EMA需要在每步训练时,同步更新shadow权重,但其计算...SWA可以在训练结束,进行手动加权,完全不增加额外的训练成本;实际使用两者可以配合使用,可以带来一点模型性能提升。整理不易,欢迎一键三连!!!%5Calphaw。
”swa“ 的搜索结果
wa
Copy一份模型所有权重(记为Weights)的备份(记为EMA_weights),训练过程中每次更新权重时同时也对EMA_weights进行滑动平均更新,训练阶段结束后用EMA_weights替换模型权重进行预测。(根据新weight更新EMA_...
SWA的方法与传统的模型平均不同。在传统模型平均中,多个模型是通过将它们的权重进行平均来创建的。但是,SWA是通过在训练过程中平均模型的权重来实现的。这是通过在训练过程中,将模型的权重从初始权重开始平均,...
1 stochastic weight averaging(swa) 随机权值平均 这是一种全新的优化器,目前常见的有SGB,ADAM, 【概述】:这是一种通过梯度下降改善深度学习泛化能力的方法,而且不会要求额外的计算量,可以用到Pytorch的...

SWA对象检测 该项目托管用于训练SWA对象检测器的脚本,如我们的论文所述: @article{zhang2020swa, title={SWA Object Detection}, author={Zhang, Haoyang and Wang, Ying and Dayoub, Feras and S{\"u}nderhauf...
SWA简单来说就是对训练过程中的多个checkpoints进行平均,以提升模型的泛化性能。记训练过程第i ii个epoch的checkpoint为w i w_{i}w i ,一般情况下我们会选择训练过程中最后的一个epoch的模型w n w_{n}w n ...
随机加权平均(SWA) PyTorch 1.6现在支持随机加权平均(SWA)! 该存储库包含在对DNN使用SWA训练方法的实现的 。 此PyTorch的代码改编自原始的PyTorch。 请参阅新的PyTorch博客文章,以获取有关SWA和torch.optim...
AplicaçãoTodo列表Vue.js 2 com SWA + GitHub操作 响应响应式演示的演示文稿,可以实现自动部署和集成自动化,还可以使用和 :rocket: Recursos Utilizados 扩展Vue.js Usadas no Projeto :fire: 执行本地应用...
pytorch中swa模块的使用范例,能有效提高模型的泛化能力。
该工具箱还实现了基本的睡眠计分GUI,该GUI允许用户以用户定义的长度(例如30秒纪元)手动设置睡眠阶段,并将各个阶段导出为准备使用swa工具箱进行分析的文件格式。 获取最新代码 要使用git获取最新代码,只需键入:...
旅游景观与规划-48.万科大梅沙度假区方案设计SWA
无痛涨点技术,用于平均多个模型的权重,此资源是对pytorch 模型进行处理的脚本
盖茨比的默认启动器 使用此默认样板启动您的项目。 该入门工具随附主要的Gatsby配置文件,您可能需要使用React的快速应用生成器快速启动并运行。 还有其他更具体的想法吗? 您可能需要查看我们充满活力的集合。...
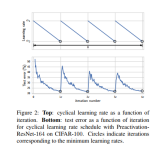
SWA,全程为“Stochastic Weight Averaging”(随机权重平均)。它是一种深度学习中提高模型泛化能力的一种常用技巧。 其思路为:**对于模型的权重,不直接使用最后的权重,而是将之前的权重做个平均**。 该方法适用...
旅游规划-·苏州上方山“三园”设计方案-SWA161页.pdf
公共景观与规划-34-方案文本.武汉商业广场概念性设计成果汇报2011SWA.rar
超框架 回购是一种实现。 它基于另一种,但有几个差异: 修复了一些错误(错误的ResNet实现,导致最大批处理量很小), 提供了许多附加功能(首先是丰富的验证)。 更准确地说,在此实现中,您将找到: ...
14.广州东部(新塘)国际商务城概念规划2010——[SWA].zip
道路景观与规划-03.SWA深圳人民路景观改造方案
PDF攻击实例-USF-ISA-SWA-Shadow Attack.7z
概念性规划设计-40-方案文本.深圳前海地区概念规划——SWA.rar
道路景观与规划-03.SWA深圳人民路景观改造方案.zip
作者:禅与计算机程序设计艺术 1.简介 随着深度学习模型的不断进步,神经网络已经从单纯的机器学习算法,转变成了处理图像、声音、文本等多种模态数据中最强大的工具。但是神经网络训练速度慢、泛化能力差、易受...

torch.optim是实现各种优化算法的包。大多数常用的方法都已得到支持,而且接口足够通用,因此将来还可以轻松集成更复杂的方法。
SWA是论文Averaging Weights Leads to Wider Optima and Better Generalization所提出的一种无痛涨点的方式,只需要在模型训练的最后阶段保存模型权重,然后取模型权重的平均值,就可以提升模型的权重。按照论文描述...
推荐文章
- 记录CentOS7 Linux下安装MySQL8_适合正式环境_干货满满(超详细,默认开启了开机自启动,设置表名忽略大小写,提供详细配置,创建非root专属远程连接用户)_centos7安装mysql8-程序员宅基地
- python 读取grib \grib2-程序员宅基地
- Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!-程序员宅基地
- Datawhale-集成学习-学习笔记Day4-Adaboost-程序员宅基地
- TexStudio配置以及解决无法Build&View_texstudio 无法启动 build & view:pdflatex:"d:/data/texl-程序员宅基地
- 用户空间访问I2C设备驱动-程序员宅基地
- 人脸识别算法初次了解-程序员宅基地
- maven的pom文件学习-程序员宅基地
- wamp mysql 没有启动,WAMP中mysql服务突然无法启动 解决方法-程序员宅基地
- 《树莓派Python编程入门与实战(第2版)》——3.7 创建Python脚本-程序员宅基地