深入探索卷积神经网络的进化,从经典架构到现代创新-程序员宅基地
1. VGG Net
1.1 VGG Net的认识
**VGG Net的主要特点是将卷积层的深度增加到了极致,使用了多个 3x3 的卷积核进行卷积操作,增加了网络的深度,从而提高了网络的准确性。**VGG Net 的网络结构非常简单,只包含卷积层、池化层和全连接层,没有任何其他的复杂结构,因此在理解上也很简单。
VGG Net总共有两个版本,分别是VGG16和VGG19,它们的网络结构非常相似,只是深度不同。其中,VGG16包含13个卷积层和3个全连接层,VGG19则包含16个卷积层和3个全连接层。这些卷积层和全连接层都使用了ReLU激活函数和Dropout正则化技术,以避免过拟合。
VGG Net的优点是它的网络结构非常清晰,易于理解和实现,同时具有较高的准确性。但是,由于网络很深,因此训练时间较长,同时也存在过拟合的问题。另外,VGG Net 的参数量非常大,因此需要较大的存储空间和计算资源。

1.2 VGG Net为什么出现模型退化的问题?
VGG Net存在模型退化的问题,这主要是由于网络的深度过大所导致的。(本质上就是学习的太多了,每加一层线性转换,你的特征就会发生一次变换,导致变化过多了所以和原始特征之间的相关性会很弱甚至基本消失了)
在深度卷积神经网络中,增加网络的深度可以有效地提高模型的准确性。然而,当网络的深度达到一定程度时,模型的准确性反而开始下降,出现了所谓的模型退化(Degradation Problem)现象。模型退化指的是,随着网络深度的增加,训练误差会逐渐降低,但测试误差却会先降低后增加。
VGG Net作为一个非常深的卷积神经网络,也存在模型退化的问题。实验结果表明,在VGG Net的网络结构中,当网络深度达到19层时,模型退化现象就开始出现了。
2.GoogleNet (其实就是Inception的重复)
- Inception模块:GoogleNet最大的特点之一是使用了Inception模块。传统的卷积神经网络通常使用多层串联的卷积操作来提取特征,但这会导致参数数量巨大。相比之下,Inception模块通过并行地进行多个不同尺度的卷积操作,然后将它们的输出连接在一起,以捕获不同层级的特征。这种多分支结构帮助GoogleNet有效地处理不同尺度的对象,并减少了参数的数量。
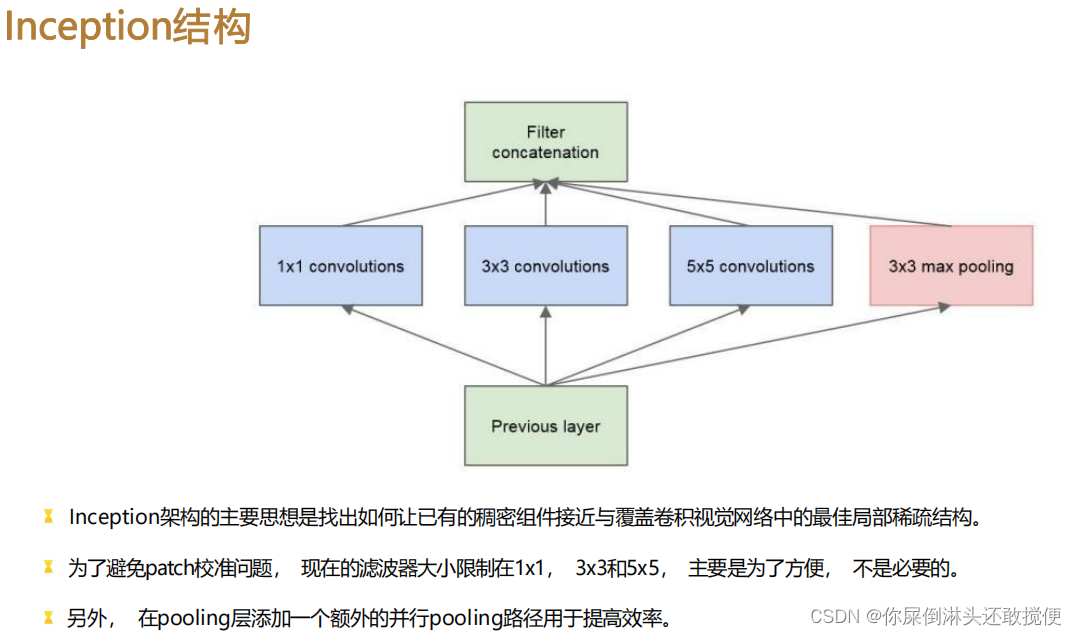
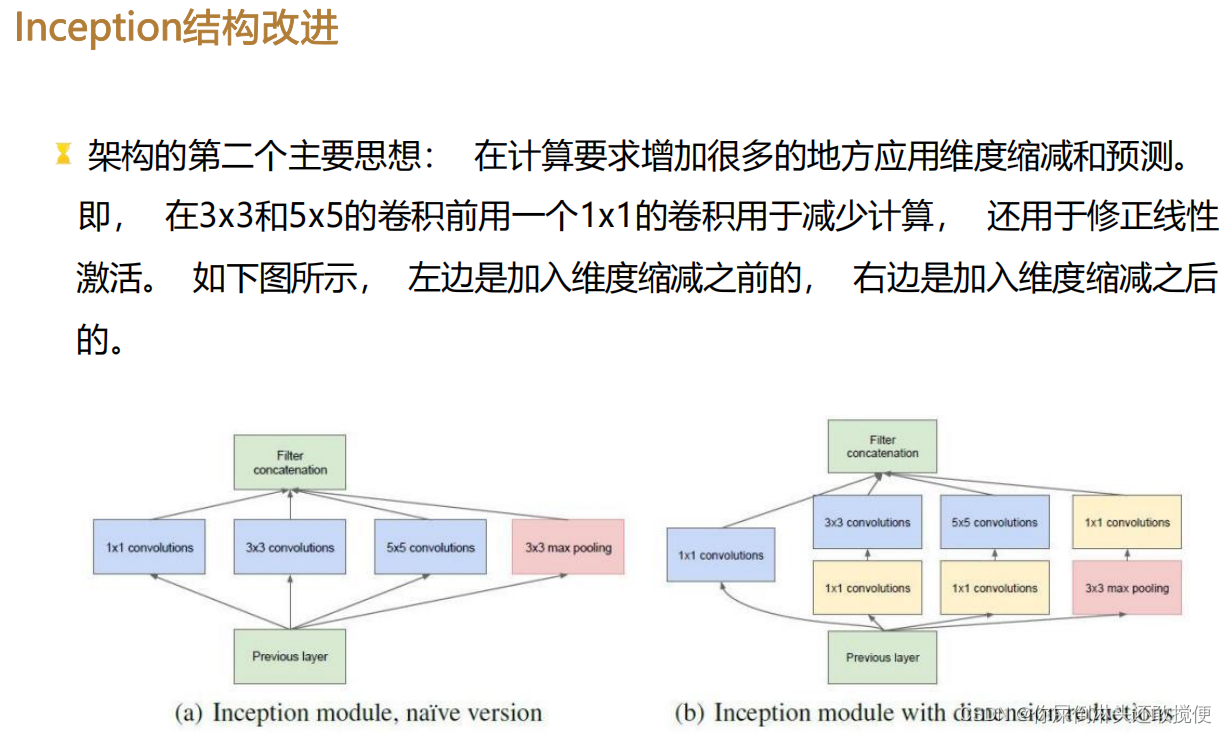
- 1x1卷积核的重要性:GoogleNet在Inception模块中广泛使用1x1卷积核。1x1卷积核主要用于降低特征图的维度,减少计算复杂度。此外,1x1卷积核还可以引入非线性激活函数,帮助模型更好地学习特征表示。通过合理使用1x1卷积核,GoogleNet能够在保持高准确率的同时大幅度减少网络参数量。
