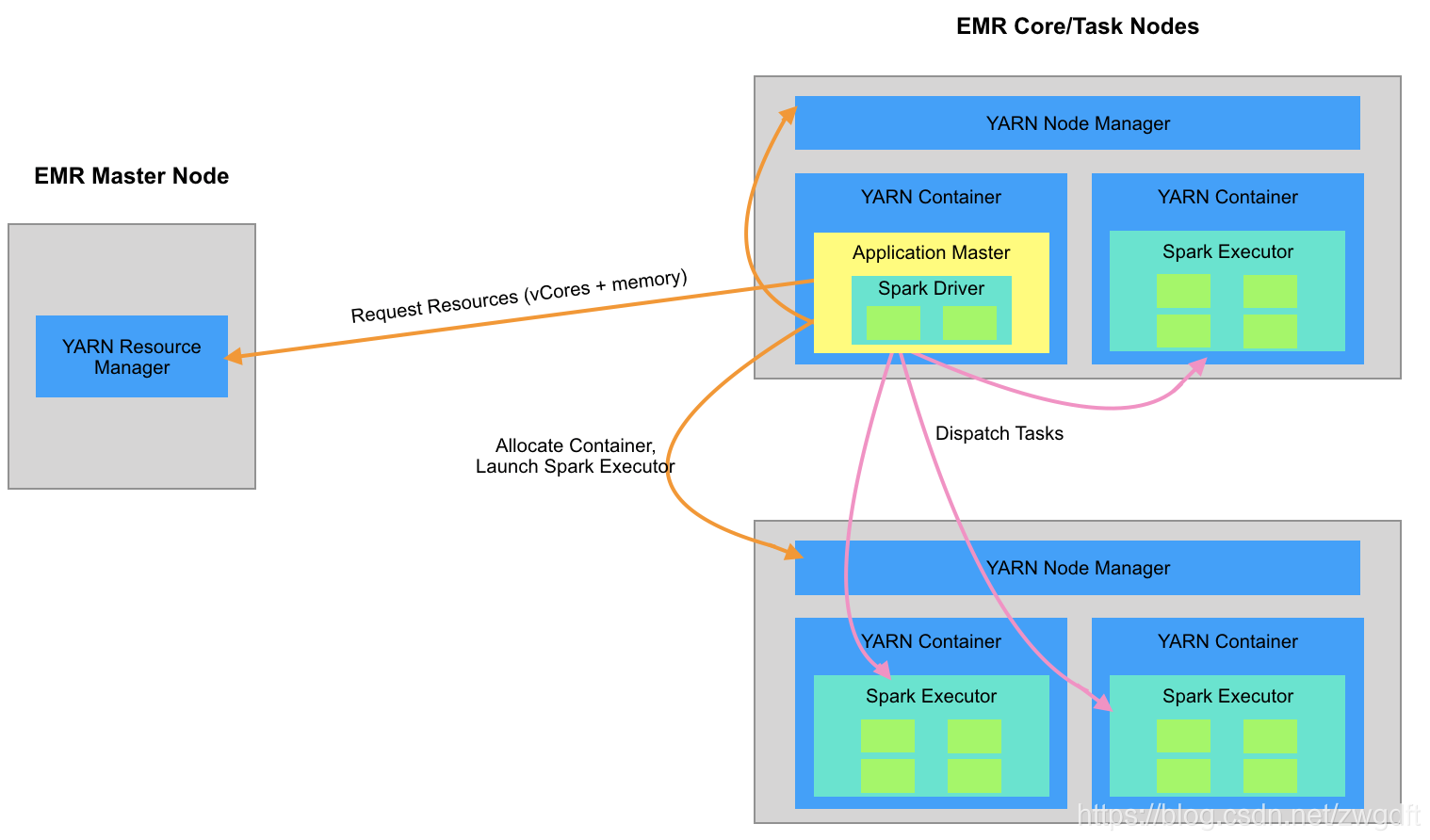
综合来看,与资源分配相关的事情主要有:
- 集群机器有多少资源
- YARN可以支配的资源有多少
- 一个YARN Container占用多少资源
集群机器有多少资源取决于我们选择什么样的AWS EC2机器,AWS提供了不同类型、不同规格的机器。比如我们常用的M4系列机器,属于通用型的范畴,即CPU、内存等能力均还不错,而这个系列里面又分xlarge、2xlarge、4xlarge等不同规格,每种规格对应了不同的CPU、内存等。
一台机器的资源显然不能完全被用于Spark计算,还需要预留一部分给系统、监控程序、调度程序等等。Spark是向YARN申请资源的,那么YARN怎么知道自己可以支配多少资源呢?主要由yarn-site.xml中的两个参数来配置,分别指定可以被分配的CPU和内存大小:
- yarn.nodemanager.resource.cpu-vcores
- yarn.nodemanager.resource.memory-mb
一个YARN Container所占用的资源大小主要由Spark Driver和Executor的大小来决定,这些配置在启动Spark应用时指定,主要有下面5个。其中,前两个用于配置Driver的大小,第三、四个配置Executor的大小,第五个配置需要多少个Executor。
- spark.driver.cores
- spark.driver.memory
- spark.executor.cores
- spark.executor.memory
- spark.executor.instances
2. EMR默认分配情况
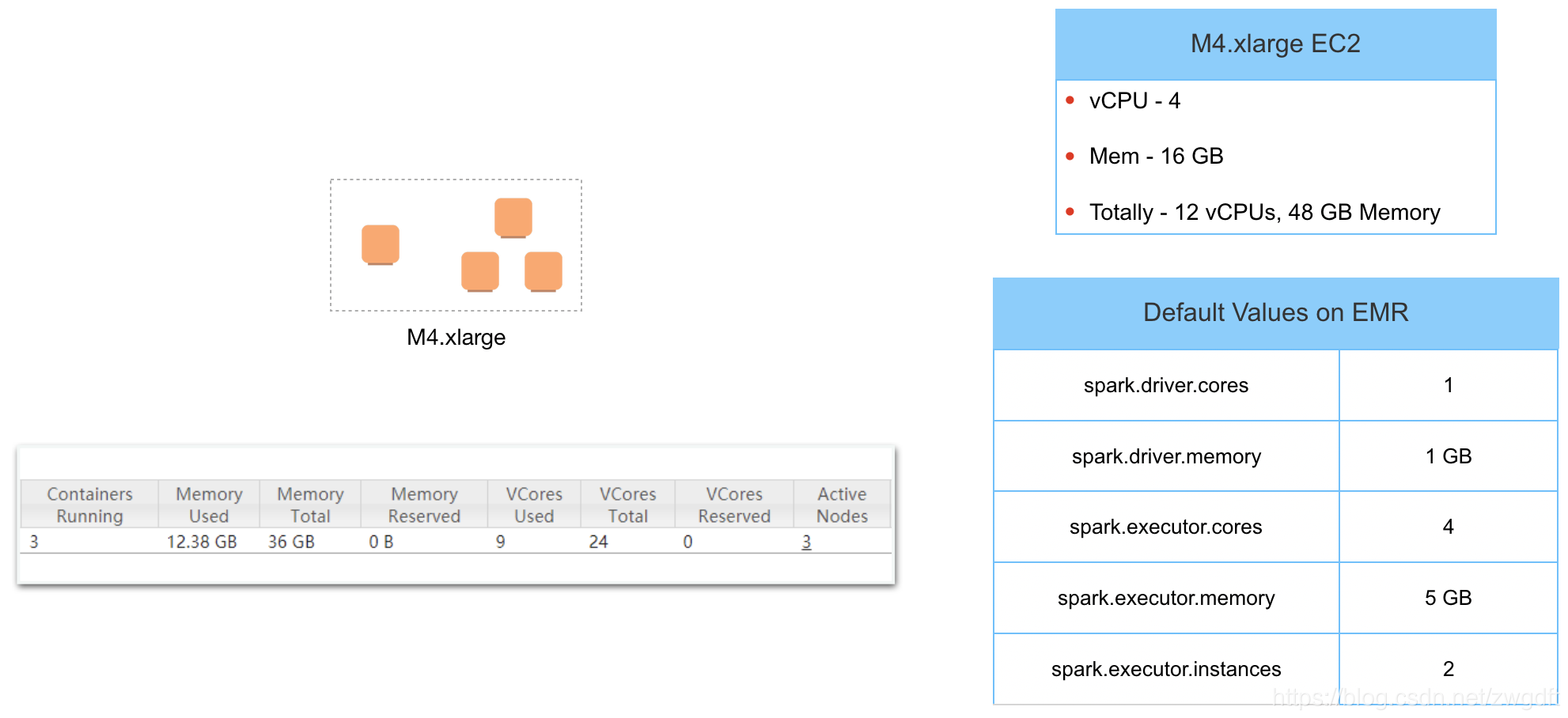
假设我们创建了一个1+3(1个Master,3个Core机器)的Spark集群,不做任何额外的配置,默认情况下其资源使用情况如何呢?我们结合下图来总结一下:
