UTF-8 与 UTF-16编码详解_utf-8和utf-16-程序员宅基地
目录
3、上述Unicode码点值范围中十进制值127、2047、65535、2097151这几个临界值是怎么来的呢?
一、UTF-8编码
1、UTF-8介绍
UTF-8编码是Unicode字符集的一种编码方式(CEF),其特点是使用变长字节数(即变长码元序列、变宽码元序列)来编码。一般是1到4个字节,当然,也可以更长。
为什么要设计为变长字节数?
可以理解为按需分配,比如一个字节足以容纳所有的ASCII字符,那何必补一堆0用更多的字节来存储呢?
变长编码的优势与劣势
优势是节省空间、自动纠错性能好、利于传输、扩展性强,劣势是不利于程序内部处理,比如正则表达式检索;而UTF-32这样等长码元序列(即等宽码元序列)的编码方式就比较适合程序处理,当然,缺点是比较耗费存储空间。
2、UTF-8是如何编码的?
UTF-8编码最短的为一个字节、最长的目前为四个字节,从首字节就可以判断一个UTF-8编码有几个字节:
- 如果首字节以0开头,肯定是单字节编码(即单个单字节码元);
- 如果首字节以110开头,肯定是双字节编码(即由两个单字节码元所组成的双码元序列);
- 如果首字节以1110开头,肯定是三字节编码(即由三个单字节码元所组成的三码元序列),以此类推。
另外,UTF-8编码中,除了单字节编码外,由多个单字节码元所组成的多字节编码其首字节以外的后续字节均以10开头(以区别于单字节编码以及多字节编码的首字节)。
0、110、1110以及10相当于UTF-8编码中各个字节的前缀,因此称之为前缀码。其中,前缀码110、1110及10中的0,是前缀码中的终结标志。
UTF-8编码中的前缀码起到了很好的区分和标识的作用——当解码程序读取到一个字节的首位为0,表示这是一个单字节编码的ASCII字符;当读取到一个字节的首位为1,表示这是一个非ASCII字符的多字节编码字符中的某个字节(可能是首字节,也可能是后续字节),接下来若继续读取到一个1,则确定为首字节,再继续读取直到遇见终结标志0为止,读取了几个1,就表示该字符为几个字节的编码;当读取到一个字节的首位为1,紧接着读取到一个终结标志0,则该字节显然是非ASCII字符的后续字节(即非首字节)。
所以,1~4字节的UTF-8编码看起来分别是这样的:
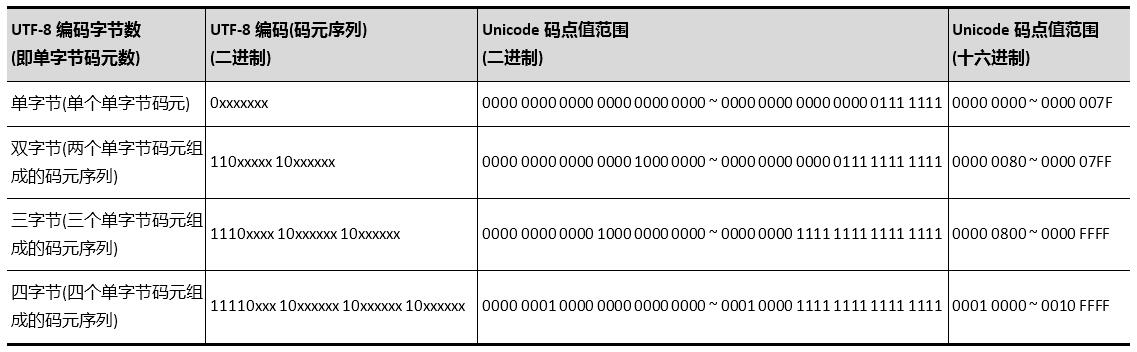
- 单字节可编码的Unicode码点值范围十六进制为0x0000 ~ 0x007F,十进制为0 ~ 127;
- 双字节可编码的Unicode码点值范围十六进制为0x0080 ~ 0x07FF,十进制为128 ~ 2047;
- 三字节可编码的Unicode码点值范围十六进制为0x0800 ~ 0xFFFF,十进制为2048 ~ 65535;
- 四字节可编码的Unicode码点值范围十六进制为0x10000 ~ 0x1FFFFF,十进制为65536 ~ 2097151
目前Unicode字符集码点编号的最大值为0x10FFFF,实际尚未编号到0x1FFFFF;这说明作为变长字节数的UTF-8编码其未来扩展性非常强,即便目前的四字节编码也还有大量编码空间未被使用,更不论还可扩展为五字节、六字节…...。
3、上述Unicode码点值范围中十进制值127、2047、65535、2097151这几个临界值是怎么来的呢?