- 辅助分类器:为了缓解梯度消失的问题,GoogleNet在中间层添加了辅助分类器。这些辅助分类器有助于网络进行训练,并且在测试阶段提供额外的梯度信号。辅助分类器在损失函数中引入了额外的权重,以鼓励网络更早进行特征学习,从而加速训练过程。在测试时,这些辅助分类器被移除,只使用主分类器进行预测。
- 全局平均池化:与传统的卷积神经网络使用全连接层不同,GoogleNet采用了全局平均池化层。全局平均池化将每个特征图的空间维度降为1x1,并在通道维度上求平均值。这种操作极大地减少了参数数量,并有助于减轻过拟合的风险。全局平均池化层使得GoogleNet成为一个高效的模型,适用于嵌入式设备等资源受限的环境。
- 参数量控制与计算效率:GoogleNet通过Inception模块和1x1卷积核的使用,有效地控制了网络的参数量。相比于传统的卷积神经网络,GoogleNet在相同准确率下具有更小的参数量,提高了模型的效率和可训练性。此外,GoogleNet还通过减少卷积操作的数量,降低了整体计算复杂度。



总结起来,GoogleNet通过引入Inception模块、1x1卷积核、辅助分类器和全局平均池化等创新技术,在图像分类任务中取得了重大突破。它不仅在准确率方面表现优异,而且在参数量和计算效率方面也具备显著优势。
3. Inception V2
3.1Inception V2的特点
- 批标准化(Batch Normalization):Inception V2引入了批标准化,通过规范化每个神经网络层的输入,有助于提高模型的收敛速度,加速训练过程,同时有助于避免梯度消失或爆炸的问题。
- **更深的网络结构:**相对于Inception V1,Inception V2拥有更深的网络结构,通过增加层的深度来提高模型的表达能力,更好地捕捉图像中的抽象特征。
- **优化的Inception模块:**Inception V2对Inception模块进行了优化,采用了更小的滤波器尺寸和更深的结构,以减少参数数量和计算成本。这有助于提高模型的计算效率。
- **辅助分类器:**为了加速模型的训练,Inception V2引入了辅助分类器。这些辅助分类器位于网络的中间层,通过提供额外的梯度流,有助于避免梯度消失问题,从而加速整个网络的训练过程。
3.2Inception V2和之前的GoogLeNet(Inception V1)做了什么改进?
- 引入了批标准化(Batch Normalization),这有助于加速模型的训练过程,提高模型的收敛速度。
- 采用更小的滤波器(把大卷积改成小卷积———计算量减少30%)和更深的结构,减少了参数数量和计算成本。
- 引入了辅助分类器,以提高梯度流,加速训练。
4.Inception V3
