MyBatis缓存机制流程分析-程序员宅基地
技术标签: java mybatis 缓存 # MyBatis
前言
在进行分析之前,建议快速浏览之前写的理解MyBatis原理、思想,这样更容易阅读、理解本篇内容。
验证一级缓存
MyBatis的缓存有两级,一级缓存默认开启,二级缓存需要手动开启。
重复读取跑缓存
可以看到,第二次请求的时候,没有打印SQL,而是使用了缓存。
@Test
public void test1() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession1 = sqlSessionFactory.openSession(true);
SysRoleMapper mapper1 = sqlSession1.getMapper(SysRoleMapper.class);
SysRole role = mapper1.getById(2);
SysRole role2 = mapper1.getById(2);
System.out.println(role);
System.out.println(role2);
}
//------------------------------打印SQL--------------------------------------
==> Preparing: select * from sys_role where role_id = ?
==> Parameters: 2(Integer)
<== Columns: role_id, role_name, role_key, role_sort, data_scope, status, del_flag, create_by, create_time, update_by, update_time, remark
<== Row: 2, 测试2, common, 2, 2, 0, 0, admin, 2022-08-29 15:58:05, , null, 普通角色
<== Total: 1
SysRole{
role_id=2, role_name='测试2'}
SysRole{
role_id=2, role_name='测试2'}
同一会话的更新操作刷新缓存
通过测试结果可以看到,因为更新操作的原因,两次查询都查了数据库。
@Test
public void test2() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession1 = sqlSessionFactory.openSession(true);
SysRoleMapper mapper1 = sqlSession1.getMapper(SysRoleMapper.class);
SysRole role = mapper1.getById(2);
mapper1.updateRoleNameById("测", 2);
SysRole role2 = mapper1.getById(2);
System.out.println(role);
System.out.println(role2);
}
//------------------------------打印SQL--------------------------------------
==> Preparing: select * from sys_role where role_id = ?
==> Parameters: 2(Integer)
<== Columns: role_id, role_name, role_key, role_sort, data_scope, status, del_flag, create_by, create_time, update_by, update_time, remark
<== Row: 2, 测试2, common, 2, 2, 0, 0, admin, 2022-08-29 15:58:05, , null, 普通角色
<== Total: 1
==> Preparing: update sys_role set role_name = ? where role_id = ?
==> Parameters: 测(String), 2(Integer)
<== Updates: 1
==> Preparing: select * from sys_role where role_id = ?
==> Parameters: 2(Integer)
<== Columns: role_id, role_name, role_key, role_sort, data_scope, status, del_flag, create_by, create_time, update_by, update_time, remark
