Pytorch学习 for hw3(2)Logisitic Regression_不归一化容易发散-程序员宅基地
技术标签: 机器学习 pytorch Hong _YiLi
文章目录
逻辑回归是由概率公式推导产生的,常用来做分类任务,拿手写数字辨识1-10为例:通过计算max{ P ( x = 0 ) , P ( x = 1 ) , . . . , P ( x = 9 ) P(x=0),P(x=1),...,P(x=9) P(x=0),P(x=1),...,P(x=9)},找出最大的概率值即为该x对应的类别。
1、Logisitic Regression
(1)前言
介绍一种下载数据集的方法,但是本次案例未使用到。
在安装pytorch时,有个torchvison工具包可以提供一些比较流行的数据集如MNISIT Dataset(手写数字数据),CIFAR-10(32╳32像素的像图片),但是需要在网上下载,下载方法如下:
import torchvision
train_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=True, download=True)
test_set = torchvision.datasets.MNIST(root='D:/py文件/Hong YiLee/homework3/dataset/mnist', train=False, download=True)
root:若未下载过则标明下载地址,已经下载过则标明数据所在位置
train=True:表示提取的是training data,=False表示提取的是testing data
download=True:表示将在往网上下载,=False表示从本机提取
运行结果如下,就是速度有点慢(开了VPN也慢)

由于是分类问题所以,本次实例和上次的略有区别:现有三个输入x,对应两个分类y=0和y=1,求输入为4时,输出y为多少。
| x | y |
|---|---|
| 1.0 | 0 |
| 2.0 | 0 |
| 3.0 | 1 |
| 4.0 | ? |
所以,进而将问题简化为二分类问题即求P(y=0)、P(y=1),且P(y=1)=1-P(y=0),若P(y=0)>0.5那么y=0。由于P(y=0)可能接近0.5,那么在这种情况下分类器对于该x的类别是不确定的,应该输出“不确定”。
(2)知识点介绍:
可以将二分类问题简化为输出为[0,1]之间的回归问题。那么我们只需要将的线性回归的输出映射到[0,1]即可,而sigmiod函数恰好满足:定义域为(-∞,+∞),值域为(0,1)。当输出y>0.5则被归为1,小于0.5则被归为0。损失函数选用由概率推导出来的cross entropy(交叉熵),简称BCE(Binary Cross Entropy),最后要求和取平均值(对loss求导数的时候1/N会影响lr的大小,加上则不用将lr调的过大)。

torch.nn.BCELoss的参数详解点击链接
torch.nn.Functional的模块包含很多函数,其中有sigmoid函数,我使用的pytorch1.7.1版本已经弃用这种方法,可直接使用torch.sigmoid()
(3)完整代码:
(和Linear Regression差不多)
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
class LogisticRegressionModel(torch.nn.Module):
# 初始化
def __init__(self):
# 初始化从torch.nn.Module继承的属性
super(LogisticRegressionModel, self).__init__()
# 设置实例属性self.linear
self.linear = torch.nn.Linear(1, 1)
