十四、Golang协程,通道详解_golang的通道与协程-程序员宅基地
技术标签: # Golang golang # Go语言进阶 后端 开发语言
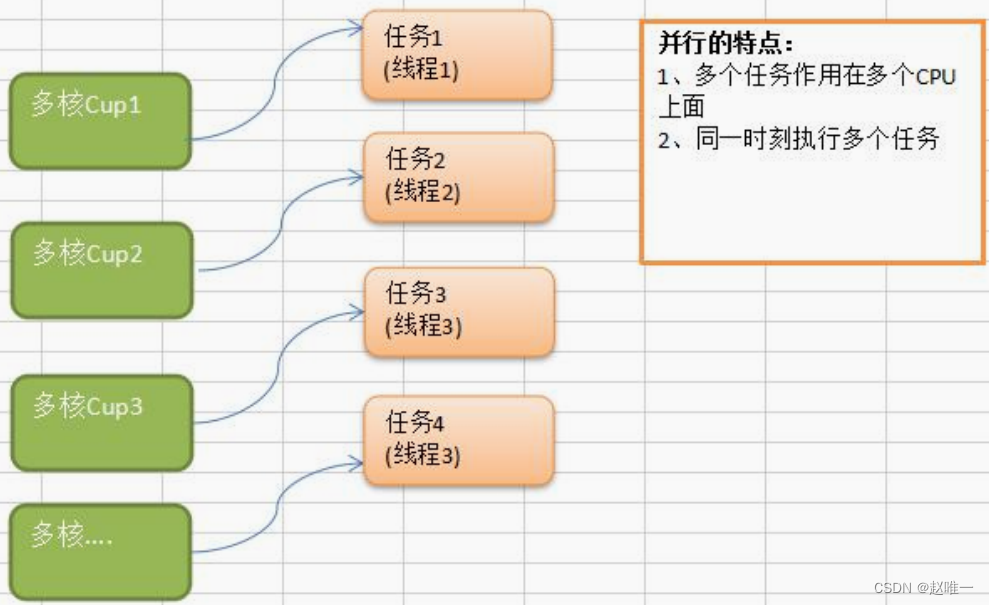
进程、线程以及并行、并发
关于进程和线程
一个进程至少有 5 种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
关于并行和并发
多线程程序在单核 CPU 上面运行就是并发多线程程序在多核 CUP 上运行就是并行。

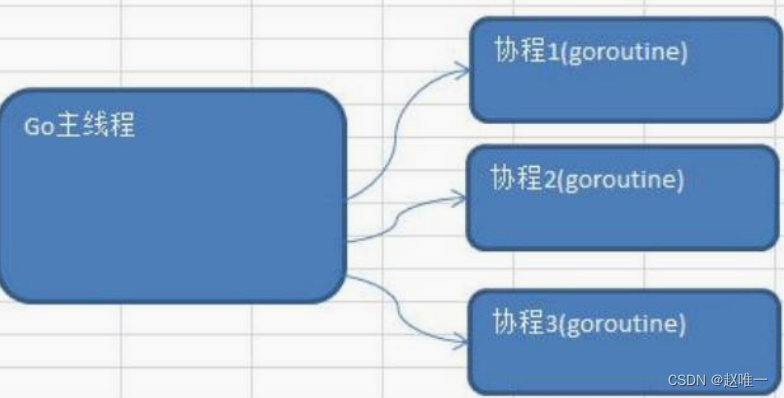
Golang 中的协程(goroutine)以及主线程
Golang 中多协程可以实现并行或者并发。
Goroutine 的使用
package main
import(
"fmt"
"time"
)
// 在主线程中也每隔10毫输出"卫宫士郎", 输出2次后,退出程序
// 要求主线程和goroutine同时执行
func test() {
for i := 0; i < 10; i++ {
fmt.Println("test() 测试专用..........")