- 1台M4.xlarge机器有4个vCPU、16GB内存,3台Core机器总共有12个vCPU、48GB内存,但是在YARN上看到的可以支配的资源是24个vCore、36GB内存,YARN的可以支配资源是如何换算与配置的?
- 根据默认的Spark配置,Spark需要的资源是9个vCore、11GB内存,但是YARN上看到的已分配掉的资源是9个vCore、12.38GB内存,多出来的1.38GB内存是做什么用的?
- Spark使用的资源只占用了YARN可以支配的资源的一小部分,也就说该集群大部分资源处于闲置状态。
这三个问题将分别在下文进行分析与阐述,进而得出最佳的资源分配方式。
3. 常见的EMR机器资源情况
作为云服务,AWS EMR根据每种机器的特性等因素帮助我们预设好YARN可以支配的资源,即上文提到的yarn-site.xml中的两个参数。当然,我们也可以根据业务需要进行调整,大多数情况下我们会基于这些配置来进行资源估算,那么搞清楚AWS EMR设置这些参数的方法与规律就很重要。我们将其归纳如下:
- 对于M4系列机器,YARN vCores = 2 * EC2 vCPUs
- 对于C4/R4系列机器,YARN vCores = EC2 vCPUs
- EMR会预留1/4的内存,最大预留8GB,最小2GB
基于此,对于3台M4.xlarge机器,YARN总共可以支配的资源为vCore = 3 * (2 * 4) = 24,内存 = 3 * (3/4 * 16) = 36GB,这就解释了第2节中的第1个问题。

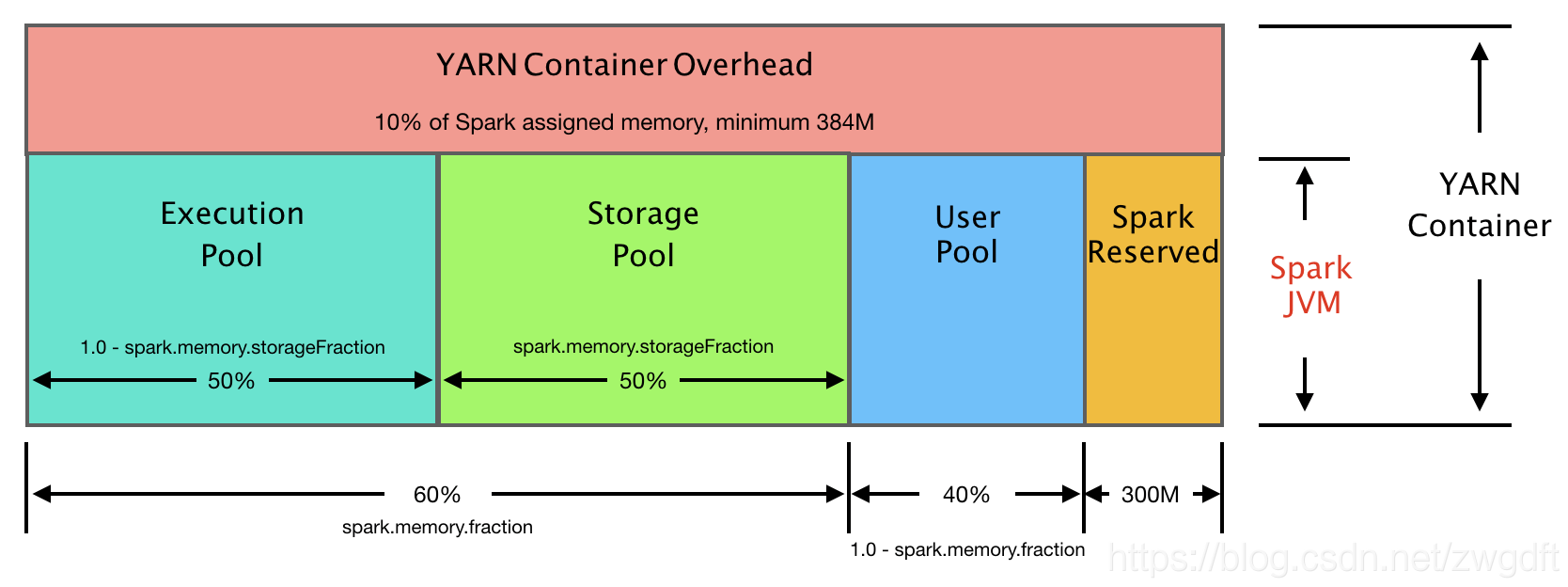
4. YARN Container Overhead
Spark内存模型还蛮复杂的,本文不会就此展开,主要关注的是Container Overhead。Spark的Driver和Executor是跑在YARN Container里面的,其本身是一个JVM程序。我们在Spark中对Driver和Executor进行的配置仅仅考虑的是Spark层面的资源需求,在这之上还有YARN Container JVM本身需要一些内存。默认情况下,其大小是分配给Driver或Executor的内存的10%,最小为384MB,可以通过下面两个参数进行调整:
