CUDA入门学习(三):共享内存与线程同步_cuda 向量点乘-程序员宅基地
技术标签: CUDA
共享内存实际上是可受用户控制的一级缓存。每个SM中的一级缓存与共享内存共享一个64KB的内存段在开普勒架构的设备中,根据应用程序的需要,每个线程块可以配置为16KB的一级缓存或共享内存。而在费米架构的设备中,可以根据喜好选择16KB或者48KB的一级缓存或者共享内存。早期费米架构中只有固定的16KB共享内存而没有一级缓存。共享内存的延迟极低,大约有1.5TB/s的带宽,远远高于全局内存的190GB/s,但是它的速度只有寄存器的十分之一。只有当数据重复利用,全局内存合并,或线程之间由数据共享时使用共享内存才更合适,否则,数据直接从全局内存加载到寄存器性能会更好。申请共享内存后,其内容在每一个用到的block被复制一遍,使得在每个block内,每一个thread都可以访问和操作这块内存,而无法访问其他block内的共享内存。这种机制就使得一个block之内的所有线程可以互相交流和合作。
共享内存是基于存储体切换的架构(bank-switched architecture)。无论有多少个线程发起操作,每个存储体每个周期只执行一次操作。因此,如果线程束中的每个线程访问一个存储体,那么所有的线程操作都可以在一个周期内同时执行。此时无须顺序地访问,因为每个线程访问的存储体在共享内存中都是独立的,互不影响。此外,如果线程束中的所有线程同时访问相同地址的存储体时,就会想常量内存一样触发一个广播机制到线程束中的每一个线程。然而如果有其他的访问方式,存储体冲突将不同程度地得到解决。这意味着,线程访问共享内存需要排队等候,当一个线程访问时,其它线程都将阻塞。因此储存体应尽可能避免冲突。
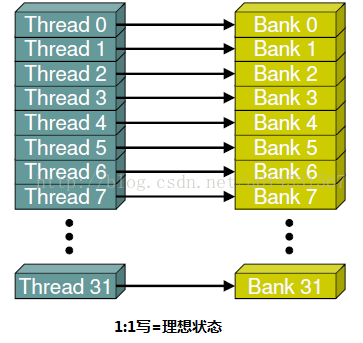
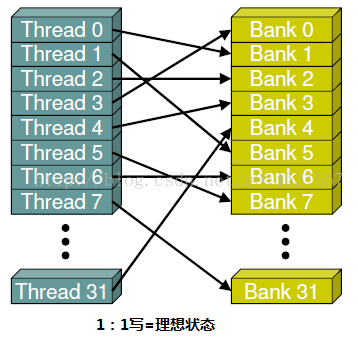
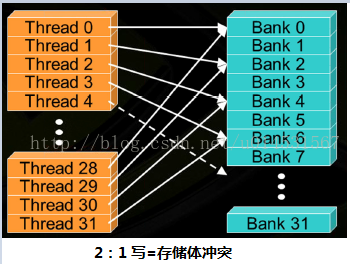
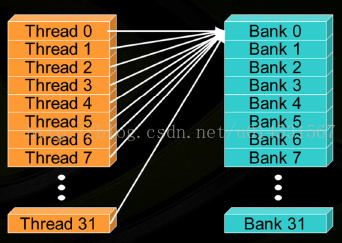
这里有必要对第四张图说明下。所有线程访问同一存储体,如果是读的话会触发广播机制,但是如果是写的话会冲突,这将导致对同一存储体顺序进行32次访问操作,这里注意箭头朝向,该图是参考博文https://segmentfault.com/a/1190000007533157,但是可能博主没考虑到读写的区别吧,如有问题,欢迎指正修改。
我们来看个向量点乘的例子吧。
#include "../common/book.h"
#define imin(a,b) (a<b?a:b)
const int N = 33 * 1024;
const int threadsPerBlock = 256;
const int blocksPerGrid =
imin( 32, (N+threadsPerBlock-1) / threadsPerBlock );
__global__ void dot( float *a, float *b, float *c ) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// set the cache values
cache[cacheIndex] = temp;
// synchronize threads in this block
__syncthreads();
// for reductions, threadsPerBlock must be a power of 2
// because of the following code
int i = blockDim.x/2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
int main( void ) {
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
// allocate memory on the cpu side
a = (float*)malloc( N*sizeof(float) );
b = (float*)malloc( N*sizeof(float) );
partial_c = (float*)malloc( blocksPerGrid*sizeof(float) );
// allocate the memory on the GPU
HANDLE_ERROR( cudaMalloc( (void**)&dev_a,
N*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_b,
N*sizeof(float) ) );
