Redis数据库——键过期时间_yii redis计数器加过期时间-程序员宅基地
一.设置键的生存时间或者过期时间
我们可以在Redis客户端输入命令,可以以秒或者毫秒精度为数据库中的某个键设置生存时间,在指定秒数或者毫秒数之后,服务器会自动删除生存时间为0的键。
1.1 设置过期时间
Redis有四个不同的命令可以用于设置键的生存时间或者过期时间:
- EXPIRE <KEY> <TTL> 命令用于将键key的生存时间设置为ttl秒。
- PEXPIRE <KEY> <TTL>命令用于将键key的生存时间设置为ttl毫秒。
- EXPIREAT <KEY> <timestamp> 命令用于将键key的过期时间设置为timestamp所指定秒数时间戳。
- PEXPIREAT <KEY> <timestamp> 命令用于将键key的过期时间设置为timestamp所指定毫秒数时间戳。
虽然有多种不同单位不同形式的设置命令,但实际上EXPIRE, PEXPIRE, EXPIREAT三个命令都是使用PEXPIREAT命令来实现的。
def EXPIRE(key, ttl_in_sec):
#将TTL从秒装换成毫秒
ttl_in_ms = sec_to_ms(ttl_in_sec)\
PEXPIRE(key, ttl_in_ms)
#PEXPIRE里面调用PEXPIREAT
def PEXPIRE(key, ttl_in_ms):
#获取以毫秒计算的当前时间戳
now_ms = get_current_unix_timestamp_in_ms()
#当前时间加上ttl,得出毫秒格式的键的过期时间
PEXPIREAT(key, now_ms + ttl_in_ms)
#EXPIREAT里面调用PEXPIREAT
def EXPIREAT(key, expire_time_in_sec):
#将过期时间从秒转化成毫秒
expire_time_in_ms = sec_to_ms(expire_time_in_sec)
PEXPIREAT(key, expire_time_in_ms)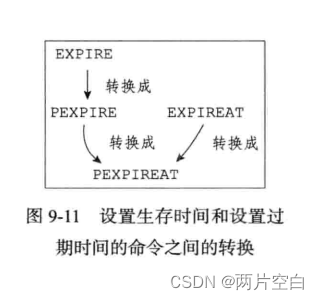
1.2 保存过期时间
redisDb结构的expires字典保存了数据库的所有键的过期时间,我们称这个字典为过期字典。
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象(也即是某个数据库的键)。
- 过期字典的值是一个long long类型的整数,这个整数保存了键所指向的数据库键的过期时间——一个毫秒精度的时间戳。
举个例子:
如果数据库当前状态如下图:

那么服务器执行一下命令之后,过期字典将新增一个键值对,其中键为message键对象,而值为1391234400000(2014年2月1日0时)
PEXPIREAT message 1391234400000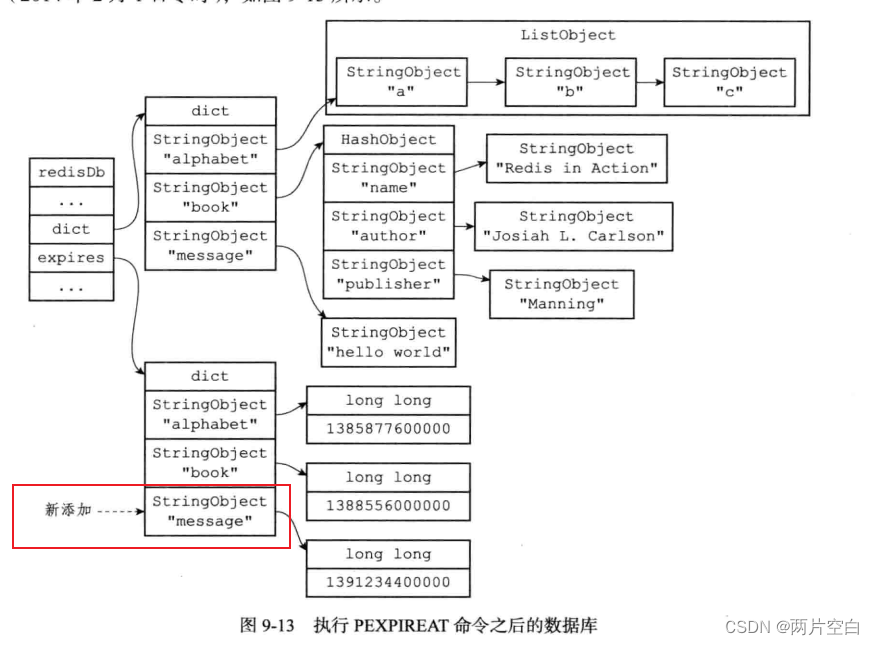
执行PEXPIREAT命令的伪代码:
def PEXPIREAT(key, expire_time_in_ms):
#如果给定的键不存在于键空间,那么不能设置过期时间
if key not in redisDb.dict:
return 0
#在过期字典中关联键和过期时间
redisDb.expires[key] = expire_time_in_ms
return 11.3 移除过期时间
PERSIST命令可以移除一个键的过期时间。
127.0.0.1:6379> set k1 'v1'
OK
127.0.0.1:6379> ttl k1
(integer) -1
127.0.0.1:6379> expire k1 1000
(integer) 1
127.0.0.1:6379> ttl k1
(integer) 998
127.0.0.1:6379> persist k1
(integer) 1
127.0.0.1:6379> ttl k1
(integer) -1
127.0.0.1:6379> 伪代码:
def PERSIST(key):
#判断键是否在过期字典中
if key not in redisDb.expires:
return 0
#删除过期字典中对应键值对
redisDb.expires.remove(key)
return 1 1.4 计算并返回剩余生存时间
TTL命令是以秒为单位返回键的剩余生存时间,PTTL命令则是以毫秒为单位返回键的剩余生存时间:
127.0.0.1:6379> hset d1 k1 v1
(integer) 1
127.0.0.1:6379> expire d1 2000
(integer) 1
127.0.0.1:6379> ttl d1
(integer) 1994
127.0.0.1:6379> pttl d1
(integer) 1989776
127.0.0.1:6379> 伪代码:
def PTTL(key):
#判断是否在键空间
if key not in redisDb.dict:
#已经过期
return -2
#判断是否存在过期字典
if key not in redisDb.expires:
#永不过期
return -1
#获得过期时间
#如果键没有设置过期时间,返回None
expire_timne_in_ms = redisDb.expires[key]
if expire_time_in_ms is None:
return -1
#获取当前时间