<== Row: 2, 测, common, 2, 2, 0, 0, admin, 2022-08-29 15:58:05, , null, 普通角色
<== Total: 1
SysRole{
role_id=2, role_name='测试2'}
SysRole{
role_id=2, role_name='测'}
跨会话更新数据没有刷新缓存
@Test
public void test() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
// 会话一
System.out.println("会话一");
SqlSession sqlSession1 = sqlSessionFactory.openSession(true);
SysRoleMapper mapper1 = sqlSession1.getMapper(SysRoleMapper.class);
SysRole role = mapper1.getById(2);
System.out.println(role);
// 会话二
System.out.println("会话二");
SqlSession sqlSession2 = sqlSessionFactory.openSession(true);
SysRoleMapper mapper2 = sqlSession2.getMapper(SysRoleMapper.class);
mapper2.updateRoleNameById("测试2", 2);
System.out.println(mapper2.getById(2));
// 会话一重新查询
System.out.println("会话一重新查询");
role = mapper1.getById(2);
System.out.println(role);
}
//------------------------------打印结果--------------------------------------
会话一
SysRole{
role_id=2, role_name='测试'}
会话二
SysRole{
role_id=2, role_name='测试2'}
会话一重新查询
SysRole{
role_id=2, role_name='测试'}
源码分析的入口点
我们要阅读、分析源码,就需要先找准一个切入点,我们以下面代码为例子,SysRoleMapper#getById()方法作为调试入口:
@Test
public void test1() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession1 = sqlSessionFactory.openSession(true);
SysRoleMapper mapper1 = sqlSession1.getMapper(SysRoleMapper.class);
// 调试入口
SysRole role = mapper1.getById(2);
SysRole role2 = mapper1.getById(2);
System.out.println(role);
System.out.println(role2);
}
在分析之前,我们就先约定一下:符号表示你的视角要焦距在哪几行代码。
一级缓存流程分析
好,现在我们开始分析一级缓存的流程,了解其设计思想,看看能学到什么。
MapperProxy
- 首先,我们可以看到,通过
getMapper方法拿到的对象mapper1,其实是一个代理对象MapperProxy的实例。
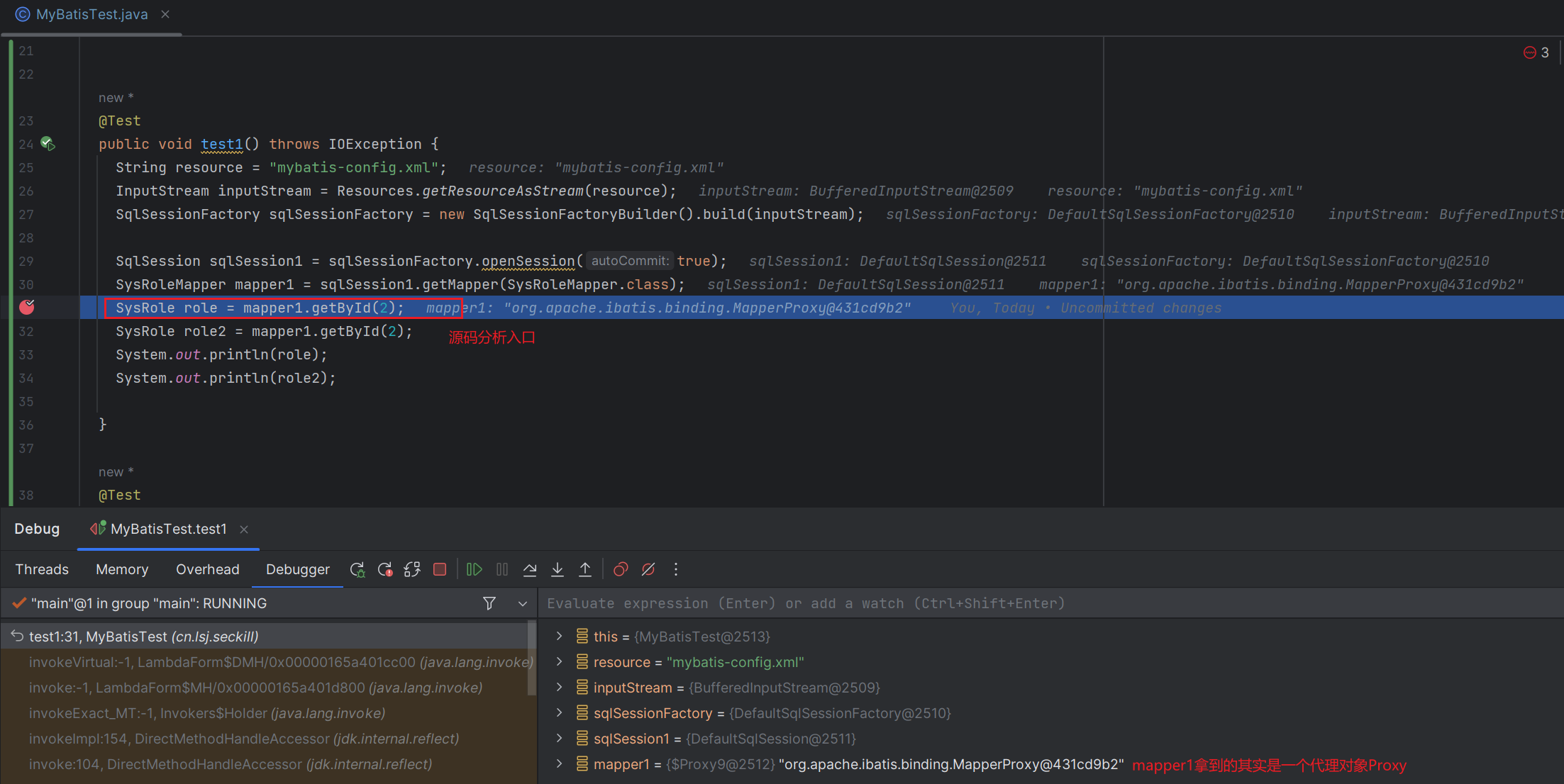
MapperProxy实现了InvocationHandler接口,所以SysRoleMapper调用的 方法 都会进入代理对象MapperProxy的invoke方法。
public class MapperProxy<T> implements InvocationHandler, Serializable {
// 略
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 先拿到声明method方法的类(在这里具体指定是SysRoleMapper)。
// 如果是 Object 类,则表明调用的是一些通用方法,比如 toString()、hashCode() 等,就直接调用即可。
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
// 略
}
小结:从上面可以知道,我们调用SysRoleMapper接口中的 方法,其实都会进入MapperProxy#invoke方法中。
现在,我们进一步看,由于getById方法不是Object默认的方法,所以会跑else分支,详情分析请看代码:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 跑else分支