Inception V3是Google Inception系列中的第三个版本,也被称为GoogLeNet V3。它是Inception V1和V2的进一步改进,致力于提高深度神经网络在计算机视觉任务中的性能。
4.1Inception V3的特点
- 优化的Inception模块: Inception V3继续优化了Inception模块,采用了更丰富的模块设计,包括使用更小的滤波器、更大的卷积核、并引入了扩张卷积(Dilated Convolution)等技术,以提高模型的表达能力。
- 辅助分类器的改进: 类似于Inception V2,Inception V3引入了辅助分类器,但在设计上进行了改进。这有助于更好地传播梯度,促进模型的训练过程。
- 更深的网络结构: Inception V3相较于前一版本,进一步增加了网络深度,提高了对复杂特征的学习能力。
- 批标准化(Batch Normalization)的应用: 继续使用批标准化来加速模型的训练过程,提高模型的收敛速度。
- 卷积操作的改进: 引入了一些新的卷积操作,例如分解卷积(Factorized Convolution),有助于减少参数数量和计算复杂性。
- 更好的图像分类性能: Inception V3在图像分类任务上表现出色,尤其在ILSVRC 2015图像分类竞赛中获得了较好的成绩。
5.ResNet
5.1 什么是ResNet?

ResNet,全称为Residual Networks,是由Microsoft Research提出的一种深度学习神经网络架构。ResNet的主要创新是引入了残差学习的概念,通过使用残差块(Residual Block)来解决深度神经网络训练中的梯度消失和梯度爆炸问题。
在深度神经网络中,随着网络层数的增加,梯度逐渐减小,导致梯度消失。这使得网络在训练过程中难以学习到有效的特征表示,限制了模型的性能。
ResNet的残差学习的基本思想是,对于一个层的输入 x 和输出 H(x),网络不再学习整个映射 H(x),而是学习残差 F(x) = H(x)−x。这样,原始的映射可以被表示为 F(x)+x。通过这种残差连接,梯度可以直接传播到较早层,有助于提高网络的训练效率。这种设计使得网络可以更轻松地训练数百层甚至上千层的深度。
ResNet的典型结构包括多个堆叠的残差块,每个块内包含多个卷积层。**网络末尾通常包括全局平均池化层和全连接层,用于输出最终的分类结果。**ResNet在图像分类、目标检测等计算机视觉任务中取得了显著的成功,成为深度学习领域的重要里程碑之一。
ResNet其实可以看成和Inception一样是一个分支结构,只不过Inception分支上有卷积池化的操作,而ResNet没有这个操作。
分支结构加强了特征的提取能力,增加特征的多样性


6.DenseNet
6.1 什么是DenseNet?