now_ms = get_current_unix_timestamp_in_ms()
return (expire_timne_in_ms - now_ms)
def TTL(key):
#获取以毫秒为单位的过期时间
ttl_in_ms = PTTL(key)
if ttl_in_ms < 0:
return ttl_in_ms
else:
return ms_to_sec(ttl_in_ms)1.5 过期键的判定
通过过期字典,程序可以用以下步骤检查一个给定的键是否过期:
- 检查给定的键是否存在于过期字典,存在,获取过期时间。
- 检查当前UNIX时间戳是否大于键的过期时间,如果是的话,表示键已经过期,否则未过期。
伪代码:
def is_expired(key):
#获取键的过期时间
expire_time_in_ms = redisDb.expires.get(key)
#键没有设置过期时间
if expire_time_in_ms is None:
return False
#获取当前时间时间戳
now_time_ms = get_current_unix_timestamp_in_ms()
if now_timw_ms > expire_time_in_ms:
return True
else
return False
我们也可以使用TTL或者PTTL命令来查看一个命令是否过期,大于等于0或者-1,表示未过期,-2表示过期。但是在redis代码中检查键是否过期的逻辑和上面的伪代码is_expired()方法一直,因为直接访问字典比执行一个命令快。
二. 过期键删除策略
对于过期键删除有三种可选策略:
- 定时删除:在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间来临时,立即执行对键的删除操作。
- 惰性删除:放任键过期不管,但是每次从键空间中获取键时,检查取得的键是否过期,如果过期的话,键删除该键,如果没有过期,就要返回该键。
- 定期删除:每个一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于删除多少过期键,以及检查多少数据库,则有算法决定。
在这三种策略中,第一种和第三种为主动删除策略,而第二种则为被动删除策略。
3.1 定时删除
定时删除策略对内存是最友好的:通过定时器,定时删除策略可以保证过期键会尽可能快的被删除,并释放过期键所占用的内存。
但是定时删除策略对CPU时间是最不友好的:在过期键比较多的情况下,删除过期键这一行为可能会占用相当一部分CPU时间。在内存不紧张但是CPU时间非常紧张的情况下,将CPU时间在删除和当前任务无关的过期键上,会对服务器的响应时间和吞吐量造成影响。
创建一个定时器需要用到Redis服务器中的时间事件,而当前时间事件是用无序链表实现的,查找一个键是否过期的时间复杂度为O(N),效率比较低。
所以,要让服务器创建大量的定时器,从而实现定时删除策略,现阶段不大现实。
3.2 惰性删除
惰性删除策略对CPU时间来说是友好的:程序只会在取出键时才对键进行过期检查,这样删除的键仅限于当前处理的键,不会在删除其他无关过期键上花费任何CPU时间。
惰性删除策略对内存来说是最不友好的:键已经过期,但是没有删除,仍然占用内存。
当数据库中有非常多的过期键,而这些键又恰好你没有被访问到,那他们就永远不会被删除,除非使用FLUSHDB命令,这种情况相当于是内存泄漏。
比如:日志,在某个时间点后,对它们的访问就会大大减少,甚至不在访问,这些过期数据就会一直占用Redis服务器内存,导致可使用的内存越来越少。
3.3 定期删除
定期删除是前面两种策略的折中:
- 定期删除策略每隔一段时间执行一次删除过期键操作,并且通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
- 定期删除策略有效的减少因为过期键带来的内存浪费。
但是定期删除策略的难点是确定删除操作的时长和频率:
- 如果删除操作执行的太频繁,或者执行时间过长,就会退化成定时删除策略。占用CPU时间过长。
- 如果删除操作执行的太少,或者执行的时间过短,就会退化成惰性删除,导致浪费内存。
因此采用定期删除策略,服务器必须根据情况,合理的设置删除操作的执行时长和执行频率。
三. Redis的过期键删除策略
Redis服务器实际使用的是惰性删除和定期删除两种策略。
3.1 惰性删除策略的实现
过期键的惰性删除策略有db.c/expireIfNeeded函数实现,所有读写数据库的redis命令在执行之前都会调用该函数进行检查:
- 如果输入键已经过期,那么expireIfNeeded函数将输入键从数据库中删除。
- 如果输入键没有过期,那么expireIfNeeded函数不动作。
int expireIfNeeded(redisDb *db, robj *key) {
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a slave, instead of
* evicting the expired key from the database, we return ASAP:
* the slave key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time. */
if (server.masterhost != NULL) return 1;
/* If clients are paused, we keep the current dataset constant,