因为UTF-8编码中的每个字节中都含有起到区分和标识之用的前缀码0、110、1110以及10之一,所以1~4个字节的UTF-8编码其实际有效位数分别为8-1=7位(2^7-1=127)、16-5=11位(2^11-1=2047)、24-8=16位(2^16-1=65535)、32-11=21位(2^21-1=2097151),如下表所示:
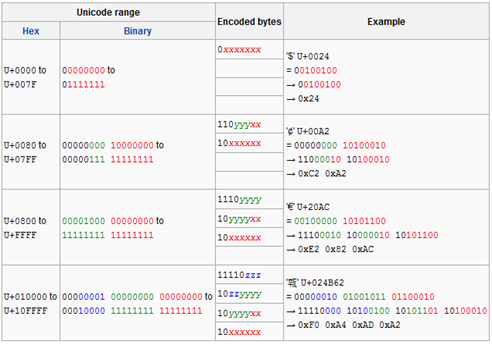
注:上图中的Unicode range即Unicode码点值范围(也就是Unicode码点编号范围),Hex为16进制,Binary为二进制;Encoded bytes即UTF-8编码中各字节的编码方式(即编码算法),其中,x代表Unicode二进制码点值的单字节或低字节中的低7位或8位、y代表两字节码点值的高字节中的低3位或8位以及三字节码点值的中字节中的8位、z代表三字节码点值的高字节中的低5位。
因此,UTF-8编码的算法简单地用一句话来概括就是:首先确定UTF-8编码中各个字节的前缀码;之后再将UTF-8编码中各个字节除了前缀码所占用之外的位,依次分配给Unicode字符码点值二进制中各个位的值,换言之,就是用Unicode字符码点值二进制中各个位的值,依次填充UTF-8编码中的各个字节除了前缀码所占用之外的位。
参考文章:刨根究底字符编码之十二——UTF-8究竟是怎么编码的 - 腾讯云开发者社区-腾讯云 (tencent.com)
二、UTF-16编码
1、UTF-16介绍
UTF-16是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为 "storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元, 长度为2 Byte)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
引用维基百科中对于UTF-16编码的解释我们可以知道,UTF-16最少也会用2 Byte来表示一个字符,因此没有办法兼容ASCII编码(ASCII编码使用1 Byte来进行存储)。
2、UTF-16编码方式
1)设计思路
我们知道Unicode的范围为0x0~0x10FFFF,首先是0x0~0xFFFF这段区间,正好16位就可以表示,那么超过这个区间的怎么办呢?也就是0xFFFF~0x10FFFF这段,我们先看这段区间有多少个码位,0x10FFFF-0xFFFF=0x100000,那么这个十六进制表示的十进制也就是:1048576个码位
我们既然16位存不下,那肯定就是32位存咯,将32位分开前16位和后16位,每个16位各存一半,那么每一半存的就是1024(由来:1024*1024=1048576),1024代表的是2的10次幂,也就是10位二进制数。
32位二进制数字中,前后16位中各存10位就够用了,但是剩余的6位用来干什么呢?和UTF-8的设计一样,为了让识别字符串变得容易(从文本的任意位置开始,均能区分一个字符的起始)。
我们通过前6位来区分数据,那么前6位就是2^6=64,也就是开头数字的区间。我们设定如下:
54开头的为32位的前16位,55开头的为32位的后16位,其他开头的为单16位,这样我们就能区分开这三个16位了,在读取文档中的任意位置,都能随意区分出间隔咯。
- 那么54开头的数据区间是多少呢,就是1101 10xx xxxx xxxx,区间就是D800~DBFF
- 那么55开头的数据区间是多少呢,就是1101 11xx xxxx xxxx,区间就是DC00~DFFF
为了配合UTF-16,Unicode中也将这两个区间屏蔽掉,不允许分配任何字符,这个区间就是代理区。
2)具体编码方式
在UTF-16中,我们将Unicode分为了两个范围,分别通过不同的方式进行存储。具体表示见下图。
| Unicode范围 |
UTF-16编码方式 |
|---|---|
| U+000~U+FFFF |
2 Byte存储,编码后等于Unicode值 |
| U+10000~U+10FFFF |
4 Byte存储,现将Unicode值减去(0x10000),得到20bit长的值。再将Unicode分为高10位和低10位。UTF-16编码的高位是2 Byte,高10位Unicode范围为0-0x3FF,将Unicode值加上0XD800,得到高位代理(或称为前导代理,存储高位);低位也是2 Byte,低十位Unicode范围一样为0~0x3FF,将Unicode值加上0xDC00,得到低位代理(或称为后尾代理,存储低位) |
- 0x3FF --> 0011 1111 1111
- 0xD800 --> 1101 1000 0000 0000
- 0xDC00 --> 1101 1100 0000 0000
3)字节顺序问题