DenseNet(Dense Convolutional Network)是一种具有密集连接的卷积神经网络, 在这个网络结构中任意两层之间均存在直接连接, 也就是说每一层的输入都是前面所有层输出的并集, 而该层所学习的特征图也会被直接传给其后面所有层作为输入。 DenseNet中的dense connectivity仅存在一个dense block中,不同dense block块之间是没有dense connectivity的。

6.2DenseNet的特点
密集连接的优点,缓解梯度消失的问题,能加强特征传播,增加特征复用,极大的减少参数量。

7.SeNet
7.1SeNet的理解
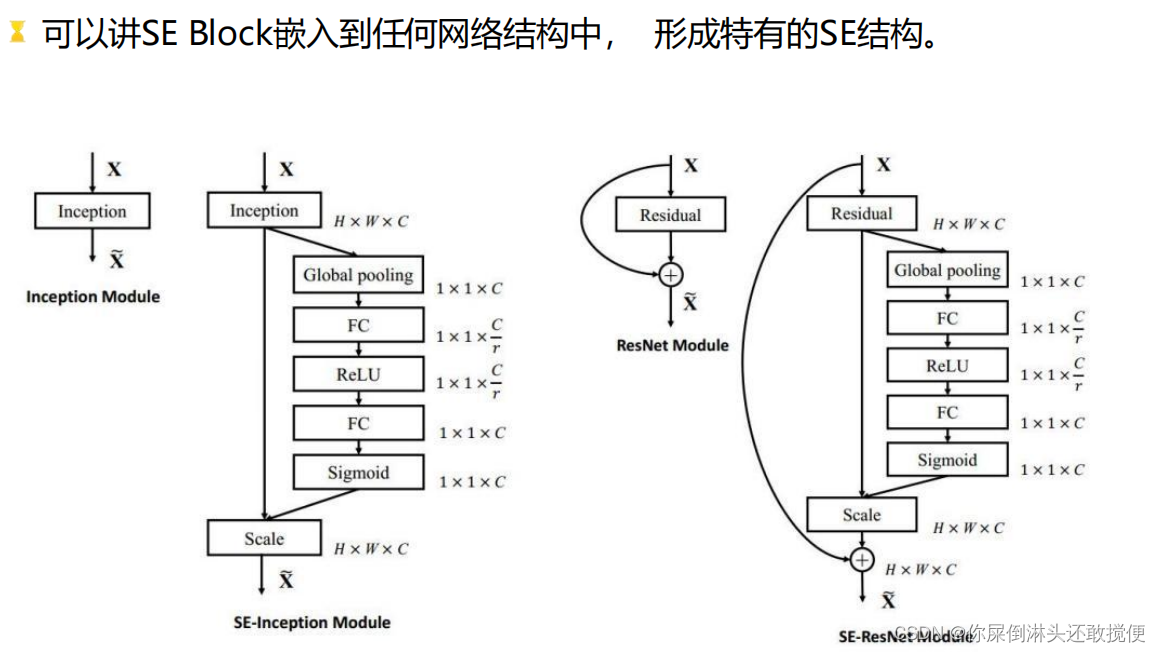
SeNet (Squeeze-and-Excitation Networks)是ImageNet 2017年分类任务冠军,**核心思是 : Squeeze(挤压、压缩)和 Excitation(激励)**两个操作其主要目的是通过显示的构建特征通道之间的相互依赖关系,采用特征重定向的策略,通过学习的方式自动的获取每个特征通道的重要程度, 然后依据这个重要程度去提升有用的特征,并抑制对于当前任务用处不大的特征。





8.Residual Attention Networks
8.1Residual Attention Networks的理解
Residual Attention Networks利用Residual和Attention机制进行网络结构的堆叠, 从而得到一个更深入的特征信息, 在每个attention module中会做一个适应性的变化, 采用上采样和下采样的结构。
8.2特点
- Stacked Network Structure: 堆叠多个attention module来构建网络结构。
- Attention Residual Learning: 一种优化思想, 类似ResNet中基于残差的更新方式,可以让模型具有更好的性能。
- Bottom-up top-down feedforward attention: 基于下采样-上采样的机制, 将特征权重加入到特征图中。
9. LeNet-5 (了解)
LeNet-5模型是一个非常经典的卷积神经网络(CNN)模型,它在手写数字识别任务上取得了很好的性能。
9.1 LeNet-5的模型结构
LeNet-5模型由两个部分组成:特征提取部分和分类器部分:
- 特征提取部分:这一部分主要用于提取输入图像的特征。它包含多个卷积层、池化层和激活函数。卷积层通过卷积运算来提取图像的局部特征,池化层则通过降采样操作来减小特征图的尺寸并保留重要的特征信息。激活函数引入非线性,增加模型的表达能力。
- 分类器部分:这一部分用于将提取的特征映射到对应的类别。它包括多个全连接层和激活函数。全连接层将特征图展平为向量,并通过多个全连接层进行映射,最后使用激活函数得到最终的分类结果。
9.2 输入数据
LeNet-5模型接受灰度图像作为输入,图像的尺寸为32x32。在输入之前,通常需要对图像进行预处理,例如将像素值归一化到[0, 1]的范围,并进行中心化操作。

import torch
import torch.nn as nn
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.features = nn.Sequential( # nn.Sequential 是PyTorch提供的一个容器,用于按照顺序组合各个层,形成一个网络模块
nn.Conv2d(in_channels=1, out_channels=20, kernel_size=(5, 5), stride=(1, 1), padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)),
nn.Conv2d(in_channels=20, out_channels=50, kernel_size=(5, 5), stride=(1, 1), padding=0),
nn.ReLU(),
# nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
nn.AdaptiveMaxPool2d(output_size=(4, 4)) # 自适应池化,不管输入的feature map是多大,强制要求输出的feature map大小必须是output_size大小
)
self.classify = nn.Sequential( # 定义了神经网络的分类器部分,其中包括两个全连接层和一个ReLU激活函数
nn.Linear(50 * 4 * 4, 500), # 定义了一个全连接层,输入的大小为50x4x4=800,即特征提取部分的输出展平后的大小,输出的大小为500
nn.ReLU(),
nn.Linear(500, 10)
)
def forward(self, x):
"""
:param x: 原始图像数据, [N,1,28,28]
:return:
"""
z = self.features(x) # [N,1,28,28] -> [N,50,4,4]
z = z.view(-1, 800) # 将特征图z进行reshape操作,将其展平成一维向量
z = self.classify(z) # 将展平后的特征向量z输入到分类器部分self.classify中进行分类
return z
if __name__ == '__main__':
