MapReduce实现分组排序_mapreduce 分组排序-程序员宅基地
技术标签: TopK Group mapreduce 分组 -- 数据专题-数据工具 Sort
MapReduce实现分组排序
以某次竞赛为例,分别进行如果实现:
- 取每组中男生前三名成绩和女生前三名成绩
- 按照年龄分组降序输出所有人的成绩
- 等价的SQL
- 在map和reduce阶段进行排序,比较的是k2。v2是不参与排序比较的。如果想让v2也进行排序,需要把k2和v2组装成新的类,作为k2,才能参与比较。
- 分组时也是按照k2进行比较的。
jangz 23 male 98
John 34 male 100
Tom 45 male 99
Lily 32 female 40
Linda 34 female 100
Chaces 28 male 98
Dong 29 male 30
Daniel 33 male 100
Marvin 24 male 100
Chaos 30 female 84
Mei 23 female 90
Newhire 18 female 100
Summer 59 male 90package mapreduce.topk2.top;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class Document implements WritableComparable<Document> {
private String name;
private Integer age;
private String gender;
private Integer score;
public Document() {
}
public Document(String name, Integer age, String gender, Integer score) {
this.name = name;
this.age = age;
this.gender = gender;
this.score = score;
}
public void set(String name, Integer age, String gender, Integer score) {
this.name = name;
this.age = age;
this.gender = gender;
this.score = score;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(age);
out.writeUTF(gender);
out.writeInt(score);
}
@Override
public void readFields(DataInput in) throws IOException {
this.name = in.readUTF();
this.age = in.readInt();
this.gender = in.readUTF();
this.score = in.readInt();
}
@Override
public int compareTo(Document o) {
if (this.score != o.score) {
return -this.score.compareTo(o.score);
} else {
return this.name.compareTo(o.name);
}
}
@Override
public String toString() {
return name + "\t" + age + "\t" + gender + "\t" + score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public Integer getScore() {
return score;
}
public void setScore(Integer score) {
this.score = score;
}
}取每组中男生前三名成绩和女生前三名成绩:
package mapreduce.topk2.top;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.log4j.Logger;
public class Top3GroupByGenderExample extends Configured implements Tool {
private static final Logger log = Logger.getLogger(Top3GroupByGenderExample.class);
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
log.error("Usage: Top3GroupByGenderExample <in> <out>");
System.exit(2);
}
ToolRunner.run(conf, new Top3GroupByGenderExample(), otherArgs);
}
@Override
public int run(String[] args) throws Exception {
FileSystem fs = FileSystem.get(getConf());
Path outPath = new Path(args[1]);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
Job job = Job.getInstance(getConf(), "Top3GroupByGenderExampleJob");
