可定制多目标视频生成;LLM驱动的文生图;控制视频生成中运动目标轨迹;扩散模型做全景分割;实时多功能SAM;各种分割任务统一模型_diffusiongpt: llm-driven text-to-image-程序员宅基地
技术标签: 音视频 计算机视觉 stable diffusion 深度学习 人工智能
本文首发于公众号:机器感知
可定制多目标视频生成;LLM驱动的文生图;控制视频生成中运动目标轨迹;扩散模型做全景分割;实时多功能SAM;各种分割任务统一模型
LoMA: Lossless Compressed Memory Attention

The ability to handle long texts is one of the most important capabilities of Large Language Models (LLMs), but as the text length increases, the consumption of resources also increases dramatically. At present, reducing resource consumption by compressing the KV cache is a common approach. Although there are many existing compression methods, they share a common drawback: the compression is not lossless. We propose a new method, Lossless Compressed Memory Attention (LoMA), which allows for lossless compression of information into special memory token KV pairs according to a set compression ratio.
Image Translation as Diffusion Visual Programmers
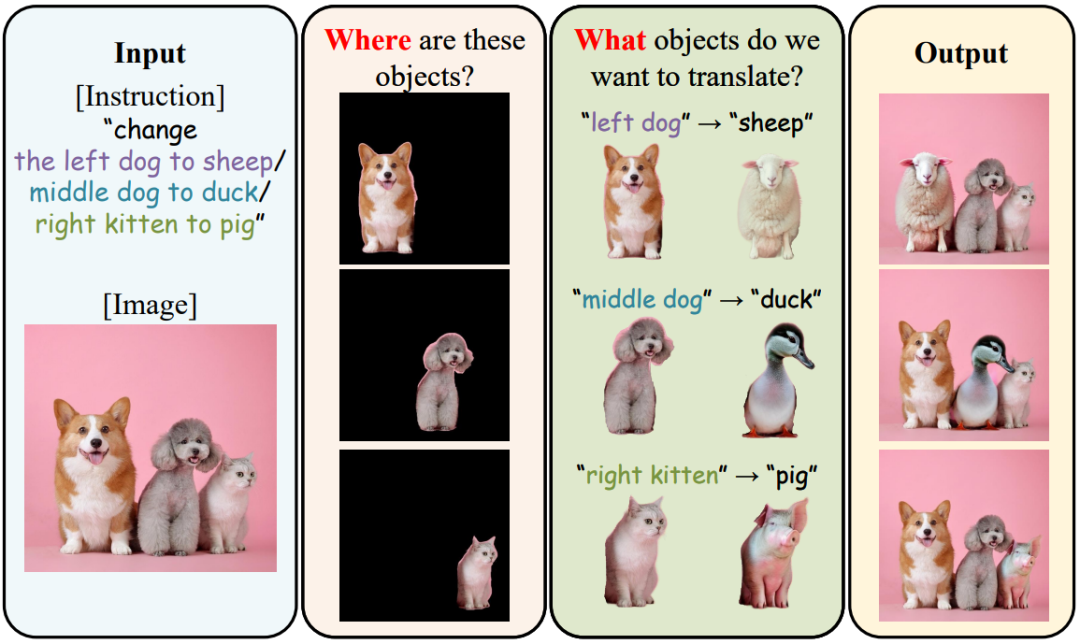
We introduce the novel Diffusion Visual Programmer (DVP), a neuro-symbolic image translation framework. Our proposed DVP seamlessly embeds a condition-flexible diffusion model within the GPT architecture, orchestrating a coherent sequence of visual programs (i.e., computer vision models) for various pro-symbolic steps, which span RoI identification, style transfer, and position manipulation, facilitating transparent and controllable image translation processes.
CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects
Customized text-to-video generation aims to generate high-quality videos guided by text prompts and subject references. Current approaches designed for single subjects suffer from tackling multiple subjects, which is a more challenging and practical scenario. In this work, we aim to promote multi-subject guided text-to-video customization. We propose CustomVideo, a novel framework that can generate identity-preserving videos with the guidance of multiple subjects. Also, we collect a multi-subject text-to-video generation dataset as a comprehensive benchmark, with 69 individual subjects and 57 meaningful pairs.