time.Sleep(time.Millisecond * 100)
}
}
func main(){
go test()
for i := 1; i <=2; i++ {
fmt.Println("main () 卫宫士郎")
time.Sleep(time.Millisecond*10)
}
}
暴露出一个问题:主线程执行完毕后即使协程没有执行完毕
所以我们对代码进行改造,可以让主线程和协程并行的同时,主线程执行完毕还不会同时带领协程退出运行。
注意:
1、主线程执行完毕后即使协程没有执行完毕程序也会退出
2、协程可以在主线程没有执行完毕前提前退出协程是否执行完毕不会影响主线程的执行为了保证我们的程序可以顺利执行我们想让协程执行完毕后在执行主进程退出。
这个时候我们可以使用sync.WaitGroup 等待协程执行完毕
sync.WaitGroup
package main
import(
"fmt"
"time"
"sync"
)
// 在主线程中也每隔10毫输出"卫宫士郎", 输出2次后,退出程序
// 要求主线程和goroutine同时执行
//主线程退出后所有的协程无论有没有执行完毕都会退出,所以我们在主进程中可以通过WaitGroup等待协程执行完毕
var sw sync.WaitGroup
func test() {
for i := 0; i < 10; i++ {
fmt.Println("test() 测试专用..........")
time.Sleep(time.Millisecond * 100)
}
sw.Done() //协程计数器-1
}
func main(){
sw.Add(1) //协程计数器+1
go test()//表示开启一个协程
for i := 1; i <=2; i++ {
fmt.Println("main () 卫宫士郎")
time.Sleep(time.Millisecond*10)
}
sw.Wait() //等待协程执行完毕...
fmt.Println("主线程执行完毕、、、、、、")
}
启动多个 Goroutine
package main
import(
"fmt"
"time"
"sync"
)
// 多个协程Goroutine启动
var sw sync.WaitGroup
func test0() {
for i := 0; i < 5; i++ {
fmt.Println("test0() 测试专用..........")
time.Sleep(time.Millisecond * 100)
}
sw.Done() //协程计数器-1
}
func test1() {
for i := 0; i < 5; i++ {
fmt.Println("test1() 测试专用..........")
time.Sleep(time.Millisecond * 100)
}
sw.Done() //协程计数器-1
}
func main(){
sw.Add(1) //协程计数器+1
go test0()//表示开启一个协程
sw.Add(1)//协程计数器+1
go test1()//表示开启一个协程
for i := 1; i <=2; i++ {
fmt.Println("main () 卫宫士郎")
time.Sleep(time.Millisecond*10)
}
sw.Wait() //等待协程执行完毕...
fmt.Println("主线程执行完毕、、、、、、")
}
设置 Golang 并行运行的时候占用的 cup 数量
package main
import (
"fmt"
"runtime"
)
func main() {
//获取当前计算机上面的Cup个数
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum)
//可以自己设置使用多个cpu
runtime.GOMAXPROCS(cpuNum - 1)
fmt.Println("设置完成")
}
//cpuNum= 8
//设置完成
来求一个素数的操作如下:
package main
import (
"fmt"
"time"
)
func main() {
start := time.Now().Unix()
fmt.Println(start)
for num := 2; num < 10; num++ {
var flag = true
for i := 2; i < num; i++ {
if num%i == 0 {
flag = false
break
}
}
if flag {
fmt.Println(num, "是素数")
}
}
end := time.Now().Unix()
fmt.Println(end)
fmt.Println(end-start)
}
goroutine for循环实现
package main
import (
"fmt"
"sync"
"time"
)
//需求:要统计1-120000的数字中那些是素数?goroutine for循环实现
/*
1 协程 统计 1-30000
2 协程 统计 30001-60000
3 协程 统计 60001-90000
4 协程 统计 90001-120000
// start:(n-1)*30000+1 end:n*30000
*/
var wg sync.WaitGroup
func test(n int) {
for num := (n-1)*30000 + 1; num < n*30000; num++ {
if num > 1 {
var flag = true
for i := 2; i < num; i++ {
if num%i == 0 {
flag = false
break
}
}
if flag {
// fmt.Println(num, "是素数")
}
}
}
wg.Done()
}
func main() {
for i := 1; i <= 4; i++ {
wg.Add(1)
go test(i)
}
wg.Wait()
fmt.Println("执行完毕")
}
Channel 管道
channel
单纯地将函数并发执行是没有意义的。
函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。
channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
channel类型
channel是一种类型,一种引用类型。声明通道类型的格式如下:
var 变量 chan 元素类型 举几个例子:
var ch1 chan int // 声明一个传递整型的通道
