语音神经科学—02.Speech synthesis from neural decoding of spoken sentences_opala ak,josh c,edward cf.speech synthesisfrom neu-程序员宅基地
Speech synthesis from neural decoding of spoken sentences(通过神经解码口语句子进行语音合成)
专业术语
speech synthesis 语音合成
brain-computer interface(BCI)脑机接口
bidirectional long short-term memory(bLSTM) 双向长短时记忆网络
vental sensorimotor cortex(vSMC) 腹侧感觉运动皮层
superior temporal gyrus(STG) 上颞回
inferior frontal gyrus(IFG) 下额回
acoustic feature 声学特征
mel-frequency cepstral coefficients(MFCCs) 梅尔频率倒谱系数
mean Mel-Cepstral Distortion(MCD) 平均梅尔倒谱失真
Pearson’s correlation 皮尔逊相关系数
acoustic feature 声学特征
Electromagnetic Articulography(EMA) 电磁声门分析
spectral features 频谱特征
auditory feedback 听觉反馈
spectrograms 频谱图
Kullback-Leibler divergence KL散度
electrode 电极
Principal Component Analysis(PCA) 主成分分析
formants 共振峰
Spectral Envelope 频谱的包络
概述
研究者设计了一个神经解码器,明确地利用人类大脑皮层活动中编码的运动学和声音表征来合成可听的语音。
背景
沟通能力丧失的神经系统疾病对大多数患者来说是十分绝望的,尽管现在有一些方法能够让患者利用通信设备,选择字母进行拼写单词,但这些方法的速度有限,我们需要研究更高速率的通信方式。
拼写是离散字母的顺序串联,而语音是一种高效的沟通形式,通过流畅的多关节发声道运动产生。因此,一种以发声道运动和它们产生的声音为重点的仿生学方法可能是实现自然语音高通信速率的唯一途径,也可能是用户最直观的学习方式。
作者研究的目标是利用神经科学和信号处理技术,将大脑信号解码为语音表达。通过通过分析大脑活动中与语音产生相关的模式和信号,研究人员希望能够准确地还原出可理解的语音输出。
语音解码设计(speech decoder design)
下图展示了一个有两阶段的解码方法:
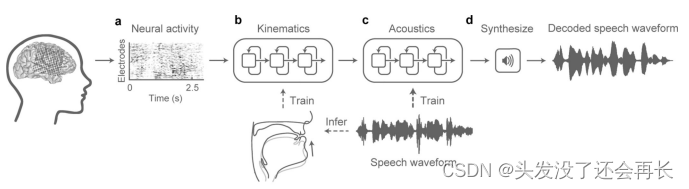
第一阶段:一个双向长短期记忆(bLSTM)循环神经网络从来自腹侧感觉运动皮层(vSMC)、上颞回(STG)和下额回(IFG)的连续神经活动(高伽马振幅包络和低频成分)中解码口腔运动学特征(图1a,b)。
第二阶段:一个独立的bLSTM从第一阶段解码得到的口腔运动学特征中解码声学特征(基频F0、梅尔频率倒谱系数(MFCCs)、声门振动和声门激励强度)(图1c)。然后,从解码得到的声学特征中合成音频信号(图1d)。
为了整合解码器的两个阶段,第二阶段(articulation-to-acoustics)直接在第一阶段(brain-to-articulation)的输出上进行训练,这样它不仅可以学习从运动学到声音的转换,还可以纠正第一阶段中可能出现的口腔运动估计误差。
合成性能(synthesis performance)
音频频谱图(audio spectrograms)
下图展示了从脑活动解码得到的语音与原始口语句子的音频频谱图的比较。共两句话,左右各一句,上方是原始语音频谱图,下方是解码到的的语音频谱图。
Q: 什么是
频谱图?原始语音频谱图和解码得到的语音频谱图代表什么?
