Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
技术标签: elasticsearch
是什么
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念:
- 节点(Node):
一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能。
一个节点可以通过配置特定的集群名称来加入特定的集群。默认情况下,每个节点被设定加入一个名称为 “elasticsearch” 的集群,这意味着如果你在你的网络中启动了一些节点,并且假设它们能相互发现,它们将会自动组织并加入一个名称是 “elasticsearch” 的集群。 - 索引(Index):
可以近似的理解SQL中的数据库,虽然官方文档上说这是不好的。可以包涵表和数据。 - 类型(Type):(警告!Type在6.0.0版本中已经不赞成使用):
可以近似的理解成是SQL中的表,里面会包涵许多数据 - 文档(Document):
可以近似的理解是SQL中的表里的每一条数据。
去哪下:
官网下载传送
官网下载window版(我的是6.6.1版本)。
双击运行bin目录下的 elasticsearch.bat
怎么玩:
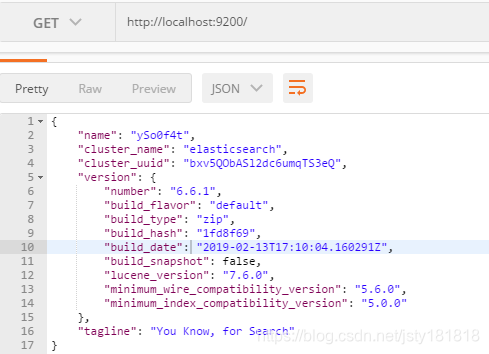
看到这个结果,说明安装,启动成功。
- 列出所有的索引:(GET)
http://localhost:9200/_cat/indices?v
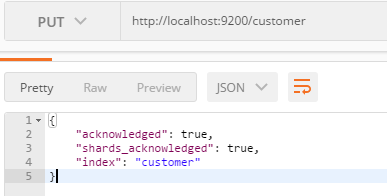
- 创建一个索引:(PUT)
http://localhost:9200/customer
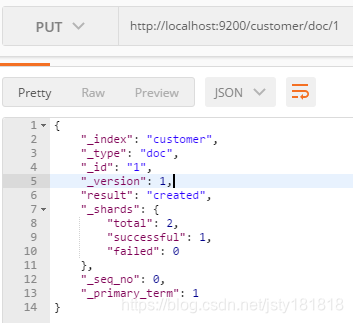
- 向索引中添加文档(PUT)
http://localhost:9200/customer/doc/1
//其中doc是类型。
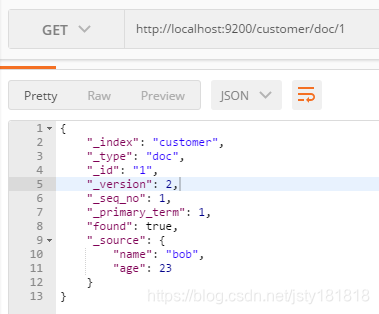
- 获取刚刚加入索引的文档:(GET)
http://localhost:9200/customer/doc/1
- 删除一个索引:(DELETE)
http://localhost:9200/customer
- 更新文档(POST)
除了能够新增和替换文档,我们也可以更新文档。注意虽然 Elasticsearch 在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch 首先去删除旧的文档,然后加入新的文档。
http://localhost:9200/customer/doc/1/_update?pretty
{
"doc": { "name": "Jane Doe" }
}
更新操作也可以使用简单的脚本来执行。如下的示例使用一个脚本将age增加了5:
http://localhost:9200/customer/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
- 删除文档(DELETE):
http://localhost:9200/customer/doc/2?pretty
推荐使用Kibana进行数据查询
搜索:
- _mget(批量获取文档)
类似sql中的 id in(1,2,3)这样。
GET _mget
{
"docs":[
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_source": ["balance", "city"]
},
{
"_index": "bank",
"_type": "account",
"_id": "5",
"_source": "firstname"
}
]
}
也可以简写:
GET /bank/account/_mget
{
"ids": ["1", "2", "4"]
}
-
_bulk(批量操作)
1.格式:
{action:{metadata}}
{requestbody}
