”过拟合“ 的搜索结果

过拟合和欠拟合 训练误差和泛化误差 训练误差,模型在训练集合上表现的误差。 泛化误差 ,模型在任意一个数据集上表现出来的误差的期望。 过拟合,模型训练误差远小于在测试集上的误差。 欠拟合 ,模型无法在训练集...
全是干货,在学习深度学校中遇到的一些问题和处理办法
过拟合(over-fitting),机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。 过拟合问题,...
过拟合处理方法
标签: test 方法 过拟合
过拟合处理方法 – 增加数据集 这是我用三阶函数拟合,但是只给定两个数据训练。可以看出来拟合不好,特点是train的loss能降下去,但是test效果不好。解决方法之一是增加数据集 我将数据集增加到4个: 效果好了...
BN)是一种常见的神经网络技术,其主要作用是在网络中每一层输入的数据进行归一化,从而使得输入数据具有更加标准的分布,增强了模型的稳定性和泛化性能,在一定程度上可以抑制过拟合。因为输入数据被归一化,最终的...
真正喜欢的人和事都值得我们去坚持。
定义定义:给定一个假设空间H... ———《Machine Learning》Tom M.Mitchell出现过拟合的原因1. 训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;2. 训练集和测试集特征分布不一致;3. 样本...
增加数据量, 大部分过拟合产生的原因是因为数据量太少了. 如果我们有成千上万的数据, 红线也会慢慢被拉直, 变得没那么扭曲 . 方法二:运用正规化 运用正规化. L1, l2 regularization等等, 这些方法适用于大多数的...
为什么正则化能够解决过拟合问题一. 正则化的解释二. 拉格朗日乘数法三. 正则化是怎么解决过拟合问题的1. 引出范数1.1 L_0范数1.2 L_1范数1.3 L_2范数2. L_2范式正则项如何解决过拟合问题2.1 公式推导2.2 图像推导[^...
过拟合欠拟合及其解决方案 模型在训练数据集上准确,测试数据集上不一定更准确 训练误差和泛化误差 训练误差:模型在训练数据集上表现出的误差。 泛化误差:模型在任意一个测试数据样本上表现出的误差的期望。常常...
一 过拟合与欠拟合及其解决方案 过拟合、欠拟合的概念 权重衰减 丢弃法 1 训练误差与泛化误差 训练误差:在训练集上的数据误差; 泛化误差:在其他任意数据集上的误差的期望,常用测试集误差来近似 模型选择:通常...
一类是欠拟合,另一类是过拟合. 1.欠拟合 模型无法得到较低的训练误差,将这一现象成为欠拟合. 2.过拟合 模型的训练误差远小于它在测试集上的误差,称这一现象为过拟合. 可能导致这两种拟合问题的因素有很多,比如...
过拟合、欠拟合及其解决方案,内容: 1. 过拟合、欠拟合的概念 2. 权重衰减 3. 丢弃法 总结 欠拟合现象:模型无法达到一个较低的误差 过拟合现象:训练误差较低但是泛化误差依然较高,二者相差较大
过拟合得问题指的是模型在测试集上的结果不好,训练误差较低但是泛化误差依然较高,二者相差较大。 解决过拟合得问题通常可以通过增加数据量,另外还可以用正则化的方法。 正则化 L2范数正则化 通常指得是L2范数正则...
过拟合,欠拟合 在模型的评估和调整过程中,往往会遇到过拟合和欠拟合的问题,这也是及其学习中的经典问题,但在目前的任务中仍然会出现过拟合等问题,对于常用的解决方法,总结如下。 在解释上述现象之前,我们...
一 过拟合和欠拟合 当模型的容量过大时,网络模型除了学习到训练集数据的模态之外,还把额外的观测误差也学习进来,导致学习的模型在训练集上面表现较好,但是在未见的样本上表现不佳,也就是模型泛化能力偏弱,我们...