# 定义实例方法,添加输入x
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = torch.nn.BCELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for i in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出如下:
能看出随迭代次数的增加loss值在减小,最后一次的loss值为1.0836951732635498。
0 2.484407901763916
1 2.4654228687286377
2 2.44744610786438
3 2.4304330348968506
4 2.4143383502960205
5 2.399118423461914
测试对x=4的y的分类,结果y_pred =0.8407>0.5 所以分类正确
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
# y_pred = tensor([[0.8407]])
(4)查看y(是否通过考试)对x(每日的学习时间)的函数
(实际上并不是函数,是在取多个点之后的预测值绘制的图像)
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 200) # 取1-10之间等间距的200个点,并组成一个列表
x_t = torch.Tensor(x).view((200, 1)) # 将1行的列表转为200行1列的列向量
y_t = model(x_t) # 输入x,调用logistic model
y = y_t.data.numpy() # 将y_data转化为numpy数据才能进行画图
plt.plot(x, y)
plt.plot([0, 10], [0.5, 0.5], c='r') # 画出分界线
plt.xlabel('Hours')
plt.ylabel('Possibility of pass')
plt.grid() # 画出背景网格线
plt.show() # 显示图
由于一使用plt.plot就出现下面的错误
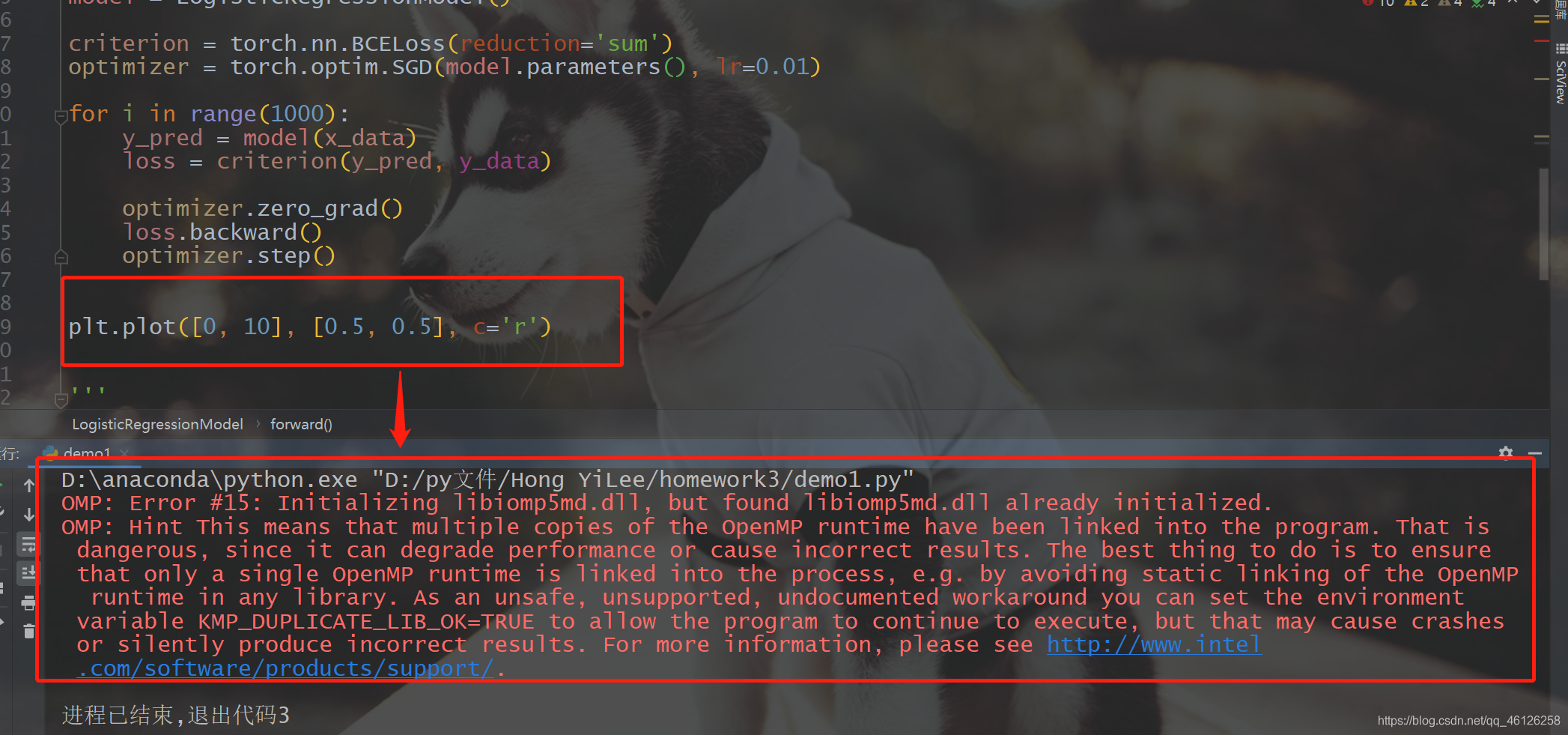
所以添加了一句,问题就解决了
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
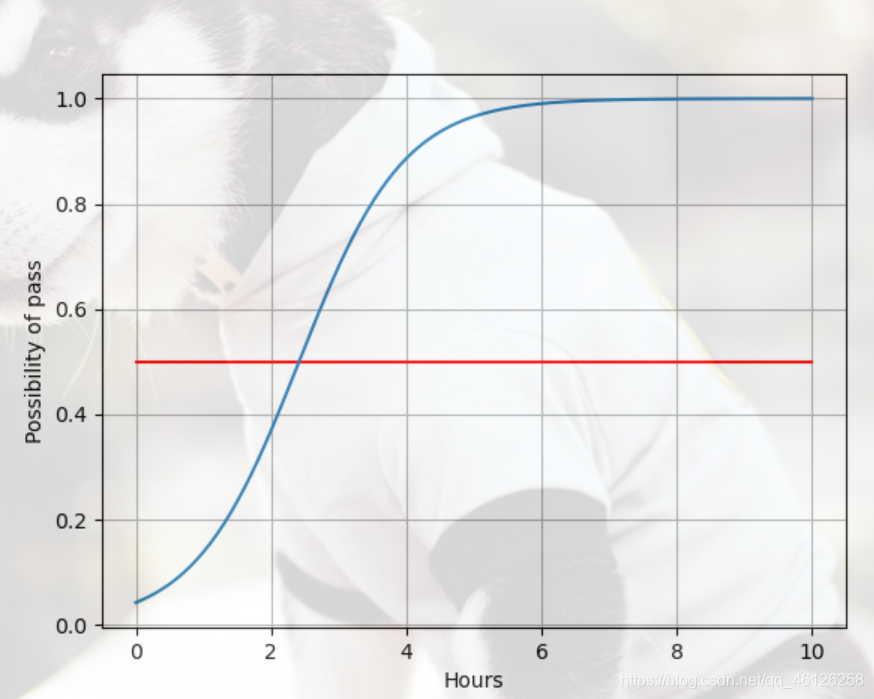
结果如下,可以看到当学习时间为两个小时多的时候就会使possibility达到0.5,也就是y的取值为1,自然当x=4时y的取值也为1.
2、多层神经网络的连接
一层的时候运算过程如下:

可以将单个函数的运算拼成矩阵相乘,进而能够使用GPU加速运算过程。torch.nn.Linear(8,1)表示输入x有8列特征,输出y有1列。

当有三层的时候,可以将矩阵乘法看成维度转换的函数,只需要改变torch.nn.Linear()的参数就可以实现两层神经网络的连接单元数如下:

(1)二分类
在二分类中我们用到糖尿病的数据集(diabetes),通过8个特征辨别其是否患有糖尿病,患病输出y=1,否则y=0。
一、数据集的准备
下载链接:https://pan.baidu.com/s/1udhg5-pvS6UsQlpawmd8-w
提取码: itm0
打开文件如下

开始分离x、y
import numpy as np
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
二、根据继承的模块定义model类
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
三、设置loss和optimizer
由于size_average已经被弃用,所以使用reduction='mean’代替来求取平均值。
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
四、迭代更新
