深度学习修炼(一)线性分类器 | 权值理解、支撑向量机损失、梯度下降算法通俗理解-程序员宅基地
技术标签: python 机器学习 深度学习 计算机视觉CV
文章目录
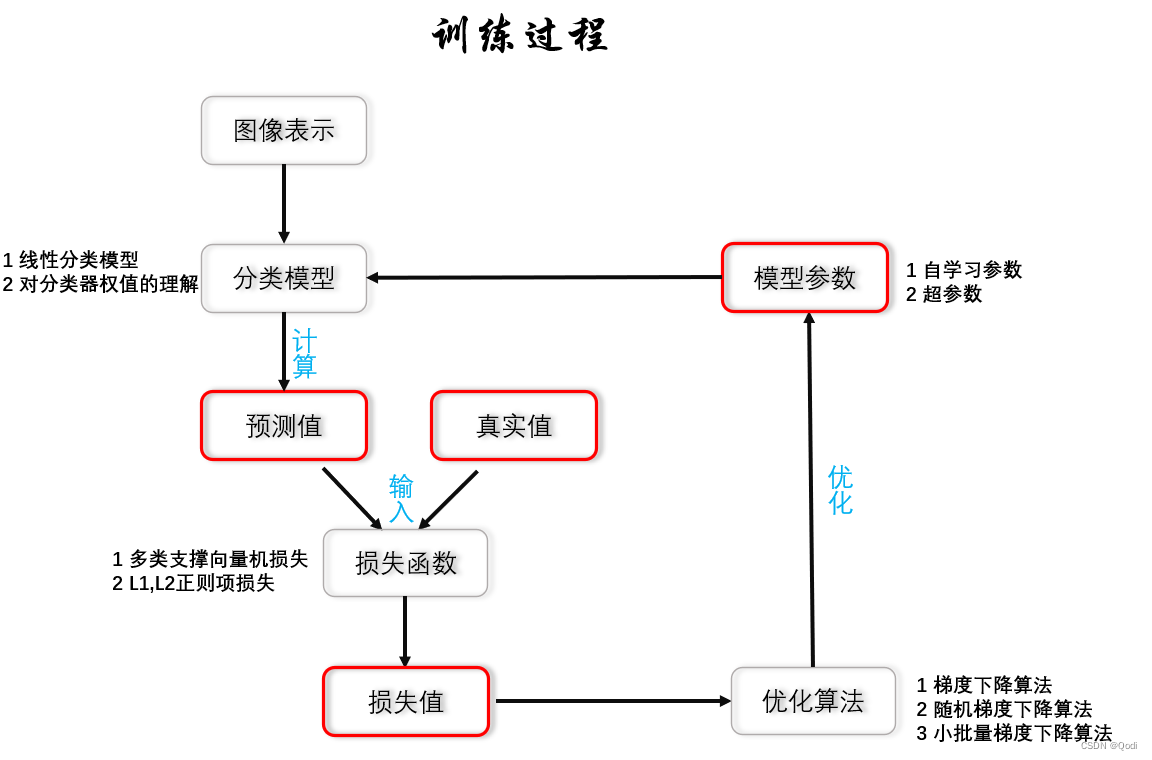
如图是神经网络训练的一般过程总结图
今天从线性分类器开始
为什么我们从线性分类器开始?是由于线性分类器的基本特点决定的
1 基本特点
形式简单、易于理解,通过层级结构(神经网路)或者高维映射(支撑向量机)可以形成功能强大的非线性模型。
从某种意义上来说,未来的卷积网络以及更为复杂的网络都离不开线性分类器
线性分类器是一种线性映射,将输入的图像特征映射为类别分数
2 训练过程
2.1 图像预处理
比如张CIFAR10 中每一张图像像素为32×32 ,每一个(采用RGB)像素通道为3,我们首先要将图片转换为一个向量,转换方式多种,现在我们只做简单的转换方式,用一个32×32×3=3072维的列向量来表示我们这张图片。
2.2 线性分类器构造
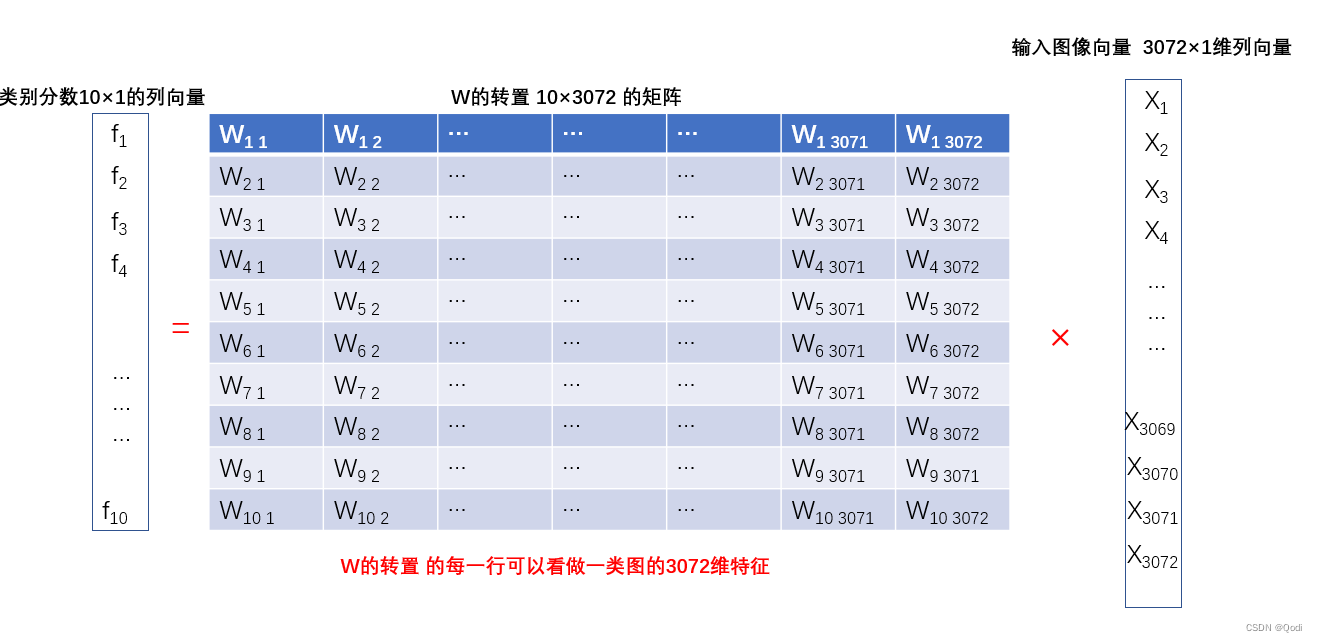
f i ( x , w i ) = w i T x + b i f_i(x,w_i)=w_i^Tx+b_i fi(x,wi)=wiTx+bi i = 1 , . . . , c i=1,...,c i=1,...,c
- x代表输入的d维图像向量 这个例子是3072维度的向量
- w i = [ w i 1 , . . . , w i d ] T w_i=[w_{i1},...,w_{id}]^T wi=[wi1,...,wid]T为第i个类别的权值向量,行数由类别数决定,如以上例子有10类,列数由输入的x向量的维度决定,如以上例子为3072维 因而 w i w_i wi的维度为10×3072
- b i b_i bi为偏置值。
当我们把一张图片(转换为3072×1的向量),输入到这个式子中,得到每个类下这张图片的分数(10×1的列向量),分数越高,是该类别的可能性就越大
然后我们就需要让模型不断优化这些参数,使得最后正确的类别的分数尽可能高
在线性模型的例子中,我们本质学习到什么?就是上图的这个W矩阵 ! 也就是分类器的权值,优化模型也就是优化这里的权值
那边该怎么理解这个权值呢?
