Hadoop环境搭建(保姆级教学)_hadoop平台搭建步骤-程序员宅基地
Hadoop大数据
Hadoop环境搭建
一、基本配置
1、首先需要的环境:Centos7-版本不限,克隆三台配置好的机子、hadoop、jdk安装包、Xftp软件(缺一不可)
二、任务部署
1、安装VMware虚拟机
2、安装Centos7版本的虚拟机
3、准备3台配置完毕的虚拟机
4、搭建3台节点的Hadoop集群
三、Hadoop搭建的安装包
1、链接: https://pan.baidu.com/s/1gWpQ7Dh5dgXyjKfHUYuC5Q
提取码:k2q8
四、知识讲解
简单说明:
在搭建的过程中,小伙伴们统一保持和博主一样的配置
VMware版本:
- VMware建议使用博主给的安装包里面都有
- 关于VMware的安装,我已经把安装包放在了链接大家自取就行,里面是包含了VMware版本密钥的
linux版本:
- linux版本我就直接放这大家自取就行
- 链接: http://mirrors.aliyun.com/centos/7/isos/x86_64/
- 若链接失效请找博主索要镜像
1、linux系统的安装:
1、安装VMware
呃,博主这安装过了
vmware安装链接: https://blog.csdn.net/Alger_/article/details/111193639
- 配置
- 处理器数量:1
- 处理器的内核数量2
- 网络配置:NAT
- 虚拟机的内存:4096(4GB)
- 磁盘容量:40,将虚拟机磁盘存储为单个文件
- 软件安装:最小安装,除智能卡取消其他全选
- KDUMP:取消勾选
- Root密码:123123
2、linux虚拟机配置ios
1:通过设置来配置ios镜像
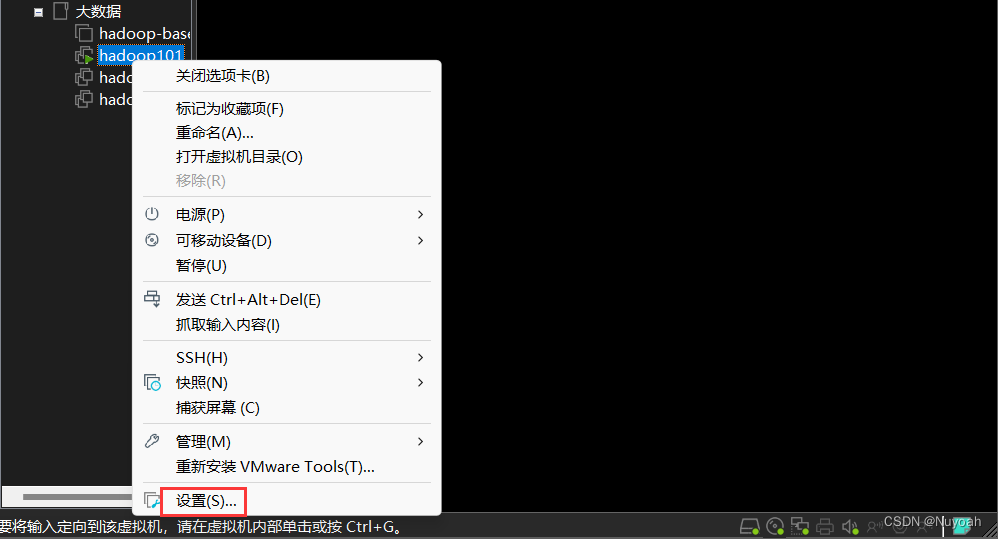
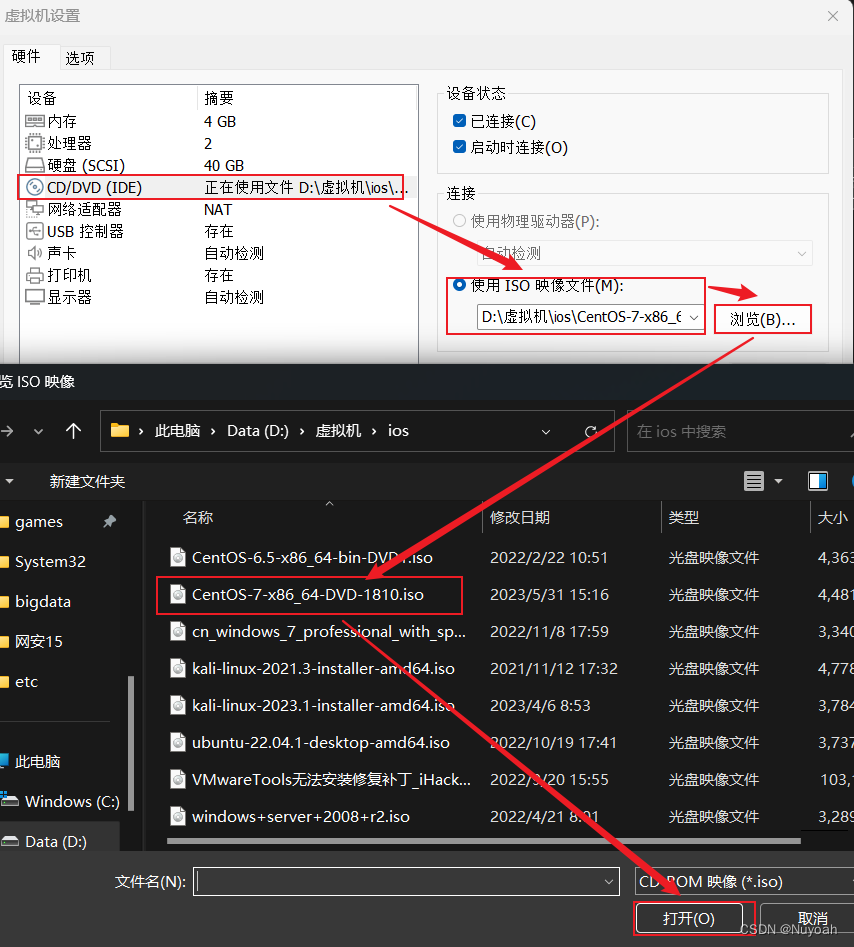
3、linux虚拟机设置网络配置
1、设置虚拟机的虚拟网络配置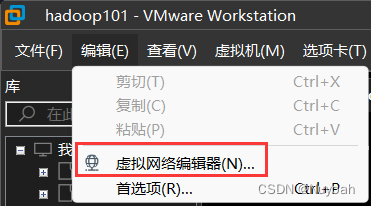
2、查看NAT的默认网关、ip地址以及子网掩码
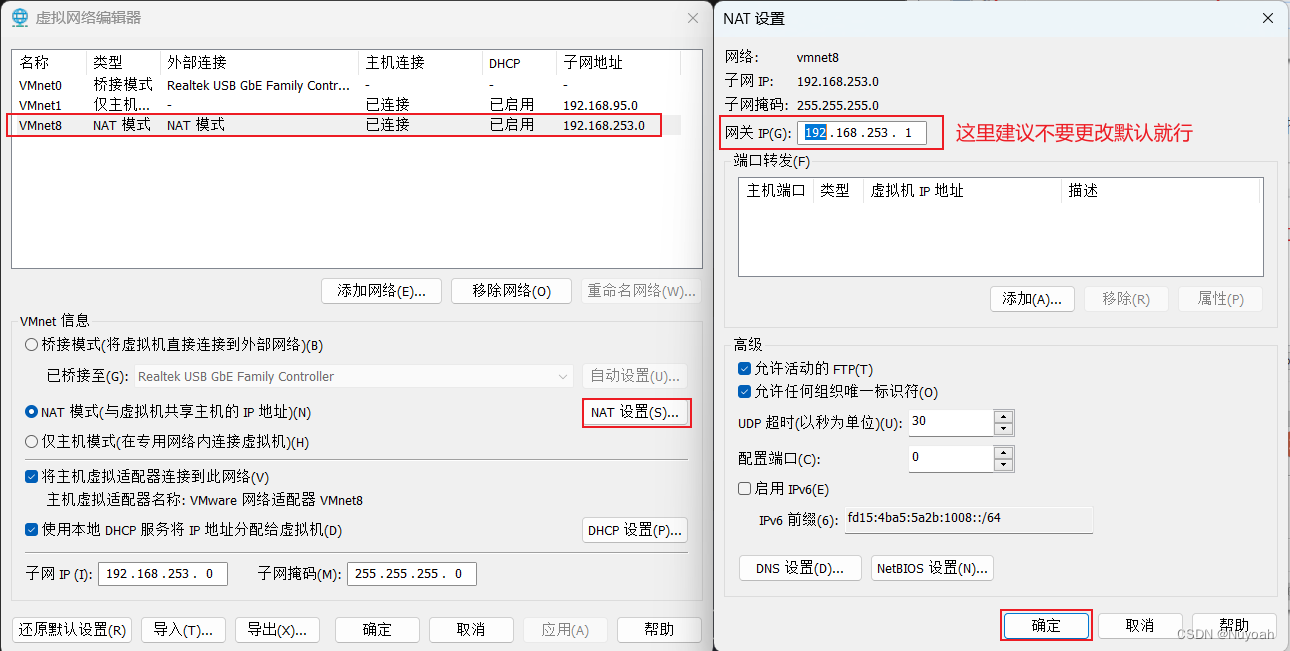
3、设置windwos的VMNet8网络地址
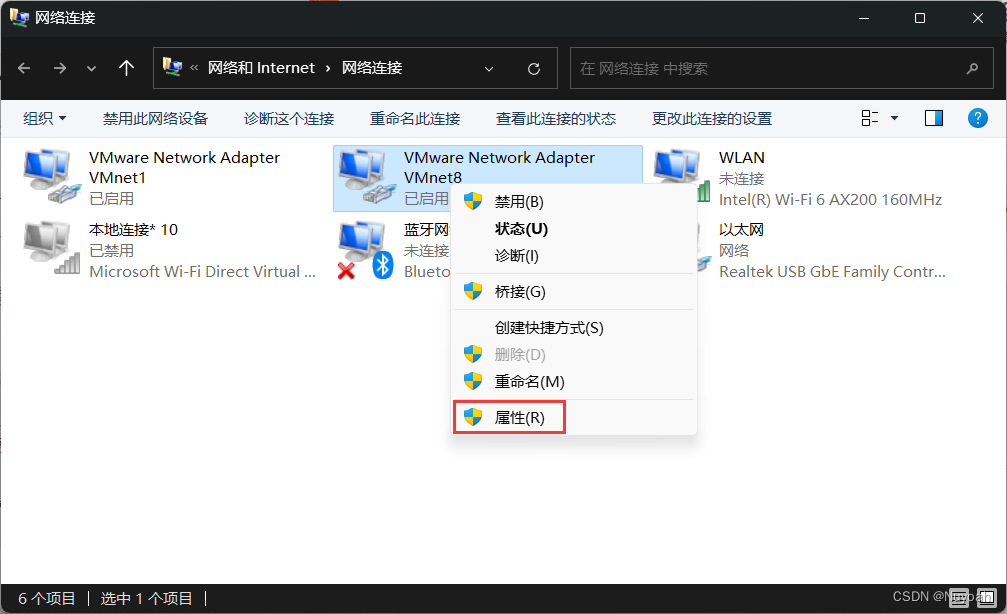
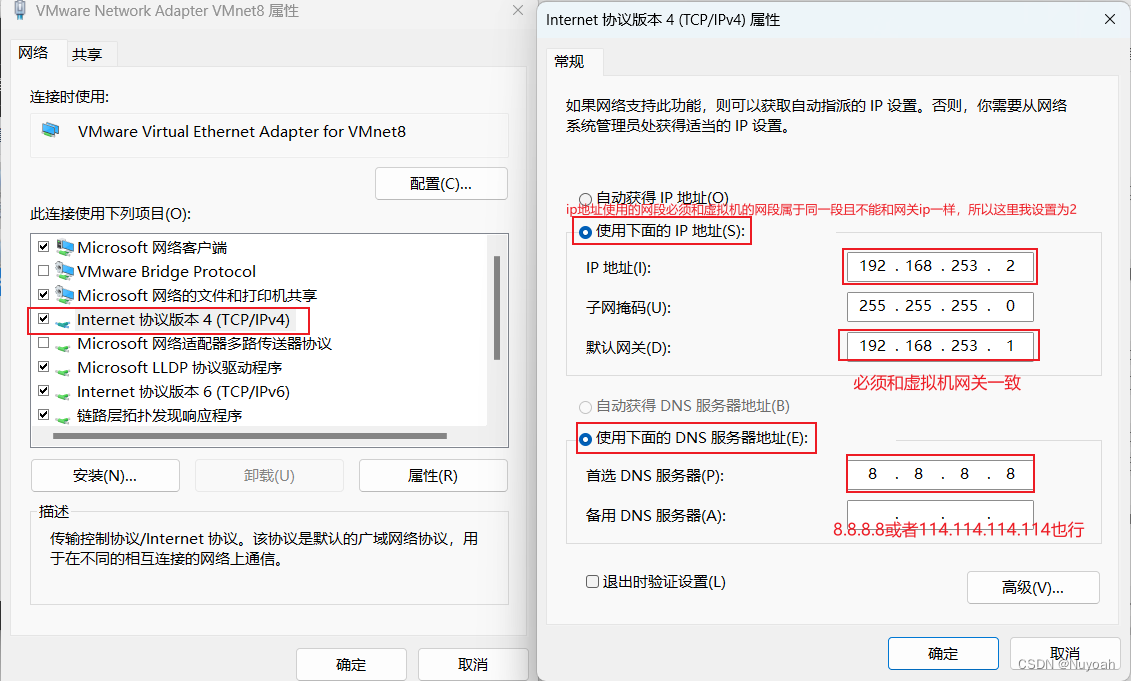
