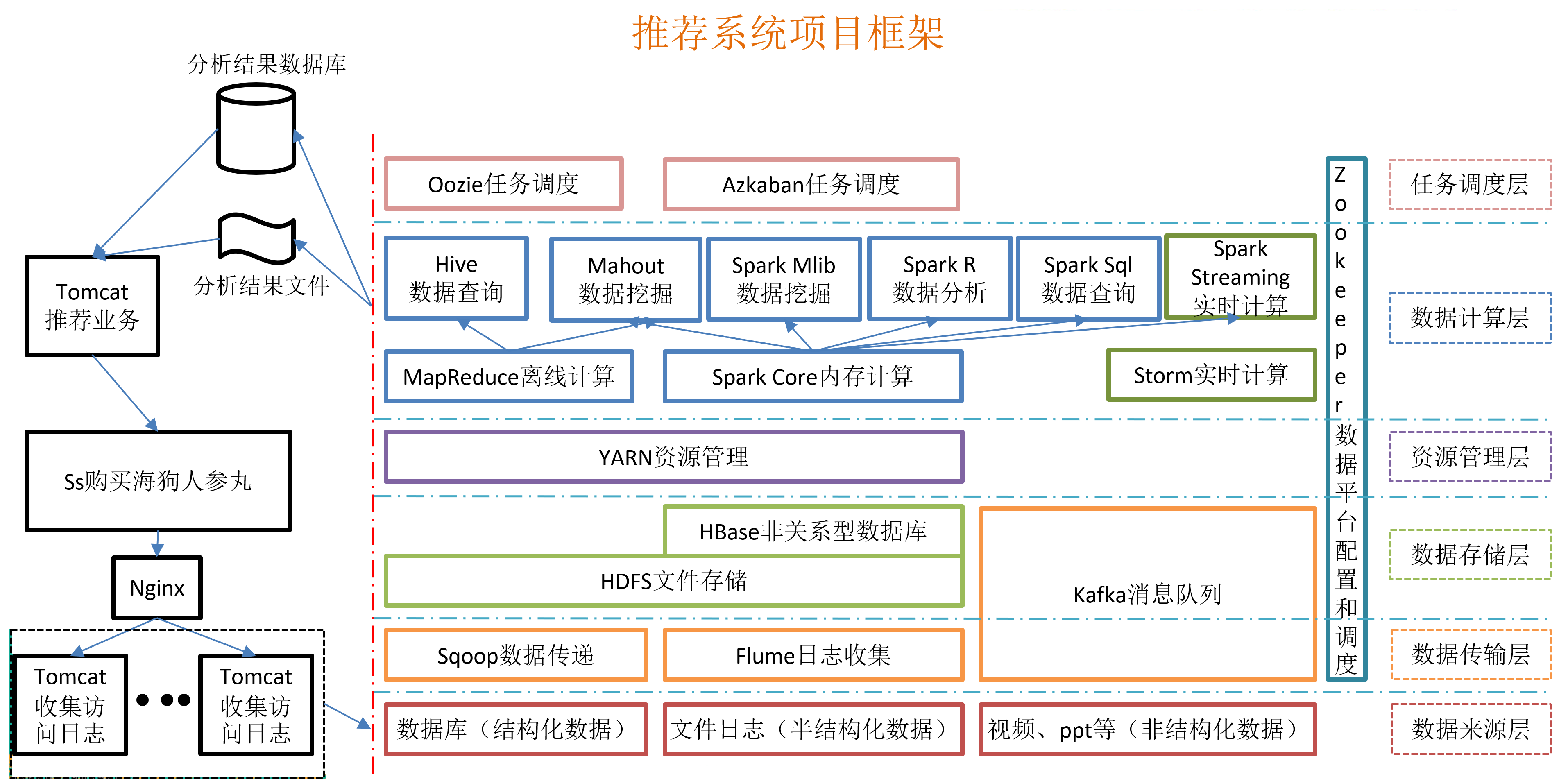
大数据-Flume(一):日志收集系统【将应用产生的日志数据发送到Kafka/HDFS/HBase】【Source(上游)--Channel(缓冲区)-->Sink(下游)】【基于CentOS6】_flume采集数据到kafka-程序员宅基地
技术标签: flume # 大数据/数据采集(Flume/dataX) 大数据




一、Flume安装
保证安装Flume的Linux服务器的环境变量中有JAVA_HOME
1、在hadoop102服务器上安装
将apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/soft目录下,解压apache-flume-1.7.0-bin.tar.gz到/opt/module/目录下
[wyr@hadoop102 software]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
修改apache-flume-1.7.0-bin的名称为flume
[wyr@hadoop102 module]$ ll
total 20
drwxrwxr-x. 7 wyr wyr 4096 Jan 31 12:14 apache-flume-1.7.0-bin
drwxr-xr-x. 11 wyr wyr 4096 Jan 31 10:43 hadoop-2.7.2
drwxrwxr-x. 9 wyr wyr 4096 Jan 30 19:27 hive
drwxr-xr-x. 8 wyr wyr 4096 Dec 13 2016 jdk1.8.0_121
drwxr-xr-x. 11 wyr wyr 4096 Jan 29 22:01 zookeeper-3.4.10
[wyr@hadoop102 module]$ mv apache-flume-1.7.0-bin/ flume
[wyr@hadoop102 module]$ ll
drwxrwxr-x. 7 wyr wyr 4096 Jan 31 12:14 flume
drwxr-xr-x. 11 wyr wyr 4096 Jan 31 10:43 hadoop-2.7.2
drwxrwxr-x. 9 wyr wyr 4096 Jan 30 19:27 hive
drwxr-xr-x. 8 wyr wyr 4096 Dec 13 2016 jdk1.8.0_121
drwxr-xr-x. 11 wyr wyr 4096 Jan 29 22:01 zookeeper-3.4.10
[wyr@hadoop102 module]$
将flume配置到系统环境变量中
[wyr@hadoop102 module]$ cd flume
[wyr@hadoop102 flume]$ pwd
/opt/module/flume
[wyr@hadoop102 flume]$ vim /etc/profile
[wyr@hadoop102 flume]$
JAVA_HOME=/opt/module/jdk1.8.0_121
HADOOP_HOME=/opt/module/hadoop-2.7.2
HIVE_HOME=/opt/module/hive
FLUME_HOME=/opt/module/flume
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$FLUME_HOME/bin
export JAVA_HOME HADOOP_HOME HIVE_HOME FLUME_HOME PATH
[wyr@hadoop102 flume]$ source /etc/profile
[wyr@hadoop102 flume]$
2、将Flume目录、环境变量文件分发到hadoop103、hadoop104上
[wyr@hadoop102 module]$ xsync.sh flume
[wyr@hadoop102 etc]$ xsync.sh profile
二、编写Agent的配置文件
Flume是Java写的系统,所以agent的配置文件的本质是一个Properties文件!格式为 属性名=属性值
Flume根据数据源类型和目的存储类型选择合适的source、sink,编写对应的配置文件即可。
在配置文件中需要编写:
- 定义当前配置文件中agent的名称
- 定义source、channel、sink等组件的别名
- 指定source、channel、sink等组件的类型
- 指定source、channel、sink等组件的配置,配置参数名和值都需要参考flume到官方用户手册
- 指定source与channel的对应关系,以及channel与sink的对应关系,来连接组件!