2.2.1多角度理解我们分类器的权值W
理解线性分类器的角度一
线性分类器的w权值信息,其实就是训练样本的平均值,统计信息,是每一类别的一个模板。由于W也是3072维的,因而我们可以进行权值模板的可视化
我们可以把它显示为32×32×3的图片,这时候就会得到10张图片,对应10类,我们实际上是将权值W可视化,观察我们可以发现:每一类其实就是该类下各个图片的一个均值,一个统计信息,如果我们新输入的图片和某一类模板相似,就会导致该类模板对应的额分数更高。
比如这里的W8代表马类,观察到两个马头,一个朝左,一个朝右,为什么呢?因为训练样本中就有的马头朝左,有的马头朝右

理解线性分类器权值角度二
如图,我们实际上就是要找一些分界面,来把不同类比的分开,如下面的红蓝绿线
- 我们距离线越远,他的得分越高,也就意味着相应的类别特征越明显
- 距离线越近,得分越低,也就类别特征越模糊
分数等于0的相当于一个决策面 分界面。
w控制着线的方向,b控制着分界面的偏移

但是真实世界中的数据集往往都不是线性可以分开的,线性网络表现会很差
所以在此基础上有很多非线性操作进行改进,如多层感知机,卷积等
2.3 损失函数计算损失值
我们要优化模型参数,就离不开损失函数的帮助
2.3.1 损失函数定义
什么是损失函数呢?
比如我们的真实值是猫咪,设有两组权值他们对于猫咪的预测的分数都是最高的,但我们权值一预测猫咪的分数是900分,权值二预测的分数是100分,很明显权值一更好,因而我们就是通过损失函数来定量的展现这样的差异。
它搭建了模型性能与模型参数之间的桥梁,指导模型参数的优化,
它其实是预测值与真实值的不一致程度,量化了这个指标,我们把它称为损失值,损失值越大,不一致程度越大,也就预测的越不准确
我们的每一次学习结束后,都可以对应得到一些新的参数,我们检测新的参数的好坏。
可以拿一百张新的图像去测试,然后把每一张图片的测试结果都对应得到一个损失值,把这一百个损失值加起来除以测试总数一百,就得到我们平均的损失值。反映了这一组参数的整体的水平,抽象为数学表达式为
L = 1 N ∑ ( L i ) L=\frac{1}{N}\sum(L_i) L=N1∑(Li)
L i L_i Li为 单张图片的损失值
损失函数有很多,先举一个例子
2.3.2 损失举例:多类支撑向量机损失
单样本的多类支撑向量机损失
L i = ∑ m a x ( 0 , s i j − s y i + 1 ) L_i=\sum{max(0,s_{ij}-s_{yi}+1)} Li=∑max(0,sij−syi+1)
如何直观理解多类支撑向量机损失?
如果模型给 正确类别打的分数比给错误类别的分数高1分及以上,这时损失函数返回为0。
否则的话就是把模型给错误类别的分数加上1分减去我们正确类别的分数就是我们得到的损失值。
看个例子就明白了
横行是模型给一张图的类别判断,分越高,模型觉得图形是哪一类

如上
- 第一行的正确类为鸟类,模型给错误类猫类分数比鸟类分数高2.9 超过一分,该项损失值为0,但对于汽车类模型没有高超过一分(反而低),因而错误的汽车类分数+1得到2.9再减去正确类鸟类的分数0.6等于2.3 1.9+1-0.6=2.3 总损失0+2.3=2.3
- 第二行的正确类为猫类,比错误类鸟类分数高超过一分,该项损失值为0,但对于汽车类没有高超过一分,因而错误的汽车类分数+1得到3.3再减去正确类猫类的分数2.9等于0.4 2.3+1-2.9=0.4 总损失0+0.4=0.4
- 第三行的正确类为汽车类,比其他错误类的分数都大于一分,因而总损失为零
2.3.3 优化损失函数
即便有了损失值,有时候我们也会出现损失值一模一样的情况,这时候如何评定参数好坏呢?就是通过添加包含超参数正则项损失 其中 λ \lambda λ 是超参数(超参数 不通过学习设置的参数,预先人为设定好的参数)这个超参数的作用是控制着正则项损失在总损失中占得比重
- λ \lambda λ为0的时候只依靠前面的损失函数
- λ \lambda λ为无穷的时候仅考虑正则项损失
L = 1 N ∑ ( L i ) + λ R ( W ) L=\frac{1}{N}\sum(L_i)+\lambda R(W) L=N1∑(Li)+λR(W)
正则项具体可以分为:
L1 正则项 把权值矩阵W的每个元素取绝对值后再相加
L2 正则项 把权值矩阵W的每个元素先平方再相加
如何直观理解正则项
正则项对于大数权值进行惩罚,喜欢分散权值,鼓励分类器将所有维度的特征值用起来。而不是强烈的依赖其中少说的几维特征。防止模型训练的太好,过拟合(即只能学会自己的数据)。
使得每个维度的特征运用起来,有什么意义呢?