A: 频谱图是语音信号在时间和频率上的表示。它展示了语音信号在不同频率上的能量分布随时间的变化。解码后的频谱图是通过对解码后的语音信号进行频谱分析得到的。
tips:原始口语句子的音频频谱图显示了语音信号在不同频率和时间上的声能分布。而解码的音频频谱图则表示通过解码脑活动得到的语音信号的声能分布。
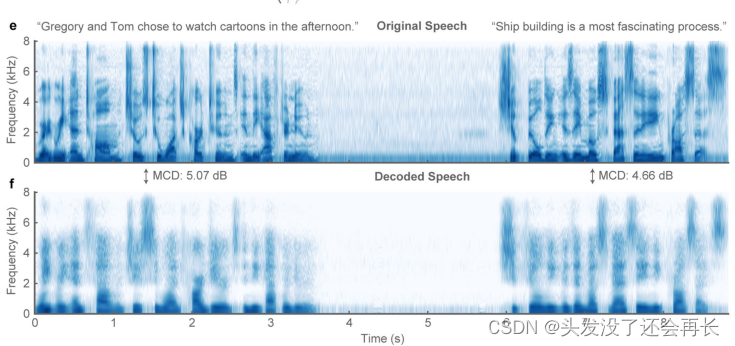
从图上可以看出,解码器保留了原始频谱图中的显著能量模式,这意味着解码后的频谱图能够准确地捕捉到原始语音幸好中重要的声学特征和能量分布。这对于语音重建任务非常重要,因为能够保留原始频谱图的能量模式可以确保解码后的语音听起来更加自然和准确。
Q: 原始语音的声学特征和能量分布是什么
A: 原始语音的声学特征和能量分布可以通过音频频谱图来表示和分析。以下是一些与原始语音相关的声学特征和能量分布的解释:
音高(Pitch):音高是指语音信号中的基频,也就是声音的音调高低。在音频频谱图中,音高对应于频谱中的周期性峰值或频率分布的周期性特征。音量(Intensity):音量表示声音的强度或能量。在音频频谱图中,音量对应于频谱中的能量分布,通常通过颜色的亮度表示。音色(Timbre):音色是指声音的质地或特征,使不同声源或乐器的声音具有独特的辨识度。音色特征在音频频谱图中通过频谱的谱线形状和分布来表示。噪声成分(Noise Components):除了基频和谐波成分之外,语音中还可能包含噪声成分,如呼吸声、环境噪声等。这些噪声成分在音频频谱图中通常表现为能量分布较广泛的频率区域。共振峰(Formants):共振峰是语音信号中的频率区域,对应于声道(如口腔和喉部)的共振峰值。共振峰在音频频谱图中表现为能量分布较高的频率峰值。
中值谱图(Median spectrograms)
Q: 什么是中值谱图
A: "Median spectrograms"是指在一组频谱图中计算得到的中值谱图。
频谱图是语音信号在时间和频率上的表示,它显示了语音信号在不同频率上的能量分布随时间的变化。对于一组语音信号,可以将每个语音信号转换为频谱图,并将它们组合在一起形成一个集合。
在这个集合中,每个时间点和频率点的能量值可以通过计算集合中对应位置的值的中位数来得到。这样得到的中值能量值可以用来构建中值谱图。
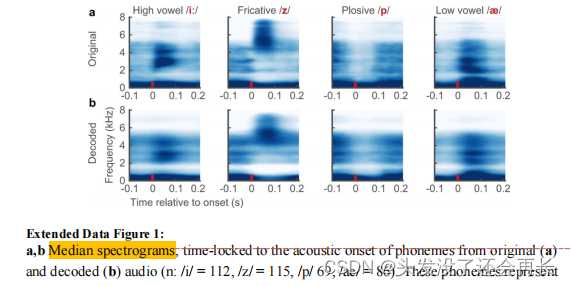
下图展示了在音素级别上重建的质量。原始和合成音素的中位数频谱图显示,解码的样本中保留了典型的频谱时域模式(例如元音/iː/和/æ/的共振峰F1-F3;以及辅音/z/和/p/的关键频谱模式,分别表现为中频带能量和宽带爆破)。
这些模式的保留和重建在研究中可以用来评估解码算法在音素级别上的准确性和效果。
Q: 什么是频谱时域模式?
A: "频谱时域模式"指的是声音信号在频谱和时间域上的特定模式或特征。它描述了声音信号在不同频率和时间点上的能量分布和变化。频谱时域模式指的是在频谱图中可以观察到的特定形态、峰值或能量集中的模式。
例如,对于元音音素,频谱时域模式可以表现为具有清晰共振峰的频谱形态,这些共振峰对应于声道的共振特征。对于辅音音素,频谱时域模式可以表现为具有特定的峰值或能量集中的频率区域,这些频率区域对应于辅音的特征如爆破音、摩擦音等。
听觉任务
在听觉任务中,参与者被要求听合成的语音,并根据自己的听觉感知进行相应任务。分为单词级别和句子级别的转写任务。
单词级别
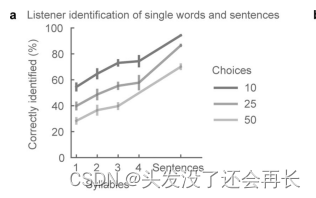
参与者需要听一个合成单词,并尝试将其正确地识别出来。评估了从合成句子中分离出来的325个单词,并量化了单词长度(音节数) 和单词数量(10、20、50个单词)对语音理解的影响。
观察到的结果是,随着单词音节数增加,听者识别的更加准确,相反,随着单词数量的增加,听者识别的准确度降低,这和自然语音感知是一致的。
句子级别
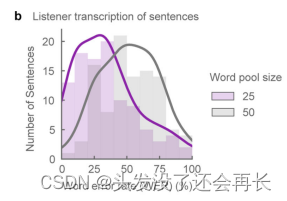
参与者需要听一个合成的句子,并尽可能准确地将其转写成文字形式。 作者设计了一个封闭词汇表,听众听到整个合成的句子,并通过从一个定义的池(25或50个单词)中选择单词来记录他们听到的内容。这些单词包括目标单词和测试集中的随机单词。
观察到的结果是,如下图展示了每个句子的平均单词错误率(WER),在大小为25的池中,句子转录的WER中值为31%,在大小为50的池中,句子转录的WER中值为53%。
解码性能的量化
特征级别
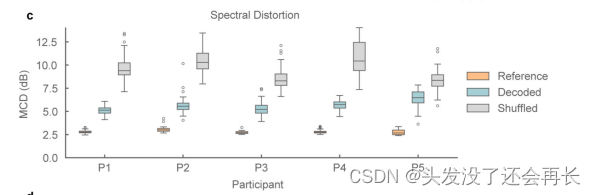
研究人员对所有参与者的解码性能进行了特征级别的量化评估。在语音合成中,通常使用平均梅尔倒谱失真(mean Mel-Cepstral Distortion,MCD)来报告合成语音与真实语音之间的频谱失真。梅尔频率带强调了音频频谱中感知相关频率带的失真情况。
Q: 什么是
Mel-Cepstral Distortion?
