MapReduce是一个用于大规模数据处理的分布式计算模型,最初由Google工程师设计并实现的,Google已经将完整的MapReduce论文公开发布了。其中的定义是,MapReduce是一个编程模型,是一个用于处理和生成大规模数据集的...
”MapReduce“ 的搜索结果
您将使用MapReduce为每个城市提供该城市中的星巴克数量。 输入是一个csv文件starbucks-locations.csv,输出应该是一个文件cityInformation,其中每行代表一个城市以及该城市中的星巴克数量。 第2部分:倒排索引 您...
(实践三)MapReduce 布隆过滤器 过滤器训练、过滤器应用、结果验证及分析 (实践四)MapReduce Top 10模式示例 在ctrip数据集上进行Top 10排序。 (实践五)去重的用户—针对ctrip数据集去重 对ctrip数据集中的...
(2)打开网站localhost:8088和localhost:50070,查看MapReduce任务启动情况 (3)写wordcount代码并把代码生成jar包 (4)运行命令 (1):把linus下的文件放到hdfs上 (2):运行MapReduce (5):查看运行结果 ...
目的: 分析 MR (MapReduce) 作业的执行流程。流程维度: 从节点、状态节点、角色进程等角度进行分析。
} ...import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;...import org.apache.hadoop.mapreduce.
需要反射调用空参构造函数,所以必须有空参构造(3)重写序列化和反序列化方法,同时要求顺序一致(4)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key...
4 分别在自编 MapReduce 程序 WordCount 运行过程中和运行结束后查看 MapReduce Web 界面。 5. 分别在自编 MapReduce 程序 WordCount 运行过程中和运行结束后练习 MapReduce Shell 常用命令。 。。
MapReduce 初级编程实践 姓名: 实验环境: 操作系统:Linux(建议Ubuntu16.04); Hadoop版本:3.2.2; 实验内容与完成情况: (一)编程实现文件合并和去重操作 对于两个输入文件,即文件 A 和文件 B,请...
倒排索引代码实现
} ...import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;...import org.apache.hadoop.mapreduce.
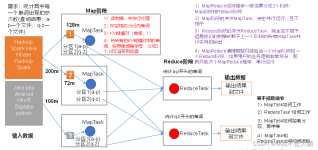
MapReduce详解MapReduce介绍MapReduce的基本编程模型MapReduce的计算过程1. Map阶段可以概括为5个步骤:2. Reduce节点也可以分为5个步骤:设置ReduceTask并行度(个数)关于分片(Split)关于ShuffleMap端的...
一、神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。但对许多开发者来说,自己完完全全实现一...
【MapReduce篇07】MapReduce之数据清洗ETL1
赠送jar包:hadoop-mapreduce-client-jobclient-2.6.5.jar; 赠送原API文档:hadoop-mapreduce-client-jobclient-2.6.5-javadoc.jar; 赠送源代码:hadoop-mapreduce-client-jobclient-2.6.5-sources.jar; 赠送...
MapReduce相关知识
标签: 笔记
每个Reduce任务都会生成自己的输出文件,它们的输出是独立的,并且在作业完成后,多个Reduce任务之间不会直接合并它们的结果,你可能需要其他的工具或步骤来合并或进一步处理这些输出文件。(1)Map任务的数量:由...
/把业务逻辑相关的信息(哪个是 mapper,哪个是 reducer,要处理的数据在哪里,输出的结果放在哪里……//System.out.println(“π的近似值为”+sumOrder;System.out.println(“请输入你想分的片数:”)//按照分片生成...
一 MapReduce入门 1.1 MapReduce定义 Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架; Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的...
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程...
近年来出现的MapReduce计算框架能够以简洁的形式和分布式的方案来解决大规模数据的并行处理问题,得到了学术界和工业界的广泛认可和使用。目前,MapReduce已经被用于自然语言处理、机器学习及大规模图处理等领域。该文...
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序1)输入数据接口:InputFormat—>FileInputFormat(文件...
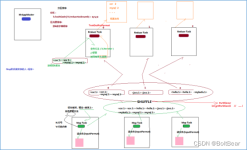
Hadoop 集群常驻进程,根据要处理的输入数据量,命令 TaskTracker生成相应...该进程是启动 MapReduce 程序的主入口,主要是指定 Map 和 Reduce 类、输入输出文件路径等,并提交作业给 Hadoop 集群。三、MapReduce操作。
用戶編寫的MapReduce程序通過Client提交到JobTracker端;同時,用戶可通過Client提供的一些接口查看作業運行狀態。在Hadoop內部用“作業” (Job)表示MapReduce程序。每一個Job都會在用戶端通過Client類將應用程序...
基于MapReduce+Pandas的电影排名与推荐以及数据分析与可视化展示
public class CarReduce extends Reducer { } ...import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs....
互联网大厂比较喜欢的人才特点:对技术有热情,强硬的技术基础实力;主动,善于团队协作,善于总结思考。无论是哪家公司,都很重视高并发高可用技术,重视基础,所以千万别小看任何知识。面试是一个双向选择的过程,...
1、传统的海量数据分析方案 2、Apache Hadoop项目 3、HDFS设计 4、MapReduce 5、Pig & Hive 6、Spark ……
MapReduce应该算是MongoDB操作中比较复杂的了,下面这篇文章主要给大家介绍了关于MongoDB中MapReduce使用的相关资料,文中通过示例代码介绍的非常详细,需要的朋友可以参考借鉴,下面随着小编来一起看看吧。
推荐文章
- Android 编译so文件 MP4V2_android下编译mp4v2-程序员宅基地
- 通讯录Contact_02_contact文件内容-程序员宅基地
- Qt笔记(四十二)之QZXing的编译 配置 使用_qzxingfilterrunnable error:-程序员宅基地
- 关于画图软件Dia打开程序始终为英文界面的问题-程序员宅基地
- OpenCV从入门到精通实战(二)——文档OCR识别(tesseract)-程序员宅基地
- 详解avcodec_receive_packet 11_avcodec_receive_packet eagain-程序员宅基地
- OpenGL SuperBible 7th源码编译记录_superbible7-media github-程序员宅基地
- Wireshark简单使用-程序员宅基地
- MXNet 粗糙的使用指南_iou loss mxnet-程序员宅基地
- iOS对ipa包进行代码混淆《二》 ---代码混淆_ipa包混淆-程序员宅基地