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
输出结果:
0 0.7159094214439392
1 0.7150604128837585
2 0.7142216563224792
3 0.7133930325508118
4 0.7125746011734009
5 0.7117661237716675
最后的loss值为 0.6668325662612915,当迭代次数达到1000次时,loss值为0.6445940732955933,并趋于稳定。
五、完整代码:
import torch
import numpy as np
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__() # 初始化从Module继承的方法
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.activation(self.linear3(x))
return x
model = Model()
xy = np.loadtxt('E:\\自制笔记\\课外\\PyTorch深度学习实践\\diabetes.csv.gz', delimiter=',', dtype=np.float32)
x = torch.from_numpy(xy[:, :-1]) # 取所有行的前8列,并转化为tensor
y = torch.from_numpy(xy[:, [-1]]) # 取所有行的的最后一列
print(x.shape, y.shape)
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
(2)回归问题
下面的案例是根据sklearn的diabetes数据集来做的回归问题。已知影响糖尿病的10列特征,和对应的target,查看随训练的变化loss的变化。
一、数据集准备:
如果安装了sklearn的话,在anaconda文件夹下能找到下图的路径,里面有自带的数据集,如我的位置是D:\anaconda\Lib\site-packages\sklearn\datasets\data
查看输入x: 打开之后发现WPS和excel并不能将每一列分割(只有两列间为" , "数据才能被分割,这里的是空格所以不能被分割为单独的列)

对应的y如下:
其中最小的为25,最大的为346 ,所以先对y进行归一化处理。不进行归一化结果会发散,loss值会很大。
import torch
import numpy as np
np.random.seed(0) #当我们设置相同的seed,每次生成的随机数相同
print()
# 按照sklearn中包的位置将数据读取出来
x = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_data.csv.gz', delimiter=' ',
dtype=np.float32)
y = np.loadtxt('D:\\anaconda\\Lib\site-packages\\sklearn\\datasets\\data\\diabetes_target.csv.gz', delimiter=' ',
dtype=np.float32)
y = y.reshape(-1, 1) #转为一列
#归一化处理
mean_y = np.mean(y, axis = 0)
std_y = np.std(y, axis = 0)
for i in range(len(y)):
if std_y[0] != 0:
y[i][0] = (y[i][0] - mean_y[0]) / std_y[0]
#创建两个tensor
x = torch.from_numpy(x)
y = torch.from_numpy(y)
# 将数据的行数打乱
def _shuffle(X, Y):
# This function shuffles two equal-length list/array, X and Y, together.
randomize = np.arange(len(X))