由于一开始的Unicode只需要两个字节,所以UTF-16虽然也是变长编码方式,但是在最初却可以当做定长编码方式使用。UTF-16每个字符都直接使用两个字节存储,所以就有字节顺序的问题,同一字节流可能会被解释为不同内容。如某字符为十六进制编码4E59,按两个字节拆分为4E和59,在Mac中和Windows中会解析如下:
| - | 读取顺序 | 显示字符 |
|---|---|---|
| Windows | 4E 59 | 奎 |
| Mac | 59 4E | 乙 |
在Mac上从低字节开始和在Windows上从高字节开始读取显示不同,从而导致在同一编码下的乱码问题。为了解决这个问题便引入了字节顺序标记(英语:byte-order mark,BOM)来标记是大端序还是小端序。
3、BOM
字节顺序标记(英语:byte-order mark,BOM)是一个有特殊含义的统一码字符,码点为U+FEFF。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。经常被用于区分是否为UTF编码。
字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前。如果它出现在字节流的中间,则表达零宽度非换行空格的意义,用户看起来就是一个空格。从Unicode3.2开始,U+FEFF只能出现在字节流的开头,只能用于标识字节序,就如它的名称——字节序标记——所表示的一样;除此以外的用法已被舍弃。取而代之的是,使用U+2060来表达零宽度无断空白。
UTF-8以字节为编码单元,没有字节序的问题。但是某些操作系统也会使用带BOM的UTF-8,叫做UTF-8 with BOM。Python中叫utf-8-sig。Unicode规范中说明UTF-8不必也不推荐使用BOM。多数时候UTF-8都是不带BOM的,但是微软公司的某些软件(如Excel)打开某些不带BOM的utf8文件(如cvs文件)会乱码,需要转换成带BOM的utf8编码才能正常显示。
所以Java中获取以UTF-16编码的字符串字节个数时,总是会比实际含有字符的字节个数多2。不过目前已经有很多主流的文本编辑器支持不带BOM的UTF编码了,通过后缀(LE和BE)区分是小端还是大端。
参考文章:UTF-16编码详解 - 知乎 (zhihu.com)
Unicode中UTF-8与UTF-16编码详解 - 腾讯云开发者社区-腾讯云 (tencent.com)
三、两者比较
1、存储容量
先说UTF-16,由于每个码位都使用2到4个字节来存储,对于含有大量中文或者其他二字节长的字符流来说,UTF-16可以节省大量的存储空间。因为UTF-16并不需要像UTF-8那样通过牺牲很多标记位来标识一个字节表示的是什么,它只需一个字符来表示是大端序和小端序。
但是对于有大量西文字符的字符流来说UTF-8的优势就变得十分明显:UTF-8只需要一个字节就能存储西文字符,这是UTF-16做不到的。所以在混合存储,或者是源代码、字节码文件等大量西文字符的文件,更倾向于UTF-8。
UTF-8存储中文比UTF-16要多出50%,不推荐要大量显示中文的程序使用。—— 知乎轮子哥
而由于UTF-8的兼容性和对西文的支持,所以西方都提倡统一使用UTF-8作为字符编码,这样也的确可以彻底根除乱码问题。目前基本上所有的开发环境和源代码文件也基本上是统一UTF-8。
2、存储效率
这里只从UTF-8和UTF-16两个编码来简单阐述下效率问题。
因为每个字符使用不同数量的字节编码,所以UTF-8编码的字符串,寻找串中第N个字符是一个O(N)复杂度的操作。即串越长,则需要更多的时间来定位特定的字符。同时,还需要位变换来把字符编码成字节,把字节解码成字符。
而从UTF-16编码规则来看,仅仅将字符的高位和地位进行拆分变成两个字节。规则非常简单,编码效率很高,单字节O(1)的查找效率也非常好。
不过值得一提的是,这种时间效率问题正在随着内存和CPU的发展而减小,现在已经不会作为主要考虑的问题了。
3、字节序
UTF-8最大的优势是,没有字节序的概念。所以特别适合用于字符串的网络数据传输,不用考虑大小端问题。对于非英文网页(对于我们而言,简单说东亚文字网页),能够避免各种乱码问题。
UTF-16编码字符串的网络传输,要考虑大小端的问题。另外网络传输中如果一个字节信息丢失,剩下的字符串都无法正确解析,读取混乱,统统乱码,而UTF-8只会影响局部,因为有标识端,后面的数据可以正常读取。
智能推荐
Oracle 21版Database In-Memory LivaLabs实验(下)_oracle的ytes_not_populated不为0-程序员宅基地
文章浏览阅读806次。Oracle 21版Database In-Memory LivaLabs实验(下)_oracle的ytes_not_populated不为0
如果非要回到古代,我会选择春秋战国-程序员宅基地
文章浏览阅读2.4k次。以史为鉴,可以知兴替|第103篇1.“矮大紧”高晓松曾说:“作为知识分子,如果非要我回到古代,我会选择春秋战国,其次是唐宋。”我不知道自己算不算得上是知识分子,假如让我...
