安装教程
本篇博客将会教会你在Windows下配置py-faster-rcnn,请细心仔细阅读。说白了,Windows下配置这些东西就是一个坑。
安装配置Anaconda
由于py-faster-rcnn要用到python,这里我们使用了Anaconda,Anaconda版本为Anaconda2-4.3.1-Windows-x86_64.exe,Anaconda下载地址,双击安装即可,安装完Anaconda2后需要下载必要的python库,在cmd下运行下面代码即可:
conda install --yes numpy scipy matplotlib scikit-image pip
pip install protobuf
conda install numpy pyqt
- 1
- 2
- 3
- 4
同样的,在cmd中輸入python --version,可以得到你安裝的python信息:(如果是Anaconda则无需之后操作)
(python27) C:\Users\39294\Desktop>python --version
Python 2.7.13 :: Anaconda 4.3.1 (64-bit)
安装配置Windows-caffe
在安装好Anaconda后,需要配置Windows-caffe。为了使用GPU来运行深度学习,我们需要安装相应的cuda和cuDNN。其中,cuda版本为cuda_8.0.61_win10,双击安装即可;cuDNN版本为cudnn-7.5-windows10-x64-v5.0-ga,下载并将其解压至D:\
CUDA下载地址 cuDNN下载地址
同样的,需要从github上下载相应的windows-caffe,并将其解压至D:\。
windows-caffe下载地址
随后,开始配置caffe:
进入D:\caffe-master\windows,复制文件CommonSettings.props.example并将其改名为CommonSettings.props,双击进入工程caffe(这里注意:需要安装了VS,才可以打开并编译)。有时候libcaffe没有加载成功(主要原因在于看看propos里面的cuda版本是7.5,而你装的是8.0,ctrl+F搜索7.5,找到到改为8.0.并重启caffe.sln即可)
- 注意:如果libcaffe和testall存在问题,请参考如下解决办法:
由于vs2013的安装路径中缺少 CUDA 8.0.props ,文件引用CUDA 8.0的路径是 C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V120\BuildCustomizations ,其实 CUDA 8.0.props 安装路径是 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\extras\visual_studio_integration\MSBuildExtensions ,只要拷贝到 C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V120\BuildCustomizations 就行了,那么libcaffe和testall就都没问题了!
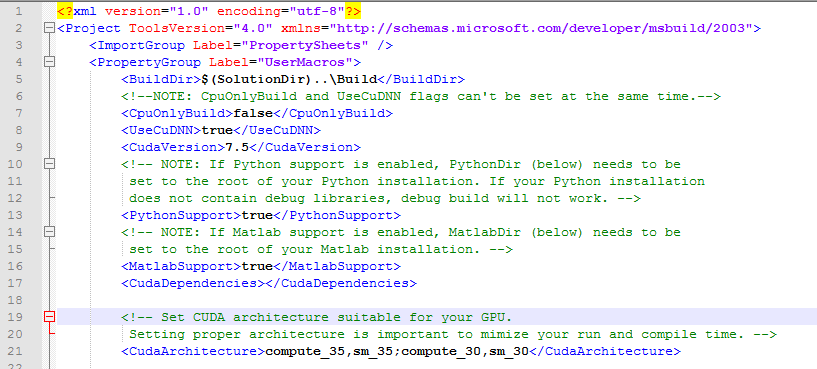
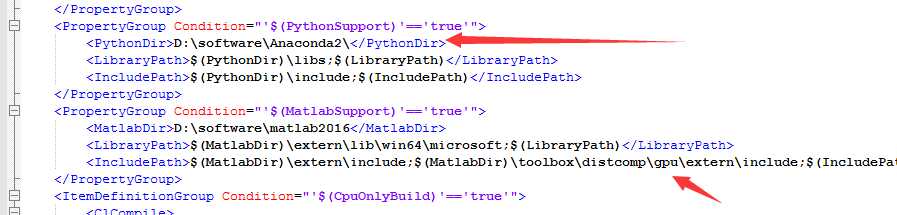
在打开caffe工程后,打开右侧文件列表中的文件CommenSetting.probs,在文件中搜索cudapath,该栏存放从cudnn解压出来的文件夹cuda的目录路径。由于我们从cudnn解压出来的文件夹cuda的目录路径是D:\,因此,输入D:\即可。
如果需要配置pycaffe,即caffe的python接口,则请进行一下操作:打开右侧文件列表中的文件CommenSetting.probs,编译支持python接口<PythonSupport>ture</PythonSupport>,同时修改python的路径,指定到Anaconda中。
随后,我们参考博客,将roi_pooling_layer.hpp,cu,cpp加入到libcaffe文件配置中。
参考博客
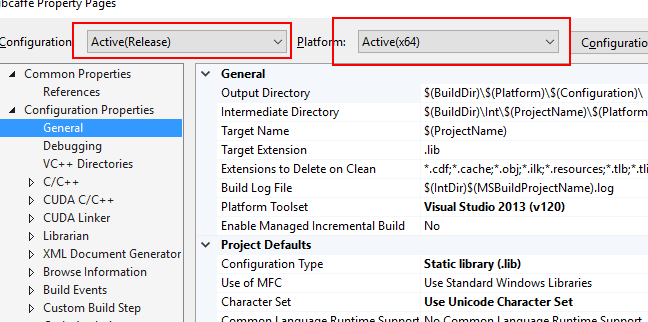
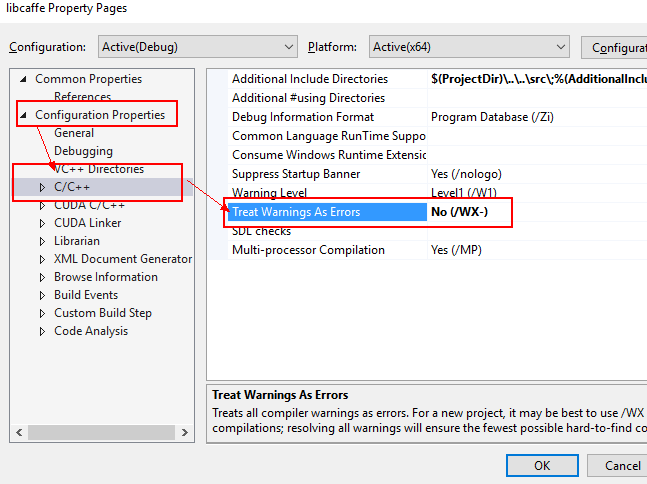
接下来,选择编译类型为release,x64,关闭 Treat Warnings As Errors (即设置为No) ,如果不设置的话在编译boost库的时候会由于文字编码的警告而报错。下面两张图帮你进行设置。
然后开始漫长的编译过程,编译结束后会在D:\下生成文件夹NugetPackages,我们也可以在拷贝别人的文件NugetPackages到指定目录D:\后进行编译。
在编译好libcaffe后,需要继续编译其他任务:下面两张图帮你进行设置并进行相关编译。
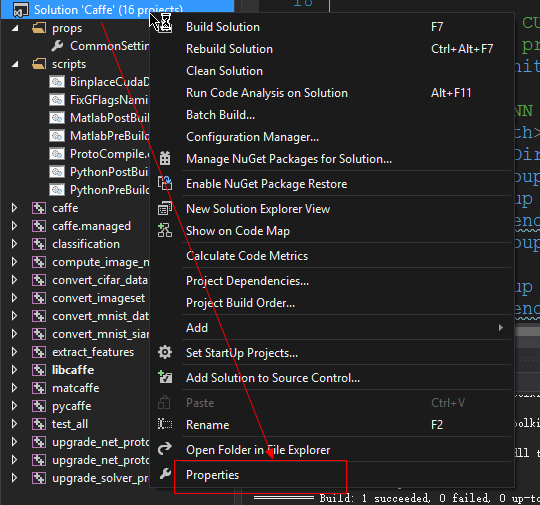
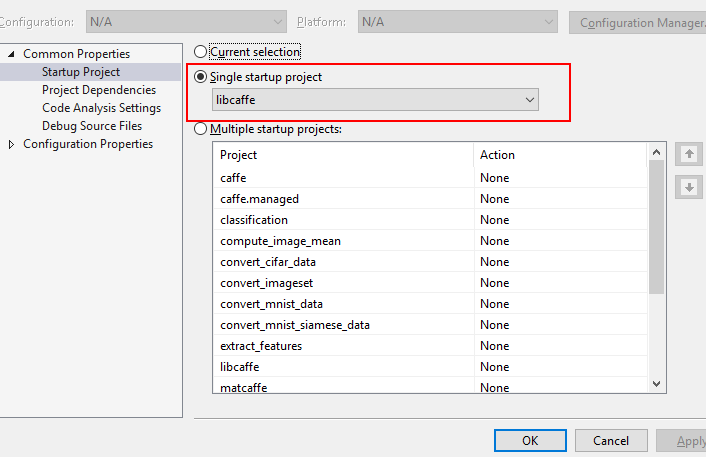
至此,caffe工程已经编译完成,可以正常训练测试网络。
-
编译错误:
error MSB4062:未能从程序集D:\NugetPackages\OpenCV.2.4.10\build\native\private\- 1
- 2