其中action(行为)可以取值:
1.create:文档不存在时创建
2.update:更新文档
3.index:创建新文档或覆盖已有文档
4.delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档以存在,使用index可以成功执行。
如果使用create创建多个,其中有存在的,那么存在的返回失败,不存在的添加成功
其中metadata可以取值:
_index,_type,_id示例:
1.create:POST /bank/account/_bulk { "create":{ "_id":"999"}} { "account_number":999, "balance": 999} { "create":{ "_id":"1000"}} { "account_number":1000, "balance": 1000} { "create":{ "_id":"1001"}} { "account_number":1001, "balance": 1001}2.delete:
POST bank/account/_bulk { "delete":{ "_index":"bank", "_type":"account", "_id":"1000"}}3.update:
POST /bank/account/_bulk { "update":{ "_id":"1001"}} { "doc":{ "balance":"0"}} -
term:
用于查询指定字段包含某个词项的文档。这个查询不知道分词器的存在,所以搜索的值不会进行分词。只会拿搜索的值去倒排索引中找。
GET /bank/account/_search
{
"query":{
"term":{
"address":{
"value":"heath"
}
}
}
}
- match:
知道分词器的存在,所以搜索的值会被分词在去查询。
GET /bank/account/_search
{
"query":{
"match":{
"address":"511 Heath Place"
}
}
}
- multi_match:
可以指定多个字段,意思是:查找fields字段值的字段中包含query字段中对应的值
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
}
}
- match_phrase:
短语搜索,就是搜索含有指定的短语的数据。意思是搜索的值经过分词之后和es中分词保存的一致,顺序也一致,两头的可以少,中间的不可以少
GET /bank/account/_search
{
"query":{
"match_phrase":{
"address":"511 Heath Place"
}
}
}
- _source:
用来指定返回的字段:
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": ["firstname", "age"]
}
_可以写个数组来指定,也可以在 "source" 字段中加"includes"和"excludes"
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": {
"includes": ["age", "balance", "gen*"],
"excludes": ["gender"]
}
}
- sort:
用来排序,和关系型数据库的排序类似
GET /bank/account/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"balance":{
"order":"desc"
}
},
{
"age":{
"order":"asc"
}
}
]
}
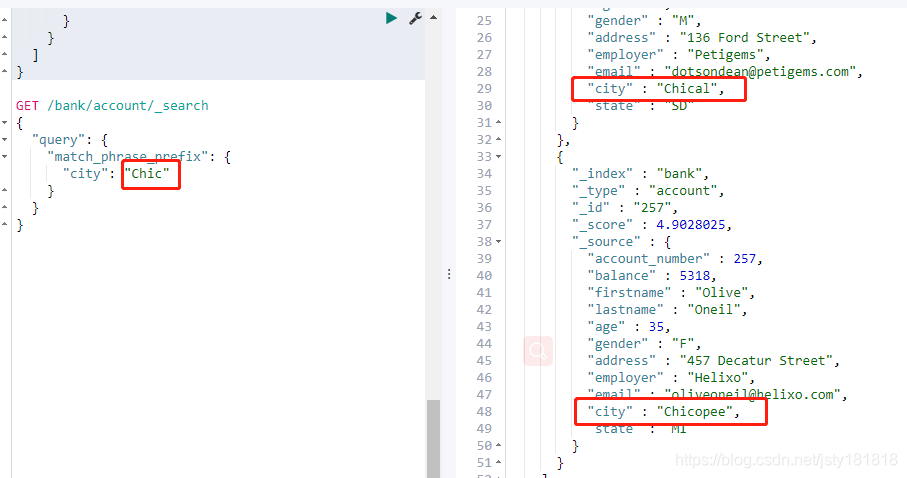
- match_phrase_prefix:
前缀匹配(查询的值不会分词,但是忽略大小写)
- range:
范围查询:
GET /bank/account/_search
{
"query":{
"range":{