Java-序列化serialVersionUID不一致处理_java序列化时对象属性不一致报错怎么办-程序员宅基地
文章浏览阅读2k次。文章目录背景serialVersionUID不一致的兼容处理背景Java Object Serialization 会使用对象中的serialVersionUID私有静态常量长整型属性(private static final long)作为该对象的版本号,反序列化时 JVM 会校验该版本号是否和序列化时的一致,如果不一致会导致序列化失败,抛出InvalidClassException异常。默认情况下,JVM 为每一个实现了Serializable的接口的类生成一个serialVersionUID,_java序列化时对象属性不一致报错怎么办
卸载 流程_IE11卸载发生错误没有成功卸载全部更新解决方法-程序员宅基地
文章浏览阅读1w次。有很多Win7系统用户把IE浏览器升级到IE11浏览器,但是发现并不好用,或是和一些工作不兼容,想要卸载回到原来老版本的IE浏览器,可是在卸载的时候出现:发生错误,没有成功卸载全部更新,也就是说卸载失败了,那么遇到这样的情况时要怎么才能卸载呢?一起来看看小编亲测可用的解决方法。修复步骤如下:操作流程:可以先进入【C:WindowsTEMP】文件夹清空;然后以管理员身份进入【命令行提示符】;输入代码..._ie浏览器降低版本卸载失败
html纵向表头,html固定表头,表单内容垂直循环滚动-程序员宅基地
文章浏览阅读84次。Bootstrap 101 Template.content {width: 500px;margin: 50px 50px;}.header {line-height: 50px;background-color: #ECECEC;}.data {height: 300px;overflow: hidden;}姓名性别年龄职业var html = '';for(var i = 0; i <..._原生html for循环 纵向表头
Python常见报错_int' object has no attribute '__getitem__-程序员宅基地
文章浏览阅读2.3k次。1.IndexError: tuple index out of range错误的原因是元组索引越界,因为后面format中的内容出现了赋值操作2.TypeError: ‘int’ object has no attribute ‘getitem’会出现报错:在python2中,input输入数字得到的就是int类型的数字,数字是不可以做下标取值,而python3中input输入都为字符串,而字符串可以下标索引3.SyntaxError: ‘break’ outside loop原因:bre_int' object has no attribute '__getitem__
随便推点
Nacos数据库配置_nacos配置数据库-程序员宅基地
文章浏览阅读1.5w次。深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则近万的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!因此收集整理了一份《Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。_nacos配置数据库
SIwave电源阻抗(PDN)分析。_siwave pdn仿真-程序员宅基地
文章浏览阅读1.3k次,点赞3次,收藏16次。Z阻抗只看PDN的时候,只需要关注自阻抗就好了。名字一样的是自阻抗,VRM到后面是传输阻抗,_siwave pdn仿真
Linux中禁用ctrl alt del快捷键重启_linx 关闭 ctrl alt del-程序员宅基地
文章浏览阅读363次,点赞7次,收藏8次。【代码】Linux中禁用ctrl alt del快捷键重启。_linx 关闭 ctrl alt del
Vue.js动态获取浏览器高度、宽度并进行实时修改DOM元素高度_vue3 dom元素获取距离浏览器工具栏的高度-程序员宅基地
文章浏览阅读4.7k次,点赞2次,收藏7次。需求:项目中有高度、宽度自适应需求,需要适应不同分辨率的高度及宽度,在不同分辨率下效果区别不会很大html代码如下:<template> <div id="home"> <div class="head" > <v-head></v-head> </div&..._vue3 dom元素获取距离浏览器工具栏的高度
在SpringBoot中使用Spring Security实现权限控制_spring-security配置允许访问ip-程序员宅基地
文章浏览阅读6.8k次,点赞2次,收藏6次。以前在Spring框架中使用Spring Security需要我们进行大量的XML配置,但是,Spring Boot在这里依然有惊喜带给我们,我们今天就一起来看看。 毫无疑问,Spring Boot针对Spring Security也提供了自动配置的功能,这些默认的自动配置极大的简化了我们的开发工作,我们今天就来看看这个吧。创建Project并添加相关依赖 配置applicat..._spring-security配置允许访问ip
vmware16,vmware17虚拟机安装以及序列号备份,安装win11,进入启动界面闪退_vm17pro密钥许可证-程序员宅基地
文章浏览阅读737次,点赞9次,收藏8次。检测到hyper-v 时,勾选自动安装。_vm17pro密钥许可证