job.setJarByClass(Top3GroupByGenderExample.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Document.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(2);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Document.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, outPath);
return job.waitForCompletion(true) ? 0 : 1;
}
public static class MyMapper extends Mapper<LongWritable, Text, Document, NullWritable> {
private Document document = new Document();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
log.info("MyMapper in<" + key.get() + "," + value.toString() + ">");
String line = value.toString();
String[] infos = line.split("\t");
String name = infos[0];
Integer age = Integer.parseInt(infos[1]);
String gender = infos[2];
Integer score = Integer.parseInt(infos[3]);
document.set(name, age, gender, score);
context.write(document, NullWritable.get());
log.info("MyMapper out<" + document + ">");
}
}
public static class MyPartitioner extends Partitioner<Document, NullWritable> {
@Override
public int getPartition(Document key, NullWritable value, int numPartitions) {
String gender = key.getGender();
return (gender.hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
public static class MyReducer extends Reducer<Document, NullWritable, Document, NullWritable> {
private int k = 3;
private int counter = 0;
@Override
protected void reduce(Document key, Iterable<NullWritable> v2s, Context context)
throws IOException, InterruptedException {
log.info("MyReducer in<" + key + ">");
if (counter < k) {
context.write(key, NullWritable.get());
counter += 1;
log.info("MyReducer out<" + key + ">");
}
}
}
}

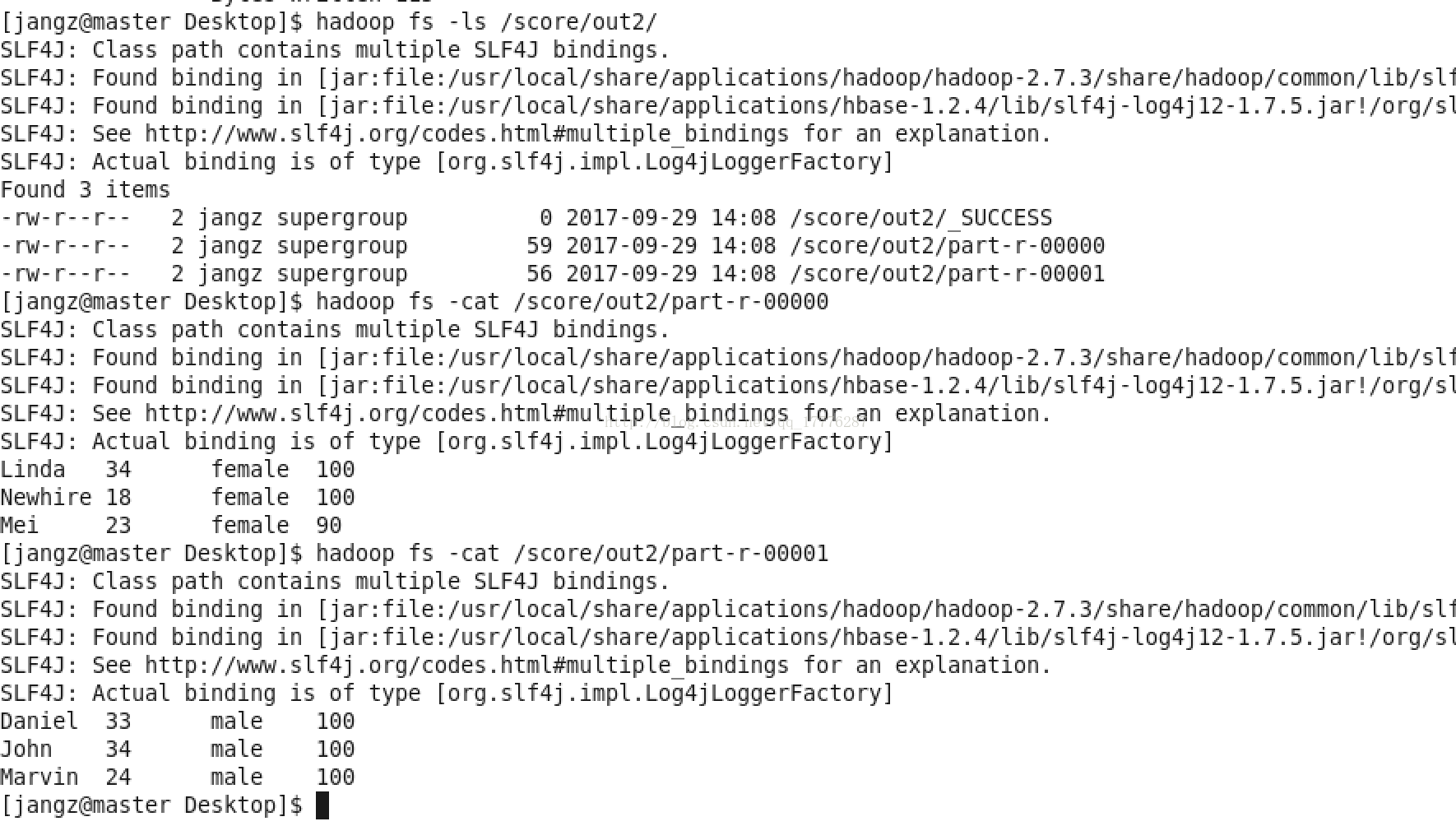
2. 按照年龄分组降序输出所有人的成绩
package mapreduce.topk2.groupsort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class Person implements WritableComparable<Person> {
private String name;
private Integer age;
private String gender;
private Integer score;
public Person() {
}
public Person(String name, Integer age, String gender, Integer score) {
this.name = name;
this.age = age;
this.gender = gender;
this.score = score;
}
public void set(String name, Integer age, String gender, Integer score) {
this.name = name;
this.age = age;
this.gender = gender;
this.score = score;
}
@Override
public String toString() {
return name + "\t" + age + "\t" + gender + "\t" + score;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(age);
out.writeUTF(gender);
out.writeInt(score);
}
@Override
public void readFields(DataInput in) throws IOException {
this.name = in.readUTF();
this.age = in.readInt();
this.gender = in.readUTF();
this.score = in.readInt();
}
/**
* Sort by score desc.