- spark.yarn.driver.memoryOverhead
- spark.yarn.executor.memoryOverhead
基于此,如果Spark需要的资源是9个vCore、11GB内存,那么实际YARN上看到的资源使用情况应该是9个vCore、12.38GB内存,这也解释了第2节中的第2个问题。
5. 合理分配资源的方法
有了上文的基础,我们就可以来探讨合理分配资源的方法了,其本质是如何计算第1节提到的Spark的5个参数,确保一个集群的可用资源都被利用起来。
基本思路是先从Executor入手,然后拿掉一个Executor换成Driver即可。
对Executor进行资源分配时,首先考虑vCore因素,重点考虑两点:
- Executor数量需要适中。过多会带来很重的额外开销;过小会导致容错性差,比如一个Executor挂了会导致很多Task一起失败。
- 所选的不同规格的机器中最小规格的vCore个数,即最小粒度问题。
通常,对于M4系列机器,我们推荐单个Executor的vCore = 4。有了这个值,就可以计算整个集群可以承载多少个Executor了,即M = 总共的YARN vCores / 单个Executor vCores。进一步可以计算出单个Executor的内存大小,即总共的YARN vCores / 1.1 / M,这里采用了默认的10%比例作为Container Overhead。
完成上述计算后,我们拿出一个Executor的资源,作为Driver的资源大小,将Executor的个数设置为M-1即可。Driver也许用不掉那么多资源,但是即使不用这部分资源也没法再分配一个新的Executor了,所以这部分资源可以全部给Driver,也可以归还部分给系统。通常情况下,Driver拥有此资源就足够了,如果有下面的情况,可以酌情考虑增加内存。
- 有很大的数据需要回收到Driver
- 需要加载的文件的Partition很多,导致需要构建一个很大的InMemoryFileIndex