- 避免受到噪声影响,假设它强烈依赖某一维度,那么一但那一维度受到噪声污染,判断就会严重错误,而如果分散权值,那么即便某一维度受到影响,也不影响整体判断
- 还有避免模型产生偏好,对某一维度的特征喜欢,产生记忆,因而也就会产生过拟合,所以正则项的一个重要作用就是防止过拟合!!!
我们目前更多地是使用L2正则项,原因是计算方便
不过L1损失函数也有优点,就是L1对于异常值更不敏感,鲁棒性更强
2.4 优化算法
2.4.1 优化的定义?
是机器学习的核心步骤,利用函数的输出值作为反馈信号来调整分类器参数,以提升分类器对训练样本的预测性能。
实际上我们就是要找使得损失函数的值是最小的那一组参数!!!而我们对这类问题并不陌生,高中的时候学习导数的时候讲过求最值问题,实际上是要找一些导数为零的点,这些导数为零的点中就有我们的最小值点。
假如我们只有一个参数W,且损失函数是
L = W 2 + 2 W + 1 L=W^2+2W+1 L=W2+2W+1
我们想要使得损失函数最小,我们可以很轻松知道是在W=-1的位置
但是实际问题中,我们的损失函数L往往非常复杂,同时W也十分庞大,如下图一个简单的线性模型,他的要学习的W的参数量就达到了10*3072维=30720。直接求导数为零的点就会变得十分困难,所以我们通过梯度下降算法来使得损失减小。
2.4.2 梯度下降算法
它是其中的一种简单而高效的优化算法
设想我们被遮住了双眼,被困在一个寂静的山谷,我们只知道只能在山谷最低的地方才有机会存活下来。我们该怎么办
唯一的办法是四处摸,找到向下的路,然后一点一点从高处移动到低处。
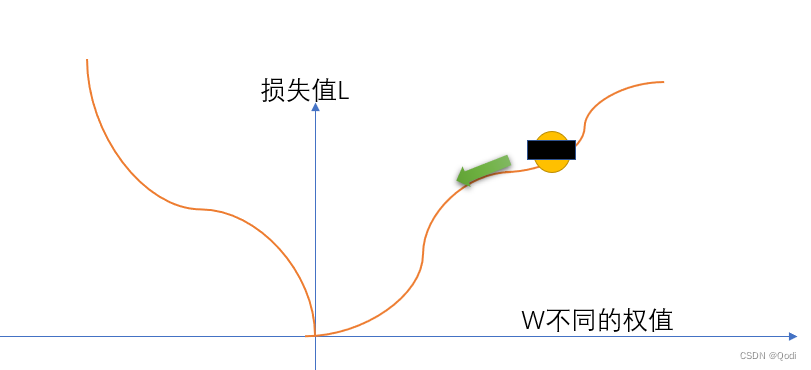
这 便是梯度下降算法的核心思想
我们需要把全部训练数据样本传入我们的分类器,这时候他就会根据我们的输出类别分数的好坏去调整参数W
相当于此时我们是 L ( W i ) L(W{_i}) L(Wi) 自变量是W,因变量是损失值L
我们只需要解决两个问题
往哪走?
