Python爬虫解析工具之xpath使用详解_python xpath用法-程序员宅基地
技术标签: 爬虫 解析工具 xpath lxml库 Python
一、数据解析方式
爬虫抓取到整个页面数据之后,我们需要从中提取出有价值的数据,无用的过滤掉。这个过程称为数据解析,也叫数据提取。数据解析的方式有多种,按照网站数据来源是静态还是动态进行分类,如下:
- 动态网站:字典取值。动态网站的数据一般都是JS发过来的,基本都是json格式数据,我们只需要将json格式转换为字典进行取值。
- 静态网站:xpath取值 + 正则取值。
说明:爬虫开发中,用的最多的数据解析方式是字典取值和xpath取值,占到80%以上,其余的少部分是正则取值。
二、xpath介绍
xpath全称XML Path Language,即XML路径语言。它是一门在XML文档中查找信息的语言,最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
xpath的选择功能十分强大,它提供了非常简明的路径选择表达式。另外,它还提供了众多的内建函数,用于字符串、数值、时间的匹配处理等,几乎所有我们想要定位的节点,都可以用XPath来选择。
三、环境安装
1. 插件安装
很多爬虫的初学者由于对解析工具语法的不熟练,经常会有这种情况:抓来的数据经过解析之后发现不是自己要的,就会多次调试代码,直至提取出精确的价值数据,这样就会导致爬虫多次频繁请求网站,结果自己的IP被网站封掉。那有没有好的办法规避这种情况呢?
有的,Chrome浏览器支持众多插件,其中就有适合xpath语法的元素查找插件:XPath Helper,在谷歌应用商店可以搜索安装,安装好之后图标如下图所示:
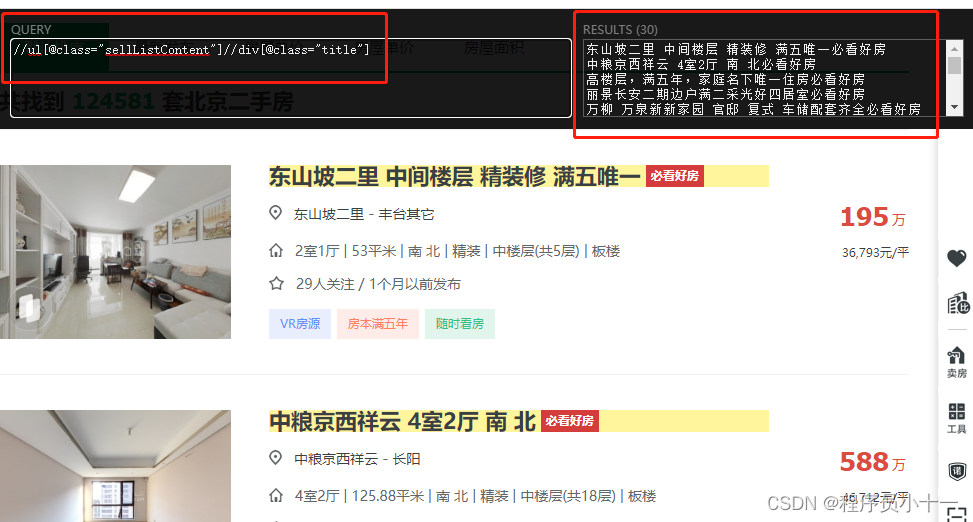
使用该插件的方法很简单,在Chrome浏览器中,打开任意网页之后,同时按下 Ctrl+Shift+X 键就可以看到网页上方的XPath Helper调试窗口,左边窗口是要输入的xpath语法,右边窗口是该xpath语法定位出的结果展示。这样就非常方便我们写爬虫项目,如果不确定解析出的结果是不是我们想要的,就可以先在调试窗口中多次调试,结果没有错误,再直接把该代码复制到我们的爬虫代码中运行,如下图:
2. 依赖库安装