4、linux设置网络配置
- 网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
添加网络必备
IPADDR=192.168.253.100 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
编辑静态IP和开机自启
BOOTPROTO=static
NOBOOT=yes
重启网络服务
systemctl restart network
安装vim和常用软件
yum -y install vim
yum -y install net-tools
4、克隆虚拟机
- 反复创建虚拟机很难受,直接克隆最干脆
- 克隆搭建好的虚拟机的快照即可

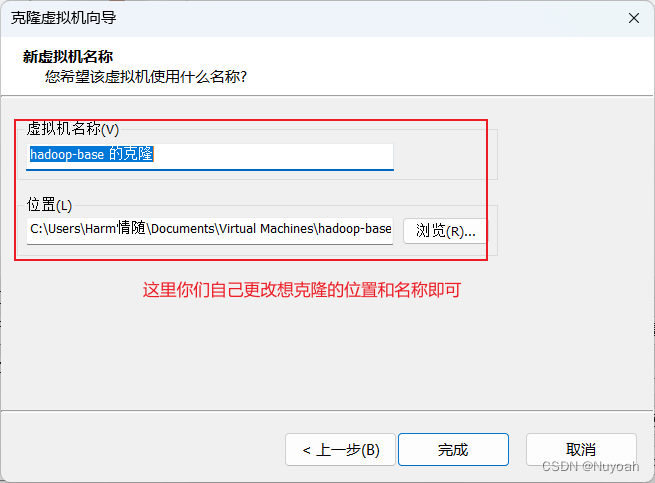
- 反复克隆出三台机子就够用了
5、克隆机更改ip地址
- 三台克隆机ip地址分别为:192.168.253.101、192.168.253.102、192.168.253.103
- 名称分别为:hadoop101、hadoop102、hadoop103
- 因克隆的虚拟机ip地址都相同,更改ip地址即可,其他可不要更改
- 启动虚拟机,用户为root,密码为123123
更改ip地址配置文件
hadoop101
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.253.101 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
hadoop102
IPADDR=192.168.253.102 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
hadoop103
IPADDR=192.168.253.103 IP地址
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.253.1 网关
DNS1=8.8.8.8 DNS解析
2、安装大数据集群环境基本配置
1、三台虚拟机关闭防火墙
systemctl status firewalld
若呈现绿色字样及未关闭
若现呈黑色字样及为关闭
systemctl stop firewalld
systemctl disable firewalld
2、三台虚拟机更改主机名
vim /etc/hostname
克隆机1