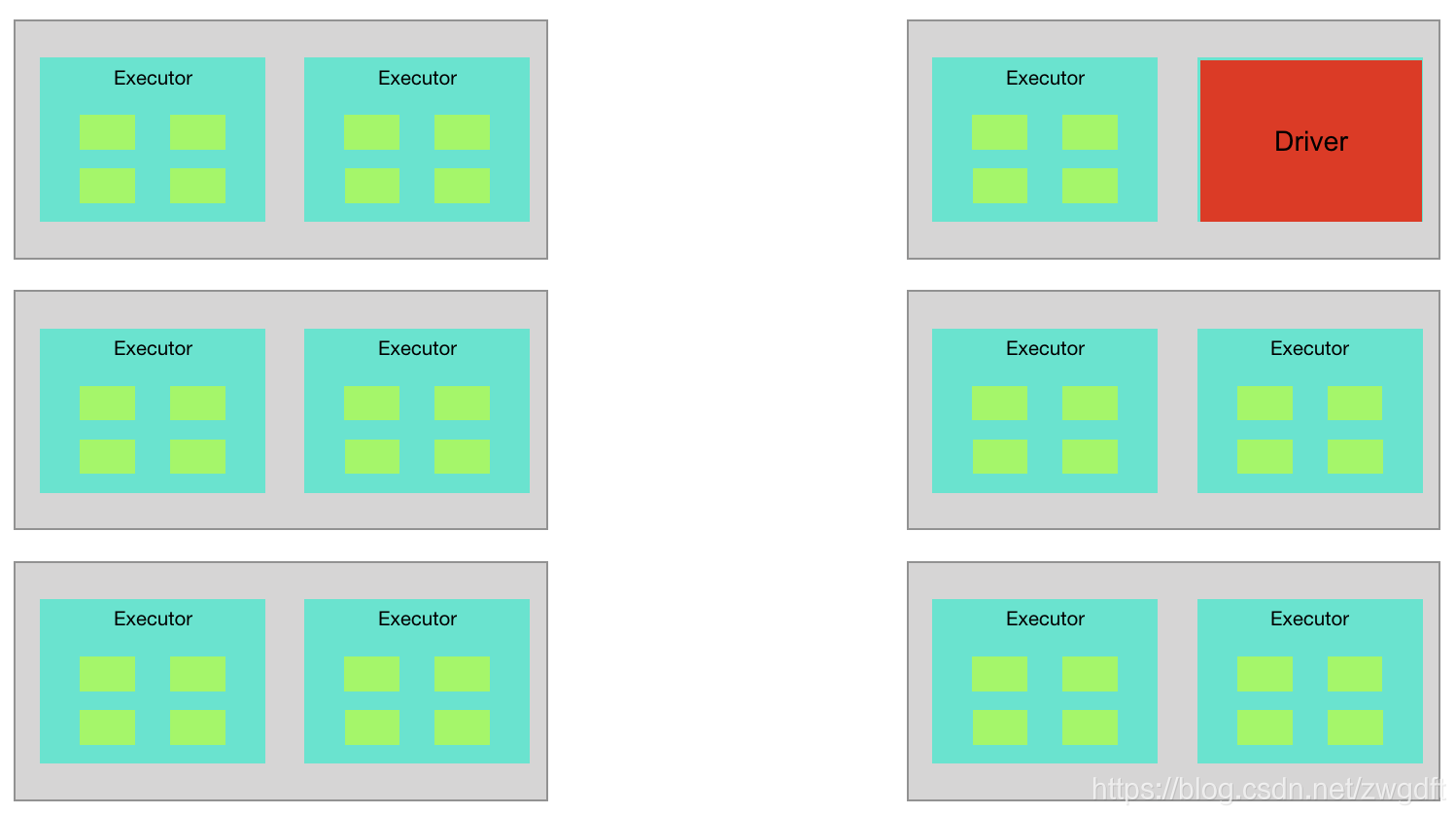
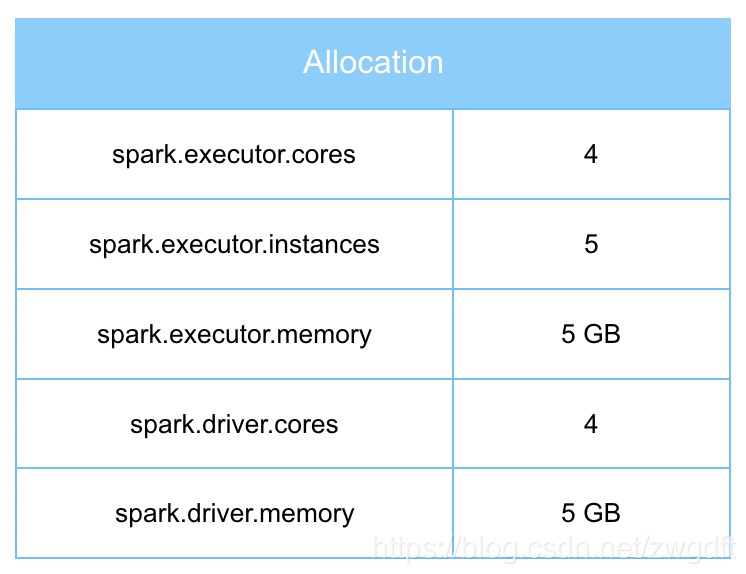
继续以第2节中的例子为例,参照上述计算方法,相关参数应该如下图表所示,共使用了24个vCores,33GB内存的资源,达到了最大利用率。
本文阐述的思路与方法虽然是应用在AWS EMR下,但是可以酌情参考应用在其他场景,期望对同道中人有所帮助。
(全文完,本文地址:https://bruce.blog.csdn.net/article/details/105037575 )
版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!
Bruce
2020/03/28 晚
智能推荐
IDEA使用statistic统计代码的行数【可以辅助读源码和自己写的代码的行数】_staic工具统计源码行数-程序员宅基地
文章浏览阅读7.3k次。statistic插件在IDEA上下载不成功可以将这个包复制到idea的plugin中,重启idea就可以了链接:https://pan.baidu.com/s/1uKtlM11gktNYUdpAPRAW5w 密码:rvxx安装成功以后查看行数如下图安装成功点击右下角的statistic,发现没有内容,然后再点击截图中的refresh就可以查看了。..._staic工具统计源码行数
用PyTorch写的python脚本,程序执行结束后,不自动终止_win7 python无法自动结束问题-程序员宅基地
文章浏览阅读1k次。问题描述:用 PyTorch 写的一个python 脚本,脚本内容执行结束后,程序不能正常结束,按Ctrl + C也没用!!(虽然这个bug似乎对实验结果没什么影响,但是,很影响心情有没有,我居然不能控制自己写的代码……)究竟是哪里出了问题??经过筛查,发现问题是下面这句代码引起的:loss.backward()如何解决?直接删了肯定不行,模型还跑不跑了,一通搜索之后,我似乎找到了解决办法 :网友解答附录:看完上面那个链接内容之后,你大概率会笑喷,或许这就是作为程序员的_win7 python无法自动结束问题
