C11新特性(部分)_c11特性-程序员宅基地
C11部分新特性
1.类型推导
C11引入了auto和decltype这两个关键字实现类型推导,可以获取复杂类型。
1.1 auto
1.1.1 auto的基本使用
auto为类型指示符 auto定义的变量,可以根绝初始化的值,在编译时推导出变量名的类型。
int main()
{
auto x = 5; //ok x是int类型
auto pi = new auto(1); //ok pi是int *型
const auto *p = &x,u=6; //ok p是const int *型,u是const int型
static auto dx = 3.4; //ok dx是double类型
}
使用auto必须给定初始化值,如果没有给定无法推导出类型:
auto s;// error 没有初始化值 无法推导出s的类型。
C11中auto不再表示存储类型指示符:
auto int b;//error C11中auto不再表示存储类型指示符。
此处u必须给定一个初始值才可以 编译通过,不然会报错。

当我们给定u与x的类型不同的值时也会报错,是因为这时候产生了二异性。
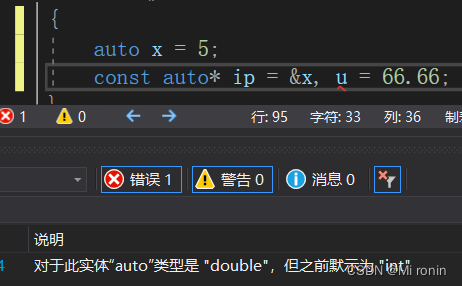
从上面的这些例子看出,auto并不是一个实际的类型声明。
使用auto声明的变量必须要有初始化值,才可以让编译器推断出它的实际类型,在编译的时候将auto替换为真正的数据类型。
1.1.2 auto的推导规则
auto可以与指针,引用结合使用,还可以有cv限定符。
int main()
{
int x =0;
auto *ip = &x; // ok ip ->int*,auto被推导为int
auto xp = &x; // ok xp -> int*, auto被推导为int*
auto &c = x; // ok c -> int &,auto被推导为int
auto d = x; // ok d -> int , auto被推导为int
const auto e = x; // ok e ->const int;
auto f = e; // ok f -> int;
const auto &g = x; // ok g -> const int &
auto & h = g; // ok h -> const int &
}
- auto在编译时被替换为int,因此a和c分别被推导为int*和int&。
- xp的推导结果说明,当auto不声明为指针,也可以推导出指针类型。
- d的推导结果说明当表达式是一个引用类型时,auto 会把引用类型抛弃,直接推导成原始类型int。
- e的推导结果说明,const auto会在编译时被替换为const int。
- f的推导结果说明,当表达式带有const(实际上volatile也会得到同样的结果)属性时,auto 会把const属性抛弃掉,推导成non-const类型int。
- g、h的推导说明,当auto和引用(换成指针在这里也将得到同样的结果)结合时,auto的推导将保留表达式的const属性。
当不声明为指针或引用时,auto的推导结果和初始化表达式抛弃引用和cv限定符后类型一致。
当声明为指针或引用时,auto的推导结果将保持初始化表达式的cv属性。
1.1.3 auto的限制
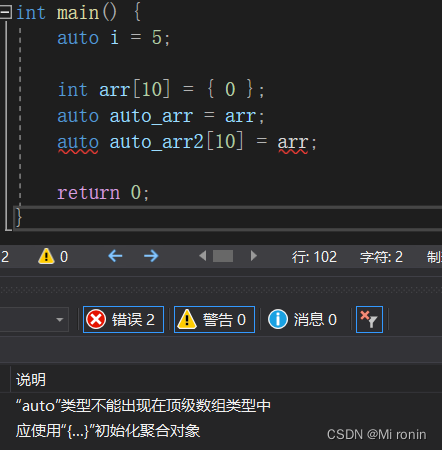
- auto无法定义数组
#include <iostream>
int main() {
auto i = 5;
int arr[10] = {
0};
auto auto_arr = arr;
auto auto_arr2[10] = arr;
return 0;
}
代码测试:
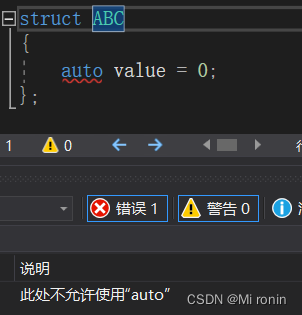
- 不能用于非静态成员变量
struct ABC
{
auto value = 0; //error 不能用于非静态成员变量
};
代码测试:
- 不能用于函数参数
auto 不能用于函数传参,因此下面的做法是无法通过编译的(考虑重载的问题,我们应该使用模板):
int add(auto x, auto y);
1.2 decltype
decltype是用来在编译时推导出一个表达式的类型。
它的用法和 sizeof 很相似:
decltype(表达式)
