XML基本介绍-程序员宅基地
1、什么是XML
XML是一种可扩展标记语言,它有良好的人即可读性,其基本结构,类似于我们的HTML文件,不过它的主要作用和HTML不同。
HTML文件主要用于网页的展示,而XML的作用,更注重数据的记录。还有一些Java工程的配置文件。比如我们的Java-web项目中的web.xml文件。
2、XML的基本结构
- xml第一行一般是一行申明。<?xml version=“1.0” encoding=“UTF-8”>
- xml有且仅有一个跟元素。
- xml的结构类似html文件。
- 针对特殊字符的处理,xml有两种处理方式:实体引用、CDATA标签。
一个基本的XML结构如下:
<?xml version="1.0" encoding="UTF-8"?>
<hr>
<employee>
<name>张三</name>
<age>24</age>
</employee>
<employee>
<name>李四</name>
<age>28</age>
</employee>
</hr>
特殊字符的处理:实体引用
实体引用就是当你使用特殊字符的时候(比如 > 、< 等字符),破坏了原本xml文档的基本语法结构,从而可以使用其他的特殊字符进行代替的行为。
$gt; 代表 >
$lt; 代表 <
$amp; 代表 &
$apos; 代表 ’
$quot; 代表 "
<shop-car>
<goods>
<name>Mac Pro<name>
<num>1</num>
<price>13118</price>
</goods>
<goods>
<name>Iphone X<name>
<num>4</num>
<price>8000</price>
</goods>
<info>Iphone > Mac Pro</info>
</shop-car>
特殊字符的处理:CDATA标签
基本逻辑就是,当你遇到不想被xml解析的片段,就使用CDATA标签包裹起来。
语法:<![CDATA[ 内容部分 ]]>
其中内容部分的东西,就不会被xml文档解析。
<content>
下面学习a标签的使用:
<![CDATA[
<a href="www.baidu.com">去百度</a>
]]>
</content>
这样,a标签这一段就不会被xml进行解析。
3、XML语义约束
XML文档,写的规范不规范,需要进行约束,这个约束有两种约束方式,一种是DTD、一种是XML Schema文件。
DTD(Document Type Defination)
DTD的语义约束规则如下:
- <!ELEMENT hr (employee)>,表示hr下面有一个employee节点。
- <!ELEMENT employee (name, age, salary)>,表示employee节点下面有name、age、salary三个节点。
- <!ELEMENT name (#PCDATA)>,表示name节点下的内容是文本。
- 关于节点数量的描述:+ 代表至少一个节点,* 代表至少0个节点,? 代表0个或者1个节点。
<!ELEMENT hr (employee+)>
一个DTD约束文件示例如下:
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT hr (employee+) >
<!ELEMENT employee (name,age,salary,department)>
<!ATTLIST employee no CDATA "">
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
<!ELEMENT salary (#PCDATA)>
<!ELEMENT department (dname,address)>
<!ELEMENT dname (#PCDATA)>
<!ELEMENT address (#PCDATA)>
XML Schema
- 使用schema作为xsd文件的跟节点
- 使用element来表示一个节点,它有一个name属性,表示节点名。
- complexType表示节点的类型为混合节点。
- complexType内部,使用sequence确保子节点是有序的。
- simpleType表示是一个简单类型的节点
- element的type属性,表示当前节点的文本类型的值。
<?xml version="1.0" encoding="UTF-8" ?>
<schema xmlns="http://www.w3.org/2001/XMLSchema">
<element name="hr">
<complexType>
<sequence>
<element name="employee">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age">
<simpleType>
<restriction base="integer">
<minExclusive value="18"></minExclusive>
<maxExclusive value="65"></maxExclusive>
</restriction>
</simpleType>
</element>
<element name="salary" type="integer"></element>