数据采集中的采样率、缓冲区大小以及,每通道采样数之间的关系_每通道采样数和采样率-程序员宅基地
文章浏览阅读1.7w次,点赞13次,收藏58次。采样率:每秒钟才多少次 每通道采样数:指的是每次从通道读取的数据长度,其实是从buffer里面读取。如果每次读的太少,读取时间间隔长那么buffer数据堆积会导致溢出。因此buffer size应该大于数据读取间隔*采样率。形象一点,buffer就是一个桶,采集端是往里面倒水的,采样率就是这个进口的水流速度。读取端是往外抽水的,每通道的采样数和读取间隔决定了出水速度,你的任务是保证水桶不会..._每通道采样数和采样率
HTML网页设计制作——响应式网页影视动漫资讯bootstrap网页(9页)_要求: (1)请将所提供的picturecarousel.html文件复制到自己所创建的项目下,并根-程序员宅基地
文章浏览阅读370次,点赞6次,收藏6次。1 网页简介:此作品为学生个人主页网页设计题材,HTML+CSS 布局制作,web前端期末大作业,大学生网页设计作业源码,这是一个不错的网页制作,画面精明,代码为简单学生水平, 非常适合初学者学习使用。2.网页编辑:网页作品代码简单,可使用任意HTML编辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad++ 等任意html编辑软件进行运行及修改编辑等操作)。3.知识应用:技术方面主要应用了网页知识中的: Div+CSS、鼠标滑_要求: (1)请将所提供的picturecarousel.html文件复制到自己所创建的项目下,并根
mybatis-plus代码生成_tenantdatasourceglobalconfiguration-程序员宅基地
