模型过拟合,如你使用三次函数拟合二次函数就是过拟合。模型欠拟合,如你用一次函数拟合二次函数就是欠拟合。两种情况均会导致模型泛化能力较差。
”过拟合和欠拟合“ 的搜索结果
AI模型的欠拟合(Underfitting)发生在模型未能充分学习训练数据中的模式和结构时,导致它在训练集和验证集上都表现不佳。欠拟合通常是由于模型太过简单,没有足够的能力捕捉到数据的复杂性和细节。
然而,图像识别任务面临着许多挑战,其中最重要的是过拟合和欠拟合问题。过拟合指的是模型在训练数据上表现得非常好,但在新的、未见过的数据上表现得很差,而欠拟合则是指模型在训练数据和新数据上都表现得不佳。在...
1.背景介绍 时间序列预测是一种常见的数据分析任务,它涉及到预测未来时间点的变量值基于其历史数据。...然而,时间序列预测任务中会遇到过拟合和欠拟合的问题,这会影响预测的准确性。过拟合指的是模型在训...
1、过拟合和欠拟合 无论在机器学习还是深度学习建模当中都可能会遇到两种最常见结果,一种叫过拟合(over-fitting )另外一种叫欠拟合(under-fitting)。 首先谈谈什么是过拟合呢?什么又是欠拟合呢?网上很直接...

在语音识别中,过拟合和欠拟合是两个影响模型性能的关键因素。过拟合指的是模型在训练数据上表现出色,但在未见过的新数据上表现很差的情况,而欠拟合则是模型在训练数据和新数据上都表现不佳的情况。本文将从语音...
1.背景介绍 ...随机森林在处理分类、回归和缺失值等问题时具有很好的性能,并且对于高维数据和非线性问题具有很强的抗干扰能力。 随机森林的两个主要技术是Bagging和Boosting。Bagging(Bootstrap A...
1.5 欠拟合和过拟合 欠拟合(Underfitting):选择的模型过于简单,以致于模型对训练集和未知数据的预测都很差的现象。 过拟合(Overfitting):选择的模型过于复杂(所包含的参数过多),以致于模型对训练集的预测...

Nelson-Siegel模型是一种用于拟合债券收益率曲线的经典模型,通过拟合收益率曲线上的数据点来估计利率期限结构。该模型通常由以下公式表示: \[ y(\tau) = \beta_0 + \beta_1 \frac{1 - e^{-\tau / \lambda}}{\tau ...
过拟合和欠拟合是指模型在训练数据上表现得很好,但在新的、未见过的数据上表现得很差的现象。在时间序列预测中,过拟合和欠拟合会导致预测的准确性大幅度降低,从而影响最终的业务效果。因此,在时间序列预测中,...
正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。 L2 范数正则化(regularization) L2 范数正则化在模型原损失函数基础上添加 L2 范数惩罚项,从而得到训练所需要最小化的函数...
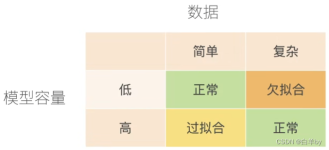
曲线拟合中的过拟合与欠拟合问题
标签: 开发技术
### 2.1 过拟合的定义和原因 过拟合是指模型在训练数据上表现良好,但在测试数据上表现不佳的现象。造成过拟合的原因主要有以下几点: - 模型过于复杂,参数过多; - 训练数据噪声较大,导致模型过度拟合噪声; - ...
将模型在训练数据上拟合的比在潜在分布中更接近的现象称为过拟合(overfitting), 用于对抗过拟合的技术称为正则化(regularization)。在前面的章节中,有些读者可能在用Fashion-MNIST数据集做实验时已经观察到了...
在深度学习中,过拟合和欠拟合是两个常见的问题,它们可能会影响模型的性能和泛化能力。 过拟合(overfitting)指的是模型在训练数据上表现良好,但在新的未见过的数据上表现较差的现象。过拟合发生的原因通常是模型...
欠拟合和过拟合简介 机器/深度学习的基本问题是利用模型对图像、语音、数字等数据进行拟合。学习的目的是对未曾在训练集合出现的样本能够正确预测。 在进行如下讲解之前先简单地介绍几个概念:模型对训练集数据的...
过拟合就是在训练集上效果很好,但在测试集上预测效果很差。
深度学习的挑战:过拟合与欠拟合 作者:禅与计算机程序设计艺术 1. 背景介绍 深度学习是机器学习领域近年来的一个重要突破,在计算机视觉、自然语言处理等众多领域取得了巨大的成功。与传统的浅层机器学习模型相比,...
问题:拿到一个图,不怎么怎么区分是过拟合还是欠拟合 图1: 图2: 图3: 1.观察图: 图1:train loss>>test loss 训练误差(10^3)较大 图2:test loss >> train loss 训练误差(10^1)较小 图3: test loss = ...
不过,这套神经网络需要足够的数据以供训练,这里就引出了过拟合和欠拟合的概念。当神经网络很庞大,数据却不多,神经网络能够记住每个数据的特征,这会导致过拟合。反之,当神经网络规模较小或拟合能力还很弱,数据...
过拟合与欠拟合 专业名词解释: 泛化误差(generalization error):指模型在任意一个测试数据样本上表现出来的误差的期望,我们通常用测试集上的误差来近似看待. 验证集(validation set):预留一部分训练数据集...
机器学习-正则化
一、过拟合、欠拟合及其解决方案 1.概念 过拟合:模型在训练集上能够得到很好的误差,但是在测试集上的效果很差。 欠拟合:模型无法得到较低的训练误差。(在训练集和测试集上都不能得到较好的误差) 2.多项式函数...
2019-08-2711:45:21问题描述:在模型评估过程中,过拟合和欠拟合具体是指什么现象,如何解决。问题求解:过拟合是指模型对于训练的数据集拟合呈现过当的情况,反应到评估指标上就是模型在训练集上的表现很好,但是在...

链接:...欠拟合的原因:模型复杂度过低,不能很好的拟合所有的数据,训练误差大; 避免欠拟合:增加模型复杂度,如采用高阶模型(预测)或者引入更多特征(分类)等。 过拟合的原因:模型...

下图描述了过拟合和欠拟合的区别。 可以看出,(a)是欠拟合的情况,拟合的线没有很好地捕捉到数据的特征,不能够很好地拟合数据。©则是过拟合的情况,模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化能力...
推荐文章
- 网站安全检测:推荐 8 款免费的 Web 安全测试工具_目前市面使用最多的web安全漏洞扫描软件-程序员宅基地
- Splashtop Wired Xdisplay在PC端闪退的解决方法_xdisplay使用虚拟显示器闪退-程序员宅基地
- 使用 Linux 系统调用的内核命令_x32_sys_call_table copy_from_user-程序员宅基地
- UDP网络延迟测试程序_千兆网络 udp测速工具 源码-程序员宅基地
- k8s常见报错解决_the service "kubernetes-dashboard" is invalid: spe-程序员宅基地
- 其实今天过节的兄弟们还有多重身份-程序员宅基地
- 信息检索速通知识点-程序员宅基地
- ionic小案例_ionic 案例-程序员宅基地
- PyQt5: chapter6-使用水平布局_pyqt5水平布局-程序员宅基地
- 内容管理妙招,柯尼卡美能达MCS服务案例解析-程序员宅基地