随机梯度下降(Stochastic Gradient Descent)算法—收敛速率证明 1.需证明公式: 2.证明过程:
”随机梯度下降SGD“ 的搜索结果
随机梯度下降(SGD, stochastic gradient descent):名字中已经体现了核心思想,随机选取一个店做梯度下降,而不是遍历所有样本后进行参数迭代。因为梯度下降法的代价函数计算需要遍历所有样本,而且是每次迭代都要...
随机梯度下降
随机梯度下降的稳定性和最优性 这是正在进行的论文的方法和算法的随附代码实现。 维护者 Dustin Tran < > 参考 弗朗西斯·巴赫 (Francis Bach) 和埃里克·穆林 (Eric Moulines)。 收敛速度为 O(1/n) 的非强凸平滑...

梯度下降代码:function [ theta, J_history ] = GradinentDecent( X, y, theta, alpha, num_iter )m = length(y);J_history = zeros(20, 1);i = 0;temp = 0;for iter = 1:num_itertemp = temp +1;theta = theta - ...
在深度学习中,模型的...随机梯度下降(Stochastic Gradient Descent,简称SGD)是一种在深度学习中常用的优化算法,用于最小化损失函数,即在机器学习中找到模型的参数,使得模型预测的损失(例如分类错误率)最小。
SGD:随机梯度下降算法:带动量的SGD、Adagrad、RMSProp 等变体。这些变体被称为优化方法(optimization method)或优化器(optimizer)。其中动量的概念尤其值得关注,它在许多变体中都有应用。动量解决了SGD 的两个...
1.批量梯度下降(BGD) 我们所说的梯度下降算法一般都默认是批量梯度下降。我们用每个样本去计算每个参数的梯度后,要将这个梯度进行累加求和 注意这里有一个求和符号,意思就是我们每次计算参数都是用全部的样本来...

强烈推荐:深度学习中优化方法——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam
梯度下降就是最简单的用于神经网络当中用于更新参数的用法,计算loss的公式如下: 有了lossfunction之后,我们立马通过这个loss求解出梯度,并将梯度用于参数theta的更新,如下所示: 这样做之后,我们只需要...
如果收藏star, 有问题可以随时与我交流, 谢谢大家!在深度学习中,优化器被用来调整模型的参数。优化器的目的是调整模型权重以最小化损失函数。回顾一下,我们使用线性类和激活函数类构建了自己的MLP模型,并且已经...
本文我们介绍下不通梯度下降算法的习性,使得我们能够更好的使用它们。本人每次复习这篇论文,或多或少都有一些收获,基础学习扎实了,后面的使用才会得心应手。简介梯度下降算法,不管在机器学习,还是在神经网络中...
就此,提出了基于单个样本的随机梯度下降法(Stochastic gradient descent,SGD)和基于部分样本的小批量梯度下降法(Mini-Batch gradient descent,Mini-batch gradient descent)。 一、随机梯度下降法 随机梯度...
本文讲解了随机梯度下降的原理,并通过自编随机梯度下降代码并应用到线性回归求解中,让读者深入了解随机梯度的原理。最后与Sklearn自带的批量梯度下降和随机梯度下降进行对比,随机梯度下降尽可能的保证了计算精度...
随机异步随机梯度下降 s文件夹包含随机的Jacobi原型代码和用于生成算法收敛图的脚本。 阅读文件SETTING-UP,以获取有关下载哪些库,在何处找到代码以及如何构建和运行所有内容的说明。 文件matrices / matrix_list....

梯度下降(GD)是最小化风险函数、损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正。 下面的h(x)是要拟合...

梯度下降法作为机器学习中较常使用的优化算法,其有着三种不同的形式:批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)以及小批量梯度下降(Mini-Batch Gradient Descent)。...


梯度下降法(BGD)、随机梯度下降法(SGD)、小批量梯度下降法(MBGD)之间的关系及batch size如何选取 我们都知道,神经网络在更新权值的时候需要先求得损失函数,再由损失函数求得各参数的梯度进行更新,这里就...
它每次迭代时从训练数据中随机选择一个小批量(mini-batch)的样本来计算梯度,然后使用梯度的相反方向更新模型参数。:SGD通常需要大量的迭代来达到收敛,因此可能需要设置一个合适的训练轮数或使用早停策略来确定...
并通过引入Sigmoid函数和梯度公式成功推导出了梯度上升和梯度下降公式,上文分类实例是依据全批量提升上升法,而本文会介绍全批量梯度上升的一种优化算法——随机梯度上升,如果还未懂得逻辑回归思想和推理公式的...
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。这里就对梯度下降法做一个完整的总结。 1. 梯度 在微积分里面,对多元...
一、梯度gradient 在标量场f中的一点处存在一个矢量G,该矢量方向为f在该点处变化率最大的方向,其模也等于这个最大变化率的数值,则矢量G称为标量场f的梯度。 在向量微积分中,标量场的梯度是一个向量场。 标量...
小批量随机梯度下降法(Mini-batch Stochastic Gradient Decent)是对速度和稳定性进行妥协后的产物 小批量随机梯度公式 我们可以看出当b=1时,小批量随机下降法就等价与SGD;当b=N时,小批量就等价于全批量。所以...
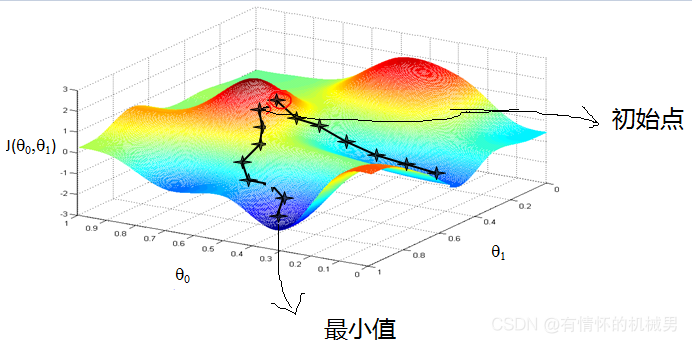
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地