coapp.NuGetNativeMSBuildTasks.dll加载任务“NuGetPackageOverlay”
该问题解决办法,只需要升级opencv即可,参考博客解决问题
下载Caffe-Microsoft并添加roi_poling_layer后正确编译
下载地址:https://github.com/Microsoft/caffe
由于windows版本caffe的不完善,要先在libcaffe项目中添加roi_poling层的相关支持。具体操作如下:
在libcaffe项目下的 cu—layers 文件夹右击,添加——现有项,找到 caffe根目录—src—caffe—layers下,添加roi_pooling_layer.cu。
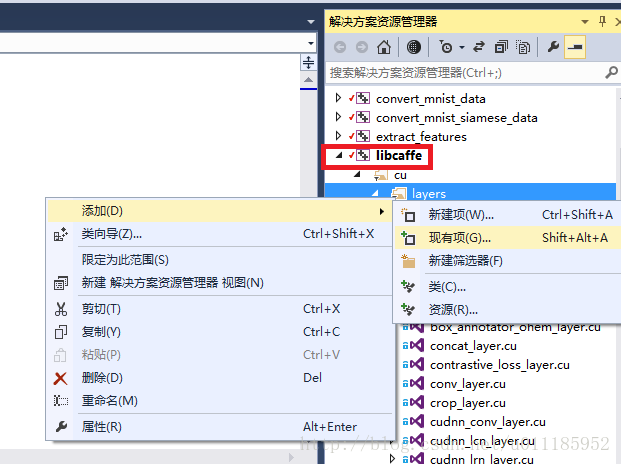
路径示例:
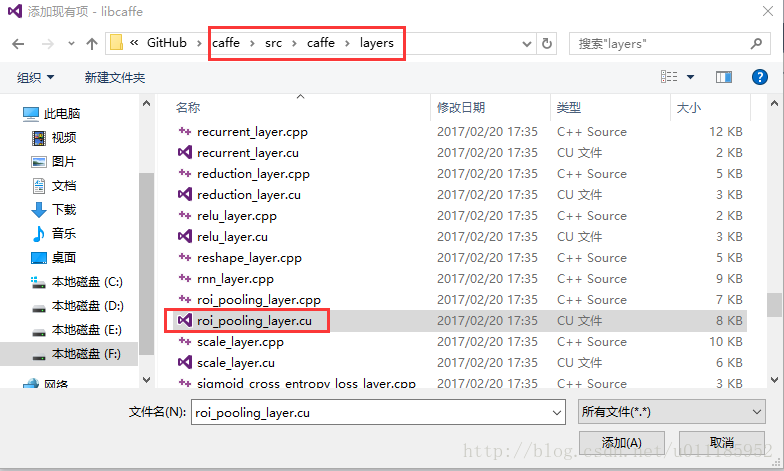
同理,在libcaffe项目下的 src—layers 添加roi_polling_layer.cpp;
(所在路径:caffe根目录—src—caffe—layers)
在libcaffe项目下 include—layers添加roi_pooling_layer.hpp。
(所在路径:caffe根目录—include—caffe—layers)
记得在配置中开启python版编译,然后生成caffe。具体步骤可参考这里,生成成功则大功告成。
error MSB4062: 未能从程序集 …… 加载任务“NuGetPackageOverlay”。
如果你之前生成过windows版caffe,在添加roi_pooling支持后重新生成时,很可能会碰到error MSB4062错误。我的解决方案如下:
(1)将caffe根目录下的Build文件夹整个删除;
(2)右键 解决方案caffe —清理解决方案;
(3)重新生成。
另:网上有说是CuDNN 5.0 与 CUDA8.0 兼容问题的,也有说是Nuget中opencv更新至2.4.11问题的(默认为2.4.10),我个人的尝试是——不好使 = =。我在两个配置过caffe的机器上都出现了error MSB4062,均为CUDA 8.0+CuDNN 5.0,一个Win7一个Win10,最终都是重新生成得以解决。
二、配置Faster-RCNN
1. 配置windows版的py-faster-rcnn
下载py-faster-rcnn,地址:https://github.com/rbgirshick/py-faster-rcnn
由于上述版本中的python都是基于linux环境编写的,windows运行需要进行改动。好在有人已经完成了相关工作:
再下载py-faster-rcnn-windows,地址:https://github.com/MrGF/py-faster-rcnn-windows
将其中的文件复制进py-faster-rcnn进行替换。
替换后,在py-faster-rcnn根目录—lib—rpn路径下,编辑proposal_layer.py:
(1)将其中的 param_str_ 替换为 param_str。
(2)将
cfg_key = str(self.phase)- 1
替换为
cfg_key = str('TRAIN' if self.phase == 0 else 'TEST')- 1
2. 拷入生成的Caffe
将Caffe根目录—Build文件夹下,找到生成的pycaffe,将其中的caffe文件夹整体复制到py-faster-rcnn根目录—caffe-fast-rcnn—python文件夹下。我生成的caffe是Release版本,如图:
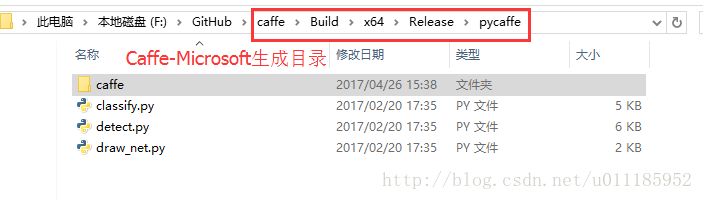
复制到:
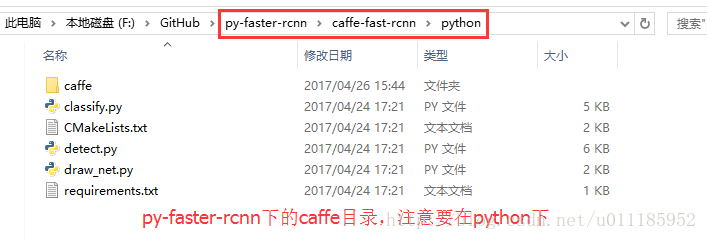
注:官方推荐用命令
git clone --recursive https://github.com/rbgirshick/py-faster-rcnn.git- 1
下载py-faster-rcnn,如果用Download ZIP(因为我们已经有了Caffe-Microsoft),在py-faster-rcnn的caffe-faster-rcnn下单独创建python文件夹,再将生成的pycaffe下的caffe拷贝进来,实测也能够完成demo生成。
3. 客制化修改与setup
根据本机的CUDA环境,修改py-faster-rcnn—lib路径下的setup_cuda.py:
(1)第14行
'-arch=sm_35' //我的是-arch=compute_60 (GTEX-1050的显卡)- 1
修改为本机显卡的计算能力,具体查询Nvida官网。
(2)第33行
include_dirs = [numpy_include, 'C:\\Programming\\CUDA\\v7.5\\include'])- 1
修改为本机的CUDA-include环境,比如我的路径是:
include_dirs = [numpy_include, 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v8.0\\include'])- 1
此时可以CMD打开至py-faster-rcnn\lib路径下,运行命令:
python setup.py install
python setup.py build_ext --inplace