A: Mel-Cepstral Distortion基于梅尔倒谱系数(Mel-frequency cepstral coefficients,MFCCs),它是一种常用于语音信号处理的特征表示方法。MFCCs将语音信号转换为在频谱上均匀分布的倒谱系数,以模拟人耳对音频的感知。MFCCs通常用于表示语音的谱特征。
Mean Mel-Cepstral Distortion计算合成语音的MFCCs与目标语音的MFCCs之间的距离或差异。它可以通过计算两组MFCCs之间的欧氏距离或其他距离度量来获得。然后,将所有MFCC系数之间的距离取平均 得到Mean Mel-Cepstral Distortion。
如下图,将神经合成语音(Decoded)的MCD与基于关节运动学的参考合成语音(Reference)和机会水平解码(Shuffled)进行比较(较低的MCD值表示性能更好)。参考合成模拟了关节运动学的完美神经解码。对于5位参与者,解码语音的MCD中位数的范围为5.14dB到6.58dB。
原始声学特征和解码声学特征的相关性
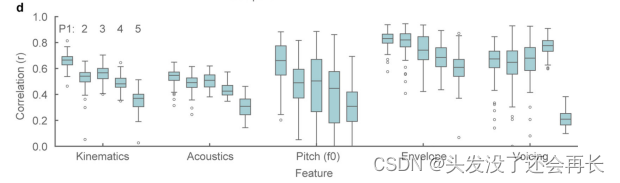
研究人员计算了原始声学特征和解码声学特征之间的相关性。对于每个句子和特征,使用该特征的每个样本(以200 Hz的采样率)计算了皮尔逊相关系数。
Q: 什么是皮尔逊相关系数?
A: 皮尔逊相关系数(Pearson correlation coefficient)是一种用于衡量两个变量之间线性相关程度的统计量。它衡量的是两个变量之间的线性关系的强度和方向。
皮尔逊相关系数的取值范围在-1到1之间,其中:
- 当
相关系数为1时,表示两个变量完全正相关,即当一个变量增加时,另一个变量也会以相同的比例增加。- 当
相关系数为-1时,表示两个变量完全负相关,即当一个变量增加时,另一个变量会以相同的比例减少。- 当
相关系数接近0时,表示两个变量之间几乎没有线性关系。
下图中绘制了参与者之间的平均解码声学特征(acoustic feature)(包括强度(intensity)、梅尔倒谱系数(MFCCs)、激励强度(excitation strengths)和声音(voicing))与推断的运动学(inferred kinematics)之间的句子级别相关性。声调特征(如基频(pitch F0)、语音包络(speech envelope)和声音(voicing))的解码相关性明显高于机会水平
此外,作者还研究了其他相关特征的解码性能:
- 动力学特征的解码性能
下图中,显示了所有33个解码的口腔运动学特征与真实值之间的相关性。动力学特征使用EMA(电磁声门分析)技术获取,表示了口腔运动器官(嘴唇、下颌和舌头的三个点)在声道中矢状面上的X和Y坐标轨迹。此外,还有Manner特征,它们是EMA的补充,进一步描述了与声学相关的运动。箱线图显示了这些特征的相关性分布情况。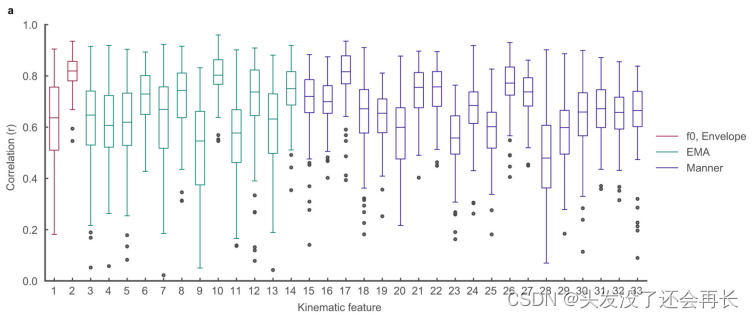
Q:
EMA是什么?
A: EMA是电磁声门分析(Electromagnetic Articulography)的缩写。它是一种用于研究和记录人类语音产生过程中口腔运动的技术。EMA通过使用传感器和磁场来捕捉和测量口腔和喉部运动的位置和轨迹。
在EMA系统中,被测者被要求戴上具有传感器的小磁体,通常是放置在舌头、嘴唇和下颌等口腔运动器官上。这些传感器是通过磁场感应原理来测量其位置和方向的。EMA系统中还包括一个测量设备,该设备生成和控制磁场,并记录传感器的位置信息。
Q:
Manner是什么?