"age":{
"gte": 20,
"lt": 30
}
}
}
}
- wildcard:
通配符匹配:
通配符:
* 代表任意多字符
? 代表一个字符
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
}
}
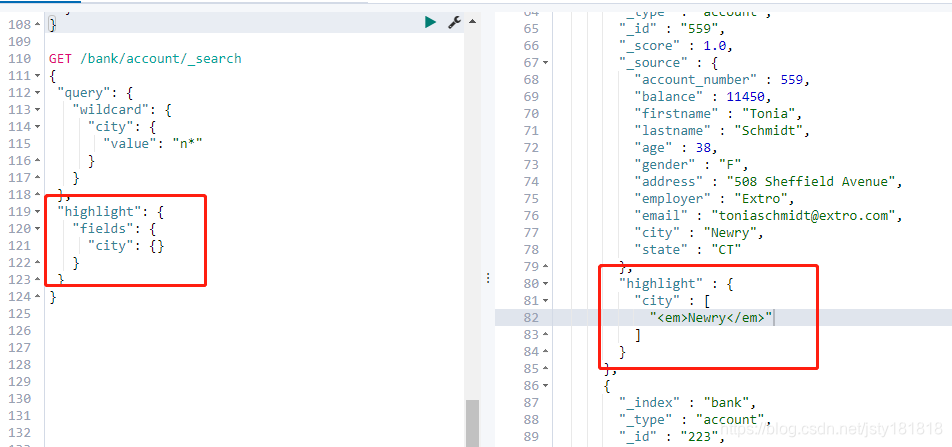
- highlight:
高亮显示:
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
},
"highlight":{
"fields":{
"city":{
}
}
}
}
- fuzzy:
模糊匹配,这个可不是mysql中的like,是可以错误的输入一些字 来进行匹配
GET /bank/account/_search
{
"query":{
"fuzzy":{
"city": "Nicho1so"
}
}
}
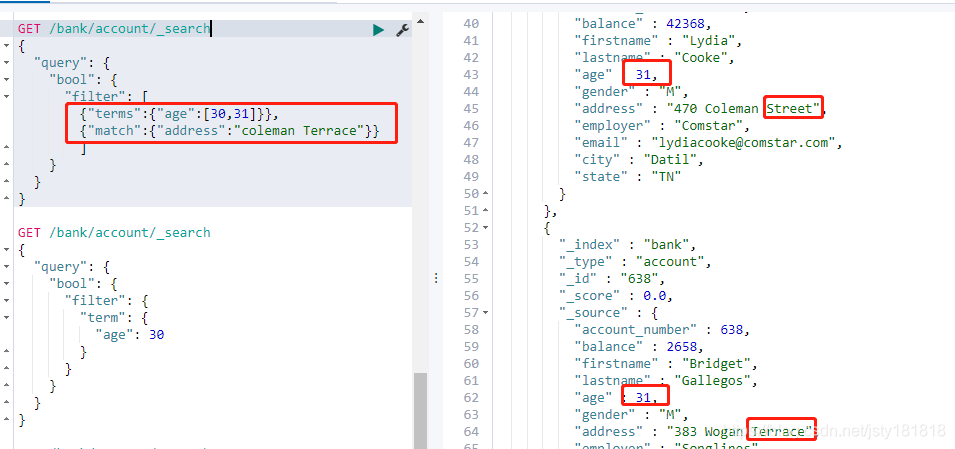
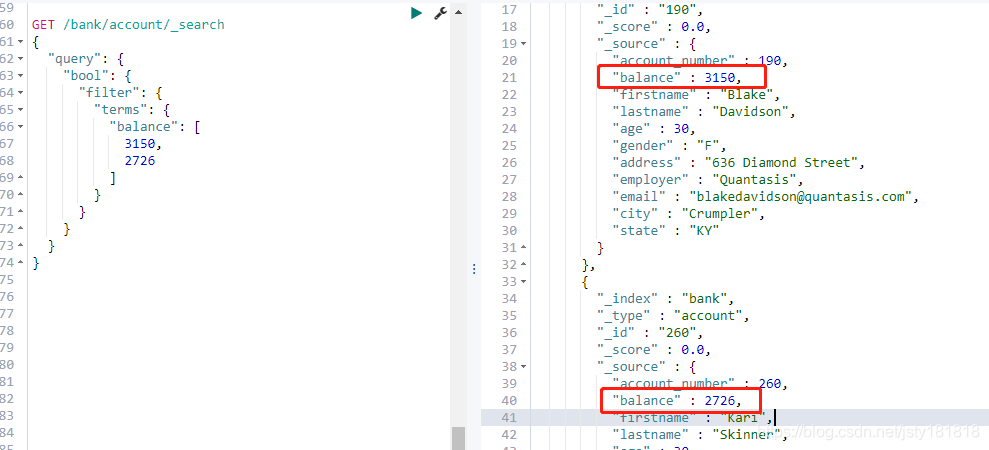
- filter查询:
过滤查询:
- must,should,must_not:
GET /bank/account/_search
{
"query":{
"bool":{
"must": [
{
"term":{
"age":{
"value" :20
}
}
}
]
}
}
}
- exists:
查询某个字段不为空
GET /bank/account/_search
{
"query":{
"bool":{
"filter": {
"exists":{
"field": "age"
}
}
}
}
}
- 聚合查询:
1.sum

智能推荐
CSS:如何清除a标签之间的默认留白间距_css处理手机自动留白安全距离-程序员宅基地
文章浏览阅读2.3k次。即使我们使用了类似 *{margin: 0;padding: 0;} 这样的代码重置了浏览器默认样式,也会发现类似标签这种inline-block元素,它们之间也还存在着间距。demo:默认情况123456789101112131415_css处理手机自动留白安全距离
数据分析与数据挖掘-程序员宅基地
文章浏览阅读2.0k次,点赞14次,收藏17次。第一章、概述1.1.1数据分析:采用适当的统计分析方法对收集到的数据进行分析、概括和总结,对数据进行恰当的描述,提取出有用的信息的过程。1.1.2数据挖掘:从海量数据种通过相关的算法来发现隐藏在数据中的规律和知识的过程。1.1.3知识发现的过程1.1.4数据分析与数据挖掘的区别1.1.5数据分析与数据挖掘的联系数据-------数据分析----->信息-------数据挖掘-------->知识1.2分析与挖掘的数据类型1.3数据分析..._数据分析与数据挖掘
Python实现WOA智能鲸鱼优化算法优化XGBoost分类模型(XGBClassifier算法)项目实战_鲸鱼算法 xgboost-程序员宅基地
文章浏览阅读312次。Python实现WOA智能鲸鱼优化算法优化XGBoost分类模型(XGBClassifier算法)项目实战_鲸鱼算法 xgboost
使用android.webkit.WebView控件-程序员宅基地
文章浏览阅读3.9k次。android.webkit.WebView/WebViewClient/WebChromeClient使用android.webkit.WebView控件在xml布局文件中定义 android:id=”@+id/webkit01” android:layout:width=”fill_parent” android:layout:height=”fill_par_android.webkit.webview
基于Matlab实现图像处理常用应用案例(附上100个案例源码)_matlab图像处理实例详解-程序员宅基地
文章浏览阅读6.5k次,点赞9次,收藏186次。基于Matlab实现图像处理常用应用案例(附上100个案例源码)_matlab图像处理实例详解