*/
@Override
public int compareTo(Person o) {
return -this.score.compareTo(o.score);
}
public String getName() {
return name;
}
public Integer getAge() {
return age;
}
public String getGender() {
return gender;
}
public Integer getScore() {
return score;
}
}
实现按年龄分组降序输出所有人的成绩:
package mapreduce.topk2.groupsort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* <p>Title: GroupByAgeDescScoreExample</p>
* <p>Description: </p>
* @author jangz
* @date 2017/9/29 14:14
*/
public class GroupByAgeDescScoreExample extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.out.println("Usage: GroupByAgeDescScoreExample <in> <out>");
System.exit(2);
}
ToolRunner.run(conf, new GroupByAgeDescScoreExample(), otherArgs);
}
@Override
public int run(String[] args) throws Exception {
FileSystem fs = FileSystem.get(getConf());
Path outPath = new Path(args[1]);
if (fs.exists(outPath)) {
fs.delete(outPath, true);
}
Job job = Job.getInstance(getConf(), "GroupByAgeDescScoreExampleJob");
job.setJarByClass(GroupByAgeDescScoreExample.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Person.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(3);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, outPath);
return job.waitForCompletion(true) ? 0 : 1;
}
public static class MyMapper extends Mapper<LongWritable, Text, Person, NullWritable> {
private Person person = new Person();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("MyMapper in<" + key.get() + "," + value.toString() + ">");
String line = value.toString();
String[] infos = line.split("\t");
String name = infos[0];
Integer age = Integer.parseInt(infos[1]);