* but return to the client what we believe is the right state. Typically,
* at the end of the pause we will properly expire the key OR we will
* have failed over and the new primary will send us the expire. */
if (checkClientPauseTimeoutAndReturnIfPaused()) return 1;
/* Delete the key */
deleteExpiredKeyAndPropagate(db,key);
return 1;
}命令调用expireIfNeeded函数过程如下图:

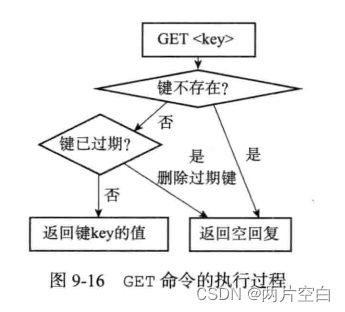
另外,因为每一个被访问的键都可能因为过期而被expireIfNeeded函数删除,所以每一个命令的实现函数必须同时处理键存在以及键不存在的情况:
- 如果键存在,命令按照键存在的情况执行。
- 当键不存在或者因为过期而被expireIfNeeded函数删除,命令按照不存在的情况执行。
下图展示了输入GET命令执行过程:
3.2 定期删除策略实现
过期键定期删除策略由redis.c/activeExpireCycle函数实现,每当Redis的服务器周期操作redis.c/serverCron函数执行时,activeExpireCycle函数会被调用,它在规定的时间内,分多次遍历服务器中的各个数据库,从数据库的expires字典中随机抽查一部分键的过期时间,并删除过期键。
#define CRON_DBS_PER_CALL 16
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
we do extra efforts. */
void activeExpireCycle(int type) {
/* Adjust the running parameters according to the configured expire
* effort. The default effort is 1, and the maximum configurable effort
* is 10. */
unsigned long
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
2*effort,
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
/* This function has some global state in order to continue the work
* incrementally across calls. */
static unsigned int current_db = 0; /* Next DB to test. */
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* When last fast cycle ran. */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
long long start = ustime(), timelimit, elapsed;
/* When clients are paused the dataset should be static not just from the
* POV of clients not being able to write, but also from the POV of
* expires and evictions of keys not being performed. */
if (checkClientPauseTimeoutAndReturnIfPaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
/* Don't start a fast cycle if the previous cycle did not exit
* for time limit, unless the percentage of estimated stale keys is
* too high. Also never repeat a fast cycle for the same period
* as the fast cycle total duration itself. */
if (!timelimit_exit &&
server.stat_expired_stale_perc < config_cycle_acceptable_stale)
return;
if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
return;
last_fast_cycle = start;
}
/* We usually should test CRON_DBS_PER_CALL per iteration, with
* two exceptions:
*
* 1) Don't test more DBs than we have.