A-KIT: Adaptive Kalman-Informed Transformer

The extended Kalman filter (EKF) is a widely adopted method for sensor fusion in navigation applications. While common EKF implementation assumes a constant process noise, in real-world scenarios, the process noise varies, leading to inaccuracies in the estimated state and potentially causing the filter to diverge. To cope with such situations, we derive and introduce A-KIT, an adaptive Kalman-informed transformer to learn the varying process noise covariance online. The A-KIT outperforms the conventional EKF by more than 49.5% and model-based adaptive EKF by an average of 35.4% in terms of position accuracy.
DiffusionGPT: LLM-Driven Text-to-Image Generation System
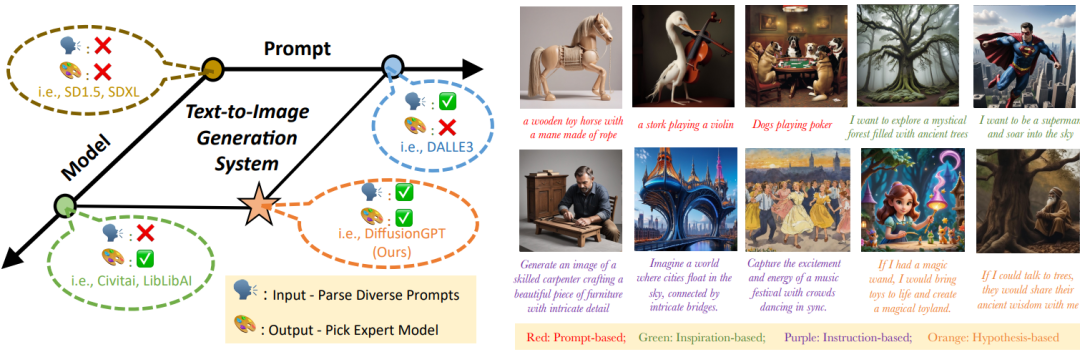
A major challenge persists in current text-to-image systems are often unable to handle diverse inputs, or are limited to single model results. Current unified attempts often fall into two orthogonal aspects: i) parse Diverse Prompts in input stage; ii) activate expert model to output. To combine the best of both worlds, we propose DiffusionGPT, which leverages Large Language Models (LLM) to offer a unified generation system capable of seamlessly accommodating various types of prompts and integrating domain-expert models. Moreover, we introduce Advantage Databases, where the Tree-of-Thought is enriched with human feedback, aligning the model selection process with human preferences.
Motion-Zero: Zero-Shot Moving Object Control Framework for Diffusion-Based Video Generation
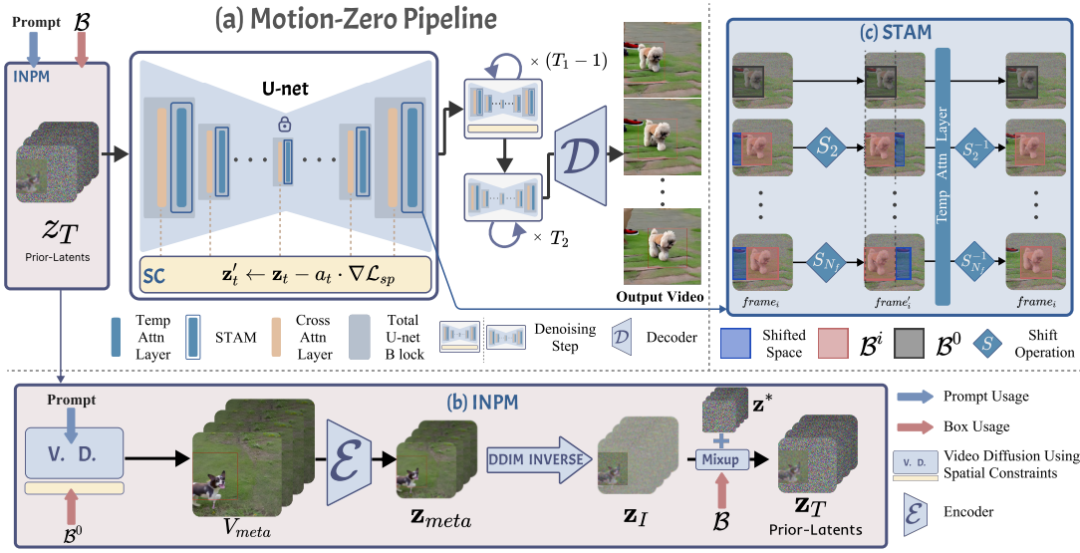
In this paper, we propose a novel zero-shot moving object trajectory control framework, Motion-Zero, to enable a bounding-box-trajectories-controlled text-to-video diffusion model.To this end, an initial noise prior module is designed to provide a position-based prior to improve the stability of the appearance of the moving object and the accuracy of position. In addition, based on the attention map of the U-net, spatial constraints are directly applied to the denoising process of diffusion models, which further ensures the positional and spatial consistency of moving objects during the inference. Furthermore, temporal consistency is guaranteed with a proposed shift temporal attention mechanism.
