无
”python笔记之爬虫笔记“ 的搜索结果
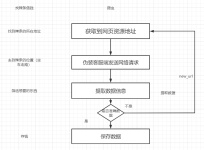
如何运行 ...python pyqt_gui.py ——学习参考资料:仅用于个人学习使用! 本代码仅作学习交流,切勿用于商业用途,否则后果自负。若涉及侵权,请联系,会尽快处理! 未进行详尽测试,请自行调试!
其实我个人认为学习一下正则表达式是大有益处的,之所以换成 XPath ,我个人认为是因为它定位更准确,使用更加便捷。可能有的人对 XPath 和正则表达式的区别不太清楚,举个例子来说吧,用正则表达式提取我们的内容,...
Python是一门强大且易学的编程语言,广泛应用于数据科学、机器学习、Web开发等多个领域。为了帮助大家更好地掌握Python,我们精心整理了一系列Python学习资料,旨在为不同需求的Python学习者提供全方位的学习支持。 ...
python 爬虫学习笔记
Python爬取疫情数据,利用Flask+Echarts对数据进行分析与多样化展示。 Python + Flask + Echarts制作的新冠肺炎疫情...里面有具体的使用说明和爬虫笔记,使用的是mysql数据库,有完整的数据库文件,可直接下载使用。
python1903笔记 爬虫.zip
python 瀑布流爬虫 授课笔记.docx
python笔记之爬虫笔记(一)——自建小型ip池以及mysql数据库的简单运用 前言:最近在爬取知乎的资料时,无奈在测试的时候一直频繁访问,导致IP被封(被封的提示为:))于是在多次提取无果以后,如果购买代理不...
记录python爬虫学习全程笔记、参考资料和常见错误,约40个爬取实例与思路解析,涵盖urllib、requests、bs4、jsonpath、re、 pytesseract、PIL等常用库的使用。 爬虫(Web Crawler)是一种自动化程序,用于从互联网...
基础讲解了requests请求在爬虫的用法
本篇文章主要介绍如何爬取麦子学院的课程信息(本爬虫仍是单线程爬虫),在开始介绍之前,先来看看结果示意图 怎么样,是不是已经跃跃欲试了?首先让我们打开麦子学院的网址,然后找到麦子学院的全部课程信息,像...
这些笔记不仅有助于理解项目的开发过程,还能为学习Python爬虫技术提供宝贵的参考资料。 适用人群: 这份项目合集适用于所有对Python爬虫开发感兴趣的人,无论你是学生、初学者还是有一定经验的开发者。无论你是想...
— — python使用的最广泛的爬虫框架。 2. 创建项目:终端cmd下创建 输入命令:scrapy startproject [项目名qsbk] 生成目录结构: 1、scrapy.cfg:项目配置文件 2、items.py :定义需要爬去的字段 3、middlewares.py:...
python爬虫笔记
主要介绍了python爬虫学习笔记之Beautifulsoup模块用法,结合实例形式详细分析了python爬虫Beautifulsoup模块基本功能、原理、用法及操作注意事项,需要的朋友可以参考下
python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python scrapy 爬虫 python爬虫学习笔记-scrapy框架(1) python ...
Python是一种解释型的、面向对象的、带有动态语义的高级程序设计语言。它是由荷兰人吉多·罗萨姆于1989年发布的,第一个公开发行版发行于1991年。Python注重解决问题的方法,而不是语法和结构。它被广泛应用于各个...
课时20:PySpider框架基本使用及抓取TripAdvisor实战.mp4.baiduyun。课时22:Scrapy框架安装.mp4.baiduyun.downloading。课时21:PySpider架构概述及用法详解.mp4.baiduyun。课时32:Scrapy分布式原理及Scrapy-Redis...
爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景。 爬虫的...
# *壹 #from urllib import request,parse # 1 #request.urlretrieve('...# # 2 ...# print(reas.getcode()) # # 3 # a = parse.urlencode({'我是':1,'你是':2,'它是':3}) ...# print(parse.parse_qs(a)) ...
想要学习 Python 爬虫 , 首先需要了解一下正则表达式的使用,下面我们就来看看如何使用。 . 的使用这个时候的点就相当于一个占位符,可以匹配任意一个字符,什么意思呢?看个例子就知道 import re content = ...
一、简单配置,获取单个网页上的内容。 (1)创建scrapy项目 scrapy startproject getblog (2)编辑 items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items ...# See documentation ...
python进行爬虫小记,主要用于python快速入门理解。
主要为大家详细介绍了python网络爬虫学习笔记的第一篇,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
本篇内容主要介绍了Python网络爬虫的相关知识,包括错误处理与异常捕获、会话管理、网页内容爬取等方面。文中给出了使用try-except结构处理网络错误、利用Session对象保持会话连续性的示例代码,以及通过Requests库和...
Python爬虫连续多页爬取数据
推荐文章
- yolov3系列(四)-keras-yolo3-实时眼睛鼻子嘴巴监测系统_眼睛 嘴巴 yolo-程序员宅基地
- C++类型支持之std::decltype-程序员宅基地
- GB/T28181国标视频监控平台TINYGBS支持4G执法记录仪接入大型可视指挥调度平台-程序员宅基地
- 毕设项目 基于wifi的室内定位算法设计与实现-程序员宅基地
- 【.Net】C# 根据绝对路径获取 带后缀文件名、后缀名、文件名、不带文件名的文件路径...-程序员宅基地
- c语言比用delay更好的延时,PIC单片机C语言程序设计(15)-程序员宅基地
- 微型计算机的细思维特征,详细版2014计算机基础期末考试大纲-程序员宅基地
- org.eclipse.wst.common.component_org/eclipse/wst/common/componentcore/resources/ivi-程序员宅基地
- 数据结构乐智教学百度云_数据结构 百度网盘分享-程序员宅基地
- Arcade 绘制全屏-程序员宅基地