net = LeNet()
img = torch.randn(2, 1, 28, 28)
scores = net(img) # [N,1,28,28] -> [N,10] 获得得到的是每个样本属于10个类别的置信度
print(scores)
probs = torch.softmax(scores, dim=1) # 求解概率值
# print(probs)
10. AlexNet (了解)
10.1 AlexNet模型结构
AlexNet模型包含8个层次,其中有5个卷积层和3个全连接层。具体而言,模型的结构如下:
- 输入层:接收原始图像数据。
- 第一个卷积层:输入为输入层,使用96个11x11的卷积核,步长为4,输出特征图大小为55x55x96。
- 第一个LRN层:对第一个卷积层的输出进行局部响应归一化处理。
- 第一个池化层:使用3x3的最大池化操作,步长为2,输出特征图大小为27x27x96。
- 第二个卷积层:输入为第一个池化层的输出,使用256个5x5的卷积核,步长为1,输出特征图大小为27x27x256。
- 第二个LRN层:对第二个卷积层的输出进行局部响应归一化处理。
- 第二个池化层:使用3x3的最大池化操作,步长为2,输出特征图大小为13x13x256。
- 第三个卷积层:输入为第二个池化层的输出,使用384个3x3的卷积核,步长为1,输出特征图大小为13x13x384。
- 第四个卷积层:输入为第三个卷积层的输出,使用384个3x3的卷积核,步长为1,输出特征图大小为13x13x384。
- 第五个卷积层:输入为第四个卷积层的输出,使用256个3x3的卷积核,步长为1,输出特征图大小为13x13x256。
- 第三个池化层:使用3x3的最大池化操作,步长为2,输出特征图大小为6x6x256。
- 第一个全连接层:将第三个池化层的输出展平为向量,然后用4096个神经元进行映射。
- 第二个全连接层:使用4096个神经元进行映射。
- 第三个全连接层:使用1000个神经元进行映射,对应于ImageNet数据集的1000个类别

import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, device1, device2):
super(AlexNet, self).__init__()
self.device1 = device1
self.device2 = device2
self.feature11 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=48, kernel_size=(11, 11), stride=(4, 4), padding=2),
nn.ReLU(),
nn.LocalResponseNorm(size=10),
nn.MaxPool2d(3, 2),
nn.Conv2d(48, 128, kernel_size=(5, 5), stride=(1, 1), padding='same'),
nn.LocalResponseNorm(size=30),
nn.ReLU(),
nn.MaxPool2d(3, 2),
).to(self.device1)
self.feature21 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=48, kernel_size=(11, 11), stride=(4, 4), padding=2),
nn.ReLU(),
nn.LocalResponseNorm(size=10),
nn.MaxPool2d(2),
nn.Conv2d(48, 128, kernel_size=(5, 5), stride=(1, 1), padding='same'),
nn.LocalResponseNorm(size=30),
nn.ReLU(),
nn.MaxPool2d(3, 2)
).to(self.device2)
self.feature12 = nn.Sequential(
nn.Conv2d(256, 192, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.Conv2d(192, 128, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.MaxPool2d(3, 2)
).to(self.device1)
self.feature22 = nn.Sequential(
nn.Conv2d(256, 192, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.Conv2d(192, 128, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.MaxPool2d(2)
).to(self.device2)
self.classify = nn.Sequential( # 这段代码定义了一个分类器(classifier),它是一个由线性层(Linear)和激活函数ReLU组成的神经网络模型
nn.Linear(6 * 6 * 128 * 2, 4096), # 13×13池化后等于6×6
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, 1000)
).to(self.device1)