hadoop101
克隆机2
hadoop102
克隆机3
hadoop103
3、三台虚拟机更改主机名与ip映射地址
vim /etc/hosts
192.168.253.100 hadoop-base
192.168.253.101 hadoop101
192.168.253.102 hadoop102
192.168.253.103 hadoop103
192.168.253.104 hadoop104
192.168.253.105 hadoop105
4、三台虚拟机添加普通用户
- 三台虚拟机统一添加普通用户user001,并给予sudo权限,用于以后所有的大数据安装(避免root执行危险的操作)
- 普通用户密码为123123
useradd user001
passwd user001
5、三台虚拟机为普通用户添加sudo权限
vim /etc/sudoers
添加如下内容
user001 ALL=ALL(ALL) NOPASSWD:ALL
6、三台虚拟机在根目录统一目录
三台克隆机在根目录下创建bigdata目录—project、software
目录权限更改为user001
chown user001:user001 project/ software/
三台克隆机通过su命令切换user001用户
su user001
123123
7、三台虚拟机普通用户免密登录
- 先重启三台虚拟机使主机名生效
- 重启命令:reboot
- ssh免密登录方式
hadoop101:
ssh-keygen
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop101
hadoop102:
ssh-keygen
ssh-copy-id hadoop101
ssh-copy-id hadoop103
ssh-copy-id hadoop102
hadoop103:
ssh-keygen
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
8、通过Xftp传输hadoop、jdk软件包
- 使用方法
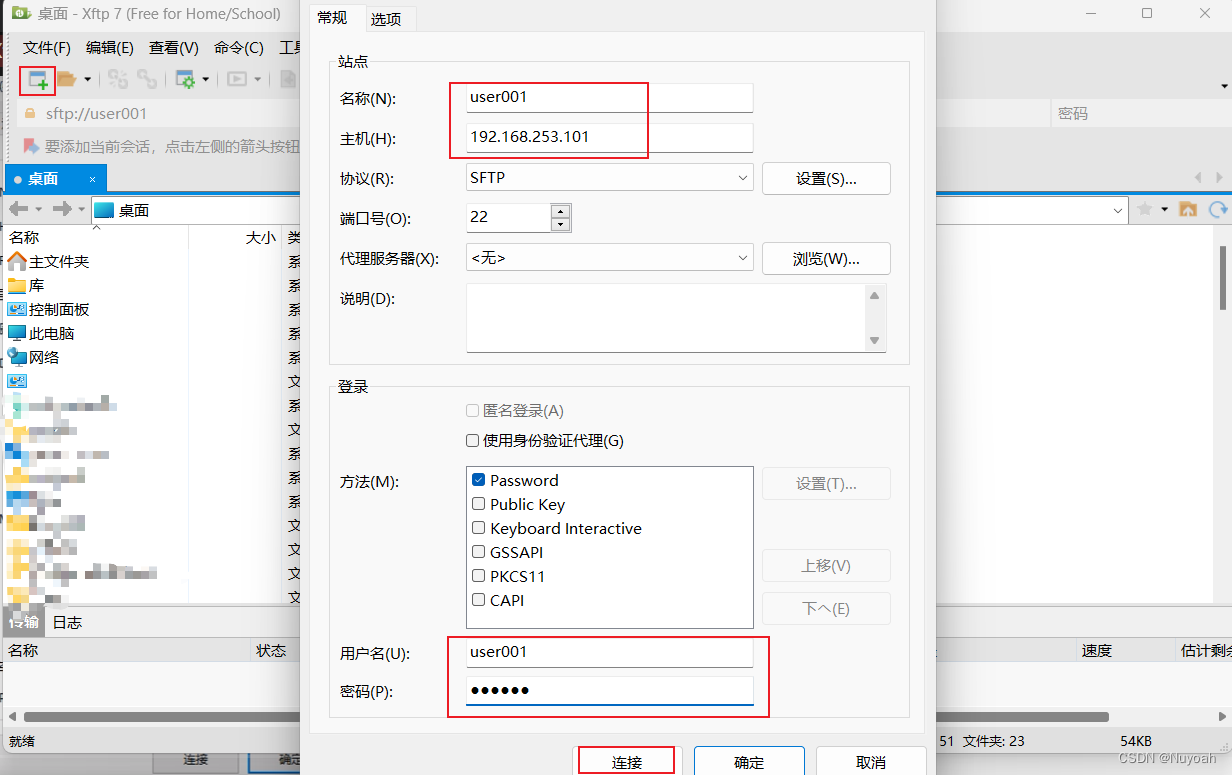
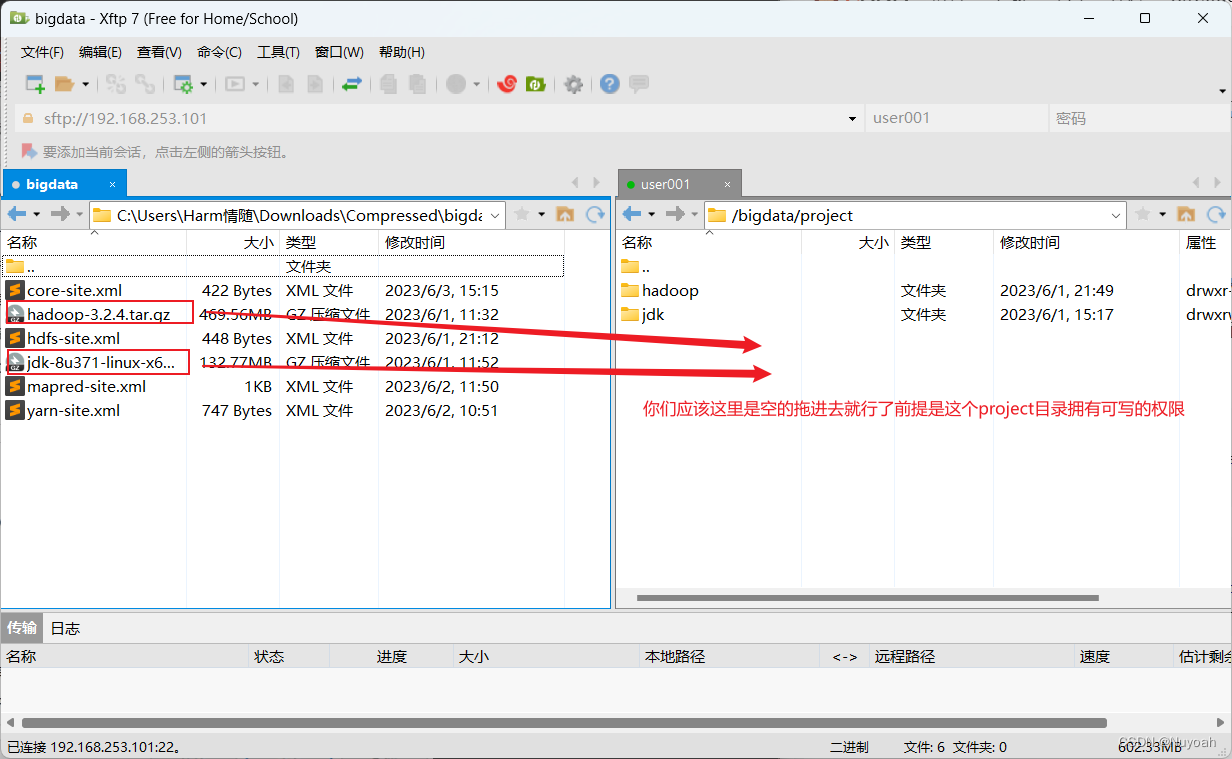
9、三台虚拟机安装jdk
- 使用user001来重新连接三台机器,使用user001来安装jdk软件
