”sparksql“ 的搜索结果

一:为什么sparkSQL? 3 1.1:sparkSQL的发展历程 3 1.1.1:hive and shark 3 1.1.2:Shark和sparkSQL 4 1.2:sparkSQL的性能 5 1.2.1:内存列存储(In-Memory Columnar Storage) 6 1.2.2:字节码生成技术...
(4)java程序实现SparkSQL 二、实验环境 Windows 10 VMware Workstation Pro虚拟机 Hadoop环境 Jdk1.8 三、实验内容 (一)SparkSQL的基本知识 (1)输入start-all.sh启动hadoop相应进程和相关的端口号 (2)启动...
编写完成从Kafka消费数据,打印控制台上,其中创建SparkSession实例对象时,需要设置参数值。
https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.30.zip下载。
SparkSQL详解,底层原理,执行过程,参数调优
sparksql基础知识
标签: sparksql
sparksql简介 df的介绍 rdd转df df的一些基础操作
本文介绍的是SparkSQL组件各个物理执行计划的操作实现。把优化后的逻辑执行计划映射到物理执行操作类这部分由SparkStrategies类实现,内部基于Catalyst提供的Strategy接口,实现了一些策略,用于分辨logicalPlan子类...
调用节点将结果返回给客户端。状态管理进程,定时检查The Impala Daemon的健康状况,协调各个运行Impalad的实例之间的信息关系,Impala正是通过这些信息去定位查询请求所要的数据,进程名叫作 statestored,在集群中...
Impala完全抛弃了MapReduce这个不太适合做SQL查询的范式,而是像Dremel一样借鉴了MPP并行数据库的思想另起炉灶,因此可做更多的查询优化,从而省掉不必要的shuffle、sort等开销。8.使用Impala,您可以访问存储在...
sparksql: Spark SQL是Spark处理数据的一个模块 专门用来处理结构化数据的模块,像json,parquet,avro,csv。 DataFrames API: 与RDD相似,增加了数据结构scheme描述信息部分。 比RDD更丰富的算子,更有利于...
sparksql: Spark SQL是Spark处理数据的一个模块 专门用来处理结构化数据的模块,像json,parquet,avro,csv,普通表格数据等均可。 与基础RDD的API不同,Spark SQL中提供的接口将提供给更多关于结构化数据和计算...
状态管理进程,定时检查The Impala Daemon的健康状况,协调各个运行Impalad的实例之间的信息关系,Impala正是通过这些信息去定位查询请求所要的数据,进程名叫作 statestored,在集群中只需要启动一个这样的进程,...
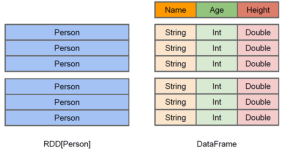
目录SparkSQL1. 基础概念2.DataFrame3.SparkSql程序开发(1.x,2.x)(1)SparkSQL1.x(2)SparkSQL2.x SparkSQL 1. 基础概念 Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且...
元数据库SparkSQL驱动程序依赖项构建JAR lein uberjar # builds target/metabase-sparksql-deps-1.2.1.spark2-standalone.jar签署JAR(可选) # (Replace keystore, TSA and profile below with your own)jarsigner ...
Spark SQL是用来操作结构化和半结构化数据的接口。当每条存储记录共用已知的字段集合,数据符合此条件时,Spark SQL就会使得针对这些数据的读取和查询变得更加简单高效。具体来说,Spark SQL提供了以下三大功能:(1)...
外部数据源API体现出的则是兼容并蓄,SparkSQL多元一体的结构化数据处理能力正在逐渐释放。关于作者:连城,Databricks工程师,Sparkcommitter,SparkSQL主要开发者之一。在4月18日召开的2015Spark技术峰会上,连城...
【代码】SparkSql学习---单词词频统计案例。
【代码】SparkSql学习---电影评分数据分析案例。
有赞数据平台从2017年上半年开始,逐步使用SparkSQL替代Hive执行离线任务,目前SparkSQL每天的运行作业数量5000个,占离线作业数目的55%,消耗的cpu资源占集群总资源的50%左右。本文介绍由SparkSQL替换Hive过程中...
一、案例介绍 案例包含三个表:tbDate、tbStock、tbStockDetail。字段信息如下表: 二、要求 1、计算所有订单中每年的销售单数、销售总额 2、计算所有订单每年最大金额订单的销售额 3、计算所有订单中每年最畅销...
Spark SQL是spark套件中一个模板,它将数据的计算任务通过SQL的形式转换成了RDD的计算,类似于Hive通过SQL的形式将数据的计算任务转换成了MapReduce。 Spark SQL的特点: 1、和Spark Core的无缝集成,可以在写整个...
1.SparkSQL概述 1.1.SparkSQL的前世今生 Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速...
1.从HDFS中加载数据到DataFrame中 2.注册UDF函数,函数名为toUpper就是将所有名字变成大写 3.创建临时视图,然后执行注册的函数
本文讲述了Array、List、Map、本地磁盘文件、HDFS文件转化为DataFrame对象的方法;通过实际操作演示了dataFrame实例方法操作DataFrame对象、SQL语言操作DataFrame对象和ScalaAPI操作DataFrame对象
SparkSQL内置函数
SparkSQL通过Hive创建DataFrame问题分析 问题一 Caused by: org.apache.spark.sql.catalyst.analysis.NoSuchTableException: Table or view 'stu' not found in database 'default'; 分析:确实没有临时表View,...
ETL_with_Pyspark _-_ SparkSQL 一个示例项目,旨在使用Apache Spark中的Pyspark和Spark SQL API演示ETL过程。 在这个项目中,我使用了Apache Sparks的Pyspark和Spark SQL API来对数据实施ETL过程,最后将转换后的...
SparkSQL是Apache Spark的一个模块,用于处理结构化数据。它提供了一个DataFrame API来编写SQL查询,这些查询可以处理来自各种数据源的数据,并返回DataFrame作为结果。DataFrame是一个分布式的数据集合,可以包含...
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地