def forward(self, x):
x1 = x.to(self.device1) # 将x复制到设备1
x2 = x.to(self.device2) # 将x复制到设备2
# 第一部分特征提取
oz1 = self.feature11(x1)
oz2 = self.feature21(x2)
# 两个通道的特征合并
z1 = torch.concat([oz1, oz2.to(self.device1)], dim=1)
z2 = torch.concat([oz1.to(self.device2), oz2], dim=1)
# 第二部分特征提取
z1 = self.feature12(z1)
z2 = self.feature22(z2)
# 两个通道的特征合并
z = torch.concat([z1, z2.to(self.device1)], dim=1)
z = z.view(-1, 6 * 6 * 128 * 2)
# 决策输出
z = self.classify(z)
return z
if __name__ == '__main__':
device1 = torch.device("cpu")
device2 = torch.device("cpu")
net = AlexNet(device1, device2)
img = torch.randn(2, 3, 224, 224)
scores = net(img)
print(scores)
probs = torch.softmax(scores, dim=1) # 求解概率值
print(probs)
# 参考pytorch中的默认实现
from torchvision import models
net = models.alexnet()
print(net)
11. ZF Net (了解)
11.1 ZF Net和AlexNet的区别之处
- 网络结构不同:ZF Net和AlexNet的网络结构不同。具体来说,ZF Net使用了较小的卷积核(7x7变为3x3),并增加了步幅和填充,以此来增加感受野的大小。同时,ZF Net还在特征图上进行了更多的重叠池化操作。相比之下,AlexNet则采用了较大的卷积核(11x11),并使用了局部响应归一化层来抑制竞争。
- 特征可视化方法不同:ZF Net引入了一种反卷积网络的方法,用于可视化卷积神经网络中的特征。而在AlexNet中,则使用了一个叫做“分层细节网络”的可视化方法,来进一步理解模型中学习到的特征。
- 性能略有不同:虽然ZF Net和AlexNet都在ImageNet图像识别挑战赛上取得了很好的成绩,但ZF Net在某些指标上略微优于AlexNet。具体来说,ZF Net在top-1错误率方面比AlexNet低了0.4%。

import torch
import torch.nn as nn
class ZFNet(nn.Module):
def __init__(self):
super(ZFNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=(7, 7), stride=(2, 2), padding=1),
nn.ReLU(),
nn.LocalResponseNorm(size=30),
nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=1),
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=(5, 5), stride=(2, 2), padding=0),
nn.ReLU(),
nn.LocalResponseNorm(size=50),
nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2), padding=1),
nn.Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding='same'),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(3, 3), stride=(2, 2))
)
self.classify = nn.Sequential(
nn.Linear(6 * 6 * 256, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, 1000)
)
def forward(self, x):
"""
:param x: 原始图像数据, [N,1,224,224]
:return:
"""
z = self.features(x) # [N,1,224,224] -> [N,256,6,6]
z = z.view(-1, 256 * 6 * 6) # reshape
z = self.classify(z)
return z
if __name__ == '__main__':
net = ZFNet()
img = torch.randn(2, 3, 224, 224)
scores = net(img)
print(scores)
probs = torch.softmax(scores, dim=1) # 求解概率值
print(probs)
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象