python setup_cuda.py install- 1
- 2
- 3
假如出现缺少某些依赖项或cv2.pyd (opencv) 的情况,用pip install命令安装或网上搜索相关配置方法即可,pip用法示例:
pip install easydict- 1
然后,在cmd中切换工作目录到py-faster-rcnn/lib目录:执行 python setup.py install 代码执行成功后,修改setup_cuda.py中第33行,CUDA的include路径为你自己的路径。执行 python setup_cuda.py install 安装成功.
python setup.py install
include_dirs = [numpy_include, 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v7.5\\include'])
python setup_cuda.py install
- 1
- 2
- 3
- 4
- 5
- 6
-
编译报错:
error: Microsoft Visual C++ 9.0 is required. Get it from http://aka.ms/vcpython27;- 1
- 2
解决办法:直接在在cmd下输入:SET VS90COMNTOOLS=%VS120COMNTOOLS%,如果不行,则参考博客(注意:直接在D盘Anaconda2下面进行修改)
-
编译报错:
File "D:\Anaconda2\lib\ntpath.py", line 180, in split d, p = splitdrive(p) File "D:\Anaconda2\lib\ntpath.py", line 115, in splitdrive if len(p) > 1: TypeError: object of type 'NoneType' has no len()- 1
- 2
- 3
- 4
- 5
- 6
解决办法:我们需要添加环境变量,参考博客办法(C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\ )
成功状态如图:
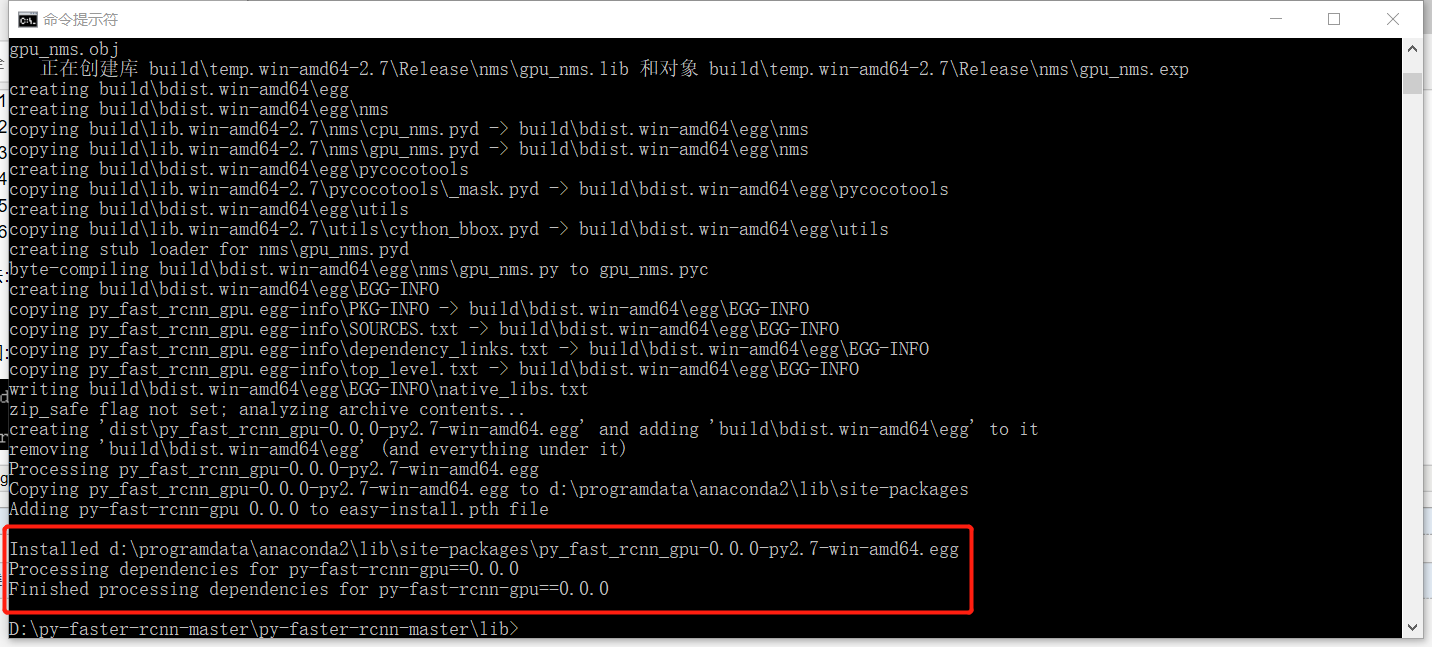
至此,py-faster-rcnn的配置工作基本完毕,接下来,我们运动demo,看看效果。在cmd中切换工作目录到到py-faster-rcnn目录下,执行python ./tools/demo.py。若执行成功,将出现相应的检测图片。
python ./tools/demo.py
- 1
- 2
-
编译报错:
ImportError: No module named easydict- 1
- 2
解决办法:在cmd下输入:pip install easydict,可以参考博客()
-
编译报错:
ImportError: No module named cv2- 1
- 2
解决办法:将opencv里面的cv2.pyd文件拷贝到D:\Anaconda2\Lib\site-packages中,可以参考博客
-
编译报错:
ImportError: No module named google.protobuf.internal- 1
- 2
解决办法:在cmd下输入:conda install protobuf,可以参考博客
-
编译报错:
AttributeError: 'ProposalLayer' object has no attribute 'param_str_'- 1
- 2
解决办法:将对应文件中’param_str_’改为’param_str’,可以参考博客
-
编译报错:
proposal_layer.py 中 pre_nms_topN = cfg[cfg_key].RPN_PRE_NMS_TOP_N, keyerror = 1- 1
- 2
解决办法:可以参考博客
如果遇到ImportError: DLL load failed: 找不到指定的程序。参考:http://blog.csdn.net/lzhalan2016/article/details/52415998
第一步:
在命令中输入以下指令卸载相应的包:pip uninstall numpy;pip uninstall scipy;pip uninstall matplotlib;pip scikit-learn
第二步:
在下面的网站中找到对应的包,如果是python2.7就是cp27系列的,电脑是多少位的一定下载对应版本
http://www.lfd.uci.edu/~gohlke/pythonlibs/#scipy
http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
http://www.lfd.uci.edu/~gohlke/pythonlibs/#matplotlib
http://www.lfd.uci.edu/~gohlke/pythonlibs/#scikit-learn
第三步:
找到安装python的目录下的Scripts文件,在这个文件里安装相应的whl包
比如指令为 cd D:\ProgramData\Anaconda2\Scripts,然后在这里用指令 pip install D:/xxx/xxx/xxx.whl
假如有successful的显示就是完成了。
至此,编译完成,运行成功。