</sequence>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
4、xml文件的读取
使用DOM4j进行XML解析。DOM4j要求是java8以上的版本。
核心代码如下:
SAXReader reader = new SAXReader();
Document document = reader.read(path);
Element root = document.getRootElement();
List<Element> employees = root.elements("employee");
for (Element employee: employees) {
Element name = employee.element("name");
String empName = name.getText();
System.out.println(empName);
System.out.println(employee.elementText("age"));
System.out.println(employee.elementText("salary"));
Element department = employee.element("department");
System.out.println(department.element("dname").getText());
System.out.println(department.element("address").getText());
Attribute att = employee.attribute("no");
System.out.println(att.getText());
}
写入相关的API:
SAXReader reader = new SAXReader();
Document document = reader.read(path);
Element root = document.getRootElement();
Element employee = root.addElement("employee");
employee.addAttribute("no", "3311");
employee.addElement("name").setText("李铁柱");
employee.addElement("age").setText("23");
Writer writer = new OutputStreamWriter(new FileOutputStream(path) , "UTF-8");
document.write(writer);
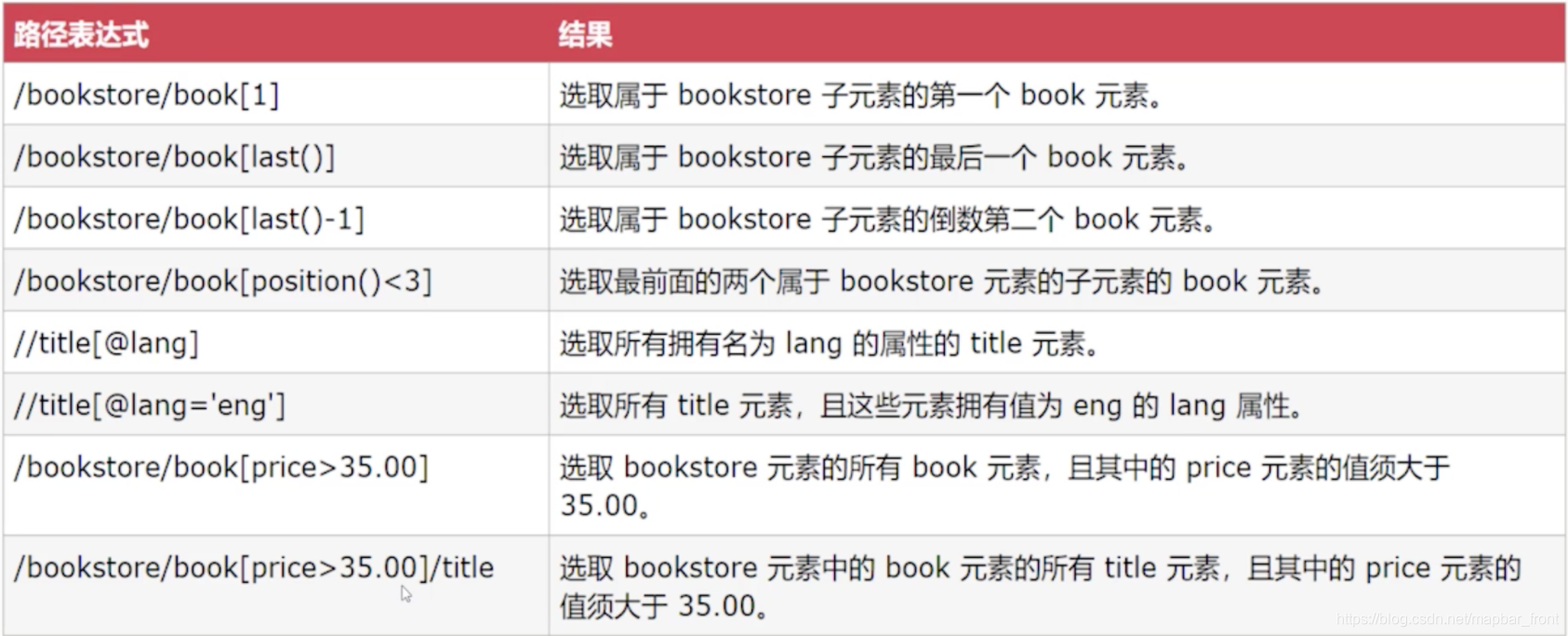
Xpath表达式
Jaxen
Jaxen是一个java编写的Xpath开源库。
Jaxen底层依赖于DOM4j
SAXReader reader = new SAXReader();
Document document = reader.read(path);
List<Node> nodes = document.selectNodes();
智能推荐
Nodejs项目部署到华为云服务器并上线超详细教程_nodejs服务器-程序员宅基地
文章浏览阅读674次,点赞26次,收藏7次。由于是第一次做Nodejs项目,发现网上关于Nodejs项目部署服务器的教程的质量参差不齐,对于初学者很不友好,看了一堆教程,最后还是不会,一头雾水,所以决定自己写一个详细教程,方便以后学习查看并记录。废话不多说,正文正式开始;_nodejs服务器
[原创]Chorme密码读取工具\Firefox密码读取工具_chorme登陆过但忘记密码-程序员宅基地
文章浏览阅读301次。工具: getBrowserPWD编译: VC作者: K8哥哥博客: http://qqhack8.blog.163.com发布: 2017/11/24 16:16:17简介: 有时为了方便我们会让浏览器保存网站登陆帐号密码浏览器密码读取工具支持(Chrome/Firefox),VC版无需.net环境GitHub上有.net界面版和python..._chorme登陆过但忘记密码
Google的十个核心技术(转)-程序员宅基地
文章浏览阅读516次。本篇将主要介绍Google的十个核心技术,而且可以分为四大类:1.分布式基础设施:GFS,Chubby和Protocol Buffer。2.分布式大规模数据处理:MapReduce和Sawzall。3.分布式数据库技术:BigTable和数据库Sharding。4.数据中心优化技术:数据中心高温化,12V电池和服务器整合。分布式基础设施GFS由于搜索引擎需要..._sole核心技术
Linux - 运行 python 脚本时报错:Matplotlib is building the font cache; this may take a moment_matplotlib is building the font cache; this may ta-程序员宅基地
文章浏览阅读1k次。缓存文件,但是删除缓存后,还是不行,不清楚具体是什么,但是第二天,脚本就可以正常运行了。_matplotlib is building the font cache; this may take a moment.