在/opt/module/flume目录下新创建一个文件夹myagests来存放各种不同配置的Agent
[wyr@hadoop102 flume]$ mkdir myagents
[wyr@hadoop102 flume]$ ll
total 152
drwxr-xr-x. 2 wyr wyr 4096 Jan 31 12:14 bin
-rw-r--r--. 1 wyr wyr 77387 Oct 11 2016 CHANGELOG
drwxr-xr-x. 2 wyr wyr 4096 Jan 31 12:14 conf
-rw-r--r--. 1 wyr wyr 6172 Sep 26 2016 DEVNOTES
-rw-r--r--. 1 wyr wyr 2873 Sep 26 2016 doap_Flume.rdf
drwxr-xr-x. 10 wyr wyr 4096 Oct 13 2016 docs
drwxrwxr-x. 2 wyr wyr 4096 Jan 31 12:14 lib
-rw-r--r--. 1 wyr wyr 27625 Oct 13 2016 LICENSE
drwxrwxr-x. 2 wyr wyr 4096 Jan 31 12:58 myagents
-rw-r--r--. 1 wyr wyr 249 Sep 26 2016 NOTICE
-rw-r--r--. 1 wyr wyr 2520 Sep 26 2016 README.md
-rw-r--r--. 1 wyr wyr 1585 Oct 11 2016 RELEASE-NOTES
drwxrwxr-x. 2 wyr wyr 4096 Jan 31 12:14 tools
[wyr@hadoop102 flume]$
创建Agent配置文件
[wyr@hadoop102 flume]$ cd myagents/
[wyr@hadoop102 myagents]$ ll
total 0
[wyr@hadoop102 myagents]$ touch netcatsource-loggersink.conf
[wyr@hadoop102 myagents]$ touch execsource-hdfssink.conf
[wyr@hadoop102 myagents]$ ll
total 0
-rw-rw-r--. 1 wyr wyr 0 Jan 31 13:01 execsource-hdfssink.conf
-rw-rw-r--. 1 wyr wyr 0 Jan 31 13:00 netcatsource-loggersink.conf
[wyr@hadoop102 myagents]$
三、Flume的使用
1、Agent01(netcatsource):监听某个tcp端口手动的数据,然后将数据输出到控制台

1.1 Agent01配置文件:netcatsource-loggersink.conf
- netcat source: 作用就是监听某个tcp端口手动的数据,将每行数据封装为一个event。 工作原理类似于nc -l 端口
- 必须属性:
- type – The component type name, needs to be netcat
- bind – Host name or IP address to bind to
- port – Port # to bind to
- 必须属性:
- logger sink: 作用使用logger(日志输出器)将event输出到文件或控制台,使用info级别记录event!
- 必须属性:
- type – The component type name, needs to be logger
- 可选属性:
- maxBytesToLog 16 Maximum number of bytes of the Event body to log
- 必须属性:
- memery channel
- 必须属性:
- channels
- type – The component type name, needs to be memory
- 可选属性:
- capacity 100 The maximum number of events stored in the channel
- transactionCapacity 100 The maximum number of events the channel will take from a source or give to a sink per transaction
- 必须属性:
#一、定义Agent中各个组件的名称:a1是agent的名称,a1中定义了一个叫r1的source,如果有多个,使用空格间隔
# r1:表示a1的Source的名称
a1.sources = r1
# k1:表示a1的Sink的名称
a1.sinks = k1
# c1:表示a1的Channel的名称
a1.channels = c1
#二、配置source:组名名.属性名=属性值
# 表示a1的输入源类型为netcat端口类型
a1.sources.r1.type=netcat
# 表示a1的监听的主机
a1.sources.r1.bind=hadoop102
# 表示a1的监听的端口号
a1.sources.r1.port=44444
#三、配置chanel:Use a channel which buffers events in memory
# 表示a1的channel类型是memory内存型
a1.channels.c1.type=memory
# 表示a1的channel总容量10000个event
a1.channels.c1.capacity=1000
# 表示a1的channel传输时收集到了1000条event以后再去提交事务
#a1.channels.c1.transactionCapacity = 1000
#四、配置sink
# 表示a1的输出目的地是控制台logger类型
a1.sinks.k1.type=logger
# 规定每行最大接收字节数
a1.sinks.k1.maxBytesToLog=100
#五、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
# 表示将r1和c1连接起来
a1.sources.r1.channels=c1
# 表示将k1和c1连接起来
a1.sinks.k1.channel=c1
1.2 启动 Agent01
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
在命令行中加上 -Dflume.root.logger=info,consloe 可以临时指定sink的输出级别、输出位置
[wyr@hadoop102 flume]$ flume-ng agent -c conf/ -n a1 -f myagents/netcatsource-loggersink.conf -Dflume.root.logger=info,console
开启Agent01之后,就开始监控hadoop102节点的44444端口收到的信息