- 上传压缩包到第一台服务器的/bigdata/project/下面,进行解压,配置环境变量即可,三台都依次安装即可
cd //bigdata/project
cd …
cd /software
ll:tarX2(hadoop\jak)
tar -zxvf jdk----------------------.tar.gz -C /bigdata/project
tar -zxvf hadoop-------------------.tar.gz -C /bigdata/project
cd /project
mv hadoop---- /hadoop
mv jdk------- /jdk
- 配置jdk和hadoop环境变量
sudo vim /etc/profile.d/my_env.sh
内容:
JAVA_HOME
export JAVA_HOME=/bigdata/project/jdk
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
HADOOP_HOME
export HADOOP_HOME=/bigdata/project/hadoop
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin
export PATH= P A T H : PATH: PATH:HADOOP_HOME/sbin

source /etc/profile 更新源
- 建议三台克隆机都拍个快照
3、hadoop集群的安装
1、上传压缩包并解压
cd //bigdata/software
tar -zxvf hadoop-------------------.tar.gz -C /bigdata/project
2、修改hadoop配置文件
修改core-site.xml
- 第一台克隆机执行以下命令
vim core-site.xml
core-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/project/hadoop/data</value>
</property>
</configuration>
修改hdfs-site.xml
- 第一台克隆机执行以下命令
vim hdfs-site.xml
hdfs-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn wen段访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:9868</value>
