
”gpu“ 的搜索结果

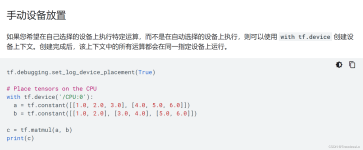
本文基于PyTorch通过tensor点积所需要的时间来对比GPU与CPU的计算速度,并介绍tensorboard的使用方法。



GPU — GPU 虚拟化技术
标签: GPU

让各位久等了,阿里小二这就开始上新菜:“GPU分片虚拟化”。 对于“分片”的理解,相信大家已经不陌生了。此处的分片从两个维度上来定义:其一,是对GPU在时间片段上的划分,与CPU的进程调度类似,一个物理GPU的...
阿里云郑晓:浅谈GPU虚拟化技术(第一章)GPU虚拟化发展史阿里云郑晓:浅谈GPU虚拟化技术(第二章)GPU虚拟化方案之——GPU直通模式今天一个小伙伴@我说:“你浅谈一下,没点技术背景的,估计都看不懂…”,醍醐灌顶...
主要介绍了CUDA,cuDNN的安装,以及在anaconda的虚拟环境中安装pytorch

pytorch 查看NVIDIA 显卡信息
通过安装CUDA工具包,加快模型训练速度


keras参考资料:https://keras.io/zh/getting-started/faq/#sample-batch-epochhttps://keras-cn.readthedocs.io/en/latest/参考资料:...
GPU 历史 GPU 图形渲染流水线 GPU 存储系统 GPU 流处理器 CPU-GPU 异构系统 GPU 资源管理模型 CPU-GPU 工作流 屏幕图像显示原理 引言 原文链接 http://chuquan.me/2018/08/26/graphics-rending-principle-gpu/ ...

GPU Instacing开启的条件 首先Shader必须兼容与Instancing。 材质开启 Enable GPU Instancing SRP Batcher的优先级高于GPU Instancing,对于Game Objects,如果SRP Batcher能被使用(Shader兼容SRP Batcher,节点...
前言Google Colab是一个基于云端的免费Jupyter笔记本环境,可供用户创建、分享、运行Python代码和机器学习模型。

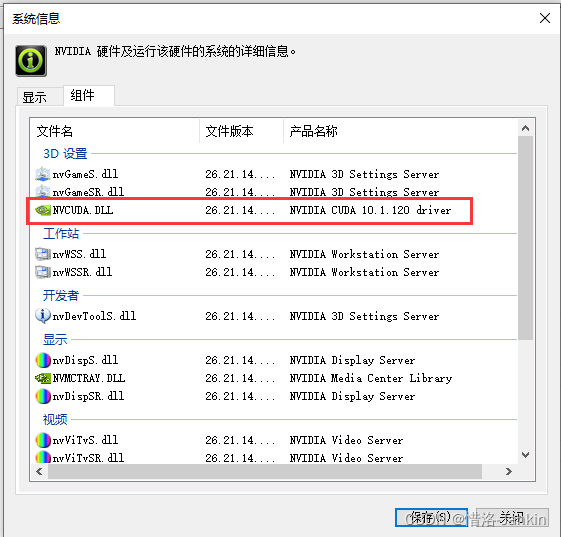
由于要在服务器的不同GPU中进行模型训练,这里记录一下改变使用GPU的一些方式。




目前市面上介绍GPU编程的博文很多,其中很多都是照章宣科,让人只能感受到冷冷的技术,而缺乏知识的温度。所以我希望能写出一篇可以体现技术脉络感的文章,让读者可以比较容易理解该技术,并可以感悟到cuda编程设计...
tensorflow tensorflow-gpu is_gpu_available tf.is_gpu_available
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地