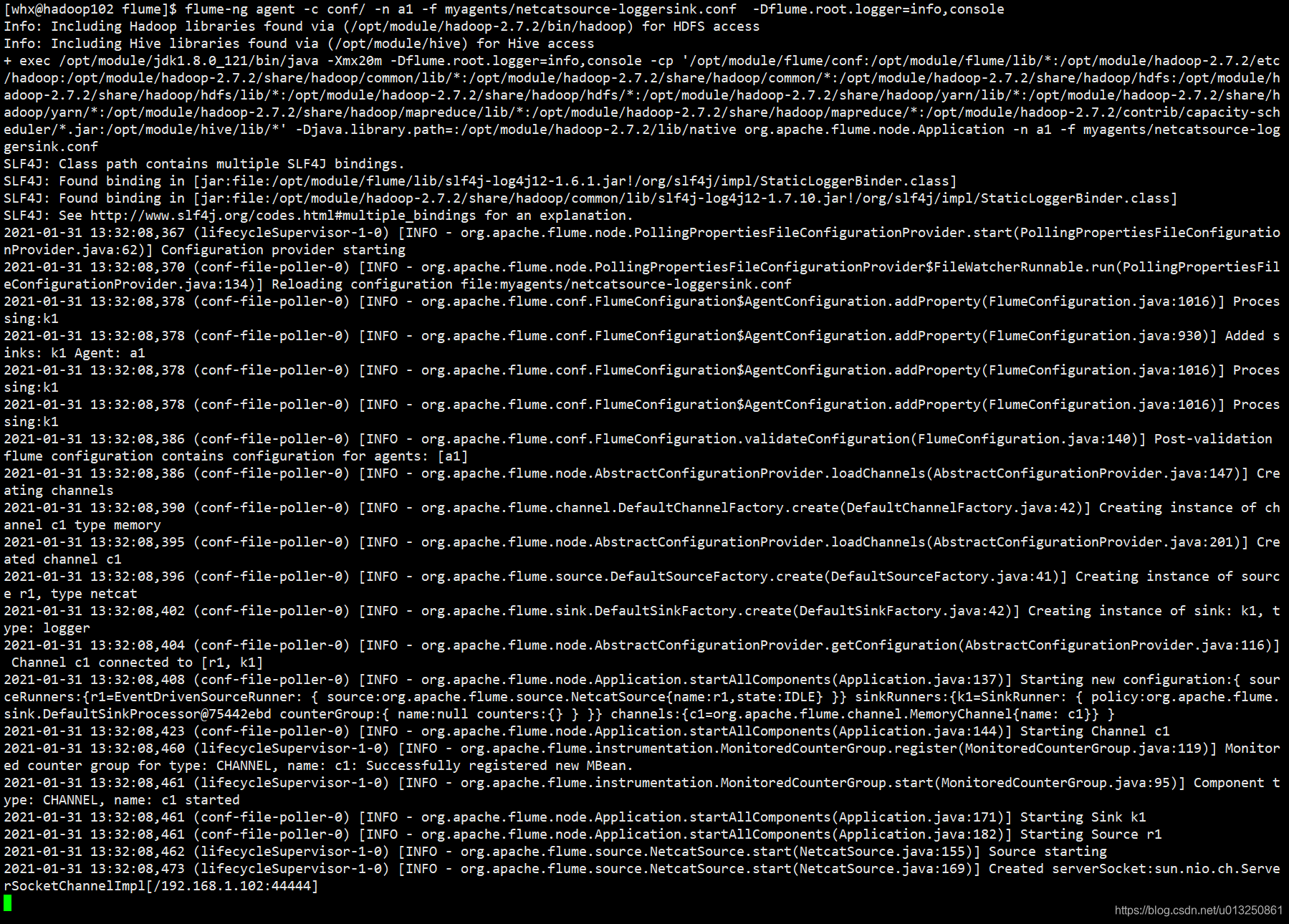
在hadoop103机器上给hadoop102节点的44444端口发送信息:
[wyr@hadoop103 ~]$ nc hadoop102 44444
hello wyr
OK
how are you
OK
fine, thanks
OK
abcdefghijklmnopqrstuvwxyz
OK
hadoop102节点上就会收到:

2、Agent02(execsource):实时监控单个本机文件的内容,将内容写入到HDFS

2.1 配置文件:execsource-hdfssink.conf
- exec source
- exec source会在agent启动时,运行一个linux命令,运行linux命令的进程要求是一个可以持续产生数据的进程!
- 将标准输出的数据封装为event!
- 通常情况下,如果指定的命令退出了,那么source也会退出并且不会再封装任何的数据!
- 所以使用这个source一般推荐类似cat ,tail -f 这种命令,而不是date这种只会返回一个数据,并且执行完就退出的命令!
- 必须配置:
- type – The component type name, needs to be exec
- command – The command to execute
- exec source的缺点
- exec source和异步的source一样,无法在source向channel中放入event故障时及时通知客户端让其暂停生成数据,客户端此时依旧生产数据,但是此时客户端生产的数据无法通过Agent进行保存,会造成数据丢失
- 解决方案:
- 需要在发生故障时,及时通知客户端。
- 如果客户端无法暂停,必须有一个数据的缓存机制。
- 如果希望数据有强的可靠性保证,可以考虑使用SpoolingDirSource或TailDirSource或自己写Source自己控制。
- hdfs sink
- hdfssink将event写入到HDFS!目前只支持生成两种类型的文件: text | sequenceFile,这两种文件都可以使用压缩。
- 写入到HDFS的文件可以自动滚动(关闭当前正在写的文件,创建一个新文件)。基于时间、events的数量、数据大小进行周期性的滚动!(比如基于数据大小进行周期性的滚动:设定每写128M的数据就新创建一个新文件来继续写数据)
- 支持基于时间和采集数据的机器进行分桶和分区操作!
- HDFS数据所上传的目录或文件名可以包含一个格式化的转义序列,这个路径或文件名会在上传event时,被自动替换,替换为完整的路径名!
- 使用此Sink要求本机已经安装了hadoop,或持有hadoop的jar包!
- 必须配置:
- channels
- type – The component type name, needs to be hdfs
- hdfs.path – HDFS directory path (eg hdfs://namenode/flume/webdata/)
#一、定义Agent中各个组件的名称:a2是agent的名称,a2中定义了一个叫r1的source,如果有多个,使用空格间隔
a2.sources = r1
a2.sinks = k1
a2.channels = c1
#二、配置source:组名名.属性名=属性值
a2.sources.r1.type=exec
a2.sources.r1.command=tail -f /opt/module/hive/logs/hive.log
#三、配置chanel:Use a channel which buffers events in memory
a2.channels.c1.type=memory
a2.channels.c1.capacity=1000
#四、配置sink
a2.sinks.k1.type = hdfs
#一旦路径中含有基于时间的转义序列,要求event的header中必须有timestamp=时间戳,如果event的header中必须有timestamp=时间戳,需要设置useLocalTimeStamp = true
a2.sinks.k1.hdfs.path = hdfs://hadoop103:9000/flume/%Y%m%d/%H/%M
#是否使用本地(Agent运行所在的机器)时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#上传后的文件统一添加的前缀
a2.sinks.k1.hdfs.filePrefix = wyr-exec-logs-
#积攒多少个Event才flush到HDFS一次
a2.sinks.k1.hdfs.batchSize = 100
#以下三个和目录的滚动相关,目录一旦设置了时间转义序列,基于时间戳滚动
#是否将时间戳向下舍
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = minute
#以下三个和文件的滚动相关,以下三个参数是或的关系!以下三个参数如果值为0都代表禁用!
# 每10秒滚动生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 10
#设置每个文件到128M时滚动
a2.sinks.k1.hdfs.rollSize = 134217700
#每写多少个event滚动一次
a2.sinks.k1.hdfs.rollCount = 0
#五、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a2.sources.r1.channels=c1
a2.sinks.k1.channel=c1
2.2 启动 Agent02
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
[wyr@hadoop102 flume]$ flume-ng agent -c conf/ -n a2 -f myagents/execsource-hdfssink.conf -Dflume.root.logger=info,console
3、Agent03(spoolingdirsource):实时监控多个本机文件的内容,将内容写入到HDFS
3.1 配置文件:spoolingdirsource-hdfssink.conf
- SpoolingDirSource:指定本地磁盘的一个目录为"Spooling(自动收集)"的目录!这个source可以读取目录中新增的文件,将文件的内容封装为event。
- SpoolingDirSource在读取一整个文件到channel之后,它会采取策略,要么删除文件(是否可以删除取决于配置),要么对文件进程一个完成状态的重命名,这样可以保证source持续监控新的文件。
- SpoolingDirSource和execsource不同,SpoolingDirSource是可靠的!即使flume被杀死或重启,依然不丢数据!但是为了保证这个特性,付出的代价是,一旦flume发现以下情况,flume就会报错,停止!