文章浏览阅读208次。代码生成器主类GenteratorCodeimport com.baomidou.mybatisplus.generator.AutoGenerator;import com.baomidou.mybatisplus.generator.InjectionConfig;import com.baomidou.mybatisplus.generator.config.*;import com.baomidou.mybatisplus.generator.config.converts.MySqlTy_tenantdatasourceglobalconfiguration
RichFaces 大概-程序员宅基地
文章浏览阅读74次。.RichFaces组件包RichFaces 4.x包含的4个jar包如表1-2所示。表1-2 RichFaces 4.x包含的4个jar包包 名描 述 richfaces-core-api-<版本名称>.jarRichFaces的核心包 richfaces-core-impl-<版本名..._mojarra 2.2.8作用
随便推点
qemu: usb存储设备仿真_qemu usb-程序员宅基地
文章浏览阅读1w次。qemu既支持仿真虚拟的usb存储设备,也支持连接真实的设备(如U盘)。相关的命令参数为:-usb-device usb-storage,drive=drive_id-device usb-uas-device usb-bot-device usb-host,hostbus=bus,hostaddr=addr-device usb-host,vendorid=vendor,produc..._qemu usb
Pm命令用法_pm install-程序员宅基地
文章浏览阅读5.8k次。Pm命令用法1. Pm主要命令2. 详细参数2.1 list packages2.2 pm install2.3 其他参数 在公司的Linux环境下目前不能使用adb命令,需要使用pm命令,因此写一篇文章学习一下,pm命令主要应用在安装APK的时候。1. Pm主要命令命令格式:pm <command>命令列表:命令功能实现方法list packages列举app包信息PMS.getInstalledPackagesinstall [options]_pm install