类似于sizeof,decltype的推导过程是在编译期完成的,编译器分析表达式并得到它的类型,却不实际计算表达式的值。
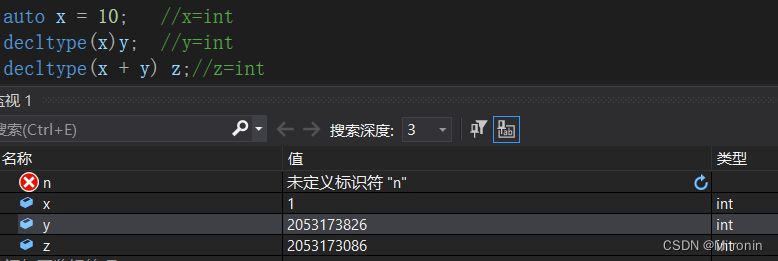
auto x = 10; //x=int
decltype(x)y; //y=int
decltype(x + y) z;//z=int
代码测试:
不去调动Add 只是计算表达式判断类型
#include <iostream>
int Add(int a,int b)
{
printf("add\n");
return 0;
}
int main()
{
auto x = 10; //x=int
decltype(x)y; //y=int
decltype(x + y) z;//z=int
decltype(Add(1, 2)) c;
}
代码测试:

2.nullptr-指针空值
当我们初始化一个指针时是将其指向一个""空"的位置,大部分情况下我们使用的都是0或NULL。因此在大多数的代码中,我们常常能看见指针初始化的语法如下:
int *p = 0;
int *p = NULL;
通过上面对空指针的定义,我们不难看出NULL可能被定义为字面常量0,或者是定义为无类型指针(void *) 0常量。
我们在使用空值的指针时,都不可避免地会遇到一些麻烦:
void fun(char *)
{
printf("ca11 fun(char *)n") ;
}
void fun(int i)
{
printf(" ca11 fun(int i)n");
)
int main()
{
fun(O);
fun(NULL);//期望调用
fun(char*);
}
这里我们期望调用的函数并没有被调用,这个问题是由于0的二义性。
为了解决上述问题,就在C11中引入了nullptr。
C11标准中,将nullptr定义为一个指针空值的常量。
当使用nullptr后:
void fun(char *)
{
printf("ca11 fun(char *)n") ;
}
void fun(int i)
{
printf(" ca11 fun(int i)n");
)
int main()
{
fun(nullptr);
fun(0);
return 0;
}
这里运行结果,就符合用户的期望。
所以,以后书写代码的时候如果遇到NULL,我们就可以将NULL替换为nullptr。
nullptr与nullptr_t:
nullptr_t在C11中被定义为指针空值类型。 我们可以通过nullptr_t来声明一个指针空值类型的变量。
在使用的时候对于nullptr_r,我们需要#include,而nullptr不需要,直接使用即可。所以我们也可以认为nullptr是关键字,而nullptr_r是推导而来的。
注意:
1、nullptr 是C11新引入的关键字,是一个所谓"指针空值类型"的常量,
在C++程序中直接使用。
2、在C11中,sizeof(nullptr)与sizeof(void*)0)所占的字节数相同都为4或8**(对应32位和64位)。
3、为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
3.基于范围的for循环
在C98中,不同的容器和数组,遍历的方法不尽相同,写法不统一,也不够简洁。C++11引入了基于范围的迭代写法,我们拥有了能够写出像 Python 一样简洁的循环语句。
C11基于范围的for循环以统一、简洁的方式来遍历容器和数组,用起来更方便。
首先明确什么是容器:能够容纳其他元素的元素或者容纳其他对象的对象。
基于范围的for循环一般格式:
for(ElemType val: array)
{
…//statement 循环体
}
ElemType:是范围变量的数据类型。
它必须与数组(容器)元素的数据类型一样,或者是数组元素可以自动转换过来的类型。
val :是范围变量的名称。
该变量将在循环迭代期间依次接收数组中的元素值。在迭代期间,接收的是本次迭代次数的元素值。
array:是要让该循环进行处理的数组(容器)的名称。该循环将对数组中的每个元素迭代一次。
statement:是在每次循环迭代期间要执行的语句。
我们以最常用的 std::vector 遍历说明。
未使用基于范围的for循环,代码如下:
std::vector<int> arr(5, 100);