- 一个文件已经被放入目录,在采集文件时,不能被修改(注意:采集完毕后可以修改,但是修改后需要重命名)
- 文件的名在放入目录后又被重新使用(出现了重名的文件)
- 要求: 必须已经封闭的文件才能放入到SpoolingDirSource,在同一个SpoolingDirSource中都不能出现重名的文件!
- 必需配置:
- type – The component type name, needs to be spooldir.
- spoolDir – The directory from which to read files from.
#一、定义Agent中各个组件的名称:a3是agent的名称,a3中定义了一个叫r1的source,如果有多个,使用空格间隔
a3.sources = r1
a3.sinks = k1
a3.channels = c1
#二、配置source:组名名.属性名=属性值
a3.sources.r1.type=spooldir
a3.sources.r1.spoolDir=/home/wyr/flumedir/spooldir
#三、配置chanel:Use a channel which buffers events in memory
a3.channels.c1.type=memory
a3.channels.c1.capacity=1000
#四、配置sink
a3.sinks.k1.type = hdfs
#一旦路径中含有基于时间的转义序列,要求event的header中必须有timestamp=时间戳,如果event的header中必须有timestamp=时间戳,需要设置useLocalTimeStamp = true
a3.sinks.k1.hdfs.path = hdfs://hadoop103:9000/flume/%Y%m%d/%H/%M
#是否使用本地(Agent运行所在的机器)时间戳
a3.sinks.k1.hdfs.useLocalTimeStamp = true
#上传后的文件统一添加的前缀
a3.sinks.k1.hdfs.filePrefix = wyr-spooldir-logs-
#积攒多少个Event才flush到HDFS一次
a3.sinks.k1.hdfs.batchSize = 100
#以不压缩的文本形式保存数据
a3.sinks.k1.hdfs.fileType=DataStream
#以下三个和目录的滚动相关,目录一旦设置了时间转义序列,基于时间戳滚动
#是否将时间戳向下舍
a3.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k1.hdfs.roundUnit = minute
#以下三个和文件的滚动相关,以下三个参数是或的关系!以下三个参数如果值为0都代表禁用!
# 每30秒滚动生成一个新的文件
a3.sinks.k1.hdfs.rollInterval = 30
#设置每个文件到128M时滚动
a3.sinks.k1.hdfs.rollSize = 134217700
#每写多少个event滚动一次
a3.sinks.k1.hdfs.rollCount = 0
#五、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a3.sources.r1.channels=c1
a3.sinks.k1.channel=c1
3.2 启动 Agent03
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
[wyr@hadoop102 flume]$ flume-ng agent -n a3 -c conf/ -f myagents/spoolingdirsource-hdfssink.conf -Dflume.root.logger=info,console
4、Agent04(taildirsource):实时监控多个本机文件的内容,将内容写入到HDFS
4.1 配置文件:taildirsource-loggersink.conf
-
flume ng 1.7版本后提供!
-
常见问题: TailDirSource采集的文件,不能随意重命名!如果日志在正在写入时,名称为 xxxx.tmp,写入完成后,滚动,改名为xxx.log,此时一旦匹配规则可以匹配上述名称,就会发生数据的重复采集!
-
Taildir Source 可以读取多个文件最新追加写入的内容!
-
Taildir Source是可靠的,即使flume出现了故障或挂掉。Taildir Source在工作时,会将读取文件的最后的位置记录在一个json文件中,一旦agent重启,会从之前已经记录的位置,继续执行tail操作!
-
Json文件中,位置是可以修改,修改后,Taildir Source会从修改的位置进行tail操作!如果JSON文件丢失了,此时会重新从每个文件的第一行,重新读取,这会造成数据的重复!
-
Taildir Source目前只能读文本文件!
-
必需配置:
- channels
- type – The component type name, needs to be TAILDIR.
- filegroups – Space-separated list of file groups. Each file group indicates a set of files to be tailed.
- filegroups. – Absolute path of the file group. Regular expression (and not file system patterns) can be used for filename only.
#一、定义Agent中各个组件的名称:a4是agent的名称,a4中定义了一个叫r1的source,如果有多个,使用空格间隔
a4.sources = r1
a4.sinks = k1
a4.channels = c1
#二、配置source:组名名.属性名=属性值
a4.sources.r1.type=taildir
a4.sources.r1.filegroups=f1 f2
a4.sources.r1.filegroups.f1=/home/wyr/flumedir/taildir/test01
a4.sources.r1.filegroups.f2=/home/wyr/flumedir/taildir/test02
#三、配置chanel:Use a channel which buffers events in memory
a4.channels.c1.type=memory
a4.channels.c1.capacity=1000
#四、配置sink
a4.sinks.k1.type=logger
a4.sinks.k1.maxBytesToLog=100
#五、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
a4.sources.r1.channels=c1
a4.sinks.k1.channel=c1
4.2 启动 Agent04
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