如何在 Python 中调用函数?九种方法任你挑选_python调用函数-程序员宅基地
文章浏览阅读2.9w次,点赞5次,收藏43次。1.直接函数调用这是最简单、最直观的方式:def test():print("This is a test")test()2.使用partial()函数在 的内置库中functools,有一个专用于生成偏函数的偏函数partial。def power(x, n):s = 1while n > 0:n = n - 1s = s * xreturn sfrom functools import partialpower_2 = partial(pow_python调用函数
随便推点
HotSpot虚拟机-程序员宅基地
文章浏览阅读2.8k次。HotSpot VM_hotspot虚拟机
面向容器技术资源调度关键技术深度对比-程序员宅基地
文章浏览阅读1.1k次。导读:之前发布了云平台技术栈(ps:点击可查看),本文主要说一下其中的容器调度技术!作者:阿里中间件,公众号:云栖社区本文以资源分配理念:拍卖、预算、抢占出发,引出Bor..._资源调度编排种类
Matplotlib解决多子图时的间距问题_matplotlib 子图间隔-程序员宅基地
文章浏览阅读2w次,点赞43次,收藏94次。Matplotlib解决多子图时的间距问题Create SubplotsAdjust Spacing of Subplots Using tight_layout()Adjust Spacing of Subplot TitlesAdjust Spacing of Overall Title参考链接Often you may use subplots to display multiple plots alongside each other in Matplotlib. Unfortunately, t_matplotlib 子图间隔
解决msys2“无法升级 mingw64 (无效或已损坏的数据库 (PGP 签名))”密钥失效问题_由 msys2-keyring-r21.b39fb11-1-any.pkg.tar.xz.sig 认-程序员宅基地
文章浏览阅读1.8w次,点赞14次,收藏50次。最近在使用msys2的时候,无法使用pacman -Syu进行更新,会出现如下提示:原因是密钥无法信赖(rely on)msys2-keyring密钥服务器。msys2官方提供了以下方法:# pacman-key --verify msys2-keyring-r21.b39fb11-1-any.pkg.tar.xz{.sig,}解决办法:1. 下载 msys2-keyring-r21.b39fb11-1-any.pkg.tar.xz 软件包# curl -O http://repo.msys_由 msys2-keyring-r21.b39fb11-1-any.pkg.tar.xz.sig 认定的签名无法验证
Android开发中的WMS详细解析-程序员宅基地
文章浏览阅读647次。的博客地址:https://juejin.cn/user/3597257779197021介绍 WindowManagerService 简称 WMS ,是系统的核心服务,主要分为四大部分,分别是窗口管理,窗口动画,输入系统中转站和Surface 管理 。WMS 的职责很多,主要的就是下面这几点:窗口管理:WMS是窗口的管理者,负责窗口的启动,添加和删除,另外窗口的大小也时有 WMS 管理的,管理..._android windowmanagerpolicy详解
小米校招产品作业解读:设计一款日记APP_写日记app的产品设计总结-程序员宅基地
文章浏览阅读1.5k次。题目:设计一个日记App,提供目标用户分析、主流程交互框图在人人都是产品经理看到这个标题,突然感到很有兴趣。众所周知,移动端输入内容远远还没有做到PC上那么便捷,是怎样的一款能让用户选择移动端而非PC来写日记呢?这一年多来,都是在这个网站上看别人的分析和经验总结,这次就不看作者的观点了,谈谈自己的一些见解。目标用户分析移动端相比PC端最大的优势,就是可以随身携带,能充分利用_写日记app的产品设计总结