for(std::vector<int>::iterator i = arr.begin(); i != arr.end(); ++i)
{
std::cout << *i << std::endl;
}
使用基于范围的for循环后,代码如下:
// & 启用了引用
for(auto &i : arr) {
std::cout << i << std::endl;
}
由上述例子我们可以明确观察到,使用基于范围的for循环后会变得简单明了。
并且我们需要记住,基于范围的for一定是一个集合。
4.typedef与using
4.1typedef的语法和使用场景
typedef是C/C++语言中保留的关键字,用来定义一种数据类型的别名。需要注意的是typedef并没有创建新的类型,只是指定了一个类型的别名而已。
typedef定义的类型的作用域只在该语句的作用域之内, 也就是说如果typedef定义在一个函数体内,那么它的作用域就是这个函数。
typedef经常使用的场景包括以下几种:
- 指定一个简单的别名,避免了书写过长的类型名称。
- 实现一种定长的类型,在跨平台编程的时候尤其重要。
- 使用一种方便阅读的单词来作为别名,方便阅读代码。
4.2 using的语法与使用场景
C++11 中扩展了using的使用场景(C++11之前using主要用来引入命名空间名字 如:using namespace std;),可以使用using定义类型的别名:
使用语法如下:
using 别名 = xxx(类型);
using声明别名的顺序和typedef是正好相反:typedef首先是类型,接着是别名,而using使用别名作为左侧的参数,之后才是右侧的类型,例如上面的类型定义:
typedef int points;
using points = int; //等价的写法
定义诸如函数指针等类型时,使用using的方式更加自然和易读:
typedef void (*FP) (int, const std::string&);
using FP = void (*) (int, const std::string&); //等价的using别名
using可以在模板别名中使用,但是typedef不可以
template <typename T>
using Vec = MyVector<T, MyAlloc<T>>;
// usage
Vec<int> vec;
归根到底就是一句话,在C++11中,请使用using,而非typedef,它可以完成typedef能完成的,并且可以做的更多。
5.新增容器
5.1 std::array
std::array 保存在栈内存中,相比堆内存中的 std::vector,我们能够灵活的访问这里面的元素,从而获得更高的性能。
std::array 会在编译时创建一个固定大小的数组,std::array 不能够被隐式的转换成指针,使用 std::array只需指定其类型和大小即可:
std::array<int, 4> arr= {
1,2,3,4};
int len = 4;
std::array<int, len> arr = {
1,2,3,4}; //error 数组大小参数必须是常量表达式
当我们开始用上了 std::array 时,可能要将其兼容 C 风格的接口,这里有三种做法:
void foo(int *p, int len)
{
return;
}
std::array<int 4> arr = {
1,2,3,4};
// C 风格接口传参
// foo(arr, arr.size()); // error, 无法隐式转换
foo(&arr[0], arr.size());
foo(arr.data(), arr.size());
// 使用 `std::sort`
std::sort(arr.begin(), arr.end());
5.2 std::forward_list
std::forward_list 是一个列表容器,使用方法和 std::list 基本类似。
和 std::list 的双向链表的实现不同,std::forward_list 使用单向链表进行实现,提供了 O(1) 复杂度的元素插入,不支持快速随机访问(这也是链表的特点),也是标准库容器中唯一一个不提供 size() 方法的容器。当不需要双向迭代时,具有比 std::list 更高的空间利用率。
5.3 无序容器
C++11 引入了两组无序容器:
std::unordered_map/std::unordered_multimap
std::unordered_set/std::unordered_multiset。
无序容器中的元素是不进行排序的,内部通过 Hash 表实现,插入和搜索元素的平均复杂度为 O(constant)。
5.4 元组 std::tuple
元组的使用有三个核心的函数:
- std::make_tuple: 构造元组
- std::get: 获得元组某个位置的值
- std::tie: 元组拆包
#include <tuple>
#include <iostream>
auto get_student(int id)
{
// 返回类型被推断为 std::tuple<double, char, std::string>
if (id == 0)
return std::make_tuple(3.8, 'A', "张三");
if (id == 1)
return std::make_tuple(2.9, 'C', "李四");
if (id == 2)
return std::make_tuple(1.7, 'D', "王五");
return std::make_tuple(0.0, 'D', "null");
// 如果只写 0 会出现推断错误, 编译失败
}
int main()
{
auto student = get_student(0);
std::cout << "ID: 0, "
<< "GPA: " << std::get<0>(student) << ", "
<< "成绩: " << std::get<1>(student) << ", "
<< "姓名: " << std::get<2>(student) << '\n';
double gpa;
char grade;
std::string name;
// 元组进行拆包
std::tie(gpa, grade, name) = get_student(1);
std::cout << "ID: 1, "
<< "GPA: " << gpa << ", "
<< "成绩: " << grade << ", "
<< "姓名: " << name << '\n';
}
合并两个元组,可以通过 std::tuple_cat 来实现。
auto new_tuple = std::tuple_cat(get_student(1), std::move(t));
参考链接: C11新特性
智能推荐
python difflib 编辑距离_Python Edit_Distance包_程序模块 - PyPI - Python中文网-程序员宅基地
文章浏览阅读413次。编辑距离用于计算序列之间编辑距离和对齐的python模块。我需要一种方法来计算python中序列之间的编辑距离。我没有能够找到任何合适的库来实现这一点,所以我自己编写了一个。在那里似乎有许多可用于计算编辑的编辑距离库两个字符串之间的距离,但不是两个序列之间的距离。这完全是用python编写的。这种实现可能是在python中优化为更快。如果在C中实现。库API是根据difflib.sequencem..._edit distance python lib
antd upload组件 手动上传-程序员宅基地
文章浏览阅读3.8k次,点赞2次,收藏15次。antd 的upload组件是点开对话框后,按下确实就会上传,而且如果多选文件也会反复调用后端接口来完成上传。因为项目需要,所以要实现手动上传,和一次性上传多个文件(调用一次后端接口)在实现这个功能时,我翻阅了很多博客,可能是因为版本原因,很多代码都无用,最后还是通过翻阅官方文档,才最终实现。..._antd upload
sqlite3 环境搭建_sqlite 部署-程序员宅基地
文章浏览阅读246次。注意 第一步在一个文件下打开终端然后 sqlite3 student.db(创建一个数据库),然后再create stu。callback 回调函数 (只有sql为查询语句的时候,才会执行此语句)6--删除一列(sqlite3 不支持) 用下面方法。功能 :打开sqlite 数据库。功能 :关闭sqlite 数据库。基本sql命令,不以 . 夹头,db:指向sqlite句柄的指针。将新表的名字改为原来表的名字。sqlite3的基本命令。功能:执行一条sql语句。以 . 开头的命令。_sqlite 部署