flume-ng agent -n a4 -c conf/ -f myagents/taildirsource-loggersink.conf -Dflume.root.logger=info,console
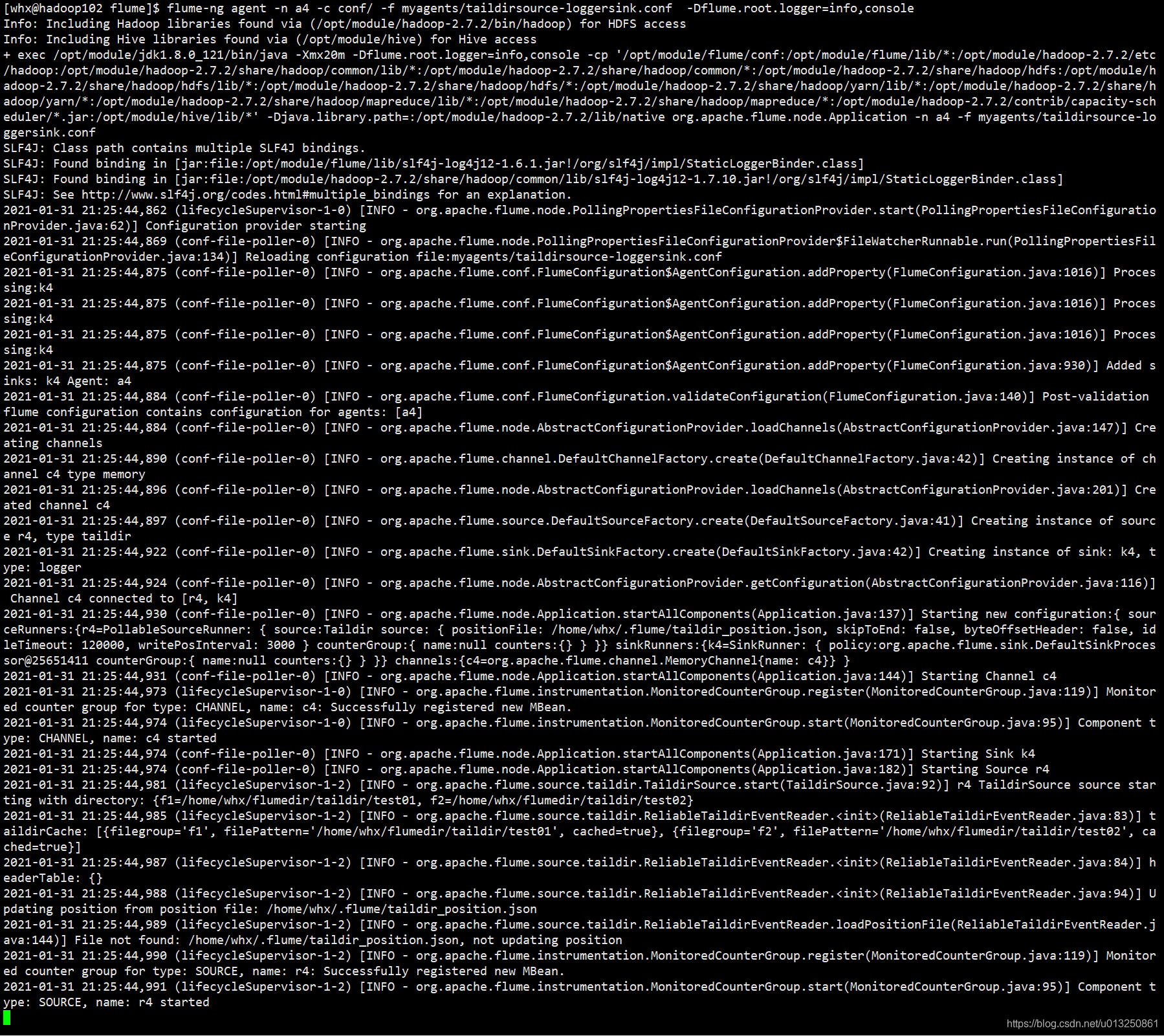
在/home/wyr/flumedir/taildir目录新建test01文件,并输入文字

在/home/wyr/flumedir/taildir目录新建test02文件

在test02中输入第一行文字:this is test02 file 保存

5、Agent05 & Agent06简单串联

5.1 配置文件
5.1.1 Agent05 配置文件:netcatsource-avrosink.conf(在hadoop103服务器上)
#一、定义Agent中各个组件的名称:a5是agent的名称,a5中定义了一个叫r1的source,如果有多个,使用空格间隔
# r1:表示a5的Source的名称
a5.sources = r1
# k1:表示a5的Sink的名称
a5.sinks = k1
# c1:表示a5的Channel的名称
a5.channels = c1
#二、配置source:组名名.属性名=属性值
# 表示a5的输入源类型为netcat端口类型
a5.sources.r1.type=netcat
# 表示a5的监听的主机
a5.sources.r1.bind=hadoop103
# 表示a5的监听的端口号
a5.sources.r1.port=44444
#三、配置chanel:Use a channel which buffers events in memory
# 表示a5的channel类型是memory内存型
a5.channels.c1.type=memory
# 表示a5的channel总容量10000个event
a5.channels.c1.capacity=1000
# 表示a5的channel传输时收集到了1000条event以后再去提交事务
#a5.channels.c1.transactionCapacity = 1000
#四、配置sink
# 表示a5将event序列化之后传给另一个sink
a5.sinks.k1.type=avro
# 规定sink数据接收主机
a5.sinks.k1.hostname=hadoop102
# 规定sink数据接收端口
a5.sinks.k1.port=33333
#五、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
# 表示将r1和c1连接起来
a5.sources.r1.channels=c1
# 表示将k1和c1连接起来
a5.sinks.k1.channel=c1
5.1.2 Agent06 配置文件:avrosource-loggersink.conf(在hadoop102服务器上)
#一、定义Agent中各个组件的名称:a6是agent的名称,a6中定义了一个叫r1的source,如果有多个,使用空格间隔
# r1:表示a6的Source的名称
a6.sources = r1
# k1:表示a6的Sink的名称
a6.sinks = k1
# c1:表示a6的Channel的名称
a6.channels = c1
#二、配置source:组名名.属性名=属性值
# 表示a6的输入源类型为avro序列化event
a6.sources.r1.type=avro
# 表示a6的监听的主机
a6.sources.r1.bind=hadoop102
# 表示a6的监听的端口号
a6.sources.r1.port=33333
#三、配置chanel:Use a channel which buffers events in memory
# 表示a6的channel类型是memory内存型
a6.channels.c1.type=memory
# 表示a6的channel总容量10000个event
a6.channels.c1.capacity=1000
# 表示a6的channel传输时收集到了1000条event以后再去提交事务
#a6.channels.c1.transactionCapacity = 1000
#四、配置sink
# 表示a6的输出目的地是控制台logger类型
a6.sinks.k1.type=logger
#五、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
# 表示将r1和c1连接起来
a6.sources.r1.channels=c1
# 表示将k1和c1连接起来
a6.sinks.k1.channel=c1
5.2 启动 Agent
5.2.1 先在hadoop102上启动Agent6
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
flume-ng agent -n a6 -c conf/ -f myagents/avrosource-loggersink.conf -Dflume.root.logger=info,console
5.2.2 在hadoop103上启动Agent5
flume-ng agent -n a5 -c conf/ -f myagents/netcatsource-avrosink.conf -Dflume.root.logger=info,console
5.3 测试 Agent
在hadoop01服务器上输入:
[wyr@hadoop103 ~]$ nc hadoop103 44444
hello0000
OK
hello1111
OK
heoo^H^Hu^H^[[D
OK
hello3333
OK
在hadoop02服务器上收到:
2021-01-31 22:19:10,003 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 68 65 6C 6C 6F 30 30 30 30 hello0000 }
2021-01-31 22:19:14,005 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 68 65 6C 6C 6F 31 31 31 31 hello1111 }
2021-01-31 22:19:36,011 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 68 65 6F 6F 08 08 75 08 1B 5B 44 heoo..u..[D }
2021-01-31 22:19:36,085 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 68 65 6C 6C 6F 33 33 33 33 hello3333 }
6、Channel选择器:单数据源多出口案例(复制和多路复用)
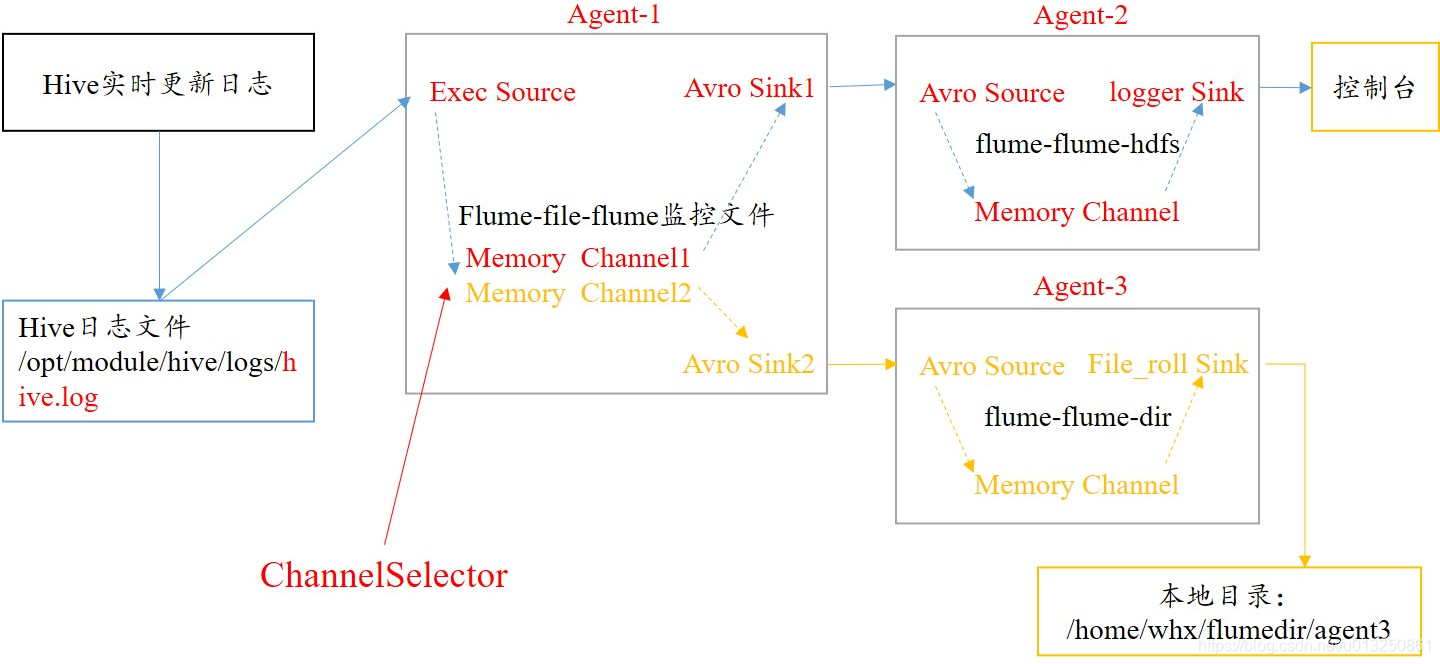
6.1 Replicating channel选择器
- Replicating Channel Selector:复制的channel选择器,也是默认的选择器!当一个source使用此选择器选择多个channel时,source会将event在每个channel都复制一份!