np.random.shuffle(randomize)
return (X[randomize], Y[randomize])
x, y = _shuffle(x, y)
二、根据继承的模块定义model类
与二分类类似,但是由于y的输出不再是单个的类别(0、1),所以最后一层不能使用激活函数限制他的值域。
class Model(torch.nn.Module):
# 初始化,并定义激活函数
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(10, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.activation = torch.nn.Sigmoid()
# 最后一层不要添加激活函数,否则最后的值域会被限制
def forward(self, x):
x = self.activation(self.linear1(x))
x = self.activation(self.linear2(x))
x = self.linear3(x)
return x
model = Model()
三、设置loss和optimizer
criterion = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
四、迭代更新
for i in range(100):
y_pred = model(x)
loss = criterion(y_pred, y)
print(i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
结果如下:
0 1.1163854598999023
1 1.0310304164886475
2 1.0081417560577393
3 1.001995325088501
4 1.0003454685211182
随迭代次数增加loss变小,最后趋于稳定为0.9996225833892822
智能推荐
Docker 快速上手学习入门教程_docker菜鸟教程-程序员宅基地
文章浏览阅读2.5w次,点赞6次,收藏50次。官方解释是,docker 容器是机器上的沙盒进程,它与主机上的所有其他进程隔离。所以容器只是操作系统中被隔离开来的一个进程,所谓的容器化,其实也只是对操作系统进行欺骗的一种语法糖。_docker菜鸟教程
电脑技巧:Windows系统原版纯净软件必备的两个网站_msdn我告诉你-程序员宅基地
文章浏览阅读5.7k次,点赞3次,收藏14次。该如何避免的,今天小编给大家推荐两个下载Windows系统官方软件的资源网站,可以杜绝软件捆绑等行为。该站提供了丰富的Windows官方技术资源,比较重要的有MSDN技术资源文档库、官方工具和资源、应用程序、开发人员工具(Visual Studio 、SQLServer等等)、系统镜像、设计人员工具等。总的来说,这两个都是非常优秀的Windows系统镜像资源站,提供了丰富的Windows系统镜像资源,并且保证了资源的纯净和安全性,有需要的朋友可以去了解一下。这个非常实用的资源网站的创建者是国内的一个网友。_msdn我告诉你
vue2封装对话框el-dialog组件_<el-dialog 封装成组件 vue2-程序员宅基地
文章浏览阅读1.2k次。vue2封装对话框el-dialog组件_
MFC 文本框换行_c++ mfc同一框内输入二行怎么换行-程序员宅基地
文章浏览阅读4.7k次,点赞5次,收藏6次。MFC 文本框换行 标签: it mfc 文本框1.将Multiline属性设置为True2.换行是使用"\r\n" (宽字符串为L"\r\n")3.如果需要编辑并且按Enter键换行,还要将 Want Return 设置为 True4.如果需要垂直滚动条的话将Vertical Scroll属性设置为True,需要水平滚动条的话将Horizontal Scroll属性设_c++ mfc同一框内输入二行怎么换行