A: 在语音学中,Manner(发音方式)是描述辅音发音方式的术语。它指的是空气流在口腔中的通路和通过使用不同的发音器官来产生不同音素的方式。
Manner可以用来描述辅音发音的特征和方式,以下是一些常见的Manner类型:
阻塞音(Stops):当发音器官完全阻止空气流经过时产生的音。例如,/p/和/b/是阻塞音,它们在发音时嘴唇紧闭,然后突然松开。擦音(Fricatives):发音器官部分阻碍空气流,产生摩擦音。例如,/s/和/f/是擦音,它们通过使气流通过狭窄的通道来产生摩擦噪声。破擦音(Affricates):结合阻塞音和擦音的特征,它们开始时有一个阻塞音部分,然后转变为擦音。例如,/tʃ/(如英语中的"ch")是一个破擦音。鼻音(Nasals):发音器官中有一个开放通道,允许空气通过鼻腔流出。例如,/m/、/n/和/ŋ/(如英语中的"ng")是鼻音。侧音(Lateral):舌尖挡住中央通道,空气从舌侧流出。例如,/l/是一个侧音。半元音(Semi-vowels):发音器官形状类似元音,但较为接近辅音。例如,/j/(如英语中的"y")和/w/是半元音。
这些不同的Manner类型描述了不同发音方式的特征和机制,对于研究语音产生和发音学有着重要的意义。
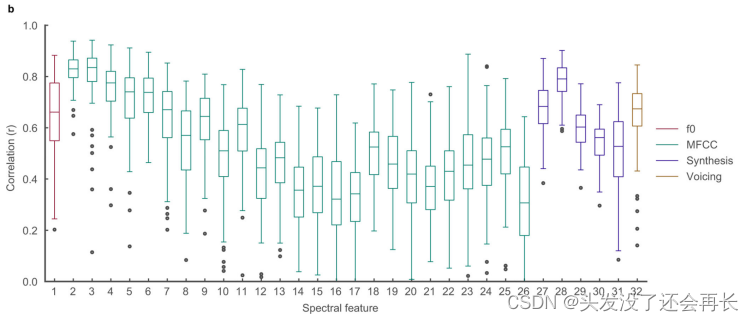
- 频谱特征的解码性能
下图中,显示了所有32个解码的频谱特征与真实值之间的相关性。频谱特征使用MFCC(梅尔频率倒谱系数)获取,它们是描述感知相关频段功率的25个系数。此外,还有合成特征,它们描述了语音合成所需的声门激励权重。箱线图显示了这些特征的相关性分布情况。
解码器特性(Decoder characteristics)
前面已经展示过解码器设计图,如下图,该解码器是一个两阶段的解码器,先从EEG中解码空腔运动学特征,再解码出声学特征,最后合成语音。因为本文想要设计的解码器是你作为临床使用,所以需要考虑到有几个关键因素会影响到解码器的性能。
第一点:数据
对于严重瘫痪或者语言功能受限的病人,很难获取大量数据用于训练解码器。
如果使用直接解码器(direct decoder),即直接从EEG中解码声学特征,而不需要先经过关节运动学解码器转换为运动学特征。如下图所示,当仅使用25分钟的语音数据就能够获得可靠的解码性能, 随着数据量的增加,性能仍然可以进一步提高。然而,如果没有关节运动学的中间步骤,直接从ECoG到声学特征的解码多谱归一化失真(MCD)会受到0.54 dB的偏差(0.2 dB在感知上是可察觉的21)。
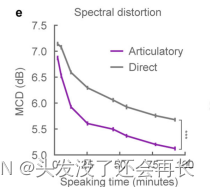
因此作者设计了一个两阶段的解码器,研究中发现明确地建模关节运动学作为中间特征,会比直接从电极脑电图(EEG)信号中解码声学特征具有明显的优势。从上图中我们也能看到两种解码器之间的差距,因为关节运动学直接反映了语音产生过程中的运动信息,与声学特征之间存在更直接的关联。 通过先解码关节运动学,然后再从关节运动学到声学特征进行解码,我们能够更准确地恢复语音特征。第二点:保留的语音学特性
当从脑信号解码语音时,确保合成语音保留自然语音的语音学特征是非常重要的。这意味着解码后的语音应该听起来与所意图表达的单词或话语相似,并且能够被人正常理解和识别。
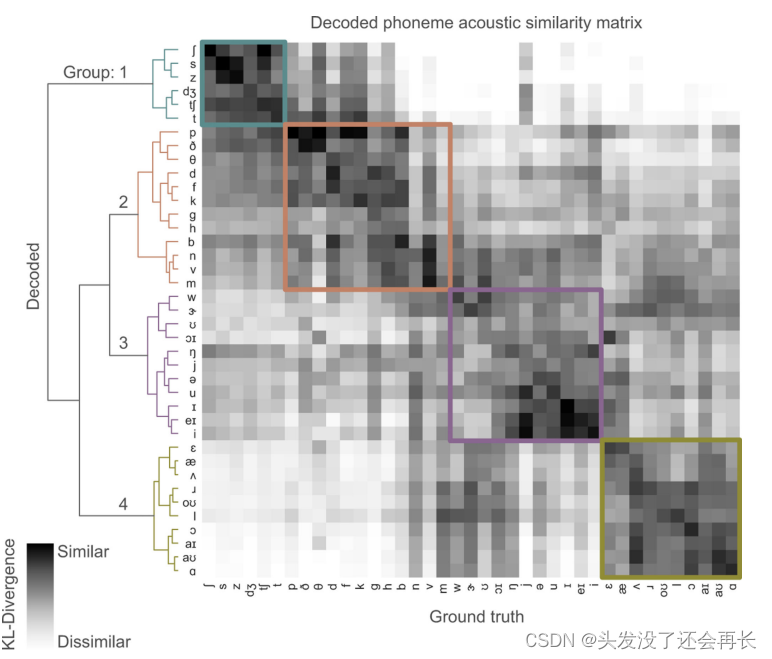