在Python代码中,若要使用xpath解析,需要安装lxml这个第三方库,它对xpath语法提供了良好的支持,安装lxml库步骤如下:
1.同时按下win + R键,打开运行框,在里面输入cmd,点击确定。
2.来到控制台中,输入安装命令:pip install lxml -i https://mirrors.aliyun.com/pypi/simple/,然后按下回车键,等候安装完成,出现“Successfully installed …”字样即为安装成功。

四、xpath语法
xpath语法,也叫xpath路径表达式。因为xpath查找内容是按照HTML代码的标签树结构搜索的,每一个标签都有自己的父标签和子标签,比如下图这组HTML代码所示:
<body>
<div>
<a href="/ershoufang/dongcheng/" title="北京东城在售二手房 ">东城</a>
<a href="/ershoufang/xicheng/" title="北京西城在售二手房 ">西城</a>
<a href="/ershoufang/chaoyang/" title="北京朝阳在售二手房 ">朝阳</a>
<a href="/ershoufang/haidian/" title="北京海淀在售二手房 ">海淀</a>
</div>
</body>
代码中的 body 标签就是 div 标签的父标签,同理,div 标签是 body 标签的子标签。标签之间的这种父子关系用xpath语法表示的话就是用 / 分隔,比如我们要找 a 标签,xpath写法就是:div/a,或者 body/div/a。这种就类似我们的电脑上面文件路径表示方法,故而,xpath语法又叫xpath路径表达式。
看到上面这些,有的小伙伴可能会纳闷:既然找 a 标签,干嘛不直接写 a 就行了,怎么写这么多父子关系进行约束呢?是不是多此一举了?

没关系,看看下面这组代码图片:
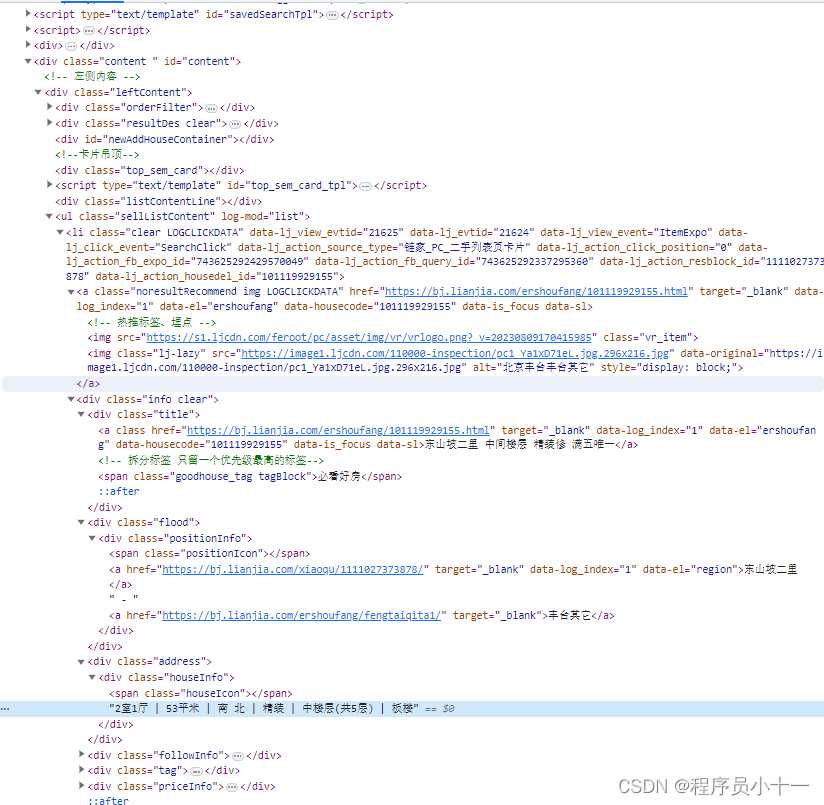
如果说要在上面这组代码中找到高亮显示的这行 “2室1厅 | 53平米 | 南 北 | 精装 | 中楼层(共5层) | 板楼” 文字,单单输入 span 标签能找到吗?显然不能,因为里面有多个 span 标签,所以,使用xpath路径表达式的用意,就是希望使用标签的父子关系约束,来精确定位到我们要找的那个标签。