DELL Latitude E5400 装了PC DOS 7.1系统启动不了-程序员宅基地
文章浏览阅读139次。DELL Latitude E5400 装了PC DOS 7.1因为ghost死机关机随后重启显示进入PC DOS 7.1Startup menu 1.Run Norton Ghost Dos Operation2.Return to windows without running Norton GhostEnter a choice:1..._dos7.1运行不了
uboot中mtest命令的用法(针对DDR3)_uboot ddr测试命令mm test-程序员宅基地
文章浏览阅读9.7k次。http://www.deyisupport.com/question_answer/dsp_arm/sitara_arm/f/25/t/122354.aspxRun mtestSimple memory test can be run from the U-Boot prompt using the mtest command. The syntax of the comma_uboot ddr测试命令mm test
Linux的IPC命令-程序员宅基地
文章浏览阅读599次。进程间通信概述 进程间通信有如下的目的:1、数据传输,一个进程需要将它的数据发送给另一个进程,发送的数据量在一个字节到几M之间;2、共享数据,多个进程想要操作共享数据,一个进程对数据的修改,其他进程应该立刻看到;3、通知事件,一个进程需要向另一个或一组进程发送消息,通知它们发生了某件事情;4、资源共享,多个进程之间共享同样的资源。为了做到这一点,需要内核提供锁和同步机制;5、进程控制,..._linux的命令ipc
注意力机制SE、CBAM、ECA、CA的优缺点_ca注意力机制和cbam注意力机制哪个好-程序员宅基地
文章浏览阅读1.7w次,点赞27次,收藏198次。注意力机制模块可以帮助神经网络更好地处理序列数据和图像数据,从而提高模型的性能和精度。_ca注意力机制和cbam注意力机制哪个好