A Simple Latent Diffusion Approach for Panoptic Segmentation and Mask Inpainting
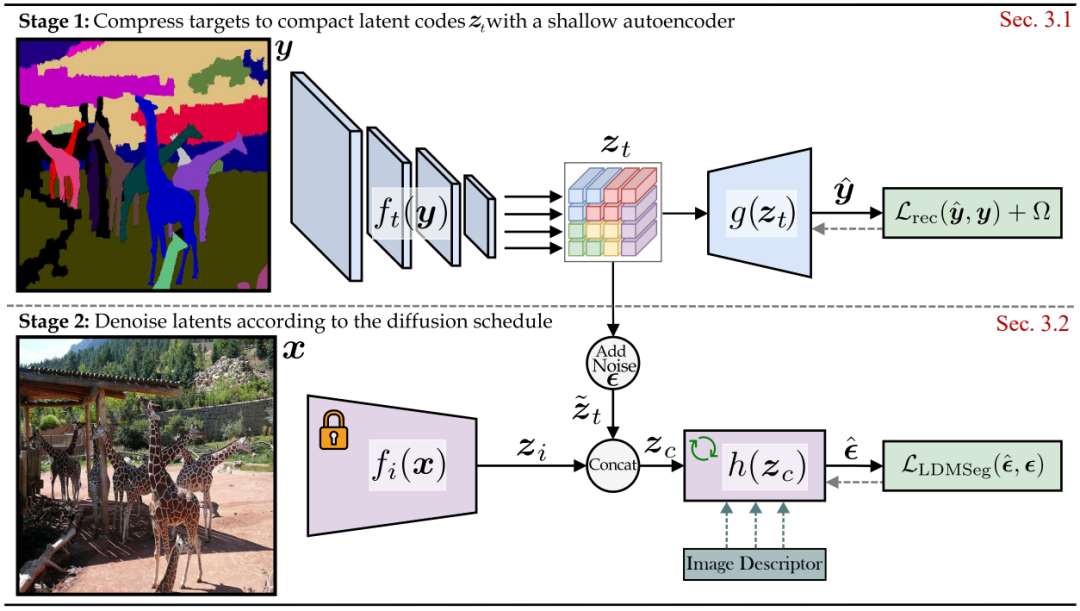
This work builds upon Stable Diffusion and proposes a latent diffusion approach for panoptic segmentation. The use of a generative model unlocks the exploration of mask completion or inpainting, which has applications in interactive segmentation. The experimental validation yields promising results for both panoptic segmentation and mask inpainting.