讲了这么多,接下来我们就看看xpath路径表达式的常用规则。使用xpath规则匹配查找的源码如下:
<body>
<div>
<a href="/ershoufang/dongcheng/" title="北京东城在售二手房 ">东城</a>
<a href="/ershoufang/xicheng/" title="北京西城在售二手房 ">西城</a>
<a href="/ershoufang/chaoyang/" title="北京朝阳在售二手房 ">朝阳</a>
</div>
</body>
/ 表示两个相邻元素节点关系,也可以说父子关系
用法示例:如果要找上述代码中的 a 标签,路径表达式为:div/a
注意:如果当前查找出来的标签有多个,比如上面查找到的 a 标签有3个,我们想要第2个,写法就是 div/a[2],同理,我们需要第几个标签,就在标签后面加上[顺序值]
// 表示两个不相邻元素节点关系,也可以说爷孙这种隔代关系
用法示例:还是从上述代码中找 a 标签,路径表达式还可以写为:body//a
注意:// 也表示从任意位置开始检索,而不考虑它们的位置。xpath查找标签的顺序正常是从HTML文档头部开始查找,当一个HTML文档中标签非常多,我们查找的标签位于文档的中间某位置。如果直接从头部标签开始一级级往下检索,非常繁琐。用 “// + 标签名” 就相当于从该标签开始检索书写。比如我们还是要找 a 标签,可以写成 //a。
. 指代当前节点,比如xpath路径表达式找到某个元素后,想在此元素基础上往后面查找其他元素,那么前面的路径表达式就可以省略,用 . 替换
@ 选取属性,作用就是更精确定位某个标签
用法示例:比如上面我们正常查找的 a 标签是有3个,我们还是要找第2个 a 标签,已经学了一种方法就是 a 标签后面加上[顺序值]。但是如果 a 标签有几十个呢,我们就要一个个数顺序,很繁琐也容易出错。这时候就可以通过标签自身的属性值来精确定位某个标签。我们仔细可以看出上面的每个 a 标签里面的 href 和 title 两个属性值都是彼此不同的,那我们要找第2个,可以这样写://a[@href=“/ershoufang/xicheng/”] 或者 //a[@title="北京西城在售二手房 "]。格式就是:标签名[@属性名=属性值]
text() 提取标签中的文本内容