1,过拟合和欠拟合的定义 2, 过拟合和欠拟合的解决方法 3, 梯度消失和爆炸的定义 4,梯度消失和爆炸的解决方法 1,过拟合和欠拟合的定义 无论在机器学习还是深度学习建模当中都可能会遇到两种最常见...
过拟合、欠拟合及其解决方案 1、预备知识 1.1 模型选择 验证数据集:测试集不可用于模型参数的调试,所以需要从训练数据集中分离出一部分数据作为验证数据集用来调参 1.2 K折交叉验证 目前来说深度学习研究的普遍...
最近一年我一直致力于深度学习领域。这段时间里,我使用过很多神经网络,比如卷积神经网络、循环神经网络、自编码器等等。我遇到的最常见的一个问题就是在训练时,深度神经网络会过拟合。
正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。 L2 范数正则化(regularization) L2 范数正则化在模型原损失函数基础上添加 L2 范数惩罚项,从而得到训练所需要最小化的函数...
过拟合与欠拟合 专业名词解释: 泛化误差(generalization error):指模型在任意一个测试数据样本上表现出来的误差的期望,我们通常用测试集上的误差来近似看待. 验证集(validation set):预留一部分训练数据集...
K折交叉验证 由于验证数据集不参与模型训练,当训练数据不够用时,预留...过拟合和欠拟合 模型训练中经常出现的两类典型问题: 一类是模型无法得到较低的训练误差,我们将这一现象称作欠拟合(underfitting); 另一类
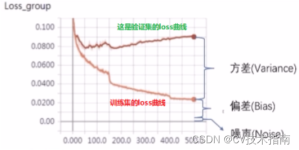
问题:拿到一个图,不怎么怎么区分是过拟合还是欠拟合 图1: 图2: 图3: 1.观察图: 图1:train loss>>test loss 训练误差(10^3)较大 图2:test loss >> train loss 训练误差(10^1)较小 图3: test loss = ...
过拟合的原理:在loss下降,进行拟合的过程中(斜线),不同的batch数据样本造成红色曲线的波动大,图中低点也就是过拟合,得到的红线点低于真实的黑线,也就是泛化更差。 可见,要想减小过拟合,减小这个波动,...
过拟合、欠拟合及解决方案知识点总结 区分两种误差 训练误差为训练数据集(training data)上的误差; 泛化误差为模型在任意一个测试数据样本上表现的误差的期望(常通过测试数据(test data)集上的误差来近似)。...
过拟合欠拟合及其解决方案 训练误差和泛化误差 训练误差:模型在训练数据集上表现出的误差 泛化误差:模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。 机器学习模型应关注...
一、过拟合和欠拟合 训练误差:指模型在训练数据集上表现出的误差。 泛化误差:指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。(ML应关注此项) 如何计算训练误差或者泛化...
推荐文章
- centos7初始化mysql 5.7.9(源码安装)-程序员宅基地
- undefined reference to `cvHaarDetectObjects'()(人脸检测)_cvhaardetectobjects未定义-程序员宅基地
- 如何将参数传递给批处理文件?_批处理 传递参数-程序员宅基地
- C++的一些小总结 类 静态成员变量/函数 this指针_c++ class 静态指针函数-程序员宅基地
- springboot小区物业管理系统7ffeo[独有源码]如何选择高质量的计算机毕业设计_小区物业管理系统er图-程序员宅基地
- mac-gradle的安装和配置,掌握这些知识点再也不怕面试通不过_mac gradle配置-程序员宅基地
- 2032:【例4.18】分解质因数(信奥一本通)-程序员宅基地
- html怎么设置默认状态,网页中如何设置默认图片?方式介绍-程序员宅基地
- milp的matlab的案例代码_matlab30个案例分析案例5代码-程序员宅基地
- html实现/ 简约好看、美观大方的个人导航页源码/开源个人主页html源码_个人导航html-程序员宅基地