</property>
</configuration>
修改mapred-site.xml
- 第一台克隆机执行以下命令
vim mapred-site.xml
mapred-site.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
第一台克隆机执行以下命令
vim yarn-site.xml
yarn-site.xml:
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
修改workers文件
第一台克隆机执行以下命令
vim workers
替换
hadoop101
hadoop102
hadoop103
Xftp覆盖配置文件
把core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml这四个配置文件通过xftp覆盖到/bigdata/project/hadoop/etc/hadoop/下面
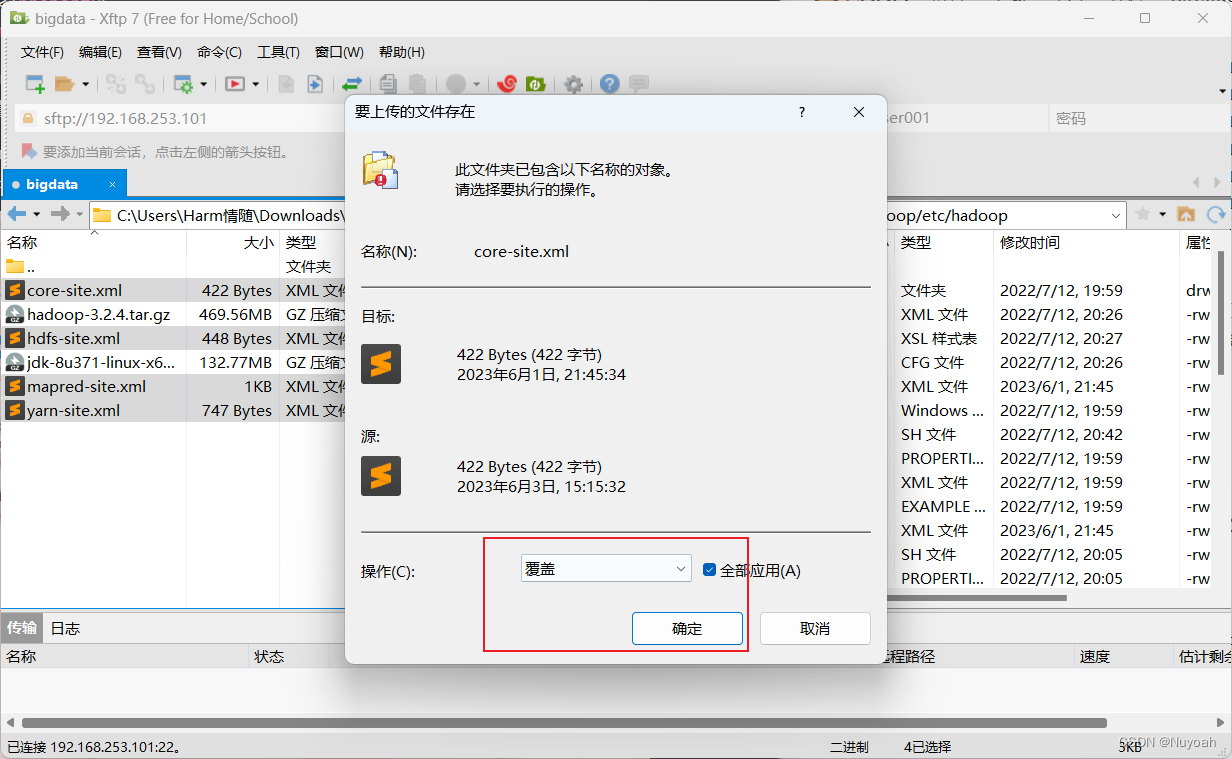
分发rsync
分发101配置文件给102和103的克隆机
hint:前提是要在/bigdata/project/Hadoop/etc/hadoop目录下
rsync -a -v ./ hadoop102:/bigdata/project/hadoop/etc/hadoop
rsync -a -v ./ hadoop103:/bigdata/project/hadoop/etc/hadoop
执行完之后在/bigdata/project/hadoop目录执行
hdfs namenode -format (对namenode进行格式化)=(对hdfs文件系统格式化)
没有报错则格式成功
4、Hadoop集群环境启动
101克隆机:hadoop的根目录下执行:sbin/start-dfs.sh 启动hdfs
102克隆机:hadoop的根目录下执行:sbin/start-yarn.sh 启动yarn
在浏览器上访问:
hadoop101:9870或ip+:9870
hadoop102:8088或ip+:8088
关闭服务
hadoop根目录下执行:stop-dfs.sh
hadoop根目录下执行:stop-yarn.sh
- ps 制作文章实属不易如帮助到你,请你给我个关注谢谢
智能推荐
新手java五子棋完整代码判断落子落在线上_Java初学者,编写小游戏五子棋的问题?...-程序员宅基地