因此作者评估了合成语音和自然语音之间的相似性来了解所保留的语音学特性,这可以包括对音位(语音中的基本单位)的准确性、音调、音高、语速和语音韵律等方面进行分析和比较。作者使用Kullback-Leibler(KL)散度来比较每个解码音素的频谱特征分布与每个真实音素的分布,以确定它们的相似程度。(关于KL散度的理解可以参考这篇博客:机器学习-KL散度的直观理解+代码)
如下图所示,作者计算了声学相似度矩阵比较解码音素和原始发音音素的声学特性。相似度是通过首先为每个音素(解码和原始)估计一个高斯核密度,然后计算解码和原始音素分布之间的Kullback-Leibler(KL)散度来计算的。每一行将一个解码音素的声学特性与原始发音音素(列)进行比较。对得到的相似度矩阵进行了层次聚类。数据来自P1。
第三点:电极的放置
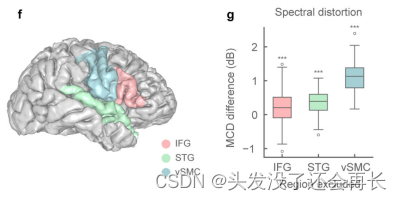
如下图f展示了电极放置的三个与语音产生相关的三个区域(IFG、STG、vSMC)。
图g展示了删除其中一个区域的电极之后解码器的解码性能,可以看出,无论删除哪一个区域的电极都会导致解码性能下降,尤其在删除vSMC区域的电极后,解码性能下降最严重,MCD降低了1.13dB。
第四点:可迁移性
作者想要验证在固定数据集上训练的解码器是否可以用于新的句子上。作者对比了两个解码器,一个在所有的句子上进行训练,包括测试集训练集,另外一个只在测试集句子上训练。实验结果如下图所示,可以看出这两个解码器,无论是相同的句子或者新句子上的解码性能在MCD和频谱特征相关性上都没有显著差异。
这说明解码器可以推广到解码器从未被训练过的任意单词和句子。
合成默契语音(Synthesizing mimed speech)
Q: 什么是默契语音?什么是合成默契语音?
A:「默契语音」指的是在没有实际发声或产生可听到的语音声音的情况下产生类似语音的手势或动作。它可以涉及到发音器官(如嘴唇、舌头、下颌)的运动。
「合成默契语音」是指从非语言或无声语言动作中生成可听到的语音的过程。它涉及将在无声语言中进行的运动和手势转换为可理解和识别的语音声音。
人发声的时候,会产生听觉反馈(auditory feedback),这反馈会传到大脑皮层,产生电信号,而我们知道,电信号就是我们解码器的输入(EGG),所以,我们需要探究,是否解码器依赖于听觉反馈产生的电信号。
Q: 什么是听觉反馈?
A: 发音的听觉反馈是指一个人在发声过程中所产生的声音通过听觉系统传达回大脑的过程。当我们发音时,声音通过喉咙、口腔和鼻腔等声道传出,产生声音波动。这些声音波动被传播到我们的耳朵,然后被内耳中的听觉神经细胞接收和转化为电信号,最终通过神经途径传输到大脑的听觉皮层。
所以作者设计了无声模拟对解码器进行测试。测试了一组包含58个句子的保留集,其中参与者(P1)首先以声音的形式朗读每个句子,然后默默模仿同样的句子,进行相同的发音动作但不发出声音。作者将原始语音(a)、发声状态下解码得到的语音(b)、不发声状态下解码得到的语音可视化如下图所示。尽管解码器没有在模仿的句子上进行训练,合成的无声语音的声谱图展现了与合成的可听语音相同句子的类似频谱模式。
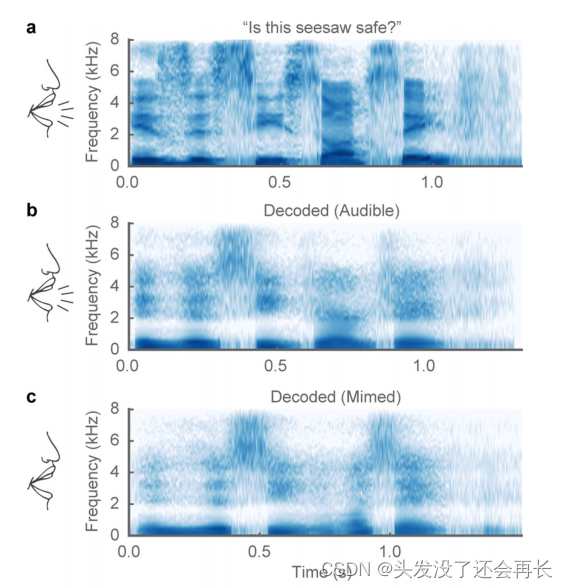
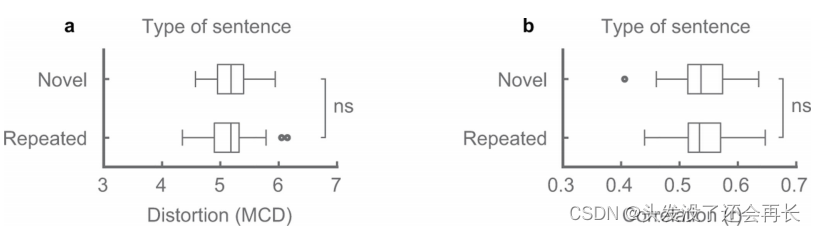
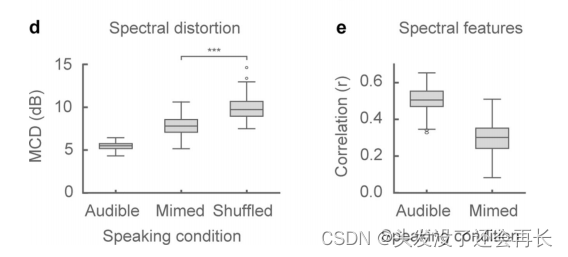
然后作者计算了在不同状态下合成语音与原始语音的MCD、频谱特征相关性,如下图所示,可以看到,无声语音略差于发声语音的合成,但是也证明了,无声语音合成的可能性。
解码语音发音的状态空间(State-space of decoded speech articulation)
Q: 标题的含义?