var ch2 chan bool // 声明一个传递布尔型的通道
var ch3 chan []int // 声明一个传递int切片的通道 创建channel
通道是引用类型,通道类型的空值是nil。
var ch chan int
fmt.Println(ch) // <nil>package main
import "fmt"
func main() {
ch1 := make(chan int ,4)
ch1<- 1
ch1<- 2
ch1<- 3
ch2 := ch1
ch2<-4
<-ch1
<-ch1
<-ch1
d:= <-ch1
fmt.Println(d)
}
//4副本ch2的值添加后,取出ch1的值改变了
声明的通道后需要使用make函数初始化之后才能使用。
创建channel的格式如下:
make(chan 元素类型, [缓冲大小]) channel的缓冲大小是可选的。
举几个例子:
//创建一个能存储 10 个 int 类型数据的管道
ch1 := make(chan int, 10)
//创建一个能存储 4 个 bool 类型数据的管道
ch2 := make(chan bool, 4)
//创建一个能存储 3 个[]int 切片类型数据的管道
ch3 := make(chan []int, 3)package main
import "fmt"
func main() {
//创建channel
ch := make(chan int, 3)
//2、给管道里面存储数据
ch <- 12
ch <- 33
ch <- 3234
//获取管道里面的内容
a := <-ch
fmt.Println(a) //12
<-ch //从管道里面取值 //33
c := <-ch
fmt.Println(c) //3234
ch <- 1
ch <- 22
//打印管道的长度和容量
fmt.Printf("值:%v 容量:%v 长度%v\n", ch, cap(ch), len(ch))
}
已经消费了的,就相当于没有,再添加的从新算

channel操作
通道有发送(send)、接收(receive)和关闭(close)三种操作。
发送和接收都使用<-符号。
现在我们先使用以下语句定义一个通道:
ch := make(chan int) 发送
将一个值发送到通道中。
ch <- 10 // 把10发送到ch中 接收
从一个通道中接收值。
x := <- ch // 从ch中接收值并赋值给变量x
<-ch // 从ch中接收值,忽略结果 关闭
我们通过调用内置的close函数来关闭通道。
close(ch) 关于关闭通道需要注意的事情是,只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
1.对一个关闭的通道再发送值就会导致panic。
2.对一个关闭的通道进行接收会一直获取值直到通道为空。
3.对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。
4.关闭一个已经关闭的通道会导致panic。 管道阻塞
无缓冲的通道
package main
import (
"fmt"
)
func main() {
ch := make(chan int)
ch <- 123
fmt.Println("传递成功......")
} 上面这段代码能够通过编译,但是执行的时候会出现以下错误:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
E:/goroutine_channel_demo/route_demo/main.go:8 +0x31
exit status 2为什么会出现死锁
因为我们使用ch := make(chan int)创建的是无缓冲的通道,无缓冲的通道只有在有接收值的时候才能发送值。(小区没代收快递点,需要快递小哥直接送到手上)
上面的代码会阻塞在ch <- i这一行代码形成死锁
因为我们使用ch := make(chan int)创建的是无缓冲的通道,无缓冲的通道只有在有人接收值的时候才能发送值。
上面的代码会阻塞在ch <- 123这一行代码形成死锁,那如何解决这个问题呢?
一种方法是启用一个goroutine去接收值,例如:
func recv(c chan int) {
ret := <-c
fmt.Println("接收成功", ret)
}
func main() {
ch := make(chan int)
go recv(ch) // 启用goroutine从通道接收值
ch <- 10
fmt.Println("发送成功")
} 无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。
有缓冲的通道
解决上面问题的方法还有一种就是使用有缓冲区的通道。
package main
import (
"fmt"
)
// func recover(ch chan int){
// rec := <- ch
// fmt.Println("接收成功",rec)
// }
func main() {
ch := make(chan int,1)
// go recover(ch)
ch <- 123
fmt.Println("传递成功......")
} 只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。(小区快递格子就一个,你取走了,别人能再放)
循环遍历管道数据
循环的话,我们就会提到for,但是for有两种循环形式
for range 和 for 用两种方式来操作
for range循环遍历管道的值 ,注意:管道没有key
package main
import "fmt"
func main() {
ch1 := make(chan int,5)
for i := 1; i <= 5; i++ {
ch1 <- i
}
for v := range ch1 {
fmt.Println(v)
}
}
我们发现虽然可以正常编译,运行,但是会出现如下情况:
1
2
3
4
5
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
main.main()
E:/goroutine_channel_demo/route_demo/main.go:14 +0xb4
exit status 2这样也会产生死锁,使用for range遍历通道,当通道被关闭的时候就会退出for range,如果没有关闭管道就会报错fatal error: all goroutines are asleep - deadlock!