* 2) If last time we hit the time limit, we want to scan all DBs
* in this iteration, as there is work to do in some DB and we don't want
* expired keys to use memory for too much time. */
//初始化检查的数据库数量
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
/* We can use at max 'config_cycle_slow_time_perc' percentage of CPU
* time per iteration. Since this function gets called with a frequency of
* server.hz times per second, the following is the max amount of
* microseconds we can spend in this function. */
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = config_cycle_fast_duration; /* in microseconds. */
/* Accumulate some global stats as we expire keys, to have some idea
* about the number of keys that are already logically expired, but still
* existing inside the database. */
long total_sampled = 0;
long total_expired = 0;
//遍历所有数据库
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* Expired and checked in a single loop. */
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle there are still
* a big percentage of keys to expire, compared to the number of keys
* we scanned. The percentage, stored in config_cycle_acceptable_stale
* is not fixed, but depends on the Redis configured "expire effort". */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
//过期键数量
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots, sampling the key
* space is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
sampled = 0;
ttl_sum = 0;
ttl_samples = 0;
if (num > config_keys_per_loop)
num = config_keys_per_loop;
/* Here we access the low level representation of the hash table
* for speed concerns: this makes this code coupled with dict.c,
* but it hardly changed in ten years.
*
* Note that certain places of the hash table may be empty,
* so we want also a stop condition about the number of
* buckets that we scanned. However scanning for free buckets
* is very fast: we are in the cache line scanning a sequential
* array of NULL pointers, so we can scan a lot more buckets
* than keys in the same time. */
long max_buckets = num*20;
long checked_buckets = 0;
while (sampled < num && checked_buckets < max_buckets) {
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;
idx &= db->expires->ht[table].sizemask;
dictEntry *de = db->expires->ht[table].table[idx];
long long ttl;
/* Scan the current bucket of the current table. */
checked_buckets++;
while(de) {
/* Get the next entry now since this entry may get
* deleted. */
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
if (activeExpireCycleTryExpire(db,e,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet
* not expired. */
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
total_expired += expired;
total_sampled += sampled;
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples.
* We just use the current estimate with a weight of 2%
* and the previous estimate with a weight of 98%. */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle for the current database if there are
* an acceptable amount of stale keys (logically expired but yet
* not reclaimed). */
} while (sampled == 0 ||
(expired*100/sampled) > config_cycle_acceptable_stale);
}
elapsed = ustime()-start;
server.stat_expire_cycle_time_used += elapsed;
latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
/* Update our estimate of keys existing but yet to be expired.