// 整体了解此行代码的流程:
// 1.首先Method会被包装成MapperMethod;1️⃣
// 2.MapperMethod被封装到PlainMethodInvoker类内;2️⃣
// 3.此类(PlainMethodInvoke)提供一个普通的方法invoke,此方法会实际调用MapperMethod的execute方法3️⃣
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
private MapperMethodInvoker cachedInvoker(Method method) throws Throwable {
try {
return MapUtil.computeIfAbsent(methodCache, method, m -> {
// 是否Java语言规范定义的默认方法?否
if (m.isDefault()) {
// 这里的细节不要深究了
try {
if (privateLookupInMethod == null) {
return new DefaultMethodInvoker(getMethodHandleJava8(method));
} else {
return new DefaultMethodInvoker(getMethodHandleJava9(method));
}
} catch (IllegalAccessException | InstantiationException | InvocationTargetException
| NoSuchMethodException e) {
throw new RuntimeException(e);
}
} else {
// 看这里,跑的是else分支
// 对于普通的方法(如SysRoleMapper#getById),使用的是PlainMethodInvoker实现类。
// >> 其中,MapperMethod表示对原始的Method方法对象进行了一次包装(细节就先不深究了)
// >> mapperInterface 信息在创建MapperProxy对象的时候写入,信息默认来源于我们定义的mybatis-config.xml文件, 包括sqlSession也是。
return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));//1️⃣️
}
});
} catch (RuntimeException re) {
Throwable cause = re.getCause();
throw cause == null ? re : cause;
}
}
private static class PlainMethodInvoker implements MapperMethodInvoker {
private final MapperMethod mapperMethod;
public PlainMethodInvoker(MapperMethod mapperMethod) {
super();
this.mapperMethod = mapperMethod;//2️⃣
}
@Override
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable {
return mapperMethod.execute(sqlSession, args);//3️⃣
}
}
从上面注释中,相信你已经了解到MapperProxy#invoke方法下一步会流向哪个类:MapperMethod#execute()

MapperMethod
现在我们看看MapperMethod#execute()做了什么:根据command属性提供的sql方法类型调用sqlSession接口中合适的的处理方法。
public class MapperMethod {
// 方法对应的sql类型:select、update、delete、insert
// 在MapperProxy#invoke#cachedInvoker方法中创建MapperMethod类时设置的,感兴趣的可以回看
private final SqlCommand command;
private final MethodSignature method;
public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) {
this.command = new SqlCommand(config, mapperInterface, method);
this.method = new MethodSignature(config, mapperInterface, method);