蓄水池采样_蓄水池取样-程序员宅基地
文章浏览阅读187次。蓄水池采样前言一、蓄水池抽样算法原理二、题目练习1.链表随机节点3822.随机数索引(398)总结前言给定一个数据流,数据流长度NNN非常大,且NNN直到处理完所有数据之前都不可知,要求遍历一遍就可以找到目标值。一、蓄水池抽样算法原理原理:蓄水池抽样是一系列的随机算法,其目的在于从包含 nnn个项目的集合 SSS 中选取 kkk 个样本,其中 nnn 为一很大或未知的数量,尤其适用于不能把所有 nnn 个项目都存放到内存的情况。二、题目练习1.链表随机节点382给定一个单链表,随机选择链_蓄水池取样
利用Fluent的FFT运算求得频谱的总结_fluent fft-程序员宅基地
文章浏览阅读2.8k次。利用Fluent的FFT运算求得频谱的总结先在Fluent的菜单中选取Surface-Point 在模型中选取监测点,注意:鼠标右键点击是选取监测点,也可以直接输入坐标;https://wenku.baidu.com/view/a72b321452ea551810a6874a.html..._fluent fft
随便推点
Unity与C++网络游戏开发实战:基于VR、AI与分布式架构 【1.3】_unity分布式仿真-程序员宅基地
文章浏览阅读610次,点赞18次,收藏9次。C#语言从本质上来说是在C++语言的基础上衍生出来,它是基于托管生成和指针管理的一种面向对象的编程语言。相比C++语言,它是一门更加简单、安全和易于学习的语言。它继承了C++语言强大的功能,摒弃了一些C++语言里比较复杂的使用方法,比如去掉了宏模板多重继承这些复杂的概念。C#语言借用了Visual Basic语言的可视化编程方法,基于.NET的开发库,开发了一套C#使用的可视化编程库,让C#语言,既拥有C++语言的强大能力,也更加人性化,让开发人员更加易于上手。C#语言具有以下特性:·语言简洁。_unity分布式仿真
[proxy:0:0@WORKSTATION-DEV] HYDU_sock_write (utils/sock/sock.c:256): write error (Broken pipe)_[proxy:0:1@58264c013f86] launch_procs (./pm/pmiser-程序员宅基地
文章浏览阅读2k次。[proxy:0:0@WORKSTATION-DEV] HYDU_sock_write (utils/sock/sock.c:256): write error (Broken pipe)_[proxy:0:1@58264c013f86] launch_procs (./pm/pmiserv/pmip_cb.c:648): unable t
前端性能测试工具Lighthouse_lighthouse accessibility-程序员宅基地
文章浏览阅读8k次,点赞2次,收藏23次。在前端开发中,对于自己开发的app或者web page性能的好坏,一直是让前端开发很在意的话题。我们需要专业的网站测试工具,让我们知道自己的网页还有哪些需要更为优化的方面,我自己尝试了一款工具:Lighthouse,感觉还不错,记录下来,也顺便分享给用得着的伙伴。Lighthouse分析web应用程序和web页面,收集关于开发人员最佳实践的现代性能指标和见解,让开发人员根据生成的评估页面,来进行网站优化和完善,提高用户体验..._lighthouse accessibility
统计推断结果的可视化(卡方分布,t分布,F分布)_卡方检验有办法可视化吗-程序员宅基地
文章浏览阅读290次。卡方检验是利用卡方分布来检验总体的某种假设,主要用于类别变量的推断,比图,一个类别变量的拟合优度,两个类别变量的独立性检验等。下面检验并可视化以下假设:①不同满意度的人数分布是否有显著差异。②网购次数与满意度是否独立。上图是该检验卡方统计量的概率分布,红色阴影面积为显著性水平0.05,其对应的自由度为2时的卡方分布临界值为5.991;蓝色竖线是该检验得到的统计量的位置,统计量的值为59.2.由于检验统计量远大于临界值,拒绝原假设,表示不同满意度之间的人数分布有显著差异。_卡方检验有办法可视化吗
Java 使用正则表达式匹配淘口令_淘口令正则表达式-程序员宅基地
文章浏览阅读6.8k次,点赞4次,收藏8次。项目中被正则表达式的反斜线问题坑了几次了,今天恰好用到正则表达式的匹配,又遇到饭斜线的处理,记录一下。先对比其他语言和 Java 语言中反斜线,最后再给出淘口令匹配的案例。_淘口令正则表达式
手把手教你在 CentOS7 上部署Ngrok (踩坑&填坑)-程序员宅基地
文章浏览阅读1.1k次,点赞23次,收藏16次。ngrok是一款用Golang语言打造的开源的内网穿透软件,它可以帮助我们把内网的应用提供给外网用户访问。_ngrok