HashTable实现原理-程序员宅基地
技术标签: collection
有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相对应的value值。一个是前面提到的HashMap,还有一个就是马上要讲解的HashTable。对于HashTable而言,它在很大程度上和HashMap的实现差不多,如果我们对HashMap比较了解的话,对HashTable的认知会提高很大的帮助。他们两者之间只存在几点的不同,这个后面会阐述。
1.定义
HashTable在Java中的定义如下:
-
public class Hashtable<K,V>
-
extends Dictionary< K, V>
-
implements Map< K, V>, Cloneable, java. io. Serializable
从中可以看出HashTable继承Dictionary类,实现Map接口。其中Dictionary类是任何可将键映射到相应值的类(如 Hashtable)的抽象父类。每个键和每个值都是一个对象。在任何一个 Dictionary 对象中,每个键至多与一个值相关联。Map是"key-value键值对"接口。
HashTable采用"拉链法"实现哈希表,它定义了几个重要的参数:table、count、threshold、loadFactor、modCount。
table:为一个Entry[]数组类型,Entry代表了“拉链”的节点,每一个Entry代表了一个键值对,哈希表的"key-value键值对"都是存储在Entry数组中的。
count:HashTable的大小,注意这个大小并不是HashTable的容器大小,而是他所包含Entry键值对的数量。
threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor:加载因子。
modCount:用来实现“fail-fast”机制的(也就是快速失败)。所谓快速失败就是在并发集合中,其进行迭代操作时,若有其他线程对其进行结构性的修改,这时迭代器会立马感知到,并且立即抛出ConcurrentModificationException异常,而不是等到迭代完成之后才告诉你(你已经出错了)
2.构造方法
在HashTabel中存在5个构造函数。通过这5个构造函数我们构建出一个我想要的HashTable。
1.默认构造函数,容量为11,加载因子为0.75:
-
1. public Hashtable() {
-
2. this( 11, 0.75f);
-
3. }
2.用指定初始容量和默认的加载因子 (0.75) 构造一个新的空哈希表:
-
1. public Hashtable(int initialCapacity) {
-
2. this(initialCapacity, 0.75f);
-
3. }
3.用指定初始容量和指定加载因子构造一个新的空哈希表。其中initHashSeedAsNeeded方法用于初始化hashSeed参数,其中hashSeed用于计算key的hash值,它与key的hashCode进行按位异或运算。这个hashSeed是一个与实例相关的随机值,主要用于解决hash冲突:
-
1. public Hashtable(int initialCapacity, float loadFactor) {
-
2. //验证初始容量
-
3. if (initialCapacity < 0)
-
4. throw new IllegalArgumentException( "Illegal Capacity: "+
-
5. initialCapacity);
-
6. //验证加载因子
-
7. if (loadFactor <= 0 || Float.isNaN(loadFactor))
-
8. throw new IllegalArgumentException( "Illegal Load: "+loadFactor);
-
9.
-
10. if (initialCapacity== 0)
-
11. initialCapacity = 1;
-
12.
-
13. this.loadFactor = loadFactor;
-
14.
-
15. //初始化table,获得大小为initialCapacity的table数组
-
16. table = new Entry[initialCapacity];
-
17. //计算阀值
-
18. threshold = ( int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
-
19. //初始化HashSeed值
-
20. initHashSeedAsNeeded(initialCapacity);
-
21. }
-
-
-
1. private int hash(Object k) {
-
2. return hashSeed ^ k.hashCode();
-
3. }
4.构造一个与给定的 Map 具有相同映射关系的新哈希表:
-
1. public Hashtable(Map<? extends K, ? extends V> t) {
-
2. //设置table容器大小,其值==t.size * 2 + 1
-
3. this(Math.max( 2*t.size(), 11), 0.75f);
-
4. putAll(t);
-
}
3.主要方法
HashTable的API对外提供了许多方法,这些方法能够很好帮助我们操作HashTable,但是这里我只介绍两个最根本的方法:put、get。
首先我们先看put方法:将指定 key 映射到此哈希表中的指定 value。注意这里键key和值value都不可为空。
-
1. public synchronized V put(K key, V value) {
-
2. // 确保value不为null
-
3. if (value == null) {
-
4. throw new NullPointerException();
-
5. }
-
6.
