HTML解析库BeautifulSoup4 HTML解析库BeautifulSoup4!!!
”beautifulsoup“ 的搜索结果
BeautifulSoup库使用解析一、前言二、使用引入库创建beautifulSoup对象类型BeautifulSoup类型Tag类型 一、前言 BeautifulSoup是一个html文档解析库,在爬虫解析数据时,十分有用。接下来记录下它的用法。 二、使用 ...
这个代码的作用是使用Requests库和Selenium库与BeautifulSoup库结合,完成了以下任务: 使用Requests库发送HTTP GET请求,获取指定URL的网页内容。 使用BeautifulSoup解析网页内容,提取网页的标题和所有链接的文本...
BeautifulSoup4是爬虫必学的技能。BeautifulSoup最主要的功能是从网页抓取数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。BeautifulSoup支持Python标准库中的HTML解析器,还支持...
beautifulsoup4-4.5.1.tar.gz Beautiful Soup是一个Python的一个库,主要为一些短周期项目比如屏幕抓取而设计。有三个特性使得它非常强大: 1.Beautiful Soup提供了一些简单的方法和Python术语,用于检索和修改语法...
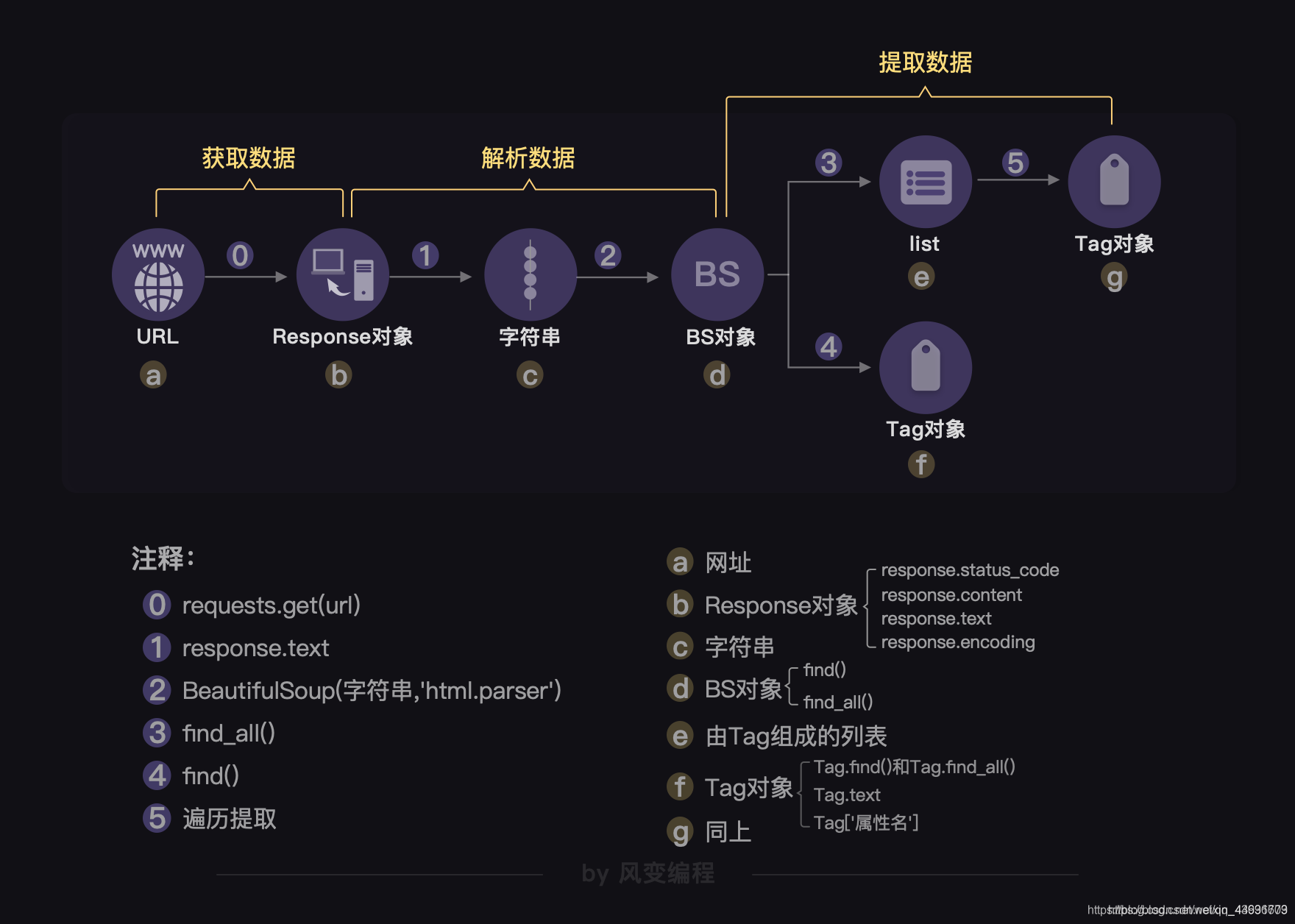
BeautifulSoup有五种基本元素,分别是标签(Tag),标签名(Name),标签的属性(Attribute),标签内非属性字符串(NavigableString)以及标签内的注释部分(Comment)。理解好BeautifulSoup库的五种基本元素是使用...