}
// 这个方法整体做了什么?根据command提供的sql方法类型调用sqlSession接口中合适的的处理方法。
// >> 我们之前封装MapperMethod的时候,定义了此类的command、method属性;
// >> 其中command这个属性表示sql方法的类型
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// getById方法是查询语句,所以会进入SELECT分支
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
// 无返回值,同时有专门的结果处理类
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
// 返回多个结果
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
// 返回map类型的结果
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
// 返回结果是数据库游标类型
result = executeForCursor(sqlSession, args);
} else {
// 看这里,跑的是else分支:
// 获取参数对象,不用关注细节
Object param = method.convertArgsToSqlCommandParam(args);
// SysRoleMapper#getById结果类型是单个对象,所以最终跑的是这行代码
result = sqlSession.selectOne(command.getName(), param);
// 下面代码细节不重要,就不展开了
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
// 略
}
好了,看完上面代码,相信你已经知道下一步代码会跑到那里了:SqlSession#selectOne()
SqlSession是一个接口,定义了一些列通用的SQL操作,如selectList、insert、update、commit 和 rollback等操作。
小结:通过上面的分析,我们已经知道,我们调用SysRoleMapper#getById方法本质上其实还是调用SqlSession接口提供的通用SQL操作方法。只不过利用 代理 Mapper接口 的方式,实现方法调用 自动路由到SqlSession接口对应的方法。

SqlSession
通过上面分析,想必你已经知道下一步要走哪了,SqlSession接口默认的实现类是DefaultSqlSession,所以selectOne方法跑的是这个实现类:
public class DefaultSqlSession implements SqlSession {
// 略
@Override
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.(译:大众投票是在 0 个结果上返回 null,并在太多结果上抛出异常。)
// 很明显,selectOne最终跑的是selectList方法
List<T> list = this.selectList(statement, parameter);
// 下面代码不用关注
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
// 略
/**
* 封装MappedStatement对象,通过executor发起查询。
* @param statement 映射信息,方法的全路径:cn.lsj.seckill.SysRoleMapper.getById
* @param parameter SQL参数
* @param rowBounds 辅助分页,默认不分页。RowBounds(int offset, int limit)
* @param handler 处理结果回调。查询完成之后调用回调
* @return
* @param <E>
*/
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
// 这个类主要封装了SysRoleMapper相关信息,包括:方法全路径(id)、原始xml文件(resource)、
// sql语句相关信息(sqlSource)、结果类型映射信息、与映射语句关联的缓存配置信息(cache)等
MappedStatement ms = configuration.getMappedStatement(statement);
// wrapCollection是懒加载机制的一部分,不用关注细节
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
}