-
7. /*
-
8. * 确保key在table[]是不重复的
-
9. * 处理过程:
-
10. * 1、计算key的hash值,确认在table[]中的索引位置
-
11. * 2、迭代index索引位置,如果该位置处的链表中存在一个一样的key,则替换其value,返回旧值
-
12. */
-
13. Entry tab[] = table;
-
14. int hash = hash(key); //计算key的hash值
-
15. int index = (hash & 0x7FFFFFFF) % tab.length; //确认该key的索引位置
-
16. //迭代,寻找该key,替换
-
17. for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
-
18. if ((e.hash == hash) && e.key.equals(key)) {
-
19. V old = e.value;
-
20. e.value = value;
-
21. return old;
-
22. }
-
23. }
-
24.
-
25. modCount++;
-
26. if (count >= threshold) { //如果容器中的元素数量已经达到阀值,则进行扩容操作
-
27. rehash();
-
28. tab = table;
-
29. hash = hash(key);
-
30. index = (hash & 0x7FFFFFFF) % tab.length;
-
31. }
-
32.
-
33. // 在索引位置处插入一个新的节点
-
34. Entry<K,V> e = tab[index];
-
35. tab[index] = new Entry<>(hash, key, value, e);
-
36. //容器中元素+1
-
37. count++;
-
38. return null;
-
39. }
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表(我们暂且理解为链表),若该链表中存在一个这个的key对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。
当程序试图将一个key-value对放入HashMap中时,程序首先根据该 key的 hashCode() 返回值决定该 Entry 的存储位置:如果两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。如果这两个 Entry 的 key 通过 equals 比较返回 true,新添加 Entry 的 value 将覆盖集合中原有 Entry的 value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将与集合中原有 Entry 形成 Entry 链,而且新添加的 Entry 位于 Entry 链的头部
如下:
首先我们假设一个容量为5的table,存在8、10、13、16、17、21。他们在table中位置如下:
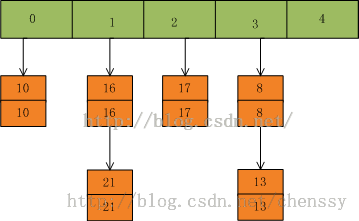
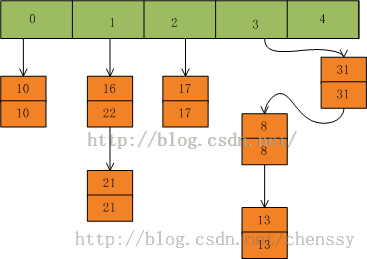
然后我们插入一个数:put(16,22),key=16在table的索引位置为1,同时在1索引位置有两个数,程序对该“链表”进行迭代,发现存在一个key=16,这时要做的工作就是用newValue=22替换oldValue16,并将oldValue=16返回。

在put(33,33),key=33所在的索引位置为3,并且在该链表中也没有存在某个key=33的节点,所以就将该节点插入该链表的第一个位置。
在HashTabled的put方法中有两个地方需要注意:
1、HashTable的扩容操作,在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,HashTable就会进行扩容处理rehash(),如下:
-
1. protected void rehash() {
-
2. int oldCapacity = table.length;
-
3. //元素
-
4. Entry<K,V>[] oldMap = table;
-
5.
-
6. //新容量=旧容量 * 2 + 1
-
7. int newCapacity = (oldCapacity << 1) + 1;
-
8. if (newCapacity - MAX_ARRAY_SIZE > 0) {
-
9. if (oldCapacity == MAX_ARRAY_SIZE)
-
10. return;
-
11. newCapacity = MAX_ARRAY_SIZE;
-
12. }
-
13.
-
14. //新建一个size = newCapacity 的HashTable
-
15. Entry<K,V>[] newMap = new Entry[];
-
16.
-
17. modCount++;
-
18. //重新计算阀值
-
19. threshold = ( int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
-
20. //重新计算hashSeed
-
21. boolean rehash = initHashSeedAsNeeded(newCapacity);
-
22.
