1.项目利用TF-IDF(Term Frequency-Inverse Document Frequency 词频-逆文档频率)检索模型和CNN(卷积神经网络)精排模型构建了一个聊天机器人,旨在实现一个能够进行日常对话和情感陪伴的聊天机器人。 2.项目运行...
”tf-idf“ 的搜索结果

解密TF-IDF:打开文本分析的黑匣子
字典特征提取、文本特征提取、jieba分词处理、tf-idf文本特征提取概念及代码实现,特征提取:将任意数据(如文本或图像)转换为可用于机器学习的数字特征,特征值化是为了计算机更好的去理解数据

版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 ...
TF-IDF算法 一、简介 TF-IDF的全称是Term Frequency-inverse Document Frequency ,是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数...
一:今日相亲 搭档镇楼。 今天的头版给我漂亮的搭档,啥年芳二六、待字闺中之类的矫情话就不说了,希望看到文章的小伙子,如果对眼,请放下你手中的游戏,我可以牵线搭桥。 好好相爱,就是为民除害。...
OpenMP-MPI-tf-idf
标签: C++
OpenMP-MPI-tf-idf openMp MPI中Tf-IDF的实现代码运行在分布式集群上。 示例输入数据位于 BOOKS 文件夹中,输出将在输出文件夹中生成 跑步: mpiCC "FILE_NAME" -o -fopenmp "EXECUTABLE NAME" mpirun -np ...
文本相似度计算,TF-IDF算法 原理,例子,代码实现
原文地址:基于tf-idf的小说主题特征抽取算法 1.主题特征抽取做什么 在当前个性化推荐大行其道的时候,那就不得不提用户画像。用户画像的主要工作内容就是将用户标签化,对于我们现有的数据来说,用户本身的固有...

tf-idf-spark-py parser.py [zzz.xml] - 将 zzz.xml 的内容吐出到已解析/结果 {0} .xml 文件中,其中 {0} 是文档编号。 文件内容:“{0}:[word, [...]]”,{0} - 文档编号。 spark-submit counter.py [dir] ...
tf×idf(i,j)=tfij×idfi=nij∑knkj×log(∣D∣1+∣Di∣)tf \times idf(i,j) = tf_{ij} \times idf_i = \frac {n_{ij}}{\sum_{k}{n_{kj}}} \times log\left(\frac{|D|}{1+|D_i|}\right)tf×idf(i,j)=tfij...

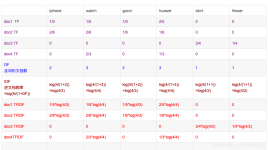
A:LSI 效果最好,TF-IDF 次之.而 Doc2Vec 模型无法正确提取关键信息,甚至牛头不对马嘴. TF-IDF 1061 0.25669920444488525 第五回 弯弓射雕(1) 1172 0.25669920444488525 第五回 弯弓射雕(2) 3880 0....
目录0 前言1 TF-IDF模型1.1 TF-IDF数学形式1.2 举例2 TF-IDF的实现2.1 TF-IDF简单python实现2.2 TF-IDF的gesim实现:2.3 TF-IDF的sklearn实现 0 前言 前面介绍了词向量的One-Hot模型以及词袋模型,这都是为了将离散...
TF-IDF-Cosine_Similariity- 在此分配中,您将实现TF-IDF和余弦相似度以计算文档之间的相似度。数据: 您可以在“数据”文件夹中找到10个txt文件。 这些是您语料库中需要处理的文档。任务:步骤1:标记化。步骤2:...
摘要这篇文章主要介绍了计算TF-IDF的不同方法实现,主要有三种方法:用gensim库来计算tfidf值用sklearn库来计算tfidf值用python手动实现tfidf的计算关于TFIDF的算法原理我就不过多介绍了,看这篇博客即可——TF-IDF...
python编程语言 预处理 统计词频 计算IT-IDF
TF-IDF
可以看到,通过TF-IDF算法,我们得到了一个包含5篇文档,15个词汇的向量表示。而逆文档频率则衡量了一个词的普遍程度,如果一个词在许多文档中出现,则其逆文档频率将很低。可以看到,当一个词在越多的文档中出现时...
Python3 实现tf-idf算法

基于UGC(user Generate Content)的推荐 用户用标签来描述对物品的看法,所以用户生成标签(UGC)是联系用户和物品的纽带,也是反应用户兴趣的重要数据源。 一个用户标签行为的数据集一般由一个三元组(用户,物品,...
tf-idf个人理解

NLP文本分类学习笔记
推荐文章
- 小说网站系统源码|PHP付费小说网站源码带app-程序员宅基地
- Swift编码规范_swift 正则判断文件类型-程序员宅基地
- 关于shell 中return用法解释(转)_shell return-程序员宅基地
- Linux编译宏BUILD_BUG_ON_ZERO-程序员宅基地
- c51语言单片机打铃系统设计,基于单片机的自动打铃系统的设计-程序员宅基地
- 在php中使用SMTP通过密抄批量发送邮件-程序员宅基地
- python数据清洗+数据可视化_python课程题目数据清除与可视化-程序员宅基地
- 【11g】3.3 Oracle自动存储管理存储配置_oraclestorageoptions-程序员宅基地
- signature=b2f9171fa2897cefe08a669efaf58433,FULFILLMENT TRACKING IN ASSET-DRIVEN WORKFLOW MODELING-程序员宅基地
- 宜兴市计算机中等学校,重磅!江苏省陶都中等专业学校正式揭牌!-程序员宅基地