String gender = infos[2];
Integer score = Integer.parseInt(infos[3]);
person.set(name, age, gender, score);
context.write(person, NullWritable.get());
System.out.println("MyMapper out<" + person + ">");
}
}
public static class MyPartitioner extends Partitioner<Person, NullWritable> {
@Override
public int getPartition(Person key, NullWritable value, int numPartitions) {
Integer age = key.getAge();
if (age < 20) {
return 0;
} else if (age <= 50) {
return 1;
} else {
return 2;
}
}
}
public static class MyReducer extends Reducer<Person, NullWritable, Person, NullWritable> {
private Text k = new Text();
@Override
protected void reduce(Person key, Iterable<NullWritable> v2s, Context context)
throws IOException, InterruptedException {
System.out.println("MyReducer in<" + key + ">");
context.write(key, NullWritable.get());
System.out.println("MyReducer out<" + k + "," + key + ">");
}
}
}
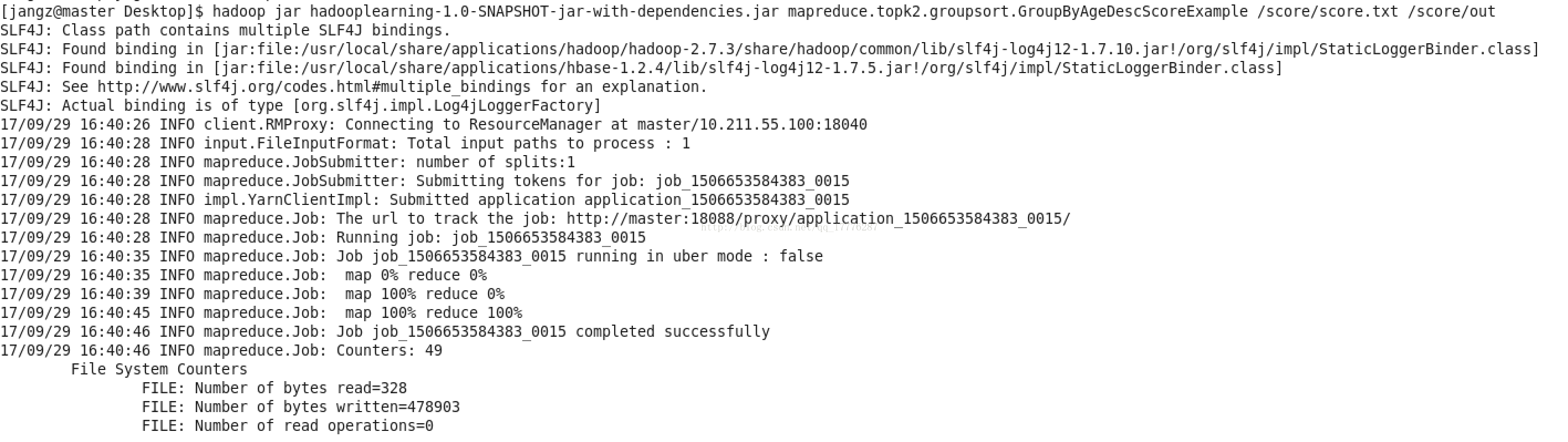
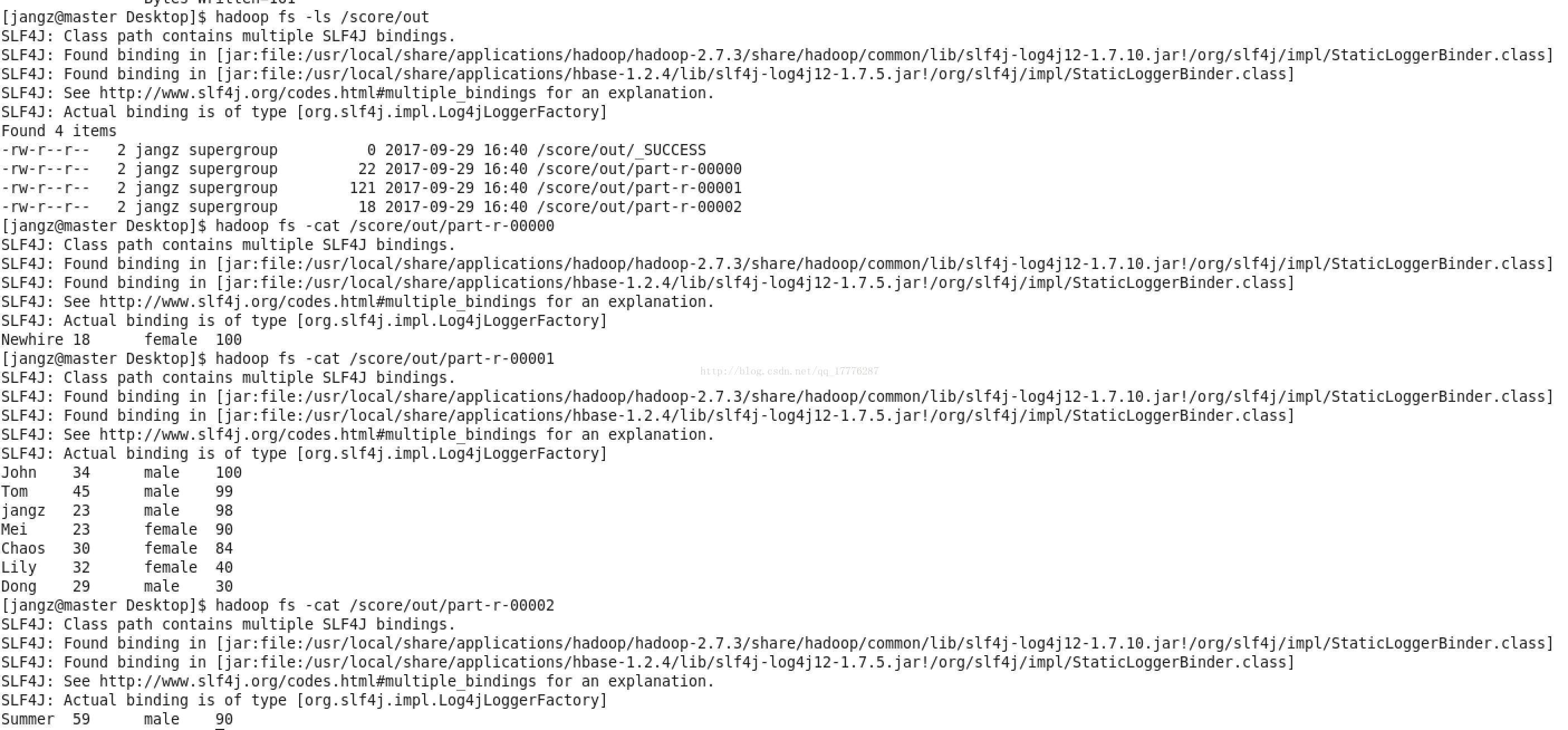
CREATE TABLE score (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
age INT,
gender VARCHAR(10),
score INT
);
INSERT INTO score(name, age, gender, score)
VALUES('jangz', 23, 'male', 98),
('John', 34, 'male', 100),
('Tom', 45, 'male', 99),
('Lily', 32, 'female', 40),
('Linda', 34, 'female', 100),
('Chaces', 28, 'male', 98),
('Dong', 29, 'male', 30),
('Daniel', 33, 'male', 100),
('Marvin', 24, 'male', 100),
('Chaos', 30, 'female', 84),
('Mei', 23, 'female', 90),
('Newhire', 18, 'female', 100),
('Summer', 59, 'male', 90);(SELECT name, age, gender, score
FROM score
WHERE gender='female'
ORDER BY gender, score DESC, name
LIMIT 3)
UNION ALL
(SELECT name, age, gender, score