通过上述代码可以知道,selectOne方法内部最终还是依靠Executor接口的query方法去执行具体的sql,只不过在此之前会从Configuration配置类里面通过 映射信息 statement 拿到MappedStatement封装对象,然后传递给query方法。

Executor
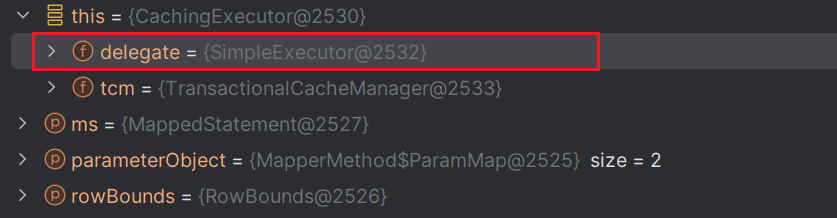
在上面,我们了解到下一步走的是Executor接口的query方法,CachingExecutor是Executor接口的实现类,基于装饰者模式对Executor功能进行了增强:增加了缓存机制。
public class CachingExecutor implements Executor {
private final Executor delegate; // 默认被装饰的实现类 SimpleExecutor
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
delegate.setExecutorWrapper(this);
}
// 略
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 表示一条 SQL 语句以及相关参数(不用关注细节)
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 构造缓存的KEY(不用关注细节)
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 读取二级缓存的缓存对象
Cache cache = ms.getCache();
// 开启二级缓存时跑这个分支,先不关注
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
// 通过断点可以看到:默认被装饰的Executor接口实现类是SimpleExecutor (图1️⃣)
// 由于SimpleExecutor继承了抽象类BaseExecutor 但没有实现query方法,所以,最终指向的还是BaseExecutor#query() (图2️⃣)
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
// 略
}
- 图1️⃣
- 图2️⃣
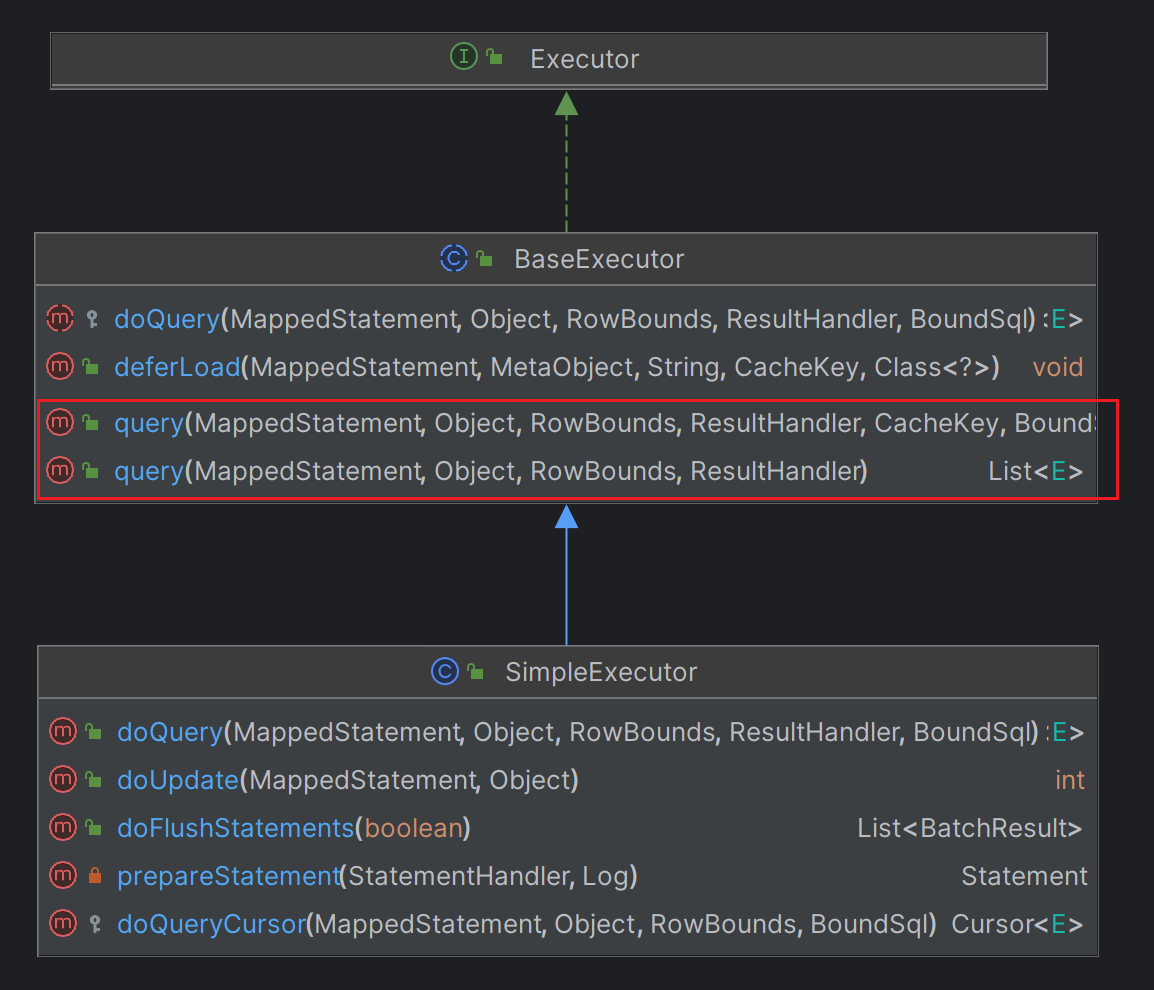
通过上面代码注释,我们最终了解到CachingExecutor#query方法跑向的是BaseExecutor#query。

现在,我们看一下BaseExecutor类的query方法:
public abstract class BaseExecutor implements Executor {
// 略
protected PerpetualCache localCache; // 缓存Cache(一级缓存)具体的一个实现类
// 略
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
// 很明显,这个是存储查询结果的,我们围绕这个对象来看代码
List<E> list;
try {
queryStack++;
// 从缓存中读取结果(第一次查询没有缓存)
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 跑else分支
// 从数据库中读取
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
// 略
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 给key对应的缓存值设置一个占位值(只是用于占位)
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 真正处理查询的方法
// 抽象类没有实现doQuery方法,所以方法的调用是其实现类 SimpleExecutor#doQuery
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
}

StatementHandler
RoutingStatementHandler
现在,我们在看看SimpleExecutor#doQuery方法,没有太多复杂逻辑,直接是交由StatementHandler接口处理了,接口的实现类是RoutingStatementHandler。
在划分上,
StatementHandler属于Executor的一部分,参与SQL处理:
RoutingStatementHandler:根据执行的 SQL 语句的类型(SELECT、UPDATE、DELETE 等)选择不同的 StatementHandler 实现进行处理。PreparedStatementHandler:处理预编译 SQL 语句的实现类。预编译 SQL 语句是指在数据库预先编译 SQL 语句并生成执行计划,然后在后续的执行中,只需要传递参数并执行编译好的执行计划,可以提高 SQL 的执行效率。