如果通过for range循环的方式来从管道取数据,在插入数据的时候一定要close()
package main
import (
"fmt"
)
func main() {
var ch1 = make(chan int, 5)
for i := 1; i <= 5; i++ {
ch1 <- i
}
close(ch1) //关闭管道
//for range循环遍历管道的值 ,注意:管道没有key
for v := range ch1 {
fmt.Println(v)
}
}
通过内置的close()函数关闭channel(如果你的管道不往里存值或者取值的时候一定记得关闭管道)
第二种方法
package main
import (
"fmt"
)
func main() {
//通过for循环遍历管道的时候管道可以不关闭
var ch2 = make(chan int, 5)
for i := 1; i <= 5; i++ {
ch2 <- i
}
for j := 0; j < 5; j++ {
fmt.Println(<-ch2)
}
}并发安全和锁
有时候在Go代码中可能会存在多个goroutine同时操作一个资源(临界区),这种情况会发生竞态问题(数据竞态)。
互斥锁
package main
import (
"fmt"
"sync"
"time"
)
var count = 0
var sw sync.WaitGroup
var mutex sync.Mutex
func test() {
mutex.Lock()
count++
fmt.Println("the count is : ", count)
time.Sleep(time.Millisecond)
mutex.Unlock()
sw.Done()
}
func main() {
for r := 0; r < 20; r++ { //开启20个协程来进行这个操作
wg.Add(1)
go test()
}
sw.Wait()
}
使用互斥锁能够保证同一时间有且只有一个 goroutine 进入临界区,其他的 goroutine 则在等 待锁;当互斥锁释放后,等待的 goroutine 才可以获取锁进入临界区,多个 goroutine 同时等待一个锁时,唤醒的策略是随机的。虽然使用互斥锁能解决资源争夺问题,但是并不完美,通过全局变量加锁同步来实现通讯,并不利于多个协程对全局变量的读写操作。这个时候我们也可以通过另一种方式来实现上面的功能管道(Channel)
读写互斥锁
互斥锁是完全互斥的,但是有很多实际的场景下是读多写少的,当我们并发的去读取一个资源不涉及资源修改的时候是没有必要加锁的,这种场景下使用读写锁是更好的一种选择。
读写锁在Go语言中使用sync包中的RWMutex类型。
读写锁分为两种:读锁和写锁。当一个goroutine获取读锁之后,其他的goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;
当一个goroutine获取写锁之后,其他的goroutine无论是获取读锁还是写锁都会等待。
package main
import(
"fmt"
"sync"
"time"
)
var (
x int64
wg sync.WaitGroup
lock sync.Mutex
rwlock sync.RWMutex
)
func write() {
// lock.Lock() // 加互斥锁
rwlock.Lock() // 加写锁
x = x + 1
time.Sleep(10 * time.Millisecond) // 假设读操作耗时10毫秒
fmt.Println("=========进行写操作")
rwlock.Unlock() // 解写锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func read() {
// lock.Lock() // 加互斥锁
rwlock.RLock() // 加读锁
time.Sleep(time.Millisecond) // 假设读操作耗时1毫秒
fmt.Println("=========进行读操作")
rwlock.RUnlock() // 解读锁
// lock.Unlock() // 解互斥锁
wg.Done()
}
func main() {
for i := 0; i < 3; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 10; i++ {
wg.Add(1)
go read()
}
wg.Wait()
}
/*
*/(也就是说,当一个 goroutine 进行写操作的时候,其他 goroutine 既不能进行读操作,也不能进行写操作)
Goroutine 结合 Channel 管道
需求 1:
1 、开启一个 fn1 的的协程给向管道 inChan 中写入 100 条数据2 、开启一个 fn2 的协程读取 inChan 中写入的数据3 、注意: fn1 和 fn2 同时操作一个管道4 、主线程必须等待操作完成后才可以退出
package main
import (
"fmt"
"sync"
"time"
)
//这是一个无缓存通道案例
//定义sync等待协程完毕
var wg sync.WaitGroup
func fn1(intChan chan int) {
for i := 0; i < 10; i++ {
intChan <- i + 1
fmt.Println("写入数据=", i+1)
time.Sleep(time.Millisecond * 100)
}
close(intChan) //写入操作完毕,关闭写入的协程
wg.Done()
}
func fn2(intChan chan int) {
for v := range intChan { //通道回显只有一个值
fmt.Printf("读到数据=%v\n", v)
time.Sleep(time.Millisecond * 50)
}
wg.Done()
}
func main() {
allChan := make(chan int, 100)
wg.Add(1)
go fn1(allChan)
wg.Add(1)
go fn2(allChan)
wg.Wait()
fmt.Println("读取完毕...")