负梯度方向,也就是向导数为负数且变化最快的点走,导数为负的点可以让函数值减小,也就是损失减小
走多远?
步长(也就学习率)来决定,步长也是我们的认识到的第二个超参数
因而我们把问题由找到导数为零的点转换为求某一点的梯度, ∂ f ∂ W i \frac{\partial f}{\partial W_{i}} ∂Wi∂f进而来不断更新权值
权值的梯度 <=计算梯度(损失,训练样本,权值)
权值 <=权值-学习率*权值的梯度
如何来求某一点的梯度呢?也就是在 一个已知一个权值矩阵的基础上如何确定他的梯度
1、 数值法
也就是利用求导的定义式,所以求得的是一个近似值
数值法求梯度主要用于检验解析梯度是否正确
2、 解析法
求这一点的导数,然后代入这一点的值
但这有一个问题,我们每次迭代计算都得把样本中的每一个数据都算一遍!当数据集样本足够大的时候,运算速度就会很慢,因而我们采用以下的方式改进
2.4.3 随机梯度下降算法
也就是我们这次不参考全部样本,而是从样本集合中随机抽取一个来更新。这样就会计算很多了,但是这样有一个问题,就是可能会抽取到噪声等一些不太好的样本,这时候会把我们带偏,但是这种方法依然可行,因为在大量抽样的情况下,整体还是向着梯度下降的方向去的。
2.4.4 小批量梯度下降算法
既然全部抽取速度太慢,部分抽取又可能会不稳定,那我们很容易想到取中间,也就是说我们随机抽取m个样本,计算损失并更新梯度。
这样的话我们计算效率会更高,同时也会更稳定!!!
梯度下降算法(Gradient Descent)的原理和实现步骤 - 知乎 (zhihu.com)
[梯度下降算法原理讲解——机器学习_zhangpaopao0609的博客-程序员宅基地_梯度下降](
智能推荐
JS对table添加删除一行_var row = btn.parentnode.parentnode; r-程序员宅基地
文章浏览阅读1k次。添加一行,并用AJAX提交数据。 function submitForm() { var name = $("#name").val(); var description = $("#description").val(); var url = $("#url").val(); $.ajax({ url: '/admin/ops', type:_var row = btn.parentnode.parentnode; row.parentnode.removechild(row);
HTML学习记录(列表标签&属性)_列表标签的属性-程序员宅基地
文章浏览阅读196次。ol:有序列表标签属性值描述type1,A,a,I,i规定列表顺序类型reversed (HTML5新加)reversed列表倒叙startnumberHTML5不支持,规定列表起始<ol type="A/a/I,i">ul:无序列表标签属性值描述typedisc,square,circle规定列表顺..._列表标签的属性
FFmpeg 编译支持的格式_ffmpeg g722-程序员宅基地
文章浏览阅读332次。[meng@localhost ffmpeg-4.3.2]$ ./configure --helpUsage: configure [options]Options: [defaults in brackets after descriptions]Help options: --help print this message --quiet Suppress showing informative output --_ffmpeg g722
Python GUI 快速入门_pygui-程序员宅基地
文章浏览阅读2.6k次,点赞4次,收藏22次。GUI 就是图形用户界面的意思,在 Python 中使用 PyQt 可以快速搭建自己的应用,使得自己的程序看上去更加高大上,学会 GUI 编程可以使得自己的软件有可视化的结果,更方便地参加 “互联网+”或其他创新创业大赛。目 录1 安装PyQt 与QtDesigner2 添加GUI 到 PyCharm3 界面设计测试小程序1 安装PyQt 与QtDesigner如果你想用 Python 快速制作界面,可以安装 PyQt:pip install pyQt5 -ih..._pygui
以吃货联盟初级改版为例,(面向对象初级程序设计模拟网上点餐控制台程序(第一版未使用工具辅助类)。_吃货(多实例测试)-程序员宅基地