FROM score
WHERE gender='male'
ORDER BY gender, score DESC, name
LIMIT 3);SELECT name, age, gender, score
FROM score
GROUP BY age
ORDER BY score DESC, nameSummary
1. 在map和reduce阶段进行排序,比较的是k2,v2不参与排序比较。(map和reduce阶段都有partition、sort、combine操作)。
2. 为了数据操作方便,我们可以自定义Bean,并让其实现WritableComparable接口,重写write、readFields和compareTo方法,当然,一定要记得重写toString方法,不然reduce最终输出的结果会达不到预期。
3. 针对非同类数据进行分组,比如按照年龄段,那么我们可以采用分区的形式实现分组。
但是针对同类数据进行分组,比如ip(长度是固定的)和出现次数组合键k2,我们可以采用GroupingComparator。
4. MapReduce是什么?MapReduce是一个运行在大规模集群上,能够可靠且容错地并行处理海量数据集的软件框架。
针对代码,大家也可以到博主的GitHub仓库进行下载,自己打包运行。博主设计,仅供参考!
智能推荐
c语言utf8编码汉字截取,C语言 获取汉字unicode和utf-8编码-程序员宅基地
文章浏览阅读845次。就VC而言,汉字储存一般都是以国标码形式存放在电脑上的,要想查询一个汉字的unicode编码,可以在一个字符串前面加一个‘L,也相当于让该汉字以unicode编码形式存放。unicode编码与utf-8编码之间的关系是什么,其实两者之间,个人感觉,utf-8编码是unicode编码的具体实现。两者之间的对应关系如下所示,可以看到。当一个字符的unicode编码在0x0000 0000~0000 0..._c语言 utf-8 提取汉字
华为公司经典设计规范合集_华为硬件开发文档编制规范下载-程序员宅基地
文章浏览阅读667次。EMC、编程语言、PCBlayout、高速电路方面、FPGA方面、硬件基本知识、射频方面、无线通信方面、经典原理图、模拟电路......_华为硬件开发文档编制规范下载
编译原理-语法制导翻译、后缀表达式、三元、四元_三元式-程序员宅基地
文章浏览阅读5.5k次,点赞8次,收藏28次。此时的每条规则后面会对应一条语义动作,即制导翻译。一、中间语言中间语言就是和源程序等价的一种编码方式,复杂性也是介于源程序和机器语言中间。_三元式
vue 可折叠面板的工作区组件_vue-collapsible-panel-程序员宅基地
文章浏览阅读2.1k次。这个组件中使用了elementui的两个图标组件Js:/**工作区组件调用示例:<work-container v-bind:height="80"> <template v-slot:tbar> 查询表单 </template> <template v-slot:work&..._vue-collapsible-panel
stanford 课程表_斯坦福大学法律课表-程序员宅基地
文章浏览阅读4.5k次。https://exploredegrees.stanford.edu/coursedescriptions/cs/CS 101. Introduction to Computing Principles. 3-5 Units.Introduces the essential ideas of computing: data representation, algorithms, prog..._斯坦福大学法律课表
在 WebStorm/PhpStorm 中开启对 Vue.js 的完美支持_phpstorm vue 高亮-程序员宅基地