}

需求 2:
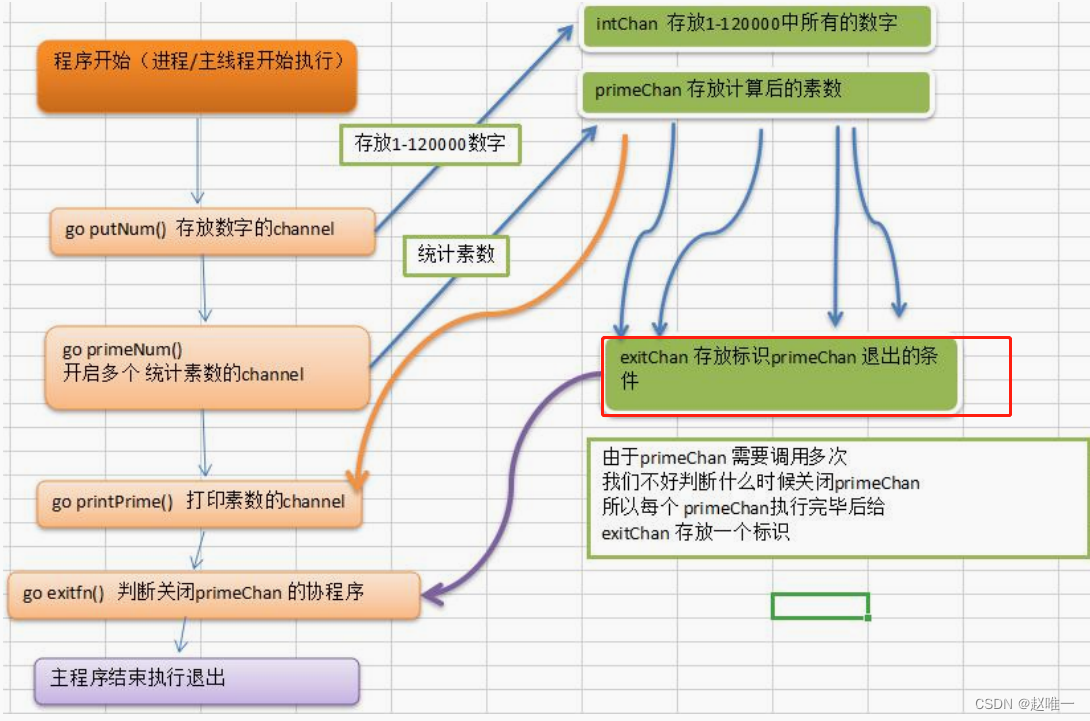
goroutine 结合 channel 实现统计 1-120 的数字中那些是素数?
package main
import(
"fmt"
"sync"
)
var sw sync.WaitGroup
//向 intChan放入 1-120个数,创建协程
func putNum(intChan chan int ){
for i := 0; i < 120; i++ {
intChan <- i
}
close(intChan)
sw.Done()
}
// 从 intChan取出数据,并判断是否为素数,如果是,就把得到的素数放在primeChan
func primeNum(intChan chan int,primeChan chan int, exitChan chan bool ){
for num := range intChan {
var flag = true
for i := 2; i < num; i++ {
if num%i == 0 {
flag = false
break
}
}
if flag {
primeChan <- num //num是素数
}
}
//要关闭 primeChan
// close(primeChan) //如果一个channel关闭了就没法给这个channel发送数据了
//什么时候关闭primeChan?