HANDLE_ERROR( cudaMalloc( (void**)&dev_partial_c,
blocksPerGrid*sizeof(float) ) );
// fill in the host memory with data
for (int i=0; i<N; i++) {
a[i] = i;
b[i] = i*2;
}
// copy the arrays 'a' and 'b' to the GPU
HANDLE_ERROR( cudaMemcpy( dev_a, a, N*sizeof(float),
cudaMemcpyHostToDevice ) );
HANDLE_ERROR( cudaMemcpy( dev_b, b, N*sizeof(float),
cudaMemcpyHostToDevice ) );
dot<<<blocksPerGrid,threadsPerBlock>>>( dev_a, dev_b,
dev_partial_c );
// copy the array 'c' back from the GPU to the CPU
HANDLE_ERROR( cudaMemcpy( partial_c, dev_partial_c,
blocksPerGrid*sizeof(float),
cudaMemcpyDeviceToHost ) );
// finish up on the CPU side
c = 0;
for (int i=0; i<blocksPerGrid; i++) {
c += partial_c[i];
}
#define sum_squares(x) (x*(x+1)*(2*x+1)/6)
printf( "Does GPU value %.6g = %.6g?\n", c,
2 * sum_squares( (float)(N - 1) ) );
// free memory on the gpu side
HANDLE_ERROR( cudaFree( dev_a ) );
HANDLE_ERROR( cudaFree( dev_b ) );
HANDLE_ERROR( cudaFree( dev_partial_c ) );
// free memory on the cpu side
free( a );
free( b );
free( partial_c );
}主函数中的CUDA 内存申请,拷贝,释放我们就不具体介绍了,我们看核函数中的__shared__ float cache[threadsPerBlock] 这里的__shared__同样是CUDA中的关键字,和__global__一样,意思是申请一个共享内存,这里申请的大小为每个线程块的线程数目,这样每个线程都可以访问一个存储体,不会造成存储体冲突。并且会为每一个线程块分配相同大小的共享内存。这样我们就可以计算每个线程块的向量点乘之和,但是这里有个潜在的危险,如下图所示,如果一部分线程已经计算好了,另一部分还没,那么相加的结果肯定是错的。所以我们需要一个同步机制来保证每个线程块都计算好了,这里就用到了__syncthreads();


总结:本次主要介绍了块内线程如何通过共享内存进行协作,除了线程级通信之外,我们之后还将学校线程块之间的通信。
参考: [1]CUDA并行程序设计 —— GPU编程指南
[2] Addison.Wesley.CUDA.By.Example.Jul.2010.ISBN.0131387685
[3]https://segmentfault.com/a/1190000007533157
智能推荐
2023年12.12更新:最新使用cookie自动登录京东并爬取京东网址图书信息python源码!_京东cookie自动登录-程序员宅基地
文章浏览阅读2k次,点赞21次,收藏21次。感谢朋友们阅读,下期再见!!!_京东cookie自动登录
qsub作业一直在排队状态_一些“基本”作业仍在排队中以实现自动化-程序员宅基地
文章浏览阅读1.1k次。qsub作业一直在排队状态The pandemic may speed up job replacement. 大流行可能会加快工作更换速度。 Before Covid-19 swept through America, low-wage workers and activists were battling in the states to raise the minimum wage, of..._qq作业上传视频总在排队中
Hadoop云计算之SSH协议简单介绍-程序员宅基地
文章浏览阅读202次。2019独角兽企业重金招聘Python工程师标准>>> ..._hadoop. 中的ssh 有哪些特点?