用法示例:上面的几种方式定位的都是某个标签,如果要拿到标签中的详细内容,比如要拿到第2个 a 标签的文本内容 “西城”这两个字,写法是://a[@title="北京西城在售二手房 "]/text()。格式是:标签/text()
注意:/text()一定要写在标签及标签属性值后面,因为属性值是修饰该标签的,可以精确定位到某个标签,其次后面才加/text(),表示该标签的文本内容。当然定位的标签如果无需属性值作为修饰即可找到,则直接就是标签名加上/text()。
@属性名 提取标签内指定属性名的属性值
用法示例:上面我们提取了标签的文本内容,但是有时候可能需要提取标签内的某个属性名对应的属性值。比如要提取第2个 a 标签中 title 的属性值 “北京西城在售二手房” 这句话,写法是://a[@title="北京西城在售二手房 "]/@title 或者 //a[2]/@title 都可以。格式是:标签/@属性名
以上就是开发中最常见的xpath表达式,记住这些对于日后解析爬虫来说就完全够用了。当然xpath还有许多其他路径表达式,有兴趣的小伙伴也可以额外探索。
五、xpath语法在Python代码中的使用
上面介绍的只是xpath路径表达式,但是如何实际在Python代码中使用呢?这就需要用到上面提到的依赖库 lxml 了。因为我们用爬虫抓取到的网页源码虽然是HTML文档,但是其实是字符串类型的数据,如下图抓取房源信息代码所示:
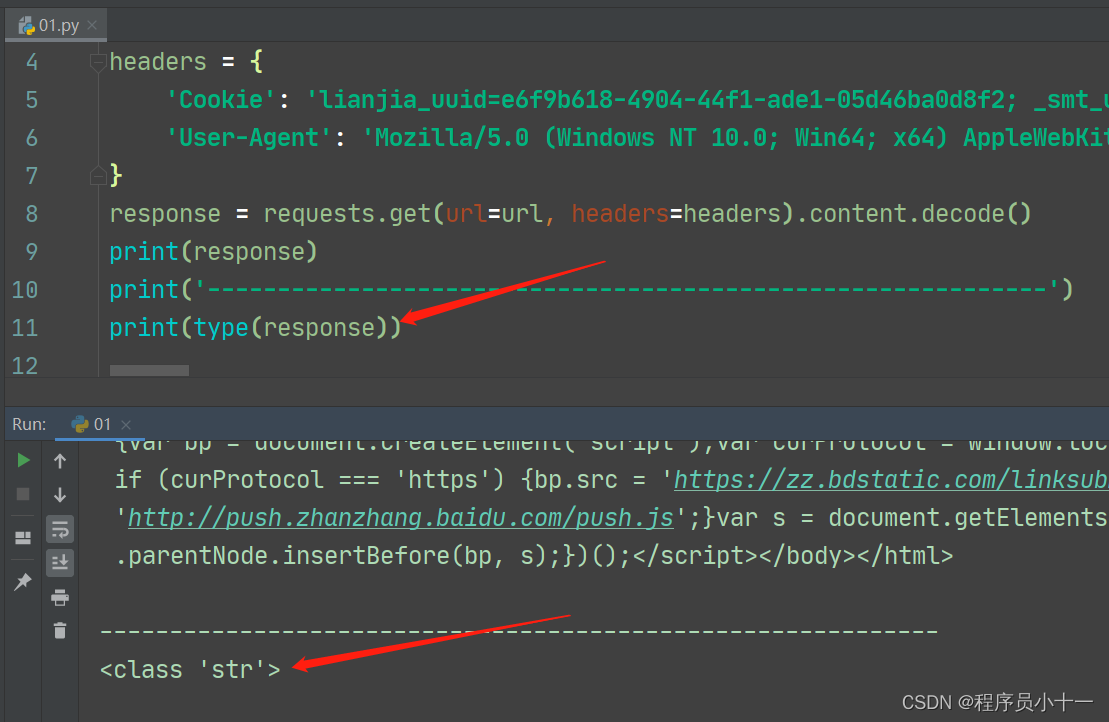
而xpath解析的是html或者lxml文档中的标签元素对象,不是字符串。我们就需要将抓到的字符串类型源码转换为html或者lxml文档中的标签元素对象,然后就可以正常使用xpath路径表达式进行解析查找。
如何将字符串内容转换成标签元素对象,要使用 lxml 库里面的 etree 模块中的 HTML() 方法,语法格式如下:
from lxml import etree # 导入 lxml 库中的 etree 模块
变量名 = etree.HTML(网页源码) # 使用 etree 模块的 HTML() 方法,括号中就是爬虫拿到的字符串类型的网页源码,将转换后的标签对象用变量保存
代码示例如下图所示:
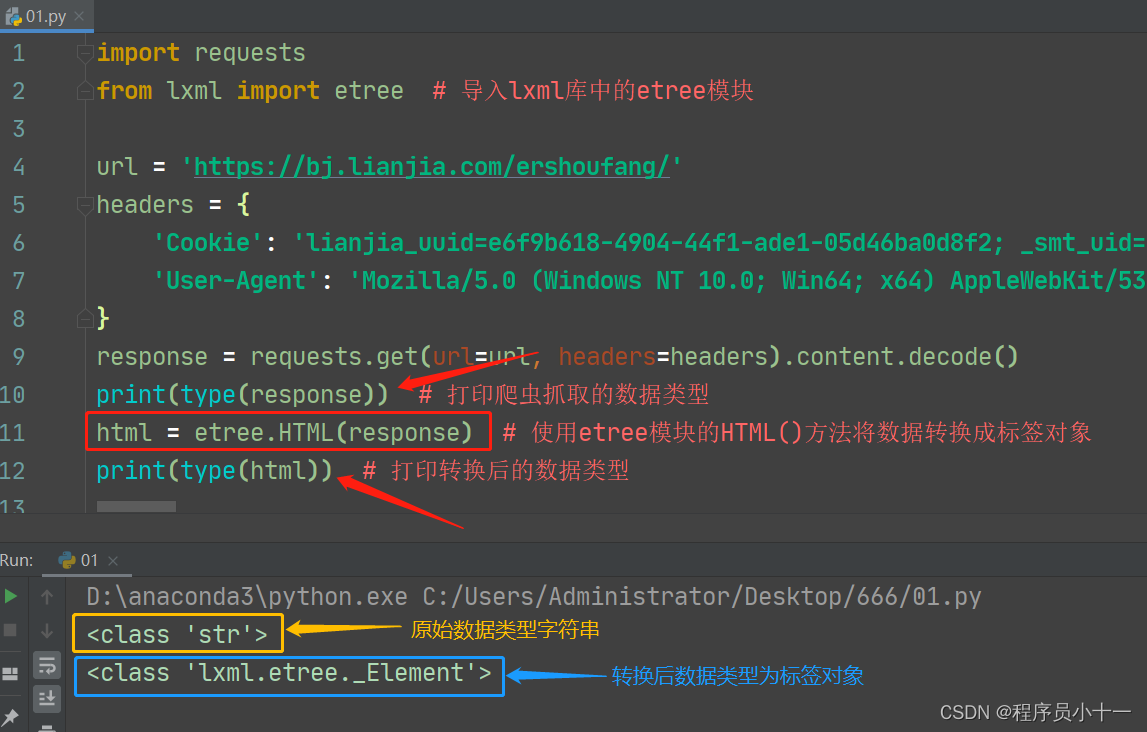
转换为标签元素对象之后,就可以正常使用上面介绍的xpath路径表达式了,语法格式如下:
标签元素对象.xpath('路径表达式') # 标签元素对象就是我们刚刚转换好的,括号里面的是双引号或者单引号都可以,包裹的就是路径表达式
代码示例如下图所示:
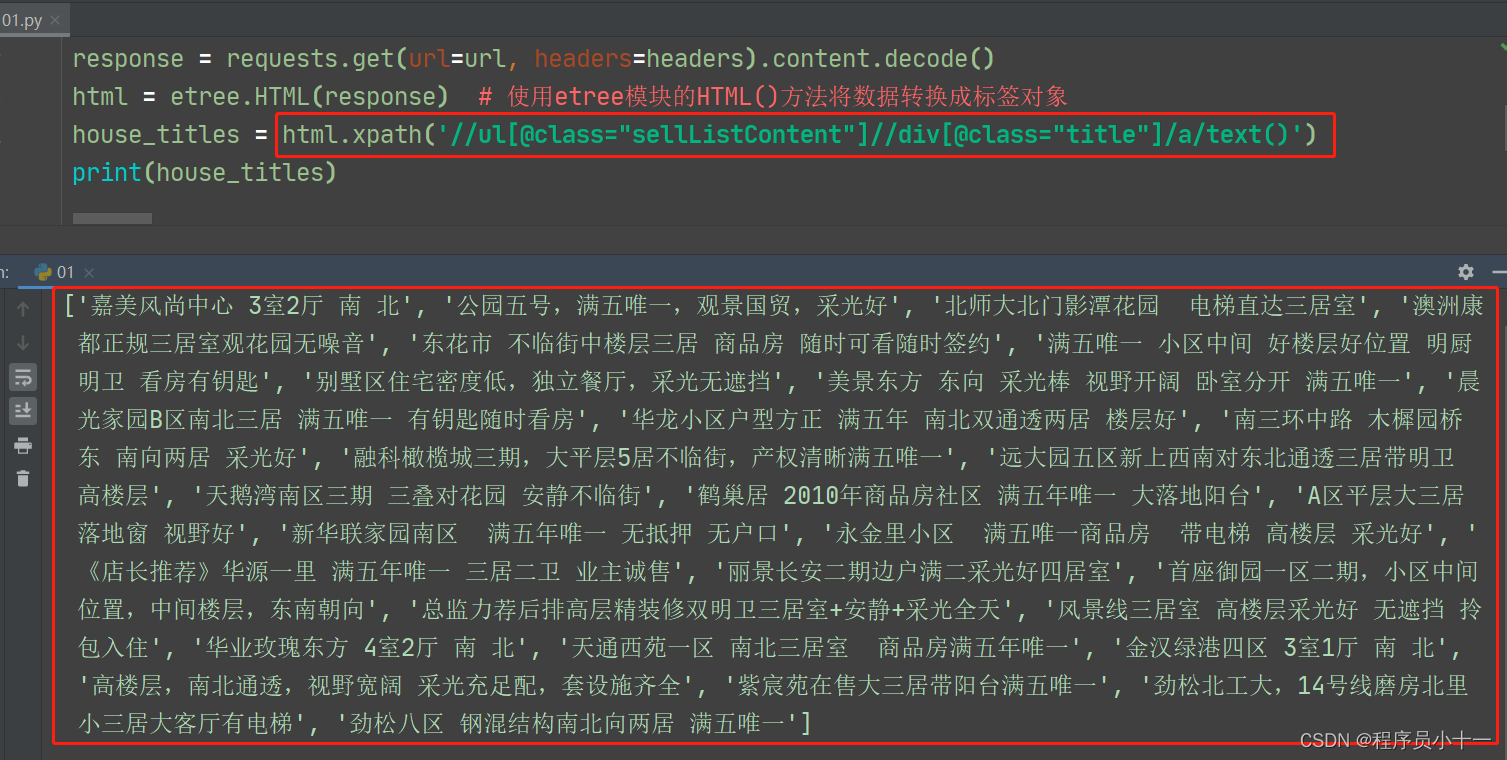
注意:在Python代码中,xpath路径表达式最终拿到的解析结果是以列表形式返回的,如果没有解析到目标数据,结果为空列表。
智能推荐
使用HttpURLConnection发送POST请求并携带请求参数-程序员宅基地
文章浏览阅读1.3w次,点赞12次,收藏39次。使用HttpURLConnection发送POST请求并携带请求参数_urlconnection发送post请求
钉钉OA流程审批,Jenkins自动授权通知用户密码_jenkins调用公司oa-程序员宅基地
文章浏览阅读3.6k次。公司目前的软件版本发布是通过Jenkins来执行的,发布版本需要通过相关的OA流程,审批通过后由运维管理员操作。该流程审批过程通知不及时,运维管理员工作量大。为了简化jenkins版本发布流程,使开发人员能更灵活的控制版本的更新迭代,现准备将Jenkins的版本发布流程,从OA系统转到钉钉软件。在钉钉的OA工作台上提交版本发布流程,审批通过过,钉钉将自动发送Jenkins登陆帐号密码给申请人,帐号密码有一定的有效期,到期后帐号权限自动收回。..._jenkins调用公司oa
神经网络结构:DenseNet-程序员宅基地
文章浏览阅读6.9k次,点赞20次,收藏139次。论文地址:密集连接的卷积神经网络博客地址(转载请引用):https://www.cnblogs.com/LXP-Never/p/13289045.html前言 在计算机视觉还是音频领域,卷积神经网络(CNN)已经成为最主流的方法,比如最近的GoogLenet,VGG-19,Incepetion、时序TCN等模型。CNN史上的一个里程碑事件是ResNet模型的出现,Res..._带denseblock的神经网络结构
win10下设置maven环境变量_maven环境 win-程序员宅基地
文章浏览阅读4w次,点赞7次,收藏23次。一、 先去maven官网:http://maven.apache.org/download.cgi#下载压缩包,下拉页面可以看到好多版本,注意下载的版本为红色标注版本:apache-maven-3.5.0-bin.zip,点击下载即可。 二、 将下载好的压缩包解压到任意目录_maven环境 win