* Running average with this sample accounting for 5%. */
double current_perc;
if (total_sampled) {
current_perc = (double)total_expired/total_sampled;
} else
current_perc = 0;
server.stat_expired_stale_perc = (current_perc*0.05)+
(server.stat_expired_stale_perc*0.95);
}activeExpireCycle工作模式:
- 函数每次运行时,都从一定数量的数据库中取一定数量的随机键进行检查,并删除其中的过期键。
- 全部变量current_db会记录当前activeExpireCycle函数检查的进度,并在下一次调用activeExpireCycle函数调用时,接着上一次的进度进行处理。比如:当前在执行activeExpireCycle函数在遍历10号数据库时返回了,那么下一次调用activeExpireCycle函数时,从11号数据库开始查找并删除过期键。
- 随着activeExpireCycle函数的不断执行,服务器中的所有数据库都会检查一遍,这时函数current_db变量重置为0,然后再次开始新一轮的检查工作。
四. AOF,RDB和复制功能对过期键的处理
4.1 生成RDB文件
在执行SAVE命令或者BGSAVE命令创建一个新的RDB文件时,程序会对数据库中的键进行检查,已过期的键不会保存到新创建的RDB文件中。
4.2 载入RDB文件
在启动Redis服务器时,如果服务器开启了RDB功能,那么服务器将对RDB文件进行载入:
- 如果服务器以主服务器模式运行,那么在载入RDB文件时,程序会对文件中保存的键进行检查,未过期的键会被载入到数据库中,而过期的键则会被忽略,所以过期的键对载入RDB文件的主服务器不会造成影响。
- 如果服务器以从服务器模式运行,那么在载入RDB文件时,文件中保存的所有键,不论是否过期,都会被载入到数据库中。不过,因为主从服务器在进行数据同步的时候,从服务器的数据库会被清空,所以一般来讲,过期键对载入RDB文件的从服务器也不会照成影响。
4.3 AOF文件写入
当服务器以AOF持久化模式运行时,如果数据库中的某个键已经过期,但是他还没有被惰性删除或者定期删除,那么AOF文件不会因为这个过期键而产生任何影响。
当过期键被惰性删除或者定期删除之后,程序会向AOF文件追加(append)一条DEL命令,来显示地记录该键已被删除。
举个例子:
如果客户端使用GET message命令,试图访问过期的message键,那么服务器将执行以下三个动作:
- 从数据库中删除message键。
- 追加一条DEL message命令到AOF文件。
- 向执行GET命令的客户端返回空回复。
4.4 AOF重写
和生成RDB文件类似,在执行AOF重写的过程中,程序会对数据库中的建进行检查,已过期的键不会被保存到重写后的AOF文件中。
4.5 复制
当服务器运行在复制模式下,从服务器的过期键删除动作由主服务器控制:
- 主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个DEL命令。告知从服务器删除这个过期键。
- 从服务器在执行客户端发送地读命令时,即使碰到过期键也不会将过期键删除,而是继续像处理未过期地键一样处理过期键。
- 从服务器只有在接到主服务器发来地DEL命令之后,才会删除过期键。
通过主服务器来控制从服务器统一删除过期键,可以保证主从服务器数据一致。当一个过期键仍然存在于主服务器的数据库时,这个过期键在从服务器里的复制品也会继续存在。
智能推荐
数据挖掘十大算法--Apriori算法-程序员宅基地
文章浏览阅读4k次,点赞19次,收藏23次。Apriori 算法是一种用于关联规则挖掘的经典算法。它用于在大规模数据集中发现频繁项集,进而生成关联规则。关联规则揭示了数据集中项之间的关联关系,常被用于市场篮分析、推荐系统等应用。Apriori 算法的主要优点是它相对简单,并且易于理解和实现。然而,在处理大规模数据集时,它可能面临性能挑战。后续的改进算法,如 FP-Growth 等,通过不同的方式优化了频繁项集的发现过程,提高了算法的效率。_apriori算法
零基础教程:R语言lavaan结构方程模型(SEM)-程序员宅基地
文章浏览阅读1.2k次,点赞17次,收藏12次。基于R语言lavaan程序包,通过理论讲解和实际操作相结合的方式,由浅入深地系统介绍结构方程模型的建立、拟合、评估、筛选和结果展示的全过程。我们筛选大量经典案例
焊工考试多少分及格?焊工考试答题技巧分享-程序员宅基地