java build-id是什么_Java Build.BOOTLOADER属性代码示例-程序员宅基地
文章浏览阅读372次。public String getDeviceInfo() {return "\n" +"Brand:" +Build.BRAND +"\n" +"Manufacturer:" +Build.MANUFACTURER +"\n" +"Product:" +Build.PRODUCT +"\n" +"Board:" +Build.BOARD +"\n" +"Bootloader:" +Build.B..._build.bootloader
计算机改了域名后无法共享,计算机的工作组名或域名、计算机名等区分计算机特征的配置不得随意修改,但可以自 - 问答库...-程序员宅基地
文章浏览阅读102次。问题:[判断题] 计算机的工作组名或域名、计算机名等区分计算机特征的配置不得随意修改,但可以自行修改计算机的IP地址。()A . 正确B . 错误工商专网为非涉密网,与政务内网实现数据共享,可以直接相连。() 正确。 错误。上官夫妇目前均刚过35岁,打算20年后即55岁时退休,估计夫妇俩退休后第一年的生活费用为8万元(退休后每年初从退休金中取出当年的生活费用)。考虑到通货膨胀的因素,夫妇俩每年的..._域名能否替代计算机名
input的placeholder设置字体颜色_input中placeholder的字体颜色-程序员宅基地
文章浏览阅读474次。具体的写法::-moz-placeholder { /* Mozilla Firefox 4 to 18 */ color: #fff; font-size: 0.56rem;opacity: 0.8;}::-moz-placeholder { /* Mozilla Firefox 19+ */ color: #fff; font-size: 0.56rem_input中placeholder的字体颜色
随便推点
永不磨灭的设计模式(有这一篇真够了,拒绝标题党)-程序员宅基地
文章浏览阅读2.3w次,点赞141次,收藏912次。在IT这个行业,技术日新月异。有可能你今年刚弄懂一个编程框架,明年它就不流行了,无怪乎有些无节操的IT从业人员去GitBub上用汉语提Issue:“求你别更新了,实在学不动了”。对于这种行为我只能说,太jb不要脸了…然而即使在易变的IT世界也有很多几乎不变的知识,他们晦涩而重要,默默的将程序员划分...._永不磨灭的设计模式
栈与C++中的std::stack详解(多图超详细)_stack出栈-程序员宅基地
文章浏览阅读874次。栈(stack)什么是栈?栈的基本操作和应用入栈(push)出栈(pop)入栈和出栈的复杂度和应用场景类模板std::satck形参T和Container成员函数元素访问栈的容量栈的修改用法示例_stack出栈
R ggplot2 图例-改图例背景颜色、大小_ggplot改变图例形状大小-程序员宅基地
文章浏览阅读4.4w次,点赞31次,收藏132次。改 图例背景颜色改 图例大小改 图例符号颜色第一部分1.1 图例背景颜色1.2 代码和语法base + theme( legend.background = element_rect( fill = "lightblue", #填充色 colour = "black", #框线色 size = 1.5 ) ) #线条宽度语法在theme主题系统..._ggplot改变图例形状大小
python读取文件夹内容(os.listdir()方法)_files = os.listdir-程序员宅基地
文章浏览阅读1.1w次,点赞7次,收藏19次。python os.listdir() 方法一般用于导出指定路径下的文件或文件夹目录。当输入的“要打开”的是文件夹(直接是文件夹的名字,没有后缀),获得的是文件夹中的文件名称列表(按字母表顺序排序)代码:import os path = 'C:\\Users\\DELL\\Desktop\\hello' #打开桌面位置处的文件夹hello,注意格式\\result=os.listdi..._files = os.listdir
win10快速访问的文件夹无法删除的解决方法_automaticdestinations文件夹里的文件删不掉-程序员宅基地
文章浏览阅读2.5w次,点赞23次,收藏17次。最近遇到快速访问的文件夹右键无法取消固定,不管怎么试都删不掉,最后我尝试了把快速访问恢复默认,解决了这个问题具体方法:找到快速访问的存储目录是这里,大家可以应对自己所用环境修改用户名:C:\Users\用户名\AppData\Roaming\Microsoft\Windows\Recent\AutomaticDestinations删除路径中的所有文件,快速访问就会重置到最初的状态!在..._automaticdestinations文件夹里的文件删不掉
基于vue.js宠物医院挂号系统设计与实现(uni-app框架+PHP后台) 研究背景和意义、国内外现状_宠物挂号系统 php-程序员宅基地
文章浏览阅读2.3k次,点赞18次,收藏17次。基于vue.js宠物医院挂号系统设计与实现(uni-app框架+PHP后台) 研究背景和意义、国内外现状主人的满意度和宠物的健康至关重要。因此,开发一套基于vue.js的宠物医院挂号系统,利用uni-app框架和PHP后台,能够提供方便快捷的预约挂号服务,改善宠物医疗服务的质量和用户体验,具有重要的研究意义和实际应用价值。因此,研究开发一套基于vue.js的宠物医院挂号系统,能够填补国内外研究空白,提升宠物医疗服务的质量和用户体验,具有重要的研究意义和实际应用价值。专注大学生毕业设计教育和辅导。_宠物挂号系统 php