文章浏览阅读1.4w次。最近的一个前后端分离项目开始使用 Vue.js 进行开发,就顺便优化了一下 PhpStorm 下的开发体验(PhpStorm 版本为 2017.1)。注:在最新的 2017.1 版本中,PhpStorm(WebStorm)已经对 Vue.js 进行了原生支持,所以不需要装第三方插件了。安装 Vue.js 插件PhpStorm 目前的版本还没有对 Vue.js 进行原_phpstorm vue 高亮
随便推点
pandas 创建空csv并且插入和修改数据_python pandas 创建空白csv-程序员宅基地
文章浏览阅读505次。【代码】pandas 创建空csv并且插入和修改数据。_python pandas 创建空白csv
SFTP服务配置以及命令/代码操作-程序员宅基地
文章浏览阅读590次。一、SFTP简述 二、SFTP服务配置(基于CentOS 7) 三、SFTP常用命令 四、Java代码实现SFTP操作(JSch实现上传、下载、监视器) 源码请见Github:https://github.com/qiezhichao/CodeHelper/tree/mast..._sys_sftpconfig
redis.exceptions.ConnectionError: Error 10061 connecting to localhost:6379. 由于目标计算机积极拒绝,无法连接-程序员宅基地
文章浏览阅读7.1k次,点赞3次,收藏15次。我用的是window的首先我打开是用cmd命令窗口开的然后出现了这个 redis.exceptions.ConnectionError: Error 10061 connecting to localhost:6379. 由于目标计算机积极拒绝,无法链接的这个报错解决办法第一步,使用管理员身份打开你的cmd命令窗口第二步 使用cd命令打开您的redis目录如下图第三步 输入 指令 redis-server.exe redis.windows.conf然后出现下图这样然后再次用管理员身份_redis.exceptions.connectionerror: error 10061 connecting to localhost:6379.
private的访问权限-程序员宅基地
文章浏览阅读3k次,点赞3次,收藏7次。非常基础的概念问题第一:private, public, protected 访问标号的访问范围。 private :只能由1.该类中的函数、2.其友元函数访问。不能被任何其他访问,该类的对象也不能访问。protected :可以被1.该类中的函数、2.子类的函数、以及3.其友元函数访问。但不能被该类的对象访问。public :可以被1.该类中的..._private访问权限
bash脚本小技巧之一:set -e和set -u-程序员宅基地
文章浏览阅读3.8k次,点赞4次,收藏10次。2019独角兽企业重金招聘Python工程师标准>>> ..._set -e -u
用DIV+CSS技术设计的明星个人网站制作(基于HTML+CSS+JavaScript制作明星彭于晏网页)-程序员宅基地
文章浏览阅读432次。个人网页设计、♂️个人简历制作、简单静态HTML个人网页作品、个人介绍网站模板 、等网站的设计与制作。个人网页设计网站模板采用DIV CSS布局制作,网页作品有多个页面,如 :个人介绍(文字页面)、我的作品(图片列表)、个人技能(图文页面)、在线留言(表单页面)CSS样式方面网页整体采用左右布局结构,制作了网页背景图片,导航区域每个导航背景色不同,导航背景色与页面背景呼应。 一套A+的网页应该包含 (具体可根据个人要求而定)网站布局方面:计划采用目前主流的、能兼容各大