- 可选的channel: 向可选的channel写入event时,即便发生异常,也会忽略!
- File Roll Sink:存储event到本地文件系统!
- 必需配置:
- type – The component type name, needs to be file_roll.
- sink.directory – The directory where files will be stored
- 必需配置:
6.1.1 Agent01 配置文件:agent01-execsource-avrosink-replicating.conf(在hadoop103服务器上)
#一、定义Agent中各个组件的名称:agent01是agent的名称,
#agent01中定义了一个叫r1的source
agent01.sources = r1
#agent01定义了2个sink,如果有多个,使用空格间隔;
agent01.sinks = k1 k2
#agent01定义了2个channel,如果有多个,使用空格间隔;
agent01.channels = c1 c2
#二、配置source:组名名.属性名=属性值
agent01.sources.r1.type=exec
agent01.sources.r1.command=tail -f /home/wyr/flumedir/exectest.txt
#三、配置r1的channel选择器
agent01.sources.r1.selector.type = replicating
#四、配置chanel
agent01.channels.c1.type=memory
agent01.channels.c1.capacity=1000
agent01.channels.c2.type=memory
agent01.channels.c2.capacity=1000
#五、配置sink
agent01.sinks.k1.type=avro
agent01.sinks.k1.hostname=hadoop102
agent01.sinks.k1.port=22222
agent01.sinks.k2.type=avro
agent01.sinks.k2.hostname=hadoop104
agent01.sinks.k2.port=33333
#六、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent01.sources.r1.channels=c1 c2
agent01.sinks.k1.channel=c1
agent01.sinks.k2.channel=c2
6.1.2 Agent02 配置文件:agent02-avrosource-loggersink-replicating.conf(在hadoop102服务器上)
#一、定义Agent中各个组件的名称:agent02是agent的名称
#agent02中定义了一个叫r1的source,如果有多个,使用空格间隔
agent02.sources = r1
# k1:表示agent02的Sink的名称
agent02.sinks = k1
# c1:表示agent02的Channel的名称
agent02.channels = c1
#二、配置source:组名名.属性名=属性值
agent02.sources.r1.type=avro
agent02.sources.r1.bind=hadoop102
agent02.sources.r1.port=22222
#三、配置chanel
agent02.channels.c1.type=memory
agent02.channels.c1.capacity=1000
#四、配置sink
agent02.sinks.k1.type=logger
#五、连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent02.sources.r1.channels=c1
agent02.sinks.k1.channel=c1
6.1.3 Agent-3 配置文件:agent03-avrosource-filerollsink-replicating.conf(在hadoop104服务器上)
#一、定义Agent中各个组件的名称:agent03是agent的名称
#agent03中定义了一个叫r1的source,如果有多个,使用空格间隔
agent03.sources = r1
# k1:表示agent03的Sink的名称
agent03.sinks = k1
# c1:表示agent03的Channel的名称
agent03.channels = c1
#二、配置source:组名名.属性名=属性值
agent03.sources.r1.type=avro
agent03.sources.r1.bind=hadoop104
agent03.sources.r1.port=33333
#三、配置chanel
agent03.channels.c1.type=memory
agent03.channels.c1.capacity=1000
#四、配置sink
agent03.sinks.k1.type=file_roll
agent03.sinks.k1.sink.directory=/home/wyr/flumedir/agent3
#五、连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent03.sources.r1.channels=c1
agent03.sinks.k1.channel=c1
6.1.4 启动 Agent并测试
先在hadoop104上启动Agent03
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
[wyr@hadoop104 flume]$ flume-ng agent -n agent03 -c conf/ -f myagents/agent03-avrosource-filerollsink-replicating.conf -Dflume.root.logger=info,console
在hadoop102上启动Agent02
[wyr@hadoop102 flume]$ flume-ng agent -n agent02 -c conf/ -f myagents/agent02-avrosource-loggersink-replicating.conf -Dflume.root.logger=info,console
最后在hadoop102上启动Agent01
[wyr@hadoop103 flume]$ flume-ng agent -n agent01 -c conf/ -f myagents/agent01-execsource-avrosink-replicating.conf -Dflume.root.logger=info,console
测试 Agent:在hadoop01服务器/home/wyr/flumedir/execdir目录下创建文件test01
6.2 MultiPlexing channel选择器
Multiplexing Channel Selector根据evnet header中属性,参考用户自己配置的映射信息,将event发送到指定的channel!