//给exitChan里面放入一条数据
exitChan <- true
sw.Done()
}
//printPrime打印素数的方法
func printPrime(primeChan chan int) {
for v := range primeChan {
fmt.Println(v)
}
sw.Done()
}
func main(){
intChan := make(chan int,1000) //在intchan中放入数字
primeChan := make(chan int,1000) //从 intChan取出数据,判断是否是素数
exitChan := make(chan bool ,20) //标识primeChan close,内部数据满足设定的缓存数量就关闭
//存放数字的协程
sw.Add(1)
go putNum(intChan)
//统计素数的协程
for i := 0; i < 20; i++ { //你要开启几个primechan的协程就写几个,对应的exitchan要一致
sw.Add(1)
go primeNum(intChan ,primeChan , exitChan )
}
//打印素数的协程
sw.Add(1)
go printPrime(primeChan)
//判断exitChan是否存满值
sw.Add(1)
go func() {
for i := 0; i < 20; i++ {
<-exitChan
}
close(primeChan) //关闭primeChan
sw.Done()
}()
sw.Wait()
fmt.Println("执行完毕....")
}单向管道
package main
import "fmt"
//单向管道
func main() {
// 1、在默认情况下下,管道是双向
ch := make(chan int, 2)
ch <- 1
ch <- 2
a := <-ch
b := <-ch
fmt.Println(a, b) //1,2
// 2、管道声明为只写
ch1 := make(chan<- int, 2)
ch1 <- 10
ch1 <- 12
// <-ch1 //receive from send-only type chan<- int
// 3、管道声明为只读
ch2 := make(<-chan int, 2)
ch2 <- 3
c := <-ch2
fmt.Println(c) //.\main.go:25:2: invalid operation: cannot send to receive-only channel ch2 (variable of type <-chan int)
}
修改之前的案例如下:
package main
import (
"fmt"
"sync"
"time"
)
//这是一个无缓存通道案例
//定义sync等待协程完毕
var wg sync.WaitGroup
func fn1(intChan chan<- int) {
for i := 0; i < 10; i++ {
intChan <- i + 1
fmt.Println("写入数据=", i+1)
time.Sleep(time.Millisecond * 100)
}
close(intChan) //写入操作完毕,关闭写入的协程
wg.Done()
}
func fn2(intChan <-chan int) {
for v := range intChan { //通道回显只有一个值
fmt.Printf("读到数据=%v\n", v)
time.Sleep(time.Millisecond * 50)
}
wg.Done()
}
func main() {
allChan := make(chan int, 100)
wg.Add(1)
go fn1(allChan)
wg.Add(1)
go fn2(allChan)
wg.Wait()
fmt.Println("读取完毕...")
}
/*
写入数据= 1
读到数据=1
写入数据= 2
读到数据=2
写入数据= 3
读到数据=3
写入数据= 4
读到数据=4
写入数据= 5
读到数据=5
写入数据= 6
读到数据=6
写入数据= 7
读到数据=7
写入数据= 8
读到数据=8
写入数据= 9
读到数据=9
写入数据= 10
读到数据=10
读取完毕...
*/
select 多路复用
在某些场景下我们需要同时从多个通道接收数据,这个时候就可以用到golang中给我们提供的select多路复用
如果只想在main方法内进行,就可以用这个方法,其他的就是定义协程了
使用select来获取channel里面的数据的时候不需要关闭channel
package main
import(
"fmt"
"time"
)
func main(){
// 在某些场景下我们需要同时从多个通道接收数据,这个时候就可以用到golang中给我们提供的select多路复用
//如果只想在main方法内进行,就可以用这个方法,其他的就是定义协程了
//1.定义一个管道 10个数据int
intoChan := make(chan int ,10)
for i := 0; i < 10; i++ {
intoChan <- i
}
//2.定义一个管道 5个数据string
stringChan := make(chan string,5)
for i := 0; i < 5; i++ {
stringChan <- "卫宫士郎"
}
//定义一个for的无限循环
for{
select{
case value := <- intoChan:
fmt.Printf("从 intChan 读取的数据%d\n", value)
case value := <-stringChan:
fmt.Printf("从 stringChan 读取的数据%v\n", value)
time.Sleep(time.Millisecond * 50)
default:
fmt.Printf("数据获取完毕")
return //注意退出...