树莓派如何与物联网平台交互(搭建一个树莓派网关)(一)_树莓派 家庭网关-程序员宅基地
文章浏览阅读1.4w次,点赞14次,收藏84次。一、功能描述 树莓派网关采集485温湿度传感器以及485门磁开关状态数据上报到涂鸦云平台;同时收到云端的指令,树莓派网关处理之后,控制继电器动作,同时继电器返回当前的状态给云端。树莓派与涂鸦云平台交互代码:demo1下载地址树莓派与485子设备通信代码: demo2下载地址二、硬件准备树莓派(Pi4B) 树莓派有两个串口可以使用,一个是硬件串口(/dev/ttyAMA0),另一个是mini串口(/dev/ttyS0)。硬件串口有单独的波特率时钟源,性能好,稳定_树莓派 家庭网关
使用docker安装jdk、tomcat、mysql、nginx-程序员宅基地
文章浏览阅读2.3k次,点赞2次,收藏18次。使用docker安装jdk、tomcat、mysql、nginx_docker安装jdk
随便推点
Qt开发经验(转载)_qtchina-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏28次。本文转载于https://qtchina.blog.csdn.net/?type=blog,feiyangqingyun的博客,感谢大佬的经验分享。默认QtCreator是单线程编译,可能设计之初考虑到尽量不过多占用系统资源,而现在的电脑都是多核心的,默认msvc编译器是多线程编译的不需要手动设置,而对于其他编译器,需要手动设置才行。方法一:在每个项目的构建设置中(可以勾选一个 shadow build 的页面地方)的build步骤,make arguments增加一行 -j16 即可,此设置会保_qtchina
Java中线程安全的List_java 静态一个 线程安全list-程序员宅基地
文章浏览阅读3.4w次,点赞10次,收藏27次。简单说一下java中线程安全的List一、VectorVector是大家熟知的线程安全的List集合,不过他的性能是最差,所有的方法都是加了synchronized来同步,从而保证线程安全。源码也是使用数组来存储数据,有以下构造方法。 /** * Constructs an empty vector with the specified initial c..._java 静态一个 线程安全list