文章浏览阅读362次。首先你需要掌握GUI编程,事件处理,已经监听器,你就掌握Swing的知识就好了Swing框架,JFrame,JPanel,鼠标、键盘监听事件Java基础,面向对象,异常处理,集合,IO流网络编程,Socket通信线程知识,Java逻辑基础上述的技术点估计需要将JavaSE这块学完才能掌握,下面进入正题。这里呢,我把几个常见的小游戏列出来,如下图:象棋对战,带聊天五子棋对战,带聊天打字游戏对战音乐播..._五子棋程序判断落子位置
杭电2041 超级楼梯_超级楼梯 (杭电2041)比赛题目 题目统计 全部提交时间限制:c/c++ 1000ms,其他语言-程序员宅基地
文章浏览阅读322次,点赞6次,收藏8次。【代码】杭电2041 超级楼梯。_超级楼梯 (杭电2041)比赛题目 题目统计 全部提交时间限制:c/c++ 1000ms,其他语言
关于构建数据仓库的几个问题_从需求出发建设数仓会有什么问题-程序员宅基地
文章浏览阅读1.6k次。写在前面数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。近年来,随着大数据的应用不断深入,构建企业级数据仓库成为了企业进行精细化运营的一种趋势。从管理者的视角来看,数据仓库是赋能业务并辅助决策的一种工具,从开发者的视角来看,数据仓库是一堆数据模型的集合。数仓开发是一个系_从需求出发建设数仓会有什么问题
手写B+树-程序员宅基地
文章浏览阅读3.2k次。插入关键字 40 ,按照第 2 种情况将结点分裂,并将关键字 37 上移到父结点,发现父结点 [15、37、44、59] 包含的关键字的个数大于 M ,所以将结点 [15、37、44、59] 分裂为两个结点 [15、37] 和结点 [44、59] ,并将关键字 37 上移到父结点中 [37、59、97] . 父结点包含关键字个数没有超过 M ,插入结束。比如插入关键字 12 ,插入关键字所在的结点的 [10,15] 包含两个关键字,小于 M ,则直接插入关键字 12。B+树插入删除时间复杂度为0(1)_手写b+树
基于SSM企业人力资源管理系统的设计与实现 |计算机毕业设计|Java毕业设计|课程设计|Python毕设|小程序|人力资源管理|人事管理系统|_基于ssm的企业人力资源管理系统的设计与实现-程序员宅基地