}
}
}
/*
从 stringChan 读取的数据卫宫士郎
从 stringChan 读取的数据卫宫士郎
从 intChan 读取的数据0
从 intChan 读取的数据1
从 stringChan 读取的数据卫宫士郎
从 intChan 读取的数据2
从 intChan 读取的数据3
从 stringChan 读取的数据卫宫士郎
从 intChan 读取的数据4
从 stringChan 读取的数据卫宫士郎
从 intChan 读取的数据5
从 intChan 读取的数据6
从 intChan 读取的数据7
从 intChan 读取的数据8
从 intChan 读取的数据9
数据获取完毕
*/Goroutine Recover 解决协程中出现的 Panic
defer + recover
延迟执行(定义的func自执行函数出现问题就交给defer)其他的协程还可以继续进行
package main
import (
"fmt"
"time"
)
//函数
func test0() {
for i := 0; i < 10; i++ {
time.Sleep(time.Millisecond * 50)
fmt.Println("远坂凛")
}
}
//函数
func test1() {
//这里我们可以使用defer + recover
//延迟执行(定义的func自执行函数出现问题就交给defer)
//其他的协程还可以继续进行
defer func() {
//捕获test抛出的panic
if err := recover(); err != nil {
fmt.Println("test1() 发生错误", err)
}
}()
//定义了一个map
var myMap map[int]string
myMap[0] = "golang" //error
}
func main() {
go test0()
go test1()
//防止主进程退出这里使用time.Sleep演示,搭建也可以用sync.WaitGroup
time.Sleep(time.Second)
}
注意,调用recover()来捕获 goroutine 恐慌只在一个defer函数内部有用;否则,该函数将返回nil并且没有其他作用。这是因为defer函数也是在周围函数恐慌时执行的。
在 Go 中,panic是一个停止普通流程的内置函数:
func main() {
fmt.Println("a")
panic("foo")
fmt.Println("b")
}该代码打印a,然后在打印b之前停止:
a
panic: foo
goroutine 1 [running]:
main.main()
main.go:7 +0xb3一旦恐慌被触发,它将继续在调用栈中向上运行,直到当前的 goroutine 返回或者panic被recover捕获:
func main() {
defer func() { // ❶
if r := recover(); r != nil {
fmt.Println("recover", r)
}
}()
f() // ❷
}
func f() {
fmt.Println("a")
panic("foo")
fmt.Println("b")
}❶ 延迟闭包内调用recover
❷ 调用f,f恐慌。这种恐慌被前面的recover所抓住。
在f函数中,一旦panic被调用,就停止当前函数的执行,并向上调用栈:main。在main中,因为恐慌是由recover引起的,所以并不停止 goroutine:
a
recover foo智能推荐
没有U盘Win10电脑下如何使用本地硬盘安装Ubuntu20.04(单双硬盘都行)_没有u盘怎么装ubuntu-程序员宅基地
文章浏览阅读3.6k次,点赞2次,收藏2次。DELL7080台式机两块硬盘。_没有u盘怎么装ubuntu
【POJ 3401】Asteroids-程序员宅基地
文章浏览阅读32次。题面Bessie wants to navigate her spaceship through a dangerous asteroid field in the shape of an N x N grid (1 <= N <= 500). The grid contains K asteroids (1 <= K <= 10,000), which are conv...
工业机器视觉系统的构成与开发过程(理论篇—1)_工业机器视觉系统的构成与开发过程(理论篇—1-程序员宅基地
文章浏览阅读2.6w次,点赞21次,收藏112次。机器视觉则主要是指工业领域视觉的应用研究,例如自主机器人的视觉,用于检测和测量的视觉系统等。它通过在工业领域将图像感知、图像处理、控制理论与软件、硬件紧密结合,并研究解决图像处理和计算机视觉理论在实际应用过程中的问题,以实现高效的运动控制或各种实时操作。_工业机器视觉系统的构成与开发过程(理论篇—1
plt.legend的用法-程序员宅基地
文章浏览阅读5.9w次,点赞32次,收藏58次。legend 传奇、图例。plt.legend()的作用:在plt.plot() 定义后plt.legend() 会显示该 label 的内容,否则会报error: No handles with labels found to put in legend.plt.plot(result_price, color = 'red', label = 'Training Loss') legend作用位置:下图红圈处。..._plt.legend