redis-desktop-manager无法连接redis-server的解决方法_redis-server doesn't support auth command or ismis-程序员宅基地
文章浏览阅读832次。检查Linux是否是否开启所需端口,默认为6379,若未打开,将其开启:以root用户执行iptables -I INPUT -p tcp --dport 6379 -j ACCEPT如果还是未能解决,修改redis.conf,修改主机地址:bind 192.168.85.**;然后使用该配置文件,重新启动Redis服务./redis-server redis.conf..._redis-server doesn't support auth command or ismisconfigured. try
实验四 数据选择器及其应用-程序员宅基地
文章浏览阅读4.9k次。济大数电实验报告_数据选择器及其应用
随便推点
灰色预测模型matlab_MATLAB实战|基于灰色预测河南省社会消费品零售总额预测-程序员宅基地
文章浏览阅读236次。1研究内容消费在生产中占据十分重要的地位,是生产的最终目的和动力,是保持省内经济稳定快速发展的核心要素。预测河南省社会消费品零售总额,是进行宏观经济调控和消费体制改变创新的基础,是河南省内人民对美好的全面和谐社会的追求的要求,保持河南省经济稳定和可持续发展具有重要意义。本文建立灰色预测模型,利用MATLAB软件,预测出2019年~2023年河南省社会消费品零售总额预测值分别为21881...._灰色预测模型用什么软件
log4qt-程序员宅基地
文章浏览阅读1.2k次。12.4-在Qt中使用Log4Qt输出Log文件,看这一篇就足够了一、为啥要使用第三方Log库,而不用平台自带的Log库二、Log4j系列库的功能介绍与基本概念三、Log4Qt库的基本介绍四、将Log4qt组装成为一个单独模块五、使用配置文件的方式配置Log4Qt六、使用代码的方式配置Log4Qt七、在Qt工程中引入Log4Qt库模块的方法八、获取示例中的源代码一、为啥要使用第三方Log库,而不用平台自带的Log库首先要说明的是,在平时开发和调试中开发平台自带的“打印输出”已经足够了。但_log4qt
100种思维模型之全局观思维模型-67_计算机中对于全局观的-程序员宅基地
文章浏览阅读786次。全局观思维模型,一个教我们由点到线,由线到面,再由面到体,不断的放大格局去思考问题的思维模型。_计算机中对于全局观的
线程间控制之CountDownLatch和CyclicBarrier使用介绍_countdownluach于cyclicbarrier的用法-程序员宅基地
文章浏览阅读330次。一、CountDownLatch介绍CountDownLatch采用减法计算;是一个同步辅助工具类和CyclicBarrier类功能类似,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。二、CountDownLatch俩种应用场景: 场景一:所有线程在等待开始信号(startSignal.await()),主流程发出开始信号通知,既执行startSignal.countDown()方法后;所有线程才开始执行;每个线程执行完发出做完信号,既执行do..._countdownluach于cyclicbarrier的用法
自动化监控系统Prometheus&Grafana_-自动化监控系统prometheus&grafana实战-程序员宅基地
文章浏览阅读508次。Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,_-自动化监控系统prometheus&grafana实战
React 组件封装之 Search 搜索_react search-程序员宅基地
文章浏览阅读4.7k次。输入关键字,可以通过键盘的搜索按钮完成搜索功能。_react search