文章浏览阅读82次。在答辩过程中,要充分展示对项目的深入研究和对技术的理解,结合实际案例和数据,清晰阐述项目的创新、可行性和应用价值,回答评委问题时要有条理、准确表达自己的观点。管理员:首页、用户管理、管理员、员工、更多管理、部门管理、 请假申请、人事考勤、公司绩效、奖惩信息、通知公告、员工工资等。员工:首页、更多管理、请假申请、人事考勤、公司绩效、奖惩信息、通知公告、员工工资等。该项目含有源码、论文等资料、配套开发软件、软件安装教程、项目发布教程等。前端技术:JavaScript、VUE.js(2.X)、css3。_基于ssm的企业人力资源管理系统的设计与实现
Hector双足机器人MPC控制_force-and-moment-based model predictive control fo-程序员宅基地
文章浏览阅读940次,点赞14次,收藏16次。首先根据当前机器人状态选择合适的步态模式(站立。然后根据步态模式生成相应的脚部期望轨迹,)是摆动腿阶段,应该采用另外的。最后更新机器人的控制命令。问题的求解使用第三方库。)是跟摩擦系数有关,_force-and-moment-based model predictive control for achieving highly dynamic
随便推点
图解通信原理与案例分析-17:2G GPRS通用分组无线业务详解_2g slot-程序员宅基地
文章浏览阅读4.7k次。先占个空,以后再详细拆解主要关注与GSM的区别,特别是GRPS是如何通过增加信道和分组交换系统支持数据传输,如何通过新的调制解调技术,增加数据传输的速率的!1. GSM是全球移动通讯系统(Global System for Mobile Communications)的简称2. GPRS是通用分组无线业务(General Packet Radio Service)的简称3. GPRS是在GSM系统基础上发展起来的分组数据承载和传输业务。4. GPRS与GSM......_2g slot
【图像拼接】论文精读:Natural Image Stitching Using Depth Maps-程序员宅基地
文章浏览阅读10w+次。图像拼接系列相关论文精读Seam Carving for Content-Aware Image ResizingAs-Rigid-As-Possible Shape ManipulationAdaptive As-Natural-As-Possible Image StitchingShape-Preserving Half-Projective Warps for Image StitchingSeam-Driven Image StitchingParallax-tolerant Ima_natural image stitching using depth maps