深入理解 C# .NET Core 中 async await 异步编程思想_netcore async await-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏11次。深入理解 C# .NET Core 中 async await 异步编程思想引言一、什么是异步?1.1 简单实例(WatchTV并行CookCoffee)二、深入理解(异步)2.1 当我需要异步返回值时,怎么处理?2.2 充分利用异步并行的高效性async await的秘密引言很久没来CSDN了,快小半年了一直在闲置,也写不出一些带有思想和深度的文章;之前就写过一篇关于async await 的异步理解 ,现在回顾,真的不要太浅和太陋,让人不忍直视!好了,废话不再啰嗦,直入主题:一、什么是异步?_netcore async await
IntelliJ IDEA设置类注释和方法注释带作者和日期_idea作者和日期等注释-程序员宅基地
文章浏览阅读6.5w次,点赞166次,收藏309次。当我看到别人的类上面的多行注释是是这样的:这样的:这样的:好装X啊!我也想要!怎么办呢?往下瞅:跟着我左手右手一个慢动作~~~File--->Settings---->Editor---->File and Code Templates --->Includes--->File Header:之后点applay--..._idea作者和日期等注释
随便推点
发行版Linux和麒麟操作系统下netperf 网络性能测试-程序员宅基地
文章浏览阅读175次。Netperf是一种网络性能的测量工具,主要针对基于TCP或UDP的传输。Netperf根据应用的不同,可以进行不同模式的网络性能测试,即批量数据传输(bulk data transfer)模式和请求/应答(request/reponse)模式。工作原理Netperf工具以client/server方式工作。server端是netserver,用来侦听来自client端的连接,c..._netperf 麒麟
万字长文详解 Go 程序是怎样跑起来的?| CSDN 博文精选-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏3次。作者| qcrao责编 | 屠敏出品 | 程序员宅基地刚开始写这篇文章的时候,目标非常大,想要探索 Go 程序的一生:编码、编译、汇编、链接、运行、退出。它的每一步具体如何进行,力图弄清 Go 程序的这一生。在这个过程中,我又复习了一遍《程序员的自我修养》。这是一本讲编译、链接的书,非常详细,值得一看!数年前,我第一次看到这本书的书名,就非常喜欢。因为它模仿了周星驰喜剧..._go run 每次都要编译吗
C++之istringstream、ostringstream、stringstream 类详解_c++ istringstream a >> string-程序员宅基地
文章浏览阅读1.4k次,点赞4次,收藏2次。0、C++的输入输出分为三种:(1)基于控制台的I/O (2)基于文件的I/O (3)基于字符串的I/O 1、头文件[cpp] view plaincopyprint?#include 2、作用istringstream类用于执行C++风格的字符串流的输入操作。 ostringstream类用_c++ istringstream a >> string
MySQL 的 binglog、redolog、undolog-程序员宅基地
文章浏览阅读2k次,点赞3次,收藏14次。我们在每个修改的地方都记录一条对应的 redo 日志显然是不现实的,因此实现方式是用时间换空间,我们在数据库崩了之后用日志还原数据时,在执行这条日志之前,数据库应该是一个一致性状态,我们用对应的参数,执行固定的步骤,修改对应的数据。1,MySQL 就是通过 undolog 回滚日志来保证事务原子性的,在异常发生时,对已经执行的操作进行回滚,回滚日志会先于数据持久化到磁盘上(因为它记录的数据比较少,所以持久化的速度快),当用户再次启动数据库的时候,数据库能够通过查询回滚日志来回滚将之前未完成的事务。_binglog
我的第一个Chrome小插件-基于vue开发的flexbox布局CSS拷贝工具_chrome css布局插件-程序员宅基地
文章浏览阅读3k次。概述之前介绍过 移动Web开发基础-flex弹性布局(兼容写法) 里面有提到过想做一个Chrome插件,来生成flexbox布局的css代码直接拷贝出来用。最近把这个想法实现了,给大家分享下。play-flexbox插件介绍play-flexbox一秒搞定flexbox布局,可直接预览效果,拷贝CSS代码快速用于页面重构。 你也可以通过点击以下链接(codepen示例)查_chrome css布局插件
win10下安装TensorFlow-gpu的流程(包括cuda、cuDnn下载以及安装问题)-程序员宅基地
文章浏览阅读308次。我自己的配置是GeForce GTX 1660 +CUDA10.0+CUDNN7.6.0 + TensorFlow-GPU 1.14.0Win10系统安装tensorflow-gpu(按照步骤一次成功)https://blog.csdn.net/zqxdsy/article/details/103152190环境配置——win10下TensorFlow-GPU安装(GTX1660 SUPER+CUDA10+CUDNN7.4)https://blog.csdn.net/jiDxiaohuo/arti