canal-adapter趟坑实践:canal-server的kafka SASLPLAIN方式鉴权适配_canal adapter kafka sasl-程序员宅基地
文章浏览阅读1.4w次。前言canal-server同步到kafka本身是支持Kerberos方式的鉴权的,但是鉴于项目现在使用的kafka集群使用的是SASL/PLAIN的鉴权方式,所以需要对canal-server同步kafka做一下适配改造。准备kafka SASL/PLAIN鉴权的搭建我参考的这篇文章kafka SASL/PLAIN鉴权的搭建了解如何使用java向以SASL/PLAIN方式鉴权的kafk..._canal adapter kafka sasl
Android adb shell相关命令_android的shell命令工具:设备规范管理-程序员宅基地
文章浏览阅读711次。adb(调试桥):debug工具。adb作用:借助adb工具,可以管理设备或手机模拟器状态。adb相关操作命令如下: 1. 显示系统中全部Android平台: android list targets2. 显示系统中全部AVD(模拟器): android list avd3. 创建AVD(模拟器): android create avd_android的shell命令工具:设备规范管理
Centos 7.9 在线安装 VirtualBox 7.0_centos安装virtualbox-程序员宅基地
文章浏览阅读769次,点赞10次,收藏7次。Centos 7.9 在线安装 VirtualBox 7.0_centos安装virtualbox
随便推点
Autodesk官方卸载工具软件安装教程-程序员宅基地
文章浏览阅读1.4w次,点赞9次,收藏10次。Autodesk卸载工具是一个专门用于Autodesk软件的卸载工具,可以自动识别电脑中的所有Autodesk软件,只需一键点击就能将Autodesk的软件完美卸载,并且不保留任何痕迹,这款卸载工具就可以帮助用户全面卸载Autodesk软件。_autodesk官方卸载工具
JDBC报错:Cannot find class: com.mysql.jdbc.Driver-程序员宅基地
文章浏览阅读4.9k次。1.配置书写错误:配置文件value值引号内不能有空格,属性文件配置信息末尾不能有空格(1)打开属性文件中com.mysql.jdbc.Driver后发现多了一个空格(如下我标出了),所以写属性文件时一定别多输入多余的空格了。 jdbc.driverClassName=com.mysql.jdbc.Driver(此处有空格)(2)配置文件中的value值的" "号中前面或..._cannot find class: com.mysql.jdbc.driver
软件常用术语_软件术语-程序员宅基地
文章浏览阅读1.8k次。软件常用术语,免得你面对各种设计模式头发晕_软件术语
Machine Learning 2 - 非线性回归算法分析_非线性回归分析方法-程序员宅基地
文章浏览阅读2.8k次。2017-08-02@erixhao 技术极客TechBoosterAI 机器学习第二篇 - 非线形回归分析。我们上文深入本质了解了机器学习基础线性回归算法后,本文继续研究非线性回归。非线性回归在机器学习中并非热点,并且较为小众,且其应用范畴也不如其他广。鉴于此,我们本文也将较为简单的介绍,并不会深入展开。非线性回归之后,我们会继续经典机器学习算法包括决策_非线性回归分析方法
hive基本函数_josn mincol-程序员宅基地
文章浏览阅读164次。一、关系运算:1.等值比较: =语法:A=B操作类型:所有基本类型描述:如果表达式A与表达式B相等,则为TRUE;否则为FALSE举例:hive>select 1 from lxw_dual where 1=1;12.不等值比较: <>语法: A <> B操作类型:所有基本类型描述:如果表达式A为NULL,或者表..._josn mincol
FI 与SD MM相关接口配置_sd 和fi 接口产生什么凭证?-程序员宅基地
文章浏览阅读767次。1 FI/SD 借口配置FI/SD通过tcode VKOA为billing设置过帐科目,用户可以创建自己的科目定义数据表。 科目是做到COA级的,通过KOFI/KOFK这两个condition type确定分别过帐到FI和CO凭证中。 由于PricingProc.是同Sale_sd 和fi 接口产生什么凭证?