6.2.1 Agent01 配置文件:agent01-execsource-avrosink-multiplexing.conf(在hadoop103服务器上)
#一、定义Agent中各个组件的名称:agent01是agent的名称,
#agent01中定义了一个叫r1的source
agent01.sources = r1
#agent01定义了2个sink,如果有多个,使用空格间隔;
agent01.sinks = k1 k2
#agent01定义了2个channel,如果有多个,使用空格间隔;
agent01.channels = c1 c2
#二、配置source:组名名.属性名=属性值
agent01.sources.r1.type=exec
agent01.sources.r1.command=tail -f /home/wyr/flumedir/exectest.txt
#三、配置r1的channel选择器
agent01.sources.r1.selector.type = multiplexing
agent01.sources.r1.selector.header = state
agent01.sources.r1.selector.mapping.CZ = c1
agent01.sources.r1.selector.mapping.US = c2
#使用拦截器为event加上某个header:模拟source中带有不同key-value的数据
agent01.sources.r1.interceptors = i1
agent01.sources.r1.interceptors.i1.type = static
agent01.sources.r1.interceptors.i1.key = state
agent01.sources.r1.interceptors.i1.value = CZ
#四、配置chanel
agent01.channels.c1.type=memory
agent01.channels.c1.capacity=1000
agent01.channels.c2.type=memory
agent01.channels.c2.capacity=1000
#五、配置sink
agent01.sinks.k1.type=avro
agent01.sinks.k1.hostname=hadoop102
agent01.sinks.k1.port=22222
agent01.sinks.k2.type=avro
agent01.sinks.k2.hostname=hadoop104
agent01.sinks.k2.port=33333
#六、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent01.sources.r1.channels=c1 c2
agent01.sinks.k1.channel=c1
agent01.sinks.k2.channel=c2
6.2.2 Agent02 配置文件:agent02-avrosource-loggersink-multiplexing.conf(在hadoop102服务器上)
#一、定义Agent中各个组件的名称:agent02是agent的名称
#agent02中定义了一个叫r1的source,如果有多个,使用空格间隔
agent02.sources = r1
# k1:表示agent02的Sink的名称
agent02.sinks = k1
# c1:表示agent02的Channel的名称
agent02.channels = c1
#二、配置source:组名名.属性名=属性值
agent02.sources.r1.type=avro
agent02.sources.r1.bind=hadoop102
agent02.sources.r1.port=22222
#三、配置chanel
agent02.channels.c1.type=memory
agent02.channels.c1.capacity=1000
#四、配置sink
agent02.sinks.k1.type=logger
#五、连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent02.sources.r1.channels=c1
agent02.sinks.k1.channel=c1
6.2.3 Agent-3 配置文件:agent03-avrosource-loggersink-multiplexing.conf(在hadoop104服务器上)
#一、定义Agent中各个组件的名称:agent03是agent的名称
#agent03中定义了一个叫r1的source,如果有多个,使用空格间隔
agent03.sources = r1
# k1:表示agent03的Sink的名称
agent03.sinks = k1
# c1:表示agent03的Channel的名称
agent03.channels = c1
#二、配置source:组名名.属性名=属性值
agent03.sources.r1.type=avro
agent03.sources.r1.bind=hadoop104
agent03.sources.r1.port=33333
#三、配置chanel
agent03.channels.c1.type=memory
agent03.channels.c1.capacity=1000
#四、配置sink
agent03.sinks.k1.type=logger
#五、连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent03.sources.r1.channels=c1
agent03.sinks.k1.channel=c1
6.2.4 启动 Agent 并测试
先在hadoop104上启动Agent03
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
[wyr@hadoop104 flume]$ flume-ng agent -n agent03 -c conf/ -f myagents/agent03-avrosource-loggersink-multiplexing.conf -Dflume.root.logger=info,console
在hadoop102上启动Agent02
[wyr@hadoop102 flume]$ flume-ng agent -n agent02 -c conf/ -f myagents/agent02-avrosource-loggersink-multiplexing.conf -Dflume.root.logger=info,console
最后在hadoop102上启动Agent01
[wyr@hadoop103 flume]$ flume-ng agent -n agent01 -c conf/ -f myagents/agent01-execsource-avrosink-multiplexing.conf -Dflume.root.logger=info,console
测试 Agent:在hadoop01服务器/home/wyr/flumedir/execdir目录下创建文件test01
7、Sink处理器:负载均衡和故障转移
7.1 Sink Processor类型
7.1.1 Default Sink Processor
- 如果agent中,只有一个sink,默认就使用Default Sink Processor,这个sink processor是不强制用户将sink组成一个组!
- 如果有多个sink,多个sink对接一个channel,不能选择Default Sink Processor
7.1.2 Failover Sink Processor
- Failover Sink Processor维护了一个多个sink的有优先级的列表,按照优先级保证,至少有一个sink是可以干活的!
- 如果根据优先级发现,优先级高的sink故障了,故障的sink会被转移到一个故障的池中冷却!
- 在冷却时,故障的sink也会不管尝试发送event,一旦发送成功,此时会将故障的sink再移动到存活的池中!
- 必需配置:
- sinks – Space-separated list of sinks that are participating in the group
- processor.type default The component type name, needs to be failover
- processor.priority. – Priority value. must be one of the sink instances associated with the current sink group A higher priority value Sink gets activated earlier. A larger absolute value indicates higher priority
7.1.3 Load Balancing Sink Processor
- 负载均衡的sink processor! Load balancing Sink Processor维持了sink组中active状态的sink!
- 使用round_robin 或 random 算法,来分散sink组中存活的sink之间的负载!