【Java基础知识 11】java泛型方法的定义和使用-程序员宅基地
文章浏览阅读1.6w次,点赞131次,收藏52次。一、基本介绍Java泛型是J2 SE1.5中引入的一个新特性,其本质是参数化类型,也就是说所操作的数据类型被指定为一个参数(type parameter)这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。二、提出背景Java集合(Collection)中元素的类型是多种多样的。例如,有些集合中的元素是Byte类型的,而有些则可能是String类型的,等等。Java允许程序员构建一个元素类型为Object的Collection,其中的元素可以是任何类型在Java S._java基础
vue中使用echarts实现省市地图绘制,根据数据在地图上显示柱状图信息,增加涟漪特效动画效果_vue 市区地图+经纬度自定义显示弹窗详情-程序员宅基地
文章浏览阅读1.7k次,点赞26次,收藏14次。vue中使用echarts实现省市地图绘制,根据数据在地图上显示柱状图信息;增加涟漪特效动画。本文以吉林省地图为例,来实现吉林省市的地图的绘制。根据数据在地图上显示柱状图信息;增加涟漪特效动画。你也可以显示中国地图或其他身份地图。原理是一样的哦。主要是通过geo地理坐标系组件实现地图绘制。柱状图是利用3个样式(顶部椭圆、中部矩形、底部椭圆)层叠实现的。_vue 市区地图+经纬度自定义显示弹窗详情
网络安全等级保护2.0自查表 | 技术部分_网络安全等级保护自查表-程序员宅基地
文章浏览阅读1.2k次,点赞46次,收藏20次。网络安全等级保护2.0自查表 | 技术部分_网络安全等级保护自查表
已知一个iis漏洞可以让php解释任意的给定文件-程序员宅基地
文章浏览阅读64次。已知一个iis漏洞可以让php解释任意的给定文件。挑战:怎么执行任意命令?应用环境:防火墙配置不准许对外连接。要求:不能要求上传文件。总算看到一次答案了:http://www.inbreak.net/kxlzxtest/phpiis.txtC:\Windows\System32\LogFiles\w3svcXXXX让php解析当天访问日志,然后用get请求提交user agent为 User-Ag..._php iis 漏洞