RAP-SAM: Towards Real-Time All-Purpose Segment Anything
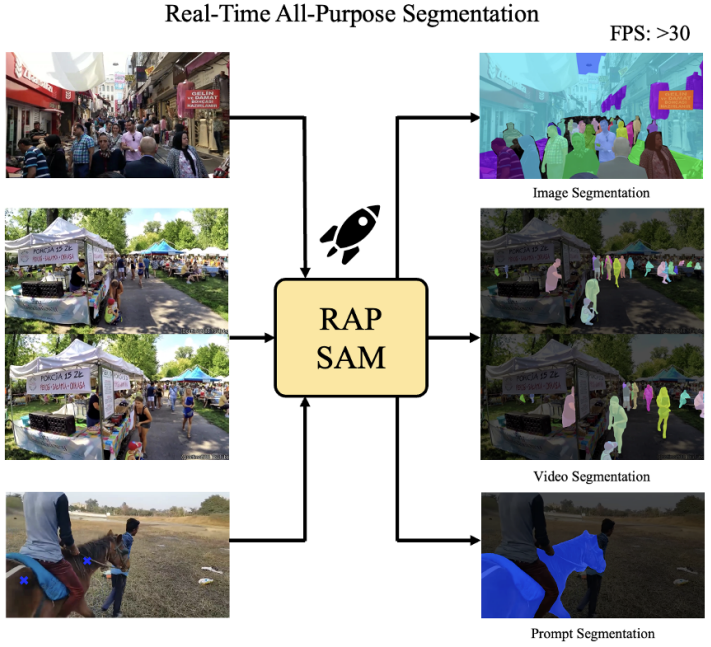
This work explores a new real-time segmentation setting, named all-purpose segmentation in real-time, to transfer VFMs in real-time deployment. It contains three different tasks, including interactive segmentation, panoptic segmentation, and video segmentation. We aim to use one model to achieve the above tasks in real-time. Then, we present Real-Time All Purpose SAM (RAP-SAM). It contains an efficient encoder and an efficient decoupled decoder to perform prompt-driven decoding.
OMG-Seg: Is One Model Good Enough For All Segmentation?
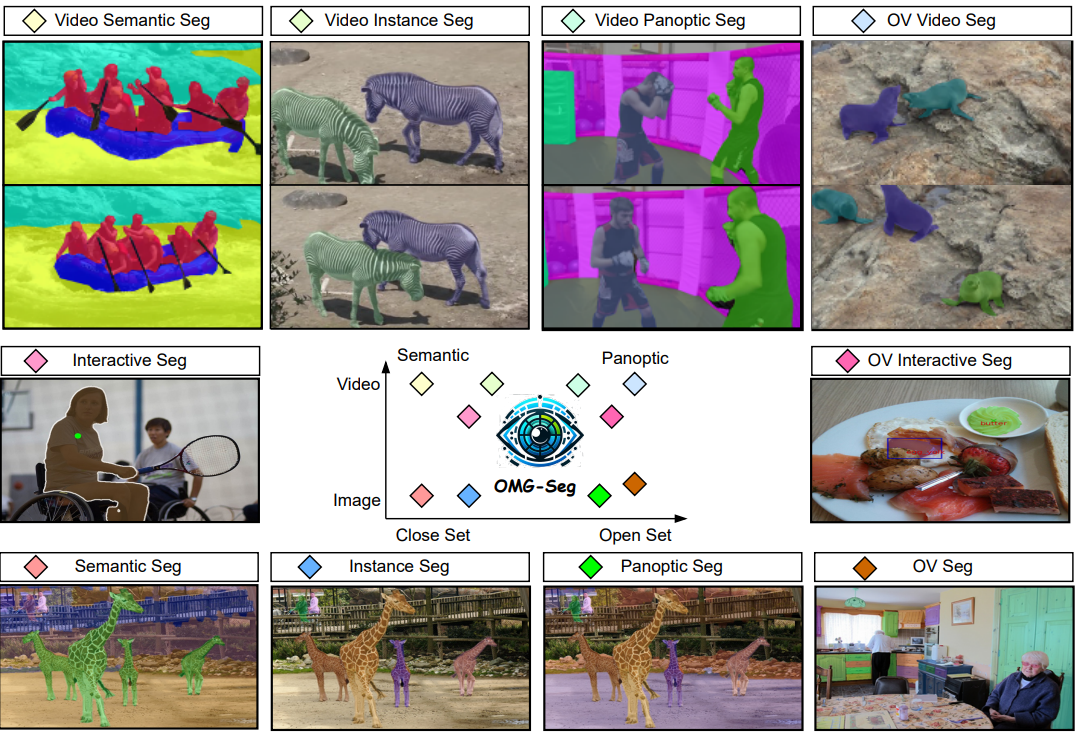
In this work, we address various segmentation tasks, each traditionally tackled by distinct or partially unified models. We propose OMG-Seg, One Model that is Good enough to efficiently and effectively handle all the segmentation tasks, including image semantic, instance, and panoptic segmentation, as well as their video counterparts, open vocabulary settings, prompt-driven, interactive segmentation like SAM, and video object segmentation. To our knowledge, this is the first model to handle all these tasks in one model and achieve satisfactory performance.
FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder
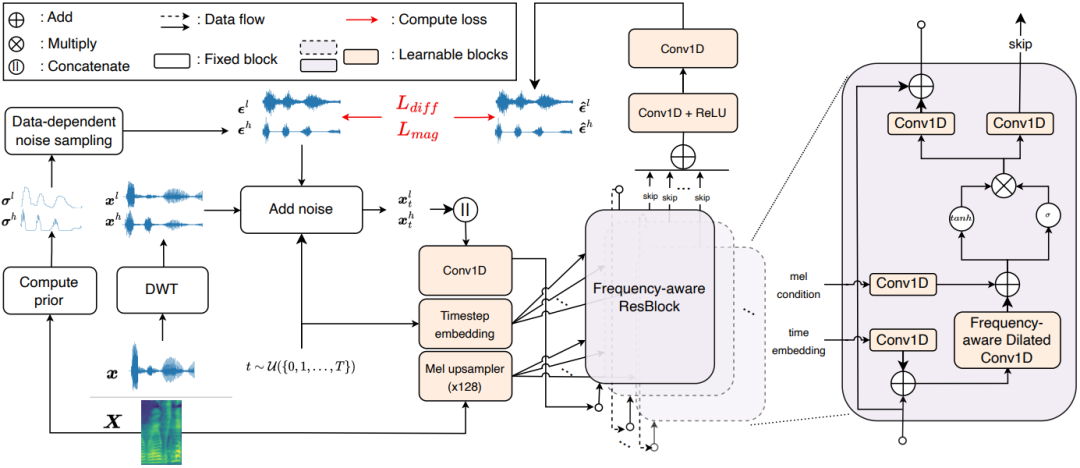
The goal of this paper is to generate realistic audio with a lightweight and fast diffusion-based vocoder, named FreGrad. In our experiments, FreGrad achieves 3.7 times faster training time and 2.2 times faster inference speed compared to our baseline while reducing the model size by 0.6 times (only 1.78M parameters) without sacrificing the output quality.
智能推荐
http隧道 java_使用java语言实现http隧道技术-程序员宅基地
文章浏览阅读119次。该楼层疑似违规已被系统折叠隐藏此楼查看此楼/***Getaparametervalue**@paramkeyString*@paramdefString*@returnString*/publicStringgetParameter(Stringkey,Stringdef){returnisStandalone?System.getProperty(ke..._java http隧道
Keepalived高可用+邮件告警_keepalived sendmail-程序员宅基地
文章浏览阅读913次。IP主机名备注192.168.117.14keepalived-master主节点192.168.117.15keepalived-slaver备节点192.168.117.100VIP1.主备节点均安装keepalived# yum install -y keepalived httpd2.主备节点均修改keepalived日志存放路径..._keepalived sendmail
SPFILE 错误导致数据库无法启动(ORA-01565)_ora01565 ora27046-程序员宅基地
文章浏览阅读469次。--==========================================--SPFILE错误导致数据库无法启动(ORA-01565)--========================================== SPFILE错误导致数据库无法启动 SQL> startup ORA-01078: failurein proce_ora01565 ora27046
功能测试基础知识(1)-程序员宅基地
文章浏览阅读6.1k次,点赞2次,收藏54次。功能测试基础知识总结_功能测试
postgresql 中文排序_pg中文排序-程序员宅基地
文章浏览阅读3.2k次,点赞3次,收藏2次。pg 中文首字母排序_pg中文排序
[Mysql] CONVERT函数_mysql convert-程序员宅基地
文章浏览阅读3.1w次,点赞23次,收藏109次。本文主要讲解CONVERT函数_mysql convert
随便推点
HTML5与微信开发(2)-视频播放事件及API属性_微信开发者工具视频快进-程序员宅基地
文章浏览阅读8.6k次,点赞2次,收藏2次。HTML5 的视频播放事件想必大家已经期待很久了吧,在HTML4.1、4.0之前我们如果在网页上播放视频无外乎两种方法: 第一种:安装FLASH插件或者微软发布的插件 第二种:在本地安装播放器,在线播放组件之类的 因为并不是所有的浏览器都安装了FLASH插件,就算安装也不一定所有的都能安装成功。像苹果系统就是默认禁用FLASH的,安卓虽然一开始的时候支持FLASH,但是在安卓4.0以后也开始不_微信开发者工具视频快进