A: 在这个短语中,“decoded speech articulation” 指的是已解码的语音发音,即从某种编码形式还原出的语音信息。而 “state-space” 则是指状态空间,是一个用来描述系统状态变化的数学模型。
因此,“state-space of decoded speech articulation” 指的是用状态空间模型来描述已解码语音发音的变化过程。这个状态空间模型可以包括不同的状态变量,例如嘴唇、舌头、下颌的位置、速度、加速度等,用来表示语音发音器官在时间上的变化。通过这个状态空间模型,我们可以分析和描述解码后的语音发音在时间和空间上的变化特征,从而更好地理解和研究语音产生过程。
因为模拟底层运动学可以提高解码性能,因此我们接下来希望更好的了解从群体神经活动中解码出的运动学特征的性质。
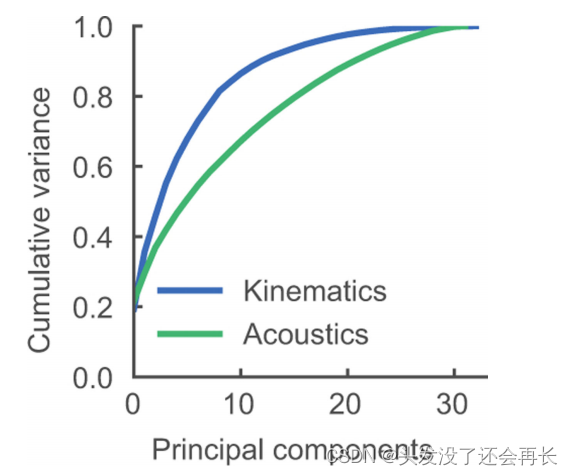
作者通过对口腔运动学特征进行主成分分析(PCA),计算状态空间的投影,以获得低维度的运动学状态空间轨迹。在总共的33个主成分中,前10个主成分(PCs)解释了85%的方差,前两个主成分解释了35%的方差,结果如下图所示,对于每一个语音运动学和声学的表示,计算主成分分析,并对每个附加主成分的方差进行累积求和。
Q: PCA是什么?
A: PCA是主成分分析(Principal Component Analysis)的缩写。它是一种常用的统计方法和降维技术,用于分析和处理多维数据集。
PCA的主要目标是通过线性变换,将高维数据转换为低维表示,同时尽量保留原始数据的最大方差。通过找到一组新的正交变量,称为主成分,PCA可以将原始数据在新的坐标系中进行表示。每个主成分都是原始数据在不同方向上的线性组合,按照方差的降序排列,表示数据中的变异性从大到小。
Q:
为什么PCA要保留数据的最大方差?
A: 当我们进行降维或特征提取时,我们希望保留尽可能多的有用信息,同时减少冗余和噪声。方差可以看作是数据中的有用信息的度量,较大的方差表示数据在该方向上具有较大的变化和差异,反之亦然。
通过保留尽可能多的方差,PCA能够捕捉到数据中最显著的模式和变化。较大的方差对应于数据中重要的特征和变异性,而较小的方差对应于数据中的噪声或冗余信息。因此,通过选择具有较大方差的主成分,PCA能够提取出数据中最显著的特征,并在保留关键信息的同时减少数据的维度。
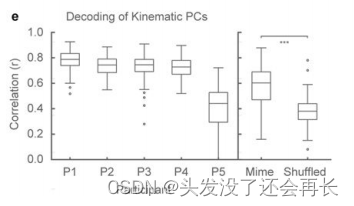
在下图a和b中,一个句子的运动轨迹被投射到前两个主成分上,可以看到,这些轨迹都被很好的解码出来了。(图e可视化了所有参与者的中位数r>0.75,除了P5,r代表前两个主成分的平均r)此外,无声语音也被很好的解码出来,中位数r=0.6。
并且,这些轨迹似乎表现出连续语音中音节模式的动态变化,辅音(consonants 灰色线)和元音(vowels 蓝色线)的时间过程被绘制在状态轨迹上,并分别倾向于对应轨迹的波谷和波峰。
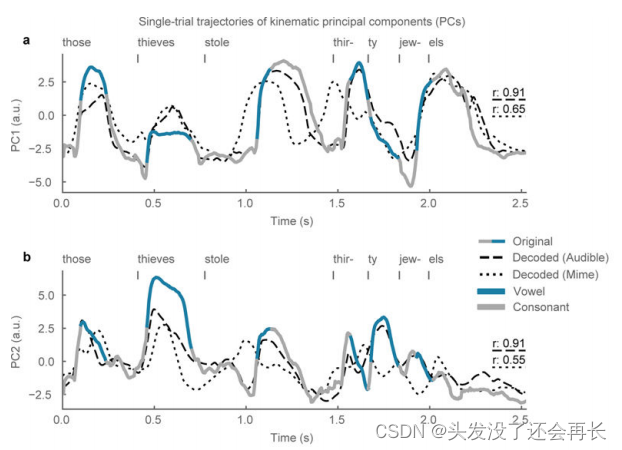
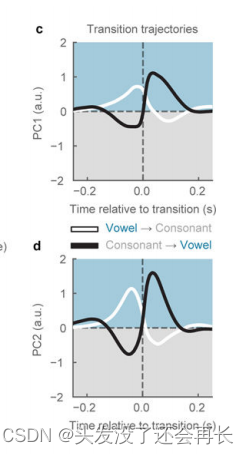
研究发现,两种类型的运动学轨迹在元音和辅音之间呈现出双相的特征,即从“高”状态到“低”状态的转变(白色),反之亦然(黑色)。在下图c、d中,从每个元音辅音转换(n=22453)和辅音元音转换(n=22453)中采样,并绘制了PC1和PC2平均轨迹的500 ms轨迹。研究人员发现PC1和PC2保留了元音和辅音状态的双相轨迹,但对于特定音素表现出特异性。这说明PC1和PC2不仅仅描述了下颌的张合和闭合,而是描述了声道的全局张合配置。
这些发现与关于人类言语行为的理论解释一致。这些理论认为,高维度的语音声学特征可以在较低维度的口腔运动学状态空间中得到解释。换句话说,人类言语行为可以通过较少的运动学特征来表示和理解。