ASC文件 - CAN报文回放_asc格式can报文-程序员宅基地
文章浏览阅读8k次。打开CANoe10.0,将*.asc文件拖进trace窗口。即可打开*asc文件。_asc格式can报文
HTTP Status 404 – Not Found Type Status Report Description The origin server did not find a current_http status 404 – not found type status report des-程序员宅基地
文章浏览阅读3.6k次,点赞2次,收藏2次。HTTP Status 404 – Not FoundType Status ReportDescription The origin server did not find a current representation for the target resource or is not willing to disclose that one exists.解决:完全停止Tomcat,..._http status 404 – not found type status report description the origin serve
带你用 Python 实现自动化群控(入门篇)-程序员宅基地
文章浏览阅读1.7k次,点赞3次,收藏22次。点击上方“Python爬虫与数据挖掘”,进行关注回复“书籍”即可获赠Python从入门到进阶共10本电子书今日鸡汤别君去兮何时还?且放白鹿青崖间。须行即骑访名山。1. 前言群控,相信大部..._自己写群控
带你真正认识Linux 系统结构_带你真正认识linux系统结构-程序员宅基地
文章浏览阅读2.5k次,点赞2次,收藏16次。带你真正认识Linux 系统结构Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序。内核、shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。1. linux内核内核是操作系统的核心,具有很多最基本功能,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。Linu_带你真正认识linux系统结构