JedisConnectionException Connection Reset_jedisconnectionexception: java.net.socketexception-程序员宅基地
文章浏览阅读5.4k次,点赞3次,收藏4次。在使用redis的过程常见错误总结1.JedisConnectionException Connection Reset参考这边文章:Connection reset原因分析和解决方案https://blog.csdn.net/cwclw/article/details/527971311.1问题描述Exception in thread "main" redis.clients...._jedisconnectionexception: java.net.socketexception: connection reset
Lua5.3版GC机制理解_lua5.3 gc-程序员宅基地
文章浏览阅读8.3k次,点赞8次,收藏42次。目录1.Lua垃圾回收算法原理简述2.Lua垃圾回收中的三种颜色3.Lua垃圾回收详细过程4.步骤源码详解4.1新建对象阶段4.2触发条件4.3 GC函数状态机4.4标记阶段4.5清除阶段5.总结参考资料lua垃圾回收(Garbage Collect)是lua中一个比较重要的部分。由于lua源码版本变迁,目前大多数有关这个方面的文章都还是基于lua5.1版本,有一定的滞后性。因此本文通过参考当前..._lua5.3 gc
手机能打开的表白代码_能远程打开,各种手机电脑进行监控操作,最新黑科技...-程序员宅基地
文章浏览阅读511次。最近家中的潮人,老妈闲着没事干,开始学玩电脑,引起他的各种好奇心。如看看新闻,上上微信或做做其他的事情。但意料之中的是电脑上会莫名出现各种问题?不翼而飞的图标?照片又不见了?文件被删了,卡机或者黑屏,无声音了,等等问题。常常让她束手无策,求助于我,可惜在电话中说不清,往往只能苦等我回家后才能解决,那种开心乐趣一下子消失了。想想,这样也不是办法啊, 于是,我潜心寻找了两款优秀的远程控制软件。两款软件...
成功Ubuntu18.04 ROS melodic安装Cartograhper+Ceres1.13.0,以及错误总结_ros18.04 安装ca-程序员宅基地
文章浏览阅读1.8k次。二.初始化工作空间三.设置下载地址四.下载功能包此处可能会报错,请看:rosdep update遇到ERROR: error loading sources list: The read operation timed out问题_DD᭄ꦿng的博客-程序员宅基地接下来一次安装所有功能包,注意对应ROS版本 五.编译功能包isolated:单独编译各个功能包,每个功能包之间不产生依赖。编译过程时间比较长,可能需要几分钟时间。此处可能会报错:缺少absl依赖包_ros18.04 安装ca
Harbor2.2.1配置(trivy扫描器、镜像签名)_init error: db error: failed to download vulnerabi-程序员宅基地
文章浏览阅读4.1k次,点赞3次,收藏7次。Haobor2.2.1配置(trivy扫描器、镜像签名)docker-compose下载https://github.com/docker/compose/releases安装cp docker-compose /usr/local/binchmod +x /usr/local/bin/docker-composeharbor下载https://github.com/goharbor/harbor/releases解压tar xf xxx.tgx配置harbor根下建立:mkd_init error: db error: failed to download vulnerability db: database download