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 此接口用于处理数据库的 Statement 对象的创建和执行
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler); // 打断点可以看到handler实现类:RoutingStatementHandler,它作用就是选择合适的StatementHandler实现类执行SQL
} finally {
closeStatement(stmt);
}
}

我们再看看RoutingStatementHandler#query方法,使用了装饰者模式,被装饰类是PreparedStatementHandler。
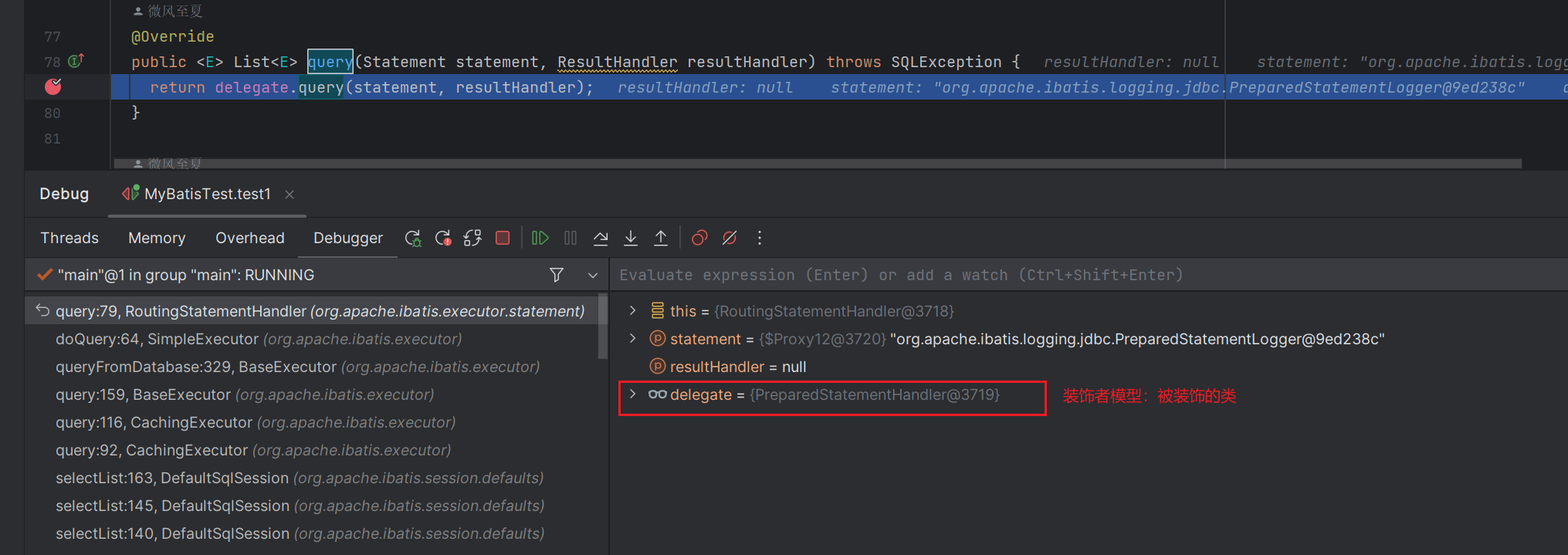
PreparedStatementHandler
RoutingStatementHandler选择了合适的处理类来执行SQL:PreparedStatementHandler。
现在打开看看PreparedStatementHandler#query方法:
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// Java JDBC 中的一个接口,用于执行预编译的 SQL 语句。使用过JDBC编程的应该见过,可以看文末的JDBC编程Demo回忆回忆。
PreparedStatement ps = (PreparedStatement) statement;
// 执行 SQL 语句。
ps.execute();
// “结果处理器”会处理并返回查询结果(在这里就不深究了)
return resultSetHandler.handleResultSets(ps);
}
现在,让我们往回看BaseExecutor#queryFromDatabase方法:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 给key对应的缓存值设置一个占位值(只是用于占位)
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 此时,我们已经拿到结果了
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 将结果写入到缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
到这里,我们经历了一次(第一次)查询的过程,并在BaseExecutor#queryFromDatabase方法中,将查询结果写入到localCache属性中。
我们再查一次,就会发现,在BaseExecutor#query中,这次直接拿到了缓存的数据:
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 略
List<E> list;
try {
queryStack++;
// 从本地缓存拿到了上次的查询结果
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
// 略
return list;
}
小结
整个流程下来,发现最关键的地方就是BaseExecutor抽象类的query、queryFromDatabase这两个方法,它们在一级缓存方面,围绕localCache属性做缓存操作。
- 第一次查询,跑
queryFromDatabase方法,并将查询结果写入localCache属性; - 第二次相同的查询,直接从
localCache属性中读取缓存的查询结果。
二级缓存流程分析
开启二级缓存
添加配置到mybatis-config.xml文件:
<settings>
<!-- 二级缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>
修改SysRoleMapper.xml文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.lsj.seckill.SysRoleMapper">
<!-- 表示此namespace开启二级缓存 -->
<cache/>
<select id="getById" resultType="cn.lsj.seckill.SysRole" >
select * from sys_role where role_id = #{id}
</select>
</mapper>
流程分析
当我们开启二级缓存之后,查询过程就变成:二级缓存->一级缓存->数据库