-
23. table = newMap;
-
24. //将原来的元素拷贝到新的HashTable中
-
25. for ( int i = oldCapacity ; i-- > 0 ;) {
-
26. for (Entry<K,V> old = oldMap[i] ; old != null ; ) {
-
27. Entry<K,V> e = old;
-
28. old = old.next;
-
29.
-
30. if (rehash) {
-
31. e.hash = hash(e.key);
-
32. }
-
33. int index = (e.hash & 0x7FFFFFFF) % newCapacity;
-
34. e.next = newMap[index];
-
35. newMap[index] = e;
-
36. }
-
37. }
-
38. }
在这个rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程是比较消耗时间的,同时还需要重新计算hashSeed的,毕竟容量已经变了。这里对阀值啰嗦一下:比如初始值11、加载因子默认0.75,那么这个时候阀值threshold=8,当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,而阀值threshold=17*0.75 = 13,当容器元素再一次达到阀值时,HashTable还会进行扩容操作,一次类推。
2、下面是计算key的hash值,这里hashSeed发挥了作用。
-
1. private int hash(Object k) {
-
2. return hashSeed ^ k.hashCode();
-
}
相对于put方法,get方法就会比较简单,处理过程就是计算key的hash值,判断在table数组中的索引位置,然后迭代链表,匹配直到找到相对应key的value,若没有找到返回null。
-
1. public synchronized V get(Object key) {
-
2. Entry tab[] = table;
-
3. int hash = hash(key);
-
4. int index = (hash & 0x7FFFFFFF) % tab.length;
-
5. for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
-
6. if ((e.hash == hash) && e.key.equals(key)) {
-
7. return e.value;
-
8. }
-
9. }
-
10. return null;
-
11. }
4.和HashMap的区别
1.HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null。如下:
当HashMap遇到为null的key时,它会调用putForNullKey方法来进行处理。对于value没有进行任何处理,只要是对象都可以。
-
if (key == null)
-
return putForNullKey(value);
而当HashTable遇到null时,他会直接抛出NullPointerException异常信息。
-
if (value == null) {
-
throw new NullPointerException();
-
}
2.Hashtable的方法是同步的,而HashMap的方法不是。所以有人一般都建议如果是涉及到多线程同步时采用HashTable,没有涉及就采用HashMap。
3.HashTable有一个contains(Object value),功能和containsValue(Object value)功能一样。
4.两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
5.哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。代码是这样的:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
而HashMap重新计算hash值,而且用与代替求模:
int hash = hash(k);
int i = indexFor(hash, table.length);
6.Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
https://blog.csdn.net/evan123mg/article/details/53044512
智能推荐
使用nginx解决浏览器跨域问题_nginx不停的xhr-程序员宅基地
文章浏览阅读1k次。通过使用ajax方法跨域请求是浏览器所不允许的,浏览器出于安全考虑是禁止的。警告信息如下:不过jQuery对跨域问题也有解决方案,使用jsonp的方式解决,方法如下:$.ajax({ async:false, url: 'http://www.mysite.com/demo.do', // 跨域URL ty..._nginx不停的xhr
在 Oracle 中配置 extproc 以访问 ST_Geometry-程序员宅基地
文章浏览阅读2k次。关于在 Oracle 中配置 extproc 以访问 ST_Geometry,也就是我们所说的 使用空间SQL 的方法,官方文档链接如下。http://desktop.arcgis.com/zh-cn/arcmap/latest/manage-data/gdbs-in-oracle/configure-oracle-extproc.htm其实简单总结一下,主要就分为以下几个步骤。..._extproc
Linux C++ gbk转为utf-8_linux c++ gbk->utf8-程序员宅基地