通过将不同参与者的相同句子的产出投影到各自的运动学状态空间中,并对它们进行了相关性分析,以评估解码的状态空间轨迹的相似性。结果发现,状态空间轨迹非常相似,相关系数大于0.8。这表明解码器很可能依赖于跨说话者之间共享的表征。这种共享的表征对于泛化是至关重要的,因为它意味着解码器能够在不同说话者之间建立一种通用的理解和表达方式。
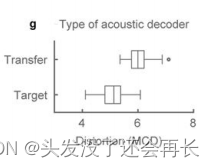
对于无法说话的人群,首先学习使用运动学解码器(第一阶段)可能更直观和更快速,同时使用在独立收集的语音数据上训练的现有运动学到声学的解码器(第二阶段)。即两个阶段来自不同的人的数据。
下图中,我们展示了从源参与者(P1)转移第二阶段到目标参与者(P2)的合成性能。声学转移表现良好,尽管比仅在目标参与者(P2)上训练第一阶段和第二阶段的情况下略差,这可能是因为MCD指标对说话者身份敏感。
总结
- 针对严重瘫痪或者由语言障碍的病人,我们需要研究一个高效的交流方式来帮助他们交流。而目前最快的方法就是直接从大脑皮层的神经活动中解码出语音。
- 本文作者提出了一个两阶段的解码器,先从脑电信号中解码出口腔运动学表征,再从口腔运动学表征中解码出声学特征,最后合成语音信号。
- 作者在本文中对解码器的效果做了大量的实验进行分析,比如频谱图,中值频谱图。作者也设计了听觉任务,对合成的语音进行测试。然后针对解码器的特征进行了四点分析,分析了影响解码器性能的四个关键因素。
- 为了排除听觉反馈对解码器的影响,作者也通过合成无声语音进行了对比实验,并在无声语音合成上也取得了较好的解码效果,为临床应用带来了更多的可能性。
- 作者也使用主成分分析,从群体神经活动中解码出的运动学特征的性质。实验结果证明,语音合成仅需要少量的空腔运动学特征便可以实现很好的效果。
- 将不同参与者的相同句子的产出投射到各自的运动学状态空间中,发现他们的状态空间轨迹非常相似,这表明解码器很可能依赖于跨说话者之间的共享表征。并且作者针对无法说话的人群采用实验,证明了这一点。
智能推荐
远程桌面服务器连接失败,Windows服务器远程桌面连接失败是什么原因-程序员宅基地
文章浏览阅读6.1k次。1、先通过显示器直接连接的方式连接到那台连接出错的服务器上。登陆以后,在桌面上的此电脑图标上面点右键,选择属性。2、然后在属性页面中我们可以看到对应的系统版本是Windows Server 2016。CPU是intel xeon型号,内存是16g。这个时候我们点击它左上角的远程设置。3、在远程设置界面,我们可以看到,它默认的设置是允许远程到这台服务器上,但是它下面勾选了”仅允许运行使用网络级别身份..._远程桌面服务无法加入服务器 win-th0hfpjn9vr 上的连接代理。 错误: 当前异步消息
ApacheCN 翻译活动进度公告 2019.6.15-程序员宅基地
文章浏览阅读109次。Special Sponsors我们组织了一个开源互助平台,方便开源组织和大 V 互相认识,互相帮助,整合资源。请回复这个帖子并注明组织/个人信息来申请加入。请回复这个帖子来推荐希望翻译的内容。如果大家遇到了做得不错的教程或翻译项目,也可以推荐给我们。我们会联系项目的维护者,一起把...
Python培训课程深圳,群年轻人正在追捧Python-程序员宅基地
文章浏览阅读182次。记者 | 伍洋宇 袁伟腾编辑 | 文姝琪1李楠打算年底换份新工作,Python方向的、纯软件岗位,发挥空间更大的全栈开发工程师就很不错,目标月薪一万二。这使得他在今年下半年开始系统学习Python。因为本科是计算机专业,期间也自学过Python这门语言,李楠选择了继续自学。学Python真的有用吗?“当然有用啦,没用谁去学它啊。”今年24岁、刚刚毕业一年的李楠这么说。目前他在一家智能硬件公司做嵌入式开发软件工程师,月薪一万,工作是“往硬件里面写软件”,他觉得太枯燥了。“代码都是写好的,基..
