”梯度下降优化算法“ 的搜索结果
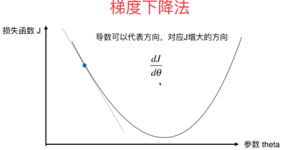
如果我们定义了一个机器学习模型...,当损失函数值下降,我们就认为模型在拟合的路上又前进了一步。最终模型对训练数据集拟合的最好的情况是在损失函数值最小的时候,在指定数据集上时,为损失函数的平均值最小的时候。
梯度下降优化算法综述 梯度下降优化算法综述 梯度下降优化算法综述
最优化--梯度下降法--牛顿法(详解)
`fmin_adam` 是来自 Kingma 和 Ba [1] 的 Adam 优化算法(具有自适应学习率的梯度下降,每个参数单独使用 Momentum)的实现。 Adam 设计用于处理随机梯度下降问题; 即当仅使用小批量数据来估计每次迭代的梯度时,或...
本次介绍梯度下降优化算法。主要参考资料为一篇综述《An overview of gradient descent optimization algorithms》


梯度方向是,步长设为常数Δ,这时就会发现,如果用在梯度较大的时候,离最优解比较远,W的更新比较快;在这儿,我们再作个形象的类比,如果把这个走法类比为力,那么完整的三要素就是步长(走多少)、方向、出发点...
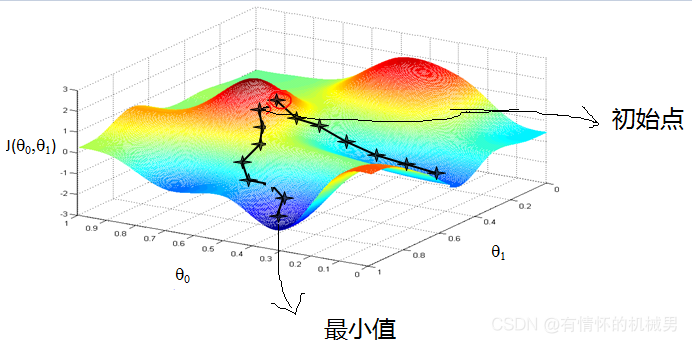
这个例子是为在研究生... 这个例子演示了如何使用梯度下降法来解决一个简单的无约束优化问题。 采用大步长会导致算法不稳定,但小步长会导致计算效率低下。 可以在此处找到相应的视频: https://youtu.be/qLpOWteWmjs
Optimizer梯度下降优化算法结合多论文实现(源代码+数据)
1. An overview of gradient descent optimization algorithms 2. 中文翻译《梯度下降优化算法综述》 :
梯度下降优化算法Momentum
标签: 算法
Momentum算法在原有的梯度下降法中引入了动量,从物理学上看,引入动量比起普通梯度下降法主要能够增加两个优点。首先,引入动量能够使得物体在下落过程中,当遇到一个局部最优的时候有可能在原有动量的基础上冲出这...
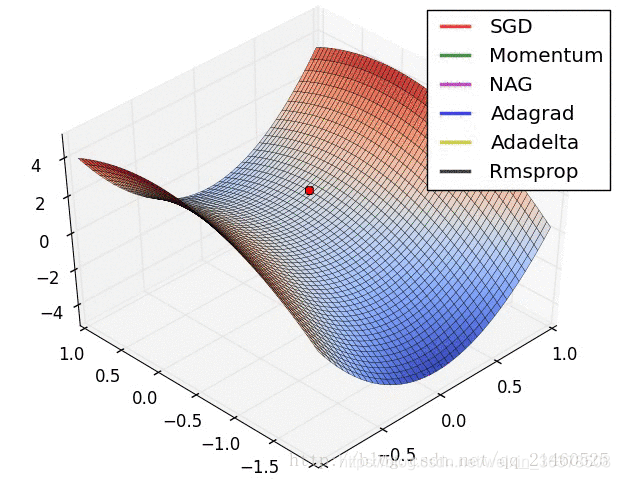
深度学习框架(例如:TensorFlow,Keras,PyTorch)中使用的常见梯度下降优化算法。梯度下降是一种用于寻找函数最小值的优化方法。它通常在深度学习模型中用于通过反向传播来更新神经网络的权重。 VanillaSGD 朴素...
1:随机梯度下降优化算法 一:普通的梯度下降算法在更新回归系数时要遍历整个数据集,是一种批处理方法,这样训练数据特别忙庞大时,可能出现如下问题: 收敛过程可能非常慢; 如果误差曲面上有多个局极小值,那么...
fmin_adam:亚当随机梯度下降优化算法的Matlab实现
梯度下降优化算法,虽然越来越流行,但经常被用作黑盒优化器,因为它们的优点和缺点的实际解释是很难得到的。这篇文章的目的是为读者提供直观的关于不同算法的行为,介绍怎么使用它们。在这篇概述中,我们研究了梯度...
最近在学习《机器学习实战:基于Scikit-Learn和TensorFlow》,这里把之前的一些基础知识点进行了总结。 对于一个线性函数: y^=hθ(x)=θ⋅x\hat{y}=h_{\theta}(\mathbf{x})=\boldsymbol{\theta} \cdot \mathbf{x}y^...
本文档我学习梯度下降优化算法的总结,开头是深度学习的基本介绍,了解为什么要用梯度下降算法,以及传统的梯度下降算法的弊端,后面的主要章节是从momentum和adaptive两方面,进行梯度下降优化算法的展开,有详细的...
【深度学习】TensorFlow学习之路四一、动量下降(Momentum)二、Nesterov加速梯度三、AdaGrad四、RMSProp五、Adam优化算法六、学习率优化方案 本系列文章主要是对OReilly的Hands-On Machine Learning with Scikit-...
一、梯度下降法 重申,机器学习三要素是:模型,学习准则,优化算法。这里讨论一下梯度下降法。 通常为了充分利用凸优化中的一些高效成熟的优化方法...机器学习中,常用的优化算法就是梯度下降法,首先初始化参数θ0...
【深度学习】梯度下降优化算法
标签: 吴恩达
全梯度下降算法(FGD)、随机梯度下降算法(SGD)、随机平均梯度下降算法(SAGD)、小批量梯度下降算法(Mini-batch gradient descent,MGD)梯度下降优化算法,动量法、Adagrad、Adadelta、RMSProp、Adam
推荐文章
- Java学到什么程度才能叫精通?_java数据结构与算法学到什么程度-程序员宅基地
- 死磕源码系列【springboot之ServletContextInitializer接口源码解析】-程序员宅基地
- arduino库函数WiFiEsp的使用(一)_小绿科技wifi库函数-程序员宅基地
- yolov3模型转换caffes实践之安装caffe-程序员宅基地
- 【Qt】数据类型和有用的数据操作类_qset初始化-程序员宅基地
- 【论文简述】DSC-MVSNet: attention aware cost volume regularization based ondepthwise separable(CIS 2023)-程序员宅基地
- Elasticsearch 安装的时候,Unsupported major.minor version 51.0问题的解决-程序员宅基地
- 关于笔记本电脑飞行堡垒风扇不能打开的解决办法_飞行堡垒7风扇模式怎么开-程序员宅基地
- 设置笔记本电脑插入USB鼠标时,自动禁用触摸板_有usb鼠标时,则自动禁用触摸板-程序员宅基地
- Http请求状态码-416_http 416-程序员宅基地