文章浏览阅读999次,点赞2次,收藏6次。面向对象最初级程序设计思维:设计过程与抽象过程,(类是对象的模板与抽象,是具有相同属性和方法的一组对象的集 合,对象是类的实体,由属性与行为共同组成一个具体的实体。) 类与对象的关系:类是对象抽象,对象是类的实例化实体。 使用类图理解类的关系 面向对象三大特性应用:1、封装 ;2、继承;3、多态;是程序设计更符合人思考的方式。 封装:{维护数据安全性将属性私有化(以包机制,与private..._吃货(多实例测试)
Camstar技术介绍-程序员宅基地
文章浏览阅读212次。Camstar_camstar
随便推点
Oracle中通过存储过程,Function,触发器实现解析时间类型的字段并插入的对应的数据表中...-程序员宅基地
文章浏览阅读71次。摘要:之前在项目中解决了插入字符串类型的数据,今天试着写了一个插入date类型的字段,成功了,现在记录一下,以便以后查看:一:首先建立一个根据xml节点名称获取对应的xml值的Function.sql:CREATE OR REPLACE FUNCTION MIP.GetXmlNodeValue (xmlStr CLOB, nodeName VARCHAR2) RETURN VAR..._oracle sql 触发器中对date类型的字段的处理
KCF -目标检测算法总结_kcf 目标检测-程序员宅基地
文章浏览阅读1.1w次,点赞7次,收藏48次。KCF简介KCF是一种鉴别式追踪方法,这类方法一般都是在追踪过程中训练一个目标检测器,使用目标检测器去检测下一帧预测位置是否是目标,然后再使用新检测结果去更新训练集进而更新目标检测器。而在训练目标检测器时一般选取目标区域为正样本,目标的周围区域为负样本,当然越靠近目标的区域为正样本的可能性越大。简单来说 KCF 是 核相关滤波算法,滤波器 和 跟踪patch 进行相乘的到相关性,对应位置较..._kcf 目标检测
汇编语言编一程序段,求双字(DX,AX)的绝对值_汇编语言求双字长数的绝对值-程序员宅基地
文章浏览阅读4.7k次。a100mov ax,ffff;把双字长数的低字放到AX中mov dx,ffff;把双字长数的高字放到DX中test dx,8000;测试双字长数的符号jz 0113;如果是非负数,则直接保存neg dx;如果是负数,则求补neg ax;求补sbb dx,0int 3g=073f:0100 0113运行附图如下:..._汇编语言求双字长数的绝对值
Qt安装MySQL驱动,解决QMYSQL driver not loaded问题_qsmqldriver-程序员宅基地
文章浏览阅读222次。根据项目https://github.com/thecodemonkey86/qt_mysql_driver翻译Get precompiled qsqlmysql.dll from releases获取编译后的qsqlmysql.dll 链接不是很懂这两个有什么区别之后put qsqlmysql.dll (if release build) / qsqlmysqld.dll (if debug build, but note that when using MinGW 8.1.0 the d_qsmqldriver
Java面试题目大汇总(附参考答案)-程序员宅基地
文章浏览阅读1.4w次,点赞61次,收藏333次。足足准备了长达3个月的面试,终于在上周拿到了阿里的offer!博主汇总整理了一份我面试之前看的一些Java面试题目,可以说是非常详细!分享给大家,希望对正在面试Java岗位的朋友有帮助哈~~(文末附参考答案)Java基础相关面试题目:JDK 和 JRE 有什么区别? == 和 equals 的区别是什么? 两个对象的 hashCode()相同,则 equals()也一定为 true,对吗? final 在 java 中有什么作用? java 中的 Math.round(-1.5)
网络存储服务ip-san搭建_ipsan搭建-程序员宅基地
文章浏览阅读2k次。一.什么是ip-sanip-san也就是SAN(全称Storage Area Network,存储局域网络),它的诞生,使存储空间得到更加充分的利用,并使得安装和管理更加有效。SAN是一种将存储设备、连接设备和接口集成在一个高速网络中的技术。SAN本身就是一个存储网络,承担了数据存储任务,SAN网络与LAN业务网络相隔离,存储数据流不会占用业务网络带宽。在SAN网络中,所有的数据传输在高速、..._ipsan搭建