Ubuntu下安装R,升级R版本,安装Rstudio,安装Rstudio Server以及安装Shiny Server_marutter-ubuntu-rrutter-focal.list-程序员宅基地
文章浏览阅读2.9k次。一、安装R只需要一步命令:sudo apt-get install r-base二、升级R版本第一步给Ubuntu指定PPA:sudo add-apt-repository ppa:marutter/rrutter第二步:sudo apt-get update第三步:sudo apt-get upgrade三、安装Rstudio直接去Rstudio官网下载最新版的Rst..._marutter-ubuntu-rrutter-focal.list
Redis5.0集群搭建(Redis Cluster)_rediscluster搭建 5.0-程序员宅基地
文章浏览阅读9.1k次。Redis5.0集群搭建RedisCluster_rediscluster搭建 5.0
题目-java基础_面向过程的程序设计是把计算机程序视为一系列的命令集合-程序员宅基地
文章浏览阅读405次。多线程和单线程线程不是越多越好,假如你的业务逻辑全部是计算型的(CPU密集型),不涉及到IO,并且只有一个核心。那肯定一个线程最好,多一个线程就多一点线程切换的计算,CPU不能完完全全的把计算能力放在业务计算上面,线程越多就会造成CPU利用率(用在业务计算的时间/总的时间)下降。但是在WEB场景下,业务并不是CPU密集型任务,而是IO密集型的任务,一个线程是不合适,如果一个线程在等待数据时,把CPU的计算能力交给其他线程,这样也能充分的利用CPU资源。但是线程数量也要有个限度,一般线程数有一个公式:最佳启_面向过程的程序设计是把计算机程序视为一系列的命令集合
随便推点
储能8串电池用140W DCDC电路2 USB_A 2个 TYPE-C 2A2C_pl56002-程序员宅基地
文章浏览阅读78次。储能8串电池,输出是2个C口,2个USBA口,功率是C1:140W,C2:100W,A1:18W,A2:18W.A1,A2不降功率,使用IP2736,IP2723T,IP2163,_pl56002
python3.8.1手机版下载-Python官方下载|Python最新版 V3.8.1 -推背图下载站-程序员宅基地
文章浏览阅读2k次。Python最新版是一款功能强大脚本编程软件。Python最新版它可以帮助编程人员更加便捷的进行代码编写,适合完成各种高层任务,兼容所有的操作系统中使用,因为它的便捷性,在程序员中得到广泛的应用,新入门的编程学习者可以使用它快速学习,欢迎前来下载!功能特点1、简单易学Python极其容易上手,因为Python有极其简单的说明文档 。2、免费开源Python是FLOSS(自由/开放源码软件)之一。3..._手机版python官网下载
Unity3D学习之(坦克大战解析)-程序员宅基地
文章浏览阅读3.9k次。欢迎大家光临我的博客!对坦克大战项目的解析:一、游戏模块主要是:注册模块、登录模块、我方模块、和敌方模块。①注册模块:可以跳转到登录界面!②登录模块:可以跳转到游戏界面!③我方模块:可以前后左右移动,可以发射子弹,可以死亡销毁。④敌方模块:可以可以发射子弹,追踪我方的位置,也可以随机出现,可以死亡销毁。 二、所用到的技术①键盘事件 //敌我双方通过键盘上下左右键的移动②位移 ...
【linux】进程和线程的几种状态及状态切换_linux线程状态-程序员宅基地
文章浏览阅读3.6k次,点赞46次,收藏54次。进程和线程的状态_linux线程状态
Java/Mysql数据库+SSM+学生信息管理系统 11578(免费领源码)计算机毕业设计项目推荐上万套实战教程JAVA、PHP,node.js,C++、python、大屏可视化等-程序员宅基地
文章浏览阅读1.1k次,点赞22次,收藏20次。免费领取项目源码,请关注●点赞●收藏并私信博主,谢谢~本系统以实际运用为开发背景,通过系统管理员可以对所有的学生和教师等人员以及学生相关联的一些学生管理、分配任务、完成任务、打卡签到、师生交流等数据信息进行统一的管理,方便资料的保留。教师和学生可以通过注册,然后登录到系统当中,对分配任务、完成任务、打卡签到以及师生交流这些信息进行查询管理。总的来说,系统的前台是通过Java页面展示,后台使用SSM这个框架,数据库采用目前流行的开源关系型数据库MYSQL。
如何在群辉NAS系统下安装cpolar套件,并使用cpolar内网穿透?_在群晖nas安装cpolar套件-程序员宅基地
文章浏览阅读1.2k次,点赞39次,收藏34次。群晖作为大容量存储系统,既可以作为个人的私有存储设备,也可以放在小型企业中作为数据中心使用。其强大的数据存储和管理功能,让其还能够胜任更多任务。但由于群晖的应用场景所限,这些功能通常只能在局域网内实现,想要让群晖NAS存储的数据能在公网访问到,我们可以借助cpolar的辅助,轻松实现在公共互联网访问内网群晖NAS上的数据。在这之前,我们还是需要了解下cpolar的基本操作方式。_在群晖nas安装cpolar套件