文章浏览阅读1.5w次。linux下没有上面的两个函数,需要使用函数 mbstowcs和wcstombsmbstowcs将多字节编码转换为宽字节编码wcstombs将宽字节编码转换为多字节编码这两个函数,转换过程中受到系统编码类型的影响,需要通过设置来设定转换前和转换后的编码类型。通过函数setlocale进行系统编码的设置。linux下输入命名locale -a查看系统支持的编码_linux c++ gbk->utf8
IMP-00009: 导出文件异常结束-程序员宅基地
文章浏览阅读750次。今天准备从生产库向测试库进行数据导入,结果在imp导入的时候遇到“ IMP-00009:导出文件异常结束” 错误,google一下,发现可能有如下原因导致imp的数据太大,没有写buffer和commit两个数据库字符集不同从低版本exp的dmp文件,向高版本imp导出的dmp文件出错传输dmp文件时,文件损坏解决办法:imp时指定..._imp-00009导出文件异常结束
python程序员需要深入掌握的技能_Python用数据说明程序员需要掌握的技能-程序员宅基地
文章浏览阅读143次。当下是一个大数据的时代,各个行业都离不开数据的支持。因此,网络爬虫就应运而生。网络爬虫当下最为火热的是Python,Python开发爬虫相对简单,而且功能库相当完善,力压众多开发语言。本次教程我们爬取前程无忧的招聘信息来分析Python程序员需要掌握那些编程技术。首先在谷歌浏览器打开前程无忧的首页,按F12打开浏览器的开发者工具。浏览器开发者工具是用于捕捉网站的请求信息,通过分析请求信息可以了解请..._初级python程序员能力要求
Spring @Service生成bean名称的规则(当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致)_@service beanname-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏6次。@Service标注的bean,类名:ABDemoService查看源码后发现,原来是经过一个特殊处理:当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致public class AnnotationBeanNameGenerator implements BeanNameGenerator { private static final String C..._@service beanname
随便推点
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立
解决asp.net导出excel时中文文件名乱码_asp.net utf8 导出中文字符乱码-程序员宅基地
文章浏览阅读7.1k次。在Asp.net上使用Excel导出功能,如果文件名出现中文,便会以乱码视之。 解决方法: fileName = HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8);_asp.net utf8 导出中文字符乱码
笔记-编译原理-实验一-词法分析器设计_对pl/0作以下修改扩充。增加单词-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏23次。第一次实验 词法分析实验报告设计思想词法分析的主要任务是根据文法的词汇表以及对应约定的编码进行一定的识别,找出文件中所有的合法的单词,并给出一定的信息作为最后的结果,用于后续语法分析程序的使用;本实验针对 PL/0 语言 的文法、词汇表编写一个词法分析程序,对于每个单词根据词汇表输出: (单词种类, 单词的值) 二元对。词汇表:种别编码单词符号助记符0beginb..._对pl/0作以下修改扩充。增加单词
android adb shell 权限,android adb shell权限被拒绝-程序员宅基地
文章浏览阅读773次。我在使用adb.exe时遇到了麻烦.我想使用与bash相同的adb.exe shell提示符,所以我决定更改默认的bash二进制文件(当然二进制文件是交叉编译的,一切都很完美)更改bash二进制文件遵循以下顺序> adb remount> adb push bash / system / bin /> adb shell> cd / system / bin> chm..._adb shell mv 权限
投影仪-相机标定_相机-投影仪标定-程序员宅基地
文章浏览阅读6.8k次,点赞12次,收藏125次。1. 单目相机标定引言相机标定已经研究多年,标定的算法可以分为基于摄影测量的标定和自标定。其中,应用最为广泛的还是张正友标定法。这是一种简单灵活、高鲁棒性、低成本的相机标定算法。仅需要一台相机和一块平面标定板构建相机标定系统,在标定过程中,相机拍摄多个角度下(至少两个角度,推荐10~20个角度)的标定板图像(相机和标定板都可以移动),即可对相机的内外参数进行标定。下面介绍张氏标定法(以下也这么称呼)的原理。原理相机模型和单应矩阵相机标定,就是对相机的内外参数进行计算的过程,从而得到物体到图像的投影_相机-投影仪标定
Wayland架构、渲染、硬件支持-程序员宅基地
文章浏览阅读2.2k次。文章目录Wayland 架构Wayland 渲染Wayland的 硬件支持简 述: 翻译一篇关于和 wayland 有关的技术文章, 其英文标题为Wayland Architecture .Wayland 架构若是想要更好的理解 Wayland 架构及其与 X (X11 or X Window System) 结构;一种很好的方法是将事件从输入设备就开始跟踪, 查看期间所有的屏幕上出现的变化。这就是我们现在对 X 的理解。 内核是从一个输入设备中获取一个事件,并通过 evdev 输入_wayland