Beautiful Soup的简介 Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下: 1、Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。...
解析利器beautifulsoup4库;beautifulsoup4库也称为Beautiful Soup库或bs4库,用于解析和处理HTML和XML文件,其最大优点是能够根据HTML和XML语法建立解析树,进而提高解析效率。;由于beautifulsoup4库是第三方库,...
BeautifulSoup 对象是使用 BeautifulSoup 构造函数创建的,通常将解析器的名称和要解析的文档作为参数传递给构造函数。Tag 对象表示 HTML 或 XML 中的标签,例如、、等,Tag对象可 以包含其他标签、文本内容和属性,...
要在Python中删除DOM节点,你需要使用一个库,如BeautifulSoup或lxml。这里是一个使用BeautifulSoup的例子。首先,确保你已经安装了BeautifulSoup库。如果尚未安装,请使用以下命令安装:然后在Python代码中,你可以...
BeautifulSoup库是python中常用的的网页解析库,灵活,高效,支持多种解析器。可以很方便地实现网页信息的提取。

Scrapy和BeautifulSoup的区别
BeautifulSoup是一个Python第三方库,用于解析HTML和XML文档。...使用BeautifulSoup,...BeautifulSoup还可以处理编码问题,自动将文档中的编码转换为Unicode编码。BeautifulSoup常用于爬虫、数据抓取、数据清洗等场景。

首先,确保你已经安装了requests和beautifulsoup4这两个库。你可以使用pip来安装它们: pip install requests beautifulsoup4 这个脚本定义了一个fetch_page_title函数,它接受一个URL作为参数,并发送一个GET请求...
是爬虫必学的技能。最主要的功能是从网页抓取数据,自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码,不需要考虑编码方式,除非文档没有指定一个编码方式,这时,就不能自动识别编码方式了,然后,仅仅...

一实例html bs4.html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>...div id = "id1" name = "div1" class = "...

BeautifulSoup 查找文档元素 查找 HTML 元素 获取元素的属性值 获取元素包含的文本值 高级查找


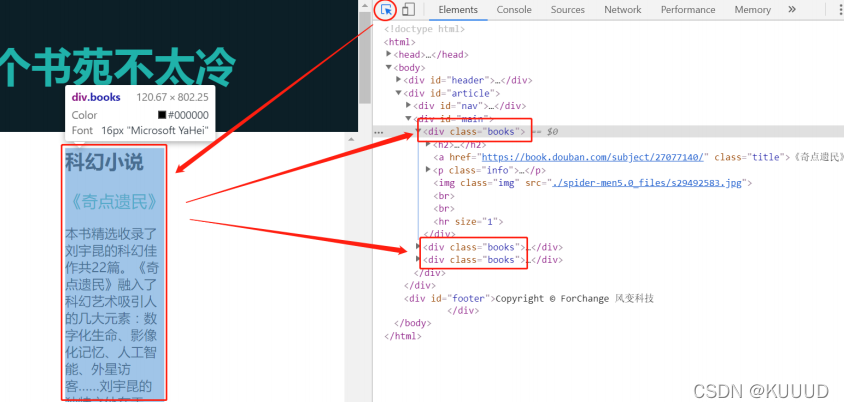
关于BeautifulSoup爬的使用这里我们可以简单的介绍下,BeautifulSoup是python的一个库,最主要的功能是从网页抓取数据,在抓取的过程中会使用到一些功能。爬取数据案例如下,这里以访问豆瓣为需求,因为豆瓣的反爬...
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地