sql按照多个字段分组统计记录条数
标签: sql
例如:统计每个人的记录条数,实际上是按照年级,班级,个人统计记录条数,无关分数和分数类型字段 sql如下: SELECT personid , classnum , gradenum , count ( *) AS num FROM ZZZ_SCORE GROUP BY personid, class...
标签: sql
例如:统计每个人的记录条数,实际上是按照年级,班级,个人统计记录条数,无关分数和分数类型字段 sql如下: SELECT personid , classnum , gradenum , count ( *) AS num FROM ZZZ_SCORE GROUP BY personid, class...

需求是对指定集合的学生信息,根据班级分组统计每个班所有学生的凭证数量。 List<HashMap<String, Object>> result = new ArrayList<>(); List<HashMap<String, Object>> list =...
以上就是js统计一个json的元素数量的方法啦
GET m-ft-itv-quality-20180622-101000/_search { "size": 0, "query": { "bool": { "must": [ {"term": { "olt_ip"...172.00.00.00&qu
单个left join:(1)一对一:结果表的行数=左表行数(2)一对多:结果表的行数>左表行数多个left join:(0)多个left join由上到下,依次生成查询表,原理同单个left join(1)需要补充的是,如果在left join a表之前,...
1、查询和计算表person_tbl中(last_name,first_name)组合有重复的记录的数量。mysql> SELECT COUNT (*) AS repetitions, last_name, first_nameFROM person_tbl GROUP BY last_name, first_nameHAVING ...
标签: sql
--按年统计 SELECT year(CreationTime) 年次, count(1) 销售次数, sum(Num) 销售量 FROM Orders GROUP BY year(CreationTime)
使用的数据表格式如下 表一: Employees_China: E_ID E_Name 01 Zhang, Hua 02 Wang, Wei 03 Carter, Thomas 04 Yang, Ming 表二: Employees_USA: E_ID E_Name 01 Adams, John ...02 Bush

python 基础知识- list基本操作-元素统计,统计python list 中某个元素的数量:
使用grep关键字出现次数进行计数统计 模糊匹配 grep -o "keyword" filename |wc -l 精确匹配(以整个word 匹配) grep -wo "keyword" filename |wc -l 包含关键字的行数(一行存在多个关键字,计数为1) grep -c ...

统计函数 COUNT(*|DISTINCT|列) --求出全部的记录数,即全部行 SUM(列) --求出总和,操作的列是数字 AVG(列) --求平均值 MAX(列) --求最大值 MIN(列) --求最小值 MEDIAN(列) --返回中间值 VARIANCE(列) --返回方差...
如果一张表的数据量太大时,使用select count(*) from table 统计记录数,语句执行,基本就超时了,相信很多老铁们,都有遇到这个问题,今天给大家推荐个好的办法: 目前这张表有一千四百万的数据,用这个SQL...
下面介绍怎样使用 IServer 提供的 count 方法来进行 无条件统计数据记录数,有条件统计数据记录数
SELECT g.user_account,g.user_name,g.user_cardno,COUNT(*) numFROM gsuser gLEFT JOIN policys p ON p.user_id = g.user_id WHERE g.sales_type = 3and g.salesbranchno like '42%'and p.policyflag = 4 GROUP BY ...
mysql对同一个字段最不同数值范围的统计,例如对年龄做年龄段统计,每个年龄段有多少人。
16_Pandas.DataFrame计算统计信息并按GroupBy分组 可以通过andas.DataFrame和pandas.Series的groupby()方法对数据进行分组。可以汇总每个组的数据,并且可以通过任何函数计算或处理统计信息,例如平均值,最小值,...
在一张表中,需要统计其中一列数据中,出现重复的记录数。 解决方案1 SELECT count(*) FROM table WHERE origin = 条件1; SELECT count(*) FROM user_operation_log WHERE origin = 条件2; SELECT count(*) ...
方法count()用于统计结果集中文档条数 语法: db.集合名称.find({条件}).count() 也可以与为 db.集合名称.count({条件}) 例1:统计男生人数 db.stu.find({gender:1}).count() 例2:统计年龄大于20的男生人数 db....
Pandas 统计数据方法汇总准备数据:一、数据的总体描述1.1 统计行数 len(df)1.2 统计有多少种不同的值 df['lable'].nunique()1.3 对 列 中每种不同的值 进行计数 df['lable'].value_counts()1.4 整体统计描述 df....
做的物资管理系统涉及到很多数据的分组统计,之前都是直接在数据库里面查询的,直到看到大佬写的代码,自愧不如。下面就上一段代码,也算是做个笔记吧。 private Map<String,Double> getPickingAmountMap...
postgresql查询一张表每个字段不为NULL和空的数量 创建一张表: create table test_table( year int, m01 int, m02 int, m03 int, m04 int ); insert into test_table values(2018, 1,2,3,4); insert...
void minMaxLoc(InputArray src, CV_OUT double* minVal, CV_OUT double* maxVal = 0, CV_OUT Point* minLoc = 0, CV_OUT Point* maxLoc = 0, InputArray mask = noArray()); src:输入图像。...
数量是8显然不对,正确的数量应该是4,重复的user_id不应该给我统计进去。 distinct 无法满足这种情况怎么办呢,还有一个常用的办法就是利用group by 进行分组统计。请直接看代码我是这么写的SELECT COUNT(1) AS ...

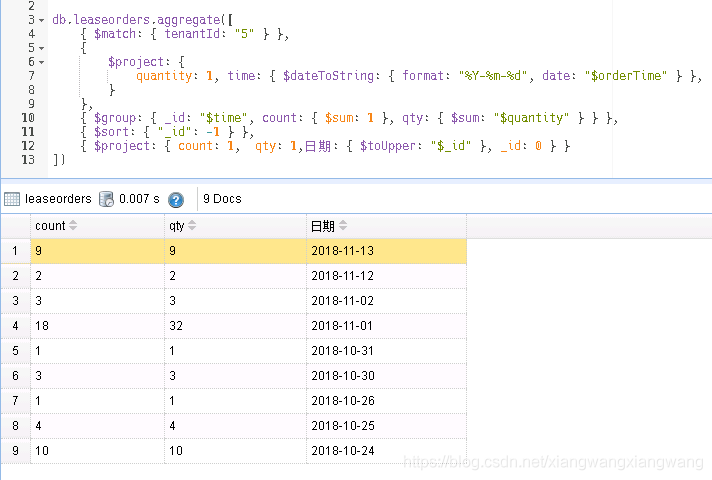
统计文件夹内,所有文件个数,filecount? 统计文件夹内,某种类型的文件个数 统计文件夹内, 所有文件名,这不有点像 dir吗? 统计文件夹内,所有非空文件的文件个数 统计文件夹内,所有某后缀名的非空文件的...