- 必需配置:
- processor.sinks – Space-separated list of sinks that are participating in the group
- processor.type default The component type name, needs to be load_balance
7.2 配置文件
7.2.1 Agent01 配置文件:agent01-execsource-avrosink-sinkprocessor.conf(在hadoop103服务器上)
#一、定义Agent中各个组件的名称:agent01是agent的名称,
#agent01中定义了一个叫r1的source
agent01.sources = r1
#agent01定义了2个sink,如果有多个,使用空格间隔;
agent01.sinks = k1 k2
#agent01定义了1个channel,如果有多个,使用空格间隔;
agent01.channels = c1
#二、配置source:组名名.属性名=属性值
agent01.sources.r1.type=exec
agent01.sources.r1.command=tail -f /home/wyr/flumedir/exectest.txt
#三、配置chanel
agent01.channels.c1.type=memory
agent01.channels.c1.capacity=1000
#四、配置sink processor
agent01.sinkgroups = g1
agent01.sinkgroups.g1.sinks = k1 k2
agent01.sinkgroups.g1.processor.sinks=k1 k2
#Load Balancing Sink Processor
agent01.sinkgroups.g1.processor.type = load_balance
#Failover Sink Processor
#agent01.sinkgroups.g1.processor.type = failover
#agent01.sinkgroups.g1.processor.priority.k1=100
#agent01.sinkgroups.g1.processor.priority.k2=90
#五、配置sink
agent01.sinks.k1.type=avro
agent01.sinks.k1.hostname=hadoop102
agent01.sinks.k1.port=22222
agent01.sinks.k2.type=avro
agent01.sinks.k2.hostname=hadoop104
agent01.sinks.k2.port=33333
#六、连接组件:同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent01.sources.r1.channels=c1
agent01.sinks.k1.channel=c1
agent01.sinks.k2.channel=c1
7.2.2 Agent02 配置文件:agent02-avrosource-loggersink-sinkprocessor.conf(在hadoop102服务器上)
#一、定义Agent中各个组件的名称:agent02是agent的名称
#agent02中定义了一个叫r1的source,如果有多个,使用空格间隔
agent02.sources = r1
# k1:表示agent02的Sink的名称
agent02.sinks = k1
# c1:表示agent02的Channel的名称
agent02.channels = c1
#二、配置source:组名名.属性名=属性值
agent02.sources.r1.type=avro
agent02.sources.r1.bind=hadoop102
agent02.sources.r1.port=22222
#三、配置chanel
agent02.channels.c1.type=memory
agent02.channels.c1.capacity=1000
#四、配置sink
agent02.sinks.k1.type=logger
#五、连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent02.sources.r1.channels=c1
agent02.sinks.k1.channel=c1
7.2.3 Agent-3 配置文件:agent03-avrosource-loggersink-sinkprocessor.conf(在hadoop104服务器上)
#一、定义Agent中各个组件的名称:agent03是agent的名称
#agent03中定义了一个叫r1的source,如果有多个,使用空格间隔
agent03.sources = r1
# k1:表示agent03的Sink的名称
agent03.sinks = k1
# c1:表示agent03的Channel的名称
agent03.channels = c1
#二、配置source:组名名.属性名=属性值
agent03.sources.r1.type=avro
agent03.sources.r1.bind=hadoop104
agent03.sources.r1.port=33333
#三、配置chanel
agent03.channels.c1.type=memory
agent03.channels.c1.capacity=1000
#四、配置sink
agent03.sinks.k1.type=logger
#五、连接组件 同一个source可以对接多个channel,一个sink只能从一个channel拿数据!
agent03.sources.r1.channels=c1
agent03.sinks.k1.channel=c1
7.2.4 启动 Agent 并测试
先在hadoop104上启动Agent03
flume-ng agent -c 其他配置文件所在的目录 -n agent的名称 -f agent配置文件 -Dproperty=value -Dflume.root.logger=info,console
[wyr@hadoop104 flume]$ flume-ng agent -n agent03 -c conf/ -f myagents/agent03-avrosource-loggersink-sinkprocessor.conf -Dflume.root.logger=info,console
在hadoop102上启动Agent02
[wyr@hadoop102 flume]$ flume-ng agent -n agent02 -c conf/ -f myagents/agent02-avrosource-loggersink-sinkprocessor.conf -Dflume.root.logger=info,console
最后在hadoop102上启动Agent01
[wyr@hadoop103 flume]$ flume-ng agent -n agent01 -c conf/ -f myagents/agent01-execsource-avrosink-sinkprocessor.conf -Dflume.root.logger=info,console
测试 Agent:在hadoop01服务器/home/wyr/flumedir/execdir目录下创建文件test01
四、Flume对接Kafka
1、Agent 配置文件:netcatsource-kafkasink.conf(在hadoop102服务器上)
agentkafka.sources = r1
agentkafka.sinks = k1
agentkafka.channels = c1
# 配置source
agentkafka.sources.r1.type = netcat
agentkafka.sources.r1.bind = hadoop102
agentkafka.sources.r1.port = 22222
# 配置channel
agentkafka.channels.c1.type = memory
agentkafka.channels.c1.capacity = 1000
# 配置sink
agentkafka.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agentkafka.sinks.k1.kafka.bootstrap.servers=hadoop103:9092,hadoop102:9092,hadoop104:9092
agentkafka.sinks.k1.kafka.topic=wyrflumekafkatopic01
#将flume 每个event中的body的内容直接写到kafka
agentkafka.sinks.k1.useFlumeEventFormat=false
# 绑定和连接组件
agentkafka.sources.r1.channels = c1
agentkafka.sinks.k1.channel = c1
启动 Flume 的 Agent
[wyr@hadoop102 flume]$ flume-ng agent -n agentkafka -c conf/ -f myagents/netcatsource-kafkasink.conf -Dflume.root.logger=info,console
在hadoop102机器上向hadoop102服务器的22222端口发送信息
[wyr@hadoop102 ~]$ nc hadoop102 22222
hello kafka
OK
在hadoop104机器上Kafka消费数据
[wyr@hadoop104 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop104:9092 --topic wyrflumekafkatopic01 --from-beginning
hello kafka
2、Agent 配置文件:netcatsource-kafkasink-interceptor.conf(在hadoop102服务器上)
agentkafka.sources = r1
agentkafka.sinks = k1
agentkafka.channels = c1
# 配置source
agentkafka.sources.r1.type = netcat
agentkafka.sources.r1.bind = hadoop102
agentkafka.sources.r1.port = 22222
# 配置拦截器
agentkafka.sources.r1.interceptors = i1 i2
agentkafka.sources.r1.interceptors.i1.type = static
agentkafka.sources.r1.interceptors.i1.key = topic
agentkafka.sources.r1.interceptors.i1.value = hello
agentkafka.sources.r1.interceptors.i2.type = static
agentkafka.sources.r1.interceptors.i2.key = key
agentkafka.sources.r1.interceptors.i2.value = 1
# 配置channel
agentkafka.channels.c1.type = memory
agentkafka.channels.c1.capacity = 1000
# 配置sink
agentkafka.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agentkafka.sinks.k1.kafka.bootstrap.servers=hadoop103:9092,hadoop102:9092,hadoop104:9092
agentkafka.sinks.k1.kafka.topic=wyrflumekafkatopic02
agentkafka.sinks.k1.useFlumeEventFormat=true
# 绑定和连接组件
agentkafka.sources.r1.channels = c1
agentkafka.sinks.k1.channel = c1
启动 Flume 的 Agent
[wyr@hadoop102 flume]$ flume-ng agent -n agentkafka -c conf/ -f myagents/netcatsource-kafkasink-interceptor.conf -Dflume.root.logger=info,console
在hadoop102机器上向hadoop102服务器的22222端口发送信息
[wyr@hadoop102 ~]$ nc hadoop102 22222
hello kafka
OK
在hadoop104机器上Kafka消费数据
[wyr@hadoop104 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop104:9092 --topic wyrflumekafkatopic02 --from-beginning
hello kafka
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范