文章浏览阅读9.2k次。一、焊工考试多少分及格?焊工特种作业操作证考试80分就算及格,特种作业操作证考试分理论和实际操作证两项考试;理论是微机考试,从题库自动抽取题目。实际操作证考试包括模拟操作、口试等。焊工职业资格证书考试理论与实操各60分为及格分。二、答题技巧首先,在理论考试的时候一定要谨记以安全为主,任何不安全的行为都是不符合逻辑以及常理的,一定是不正确的答案。其次,实际操作一定要注重细节。实际操作中往往就是细节的地方需要注意,大部分的考试可能都是要以口述为主,所以细节的地方一定要主要记..._焊工考试多少分及格
Qt 图像处理(四)sobel算子与图像卷积_sobel算子和图像卷积-程序员宅基地
文章浏览阅读1.5k次。sobel算子与图像卷积图像卷积//图像的卷积运算/* * QImage *image 输入图像 * QImage &TemplateImg 输出图像 * int nTempH 模板的height = (nTempH -1)3x3的模板 * int nTempW 模..._sobel算子和图像卷积
为AsyncHttpClient设置Cookie-程序员宅基地
文章浏览阅读230次。使用AsyncHttpClient向服务端提交数据,有时需要带cookie。给AsyncHttpClient设置Cookie的方法如下:AsyncHttpClient myClient = new AsyncHttpClient();PersistentCookieStore myCookieStore = new PersistentCookieStore(this);Bas..._asynchttpclientutils 设置cookie
在Stm32CubeIDE环境下使用DAP-Link仿真_stm32cubeide daplink-程序员宅基地
文章浏览阅读1.9w次,点赞17次,收藏91次。一、文章bei'j最近师弟需要调STM32,由于他已经习惯了Eclipse的开发环境,所以给他推荐了Stm32CubeIDE,约等于TrueStudio+CubeMX,玩过一段时间,就推荐给了师弟_stm32cubeide daplink
随便推点
java基于微信小程序的奶茶点餐系统 奶茶店奶茶点餐小程序(源码(1)-程序员宅基地
文章浏览阅读263次,点赞3次,收藏4次。近年来,随着微信的快速发展,基于微信平台的应用层出不穷,许多商家也将点餐系统部署到了微信平台上,顾客可以从微信直接登录到点餐系统中进行菜品浏览,下单与支付,这使得点餐变得更加方便与快捷。本课题针对奶茶店设计出一个奶茶点餐微信小程序,奶茶点餐小程序可以帮助传统实体奶茶店在线上实现奶茶的售卖,并且使顾客也能更加方便快捷地购买到自己想要的奶茶饮品。博主介绍:全网粉丝10W+,CSDN全栈领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者。 精彩专栏 推荐订阅。
Keil for ARM-MDK的使用_keil for arm mdk-程序员宅基地
文章浏览阅读4.3k次。概念:μVision:是Keil的文本编辑界面。目前的μVision支持代码自动补全。如果想使用外部的文本编辑器,可以在Tools-Customize Tools Menu设置。MDK:就是Keil for ARM。全称Microcontroller Development Kit。具体可以参考这里的说明。调试方法:调试方法分两种:软件仿真和硬件调试,即Simulator和Debugger。_keil for arm mdk
mpeg4 码流格式及判断关键帧_mpeg4 关键帧-程序员宅基地
文章浏览阅读3.3k次。mpeg4 码流格式及判断关键帧_mpeg4 关键帧
span 禁止选中_vue点击标签切换选中及互相排斥操作-程序员宅基地
文章浏览阅读410次。单身和已婚不能同时选中,不了解保险和已了解保险不能同时选中。同时各个标签点击可以取消选择//html与我相关v-for="(item, index) in myself":key="index"@click="checkButton('myself', item.id)":class="item.isFlag ? 'current' : ''">{{item.title}}标签v-for="..._jsp span不支持选中
计算机网络基础知识(非常详细)从零基础入门到精通,看完这一篇就够了-程序员宅基地
文章浏览阅读3.4k次,点赞16次,收藏64次。TCP建链的⼤致过程如下:1)_计算机网络基础知识
二叉排序树(BST)_二叉排序树【bst】-程序员宅基地
文章浏览阅读344次。二叉排序树一、二叉排序树的介绍二、二叉排序树创建和遍历一、二叉排序树的介绍BST: (Binary Sort(Search) Tree), 对于二叉排序树的任何一个非叶子节点,要求左子节点的值比当前节点的值小,右子节点的值比当前节点的值大。下图就是一颗二叉排序树:如果有相同的值,将该节点放在左子节点或右子节点都可以二、二叉排序树创建和遍历数组Array(7, 3, 10, 12, 5, 1, 9) 创建成对应的二叉排序树,并使用中序遍历二叉排序树代码实现:package binaryS_二叉排序树【bst】