二级缓存的验证代码:
@Test
public void test1() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession1 = sqlSessionFactory.openSession(true);
SysRoleMapper mapper1 = sqlSession1.getMapper(SysRoleMapper.class);
SysRole role = mapper1.getById(2);
System.out.println(role);
// 提交事务二级缓存数据才生效
sqlSession1.commit();
SqlSession sqlSession2 = sqlSessionFactory.openSession(true);
SysRoleMapper mapper2 = sqlSession2.getMapper(SysRoleMapper.class);
SysRole role2 = mapper2.getById(2);
System.out.println(role2);
System.out.println(mapper1.getById(2));
}
在前面的CachingExecutor#query方法中,我们看到了二级缓存的代码:
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
// 假如我们开启了二级缓存,那么我们的查询会先跑此分支
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
// 从缓存中读取数据
List<E> list = (List<E>) tcm.getObject(cache, key);
// 二级缓存中没有数据时再查数据库
if (list == null) {
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 将查询结果写入到二级缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
总结
看到这里,我们回顾一下,在之前的分析中,我们看到装饰者模式出现得比较频繁;此外还是用到动态代理技术。
整个分析下来,相信你收获的不止这些,源码阅读能力应该能得到一些提升,对设计模式、动态代理的理解也会有一些加深。
好了,如果你感兴趣的话,可以进一步深入分析缓存如何刷新、生效,如何做到缓存会话级别、Mapper级别的隔离的。
最后,留下一些思考问题:
- 开启二级缓存之后,为什么
sqlSession1.commit();之后二级缓存才生效?
附:JDBC编程Demo
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class JDBCDemo {
public static void main(String[] args) {
// MySQL服务器的JDBC URL、用户名和密码
String url = "jdbc:mysql://localhost:3306/你的数据库名";
String user = "你的用户名";
String password = "你的密码";
try {
// 加载JDBC驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
// 建立数据库连接
Connection connection = DriverManager.getConnection(url, user, password);
// 创建SQL语句
String sql = "SELECT * FROM 你的表名";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// 执行查询
ResultSet resultSet = preparedStatement.executeQuery();
// 处理结果集
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
String email = resultSet.getString("email");
System.out.println("ID: " + id + ", Name: " + name + ", Email: " + email);
}
// 关闭资源
resultSet.close();
preparedStatement.close();
connection.close();
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
}
}
}
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法